Redis底层结构与缓存原理
Redis是一个Key-Value的存储系统,使用ANSI C语言编写。
key的类型是字符串。
value的数据类型有:
常用的:string字符串类型、list列表类型、set集合类型、sortedset(zset)有序集合类型、hash类型。
不常见的:bitmap位图类型、geo地理位置类型。
一,Redis key的设计
将一个表,例如User表存入Redis中做缓存时,进行Key值的设计通常需要注意以下四个步骤:
- 用:分割
- 把表名转换为key前缀, 比如: user:
- 第二段放置主键值
- 第三段放置列名
实例:有User表中有如下数据存入到Redis中进行key的设计

username 的 key: user:1:username <表名:ID值:列明 如此设计Key值,表示明确,因为主键的唯一性,也不会出现被其它数据覆盖的问题>
二,Value常用数据类型
一, 字符串
Redis的String能表达3种值的类型:字符串、整数、浮点数 100.01 是个六位的串
常见命令:

上面的常见命令中着重分析setnx的使用,因为这个命令会涉及分布式锁的使用
通常情况下通过set命令去重复对一个key插入数据时,后面的数据会覆盖前面的数据,但是使用set NX之后,对于key已经存在的情况下,数据不会写入。这里对于 Redis的版本要求2.6以上,如果是2.6以下的版本无法在set后加NX会出现报错。


关于后续加px设置数据超时时间,超过这个时间的数据自动过期消除。
二,List列表
list列表类型可以存储有序、可重复的元素,且获取头部或尾部附近的记录是极快的,list的元素个数最多为2^32-1个(40亿)
Redis中的list和传统的数组不同,它是双向的,类似双向链表的结构(毕竟可以通过索引去取出),可以从两边进行存入和取出。也正是因为这样子的结构,Redis中的List即可用来当消息队列使用(左侧插入,右侧取出),也可以头进头出(栈)

常见命令:

对于push进去的数据,数据排序的顺序需要了解,例lpush插入的第一个数据,会在这个数组的最右侧

三,Set集合类型
Set:无序、唯一元素,集合中最大的成员数为 2^32 - 1
常用命令:
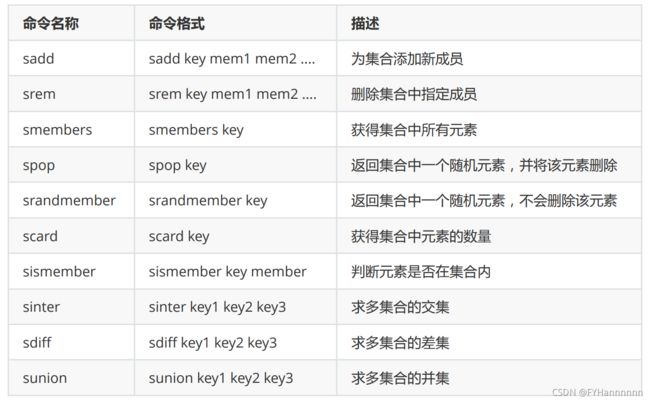
需要注意交集与随机数获取的命令使用: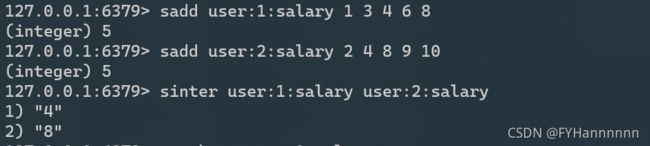

四,sortedset有序集合类型
SortedSet(ZSet) 有序集合: 元素本身是无序不重复的,每个元素关联一个分数(score),可按分数排序,分数可重复。通常用来做排行榜等数据。
常用命令:
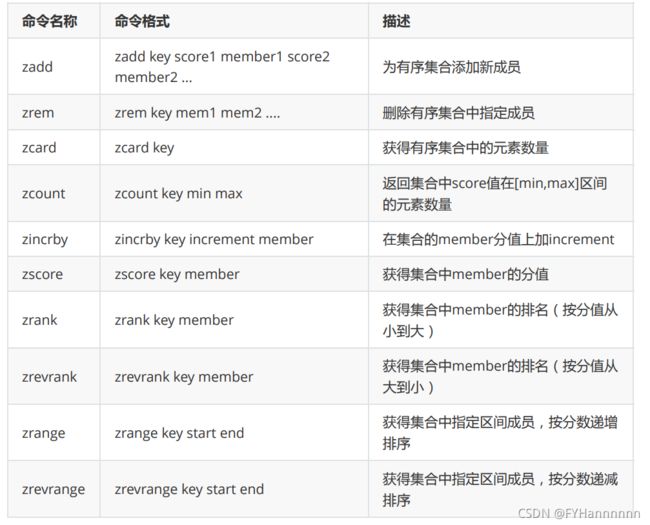
模拟点击事件次数
五,hash类型(散列表)
Redis hash 是一个 string 类型的 field 和 value 的映射表,它提供了字段和字段值的映射。 每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
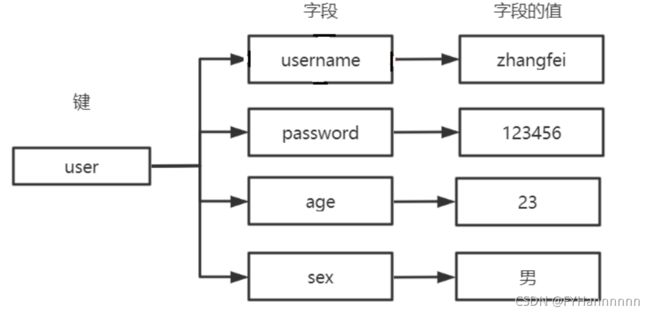
常用命令:
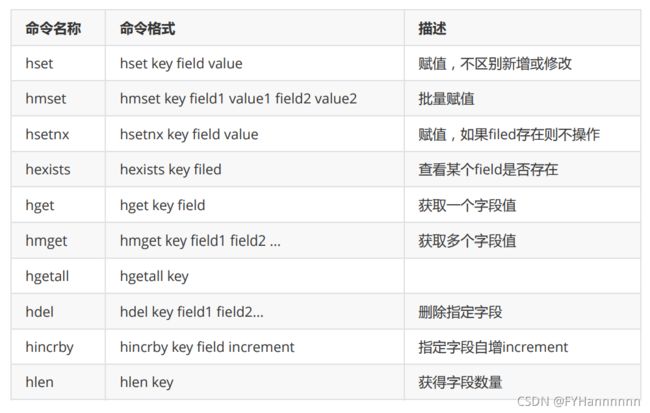 用于模拟存储对象
用于模拟存储对象

三,Redis底层数据结构
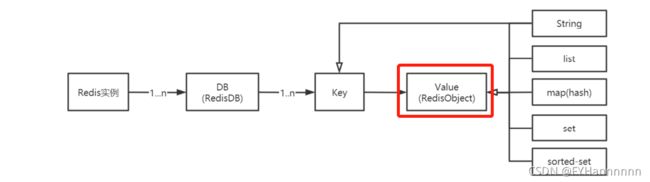
Redis没有表的概念,Redis实例所对应的db以编号区分,db本身就是key的命名空间。
一,RedisDB结构
Redis中存在“数据库”的概念,该结构由redis.h中的redisDb定义。 当redis 服务器初始化时,会预先分配 16 个数据库,所有数据库保存到结构 redisServer 的一个成员 redisServer.db 数组中, redisClient中存在一个名叫db的指针指向当前使用的数据库
RedisDB结构源码:

二,RedisObject结构
Value是一个对象,包含字符串对象,列表对象,哈希对象,集合对象和有序集合对象(常用的结构对象)
RedisObject结构源码:

24位LRU lru(两种淘汰策略公用的一个字段)
记录的是对象最后一次被命令程序访问的时间,( 4.0 版本占 24 位,2.6 版本占 22 位)。
高16位存储一个分钟数级别的时间戳,低8位存储访问计数(lfu : 最近访问次数)
lru----> 高16位: 最后被访问的时间
lfu----->低8位:最近访问次数
refcount refcount
记录的是该对象被引用的次数,类型为整型。
refcount 的作用,主要在于对象的引用计数和内存回收。
当对象的refcount>1时,称为共享对象 Redis 为了节省内存,当有一些对象重复出现时,新的程序不会创建新的对象,而是仍然使用原来的对象。
三,字符串SDS
C语言情况下字符数组结尾会以"\0"结尾,Redis 使用了 SDS(Simple Dynamic String)。用于存储字符串和整型数据,SDS结构如下图所示,相比较之下对数组的可用长度,占用长度做了指针属性,那么可以计算buf[] 的长度=len+free+1

SDS结构源码

SDS的优势:
- SDS 在 C 字符串的基础上加入了 free 和 len 字段,获取字符串长度:SDS 是 O(1),C 字符串是 O(n)。
- SDS 由于记录了长度,在可能造成缓冲区溢出时会自动重新分配内存,杜绝了缓冲区溢出。
- 可以存取二进制数据,以字符串长度len来作为结束标识
C语言 & SDS:
c语言情况下 \0 空字符串 二进制数据包括空字符串,所以没有办法存取二进制数据 。SDS非二进制之不用说,二进制情况下当成字符串的长度来存储
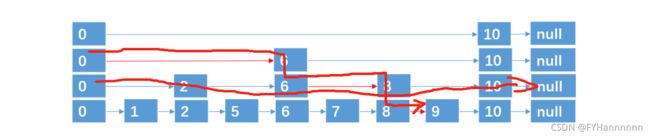
四,跳跃表
跳跃表是有序集合(sorted-set)的底层实现,效率高,实现简单。
跳跃表的基本思想:将有序链表中的部分节点分层,每一层都是一个有序链表。
通过抛硬币(概率1/2)的方式来决定新插入结点跨越的层数:
跳跃表结构源码:
//跳跃表节点
typedef struct zskiplistNode {
sds ele; /* 存储字符串类型数据 redis3.0版本中使用robj类型表示,
但是在redis4.0.1中直接使用sds类型表示 */
double score;//存储排序的分值
struct zskiplistNode *backward;//后退指针,指向当前节点最底层的前一个节点
/*
层,柔性数组,随机生成1-64的值
*/
struct zskiplistLevel {
struct zskiplistNode *forward; //指向本层下一个节点
unsigned int span;//本层下个节点到本节点的元素个数
} level[];
} zskiplistNode;
//链表
typedef struct zskiplist{
//表头节点和表尾节点
structz skiplistNode *header, *tail;
//表中节点的数量
unsigned long length;
//表中层数最大的节点的层数
int level;
}zskiplist
跳跃表的优势:
1、可以快速查找到需要的节点 O(logn)
2、可以在O(1)的时间复杂度下,快速获得跳跃表的头节点、尾结点、长度和高度。
应用场景:有序集合的实现
五,Redis字典
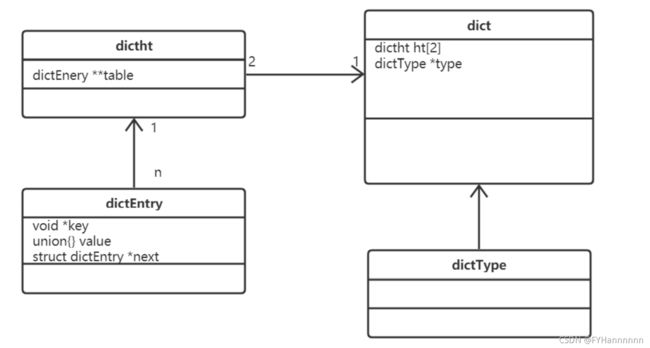
字典dict又称散列表(hash),是用来存储键值对的一种数据结构。 Redis整个数据库是用字典来存储的。(K-V结构) 对Redis进行CURD操作其实就是对字典中的数据进行CURD操作。
hash函数可以把Redis里的key:包括字符串、整数、浮点数统一转换成整数。这个部分不做多的解析,和JDK HashMap底层结构一致(对于Hash冲突,定位存储下标,扩容重新计算Hash)
Redis字典结构
Redis字典实现包括:字典(dict)、Hash表(dictht)、Hash表节点(dictEntry)。

Hash表源码
 Hash表节点源码
Hash表节点源码

dict字典源码

type字段,指向dictType结构体,里边包括了对该字典操作的函数指针

六,压缩列表
压缩列表(ziplist)是由一系列特殊编码的连续内存块组成的顺序型数据结构,主要作用用于节省内存。
压缩列表数据结构与源码:


应用场景:
sorted-set和hash元素个数少且是小整数或短字符串(直接使用)

list用快速链表(quicklist)数据结构存储,而快速链表是双向列表与压缩列表的组合。(间接使用)
七,快速列表
快速列表(quicklist)是Redis底层重要的数据结构。是列表的底层实现。(在Redis3.2之前,Redis采 用双向链表(adlist)和压缩列表(ziplist)实现。)在Redis3.2以后结合adlist和ziplist的优势Redis设 计出了quicklist。

quicklist是一个双向链表,链表中的每个节点时一个ziplist结构。quicklist中的每个节点ziplist都能够存 储多个数据元素。
 快速列表源码
快速列表源码


quicklist每个节点的实际数据存储结构为ziplist,这种结构的优势在于节省存储空间。为了进一步降低 ziplist的存储空间,还可以对ziplist进行压缩。Redis采用的压缩算法是LZF。其基本思想是:数据与前 面重复的记录重复位置及长度,不重复的记录原始数据。

四,Redis缓存过期与淘汰策略
maxmemory设置(最大内存设置)
设置maxmemory后,当趋近maxmemory时,通过缓存淘汰策略,从内存中删除对象 不设置maxmemory 无最大内存限制 maxmemory-policy noeviction (禁止驱逐不淘汰)
expire
使用expire命令设置一个键的存活时间(ttl: time to live),过了这段时间,该键就会自动 被删除。
expire源码

删除策略
Redis的数据删除有定时删除、惰性删除和主动删除三种方式,Redis的数据删除有定时删除、惰性删除和主动删除三种方式。
定时删除:在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除 操作。 需要创建定时器,而且消耗CPU,一般不推荐使用。
惰性删除:在key被访问时如果发现它已经失效,那么就删除它。调用expireIfNeeded函数,该函数的意义是:读取数据之前先检查一下它有没有失效,如果失效了就删 除它。
主动删除:在redis.conf文件中可以配置主动删除策略,默认是no-enviction(不删除);maxmemory-policy allkeys-lru
缓存淘汰策略的选择
- allkeys-lru : 在不确定时一般采用策略。 冷热数据交换
- volatile-lru : 比allkeys-lru性能差,存 : 过期时间
- allkeys-random : 希望请求符合平均分布(每个元素以相同的概率被访问)
- 自己控制:volatile-ttl 缓存穿透