【API篇】五、Flink分流合流API
文章目录
- 1、filter算子实现分流
- 2、分流:使用侧输出流
- 3、合流:union
- 4、合流:connect
- 5、connect案例
分流,很形象的一个词,就像一条大河,遇到岸边有分叉的,而形成了主流和测流。对于数据流也一样,不过是一个个水滴替换成了一条条数据。

将一条数据流拆分成完全独立的两条、甚至多条流。也就是基于一个DataStream,定义一些筛选条件,将符合条件的数据拣选出来放到对应的流里。

1、filter算子实现分流
Demo案例:读取一个整数数字流,将数据流划分为奇数流和偶数流。
实现思路:针对同一个流,多次条用filter算子来拆分
public class SplitStreamByFilter {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<Integer> ds = env.socketTextStream("node01", 9527)
.map(Integer::valueOf);
//将ds 分为两个流 ,一个是奇数流,一个是偶数流
//使用filter 过滤两次
SingleOutputStreamOperator<Integer> ds1 = ds.filter(x -> x % 2 == 0);
SingleOutputStreamOperator<Integer> ds2 = ds.filter(x -> x % 2 == 1);
ds1.print("偶数");
ds2.print("奇数");
env.execute();
}
}
以上实现的明显缺陷是,同一条数据,被多次处理。以上其实是将原始数据流stream复制两份,然后对每一份分别做筛选,冗余且低效。
2、分流:使用侧输出流
基本步骤为:
- 使用process算子(Flink分层API中的最底层的处理函数)
- 定义OutputTag对象,即输出标签对象,用于后面标记和提取侧流
- 调用上下文ctx的.output()方法
- 通过主流获取侧流
案例:实现将WaterSensor按照Id类型进行分流
先定义下MapFunction的转换规则,用来将输入的数据转为自定义的WaterSensor对象:
public class WaterSensorMapFunction implements MapFunction<String,WaterSensor>{
@Override
public WaterSensor map(String value) throws Exception {
String[] strArr = value.split( regex: ",");
//String组装对象
return new WaterSensor(strArr[0],Long.value0f(strArr[1]),Integer.value0f(strArr[2]));
}
}
使用侧流:
public class SplitStreamByOutputTag {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
SingleOutputStreamOperator<WaterSensor> ds = env.socketTextStream("node01", 9527)
.map(new WaterSensorMapFunction());
//定义两个输出标签对象,用于后面标记和提取侧流
OutputTag<WaterSensor> s1 = new OutputTag<>("s1", Types.POJO(WaterSensor.class));
OutputTag<WaterSensor> s2 = new OutputTag<>("s2", Types.POJO(WaterSensor.class));
//返回的都是主流
SingleOutputStreamOperator<WaterSensor> ds1 = ds.process(new ProcessFunction<WaterSensor, WaterSensor>()
{
@Override
//形参为别为:流中的一条数据、上下文对象、收集器
public void processElement(WaterSensor value, Context ctx, Collector<WaterSensor> out) throws Exception {
if ("s1".equals(value.getId())) {
ctx.output(s1, value);
} else if ("s2".equals(value.getId())) {
ctx.output(s2, value);
} else {
//主流
out.collect(value);
}
}
});
ds1.print("主流");
SideOutputDataStream<WaterSensor> s1DS = ds1.getSideOutput(s1);
SideOutputDataStream<WaterSensor> s2DS = ds1.getSideOutput(s2);
s1DS.printToErr("侧流s1"); //区别主流,让控制台输出标红
s2DS.printToErr("侧流s2");
env.execute();
}
}
相关传参说明,首先是创建OutputTag对象时的传参:
- 第一个参数为标签名,用于区分是哪一个侧流
- 第二个是放入侧流中的数据的类型,且必须是Flink的类型(TypeInfomation,借助Types类)
- OutputTag的泛型,是流到对应的侧流的数据类型
ProcessFunction接口的泛型中:
- 第一个是输入的数据类型
- 第二个是输出到主流上的数据类型
ctx.output方法的形参:
- 第一个为outputTag对象
- 第二个为数据,上面代码中传value即直接输出数据本身,也可输出处理后的数据,主流侧流数据类型不用一致
看下运行效果:

3、合流:union
将来源不同的多条流,合并成一条来联合处理,即合流。最简单的合流操作,就是直接将多条流合在一起,叫作流的联合(union)

union的条件是:
- 每条流中要合并的数据类型必须相同(原始不同,可先借助map,在union)
- 合并之后的新流会包括所有流中的元素,数据类型不变
stream1.union(stream2, stream3, ...) //可变长参数
public class UnionExample {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<Integer> ds1 = env.fromElements(1, 2, 3);
DataStreamSource<Integer> ds2 = env.fromElements(2, 2, 3);
DataStreamSource<String> ds3 = env.fromElements("2", "2", "3");
ds1.union(ds2,ds3.map(Integer::valueOf))
.print();
env.execute();
}
}
//输出:
1
2
3
2
2
3
2
2
3
4、合流:connect
union合并流受限于数据类型,因此还有另一种合流操作:connect

public class ConnectDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//Integer流
SingleOutputStreamOperator<Integer> source1 = env.socketTextStream("node01", 9527)
.map(i -> Integer.parseInt(i));
//String流
DataStreamSource<String> source2 = env.socketTextStream("node01", 2795);
/**
* 总结: 使用 connect 合流
* 1、一次只能连接 2条流
* 2、流的数据类型可以不一样
* 3、 连接后可以调用 map、flatmap、process来处理,但是各处理各的
*/
ConnectedStreams<Integer, String> connect = source1.connect(source2);
SingleOutputStreamOperator<String> result = connect.map(new CoMapFunction<Integer, String, String>() {
@Override
public String map1(Integer value) throws Exception {
return "来源于原source1流:" + value.toString();
}
@Override
public String map2(String value) throws Exception {
return "来源于原source2流:" + value;
}
});
result.print();
env.execute();
}
}
使用 connect 合流的总结:
- 一次只能连接 2条流,因为connect返回的是一个ConnectedStreams对象,不再是DataStreamSource或其子类了
- 两条流中的数据类型可以不一样
- 连接后可以调用 map、flatmap、process来处理,但是各处理各的
以map为例,其形参是一个CoMapFuntion接口类型,泛型则分别是流1的数据类型、流2的数据类型、合并及处理后输出的数据类型。两个map方法可以看出,虽然两个流合并成一个了,但处理数据时还是各玩各的。
- .map1()就是对第一条流中数据的map操作
- .map2()则是针对第二条流

connect 就类比被逼相亲后结婚,两个人看似成一家了,但实际上各自玩各自的。往大了举例就相当于一国两制。
5、connect案例
和connect以后的map传CoMapFunction一样,process算子也不再传ProcessFunction,而是CoProcessFunction,实现两个方法:
- processElement1():针对第一条流
- processElement2():针对第二条流
connect合并后得到的ConnectedStreams也可以直接调用.keyBy()进行按键分区,分区后返回的还是一个ConnectedStreams
connectedStreams.keyBy(keySelector1, keySelector2);
//keySelector1和keySelector2,是两条流中各自的键选择器
ConnectedStreams进行keyBy操作,其实就是把两条流中key相同的数据放到了一起,然后针对来源的流再做各自处理
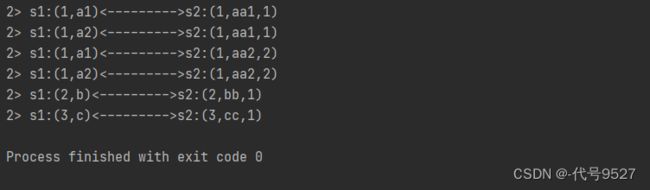
案例需求:连接两条流,输出能根据id匹配上的数据,即两个流里元组f0相同的数据(类似inner join效果)
public class ConnectKeybyDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
//二元组流
DataStreamSource<Tuple2<Integer, String>> source1 = env.fromElements(
Tuple2.of(1, "a1"),
Tuple2.of(1, "a2"),
Tuple2.of(2, "b"),
Tuple2.of(3, "c")
);
//三元组流
DataStreamSource<Tuple3<Integer, String, Integer>> source2 = env.fromElements(
Tuple3.of(1, "aa1", 1),
Tuple3.of(1, "aa2", 2),
Tuple3.of(2, "bb", 1),
Tuple3.of(3, "cc", 1)
);
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connect = source1.connect(source2);
// 多并行度下,需要根据 关联条件 进行keyby,才能保证key相同的数据到一起去,才能匹配上
ConnectedStreams<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>> connectKey = connect.keyBy(s1 -> s1.f0, s2 -> s2.f0);
SingleOutputStreamOperator<String> result = connectKey.process(
new CoProcessFunction<Tuple2<Integer, String>, Tuple3<Integer, String, Integer>, String>() {
// 定义 HashMap,缓存来过的数据,key=id,value=list<数据>
Map<Integer, List<Tuple2<Integer, String>>> s1Cache = new HashMap<>();
Map<Integer, List<Tuple3<Integer, String, Integer>>> s2Cache = new HashMap<>();
@Override
public void processElement1(Tuple2<Integer, String> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
// TODO 1.来过的s1数据,都存起来
if (!s1Cache.containsKey(id)) {
// 1.1 第一条数据,初始化 value的list,放入 hashmap
List<Tuple2<Integer, String>> s1Values = new ArrayList<>();
s1Values.add(value);
s1Cache.put(id, s1Values);
} else {
// 1.2 不是第一条,直接添加到 list中
s1Cache.get(id).add(value);
}
//TODO 2.根据id,查找s2的数据,只输出 匹配上 的数据
if (s2Cache.containsKey(id)) {
for (Tuple3<Integer, String, Integer> s2Element : s2Cache.get(id)) {
out.collect("s1:" + value + "<--------->s2:" + s2Element);
}
}
}
@Override
public void processElement2(Tuple3<Integer, String, Integer> value, Context ctx, Collector<String> out) throws Exception {
Integer id = value.f0;
// TODO 1.来过的s2数据,都存起来
if (!s2Cache.containsKey(id)) {
// 1.1 第一条数据,初始化 value的list,放入 hashmap
List<Tuple3<Integer, String, Integer>> s2Values = new ArrayList<>();
s2Values.add(value);
s2Cache.put(id, s2Values);
} else {
// 1.2 不是第一条,直接添加到 list中
s2Cache.get(id).add(value);
}
//TODO 2.根据id,查找s1的数据,只输出 匹配上 的数据
if (s1Cache.containsKey(id)) {
for (Tuple2<Integer, String> s1Element : s1Cache.get(id)) {
out.collect("s1:" + s1Element + "<--------->s2:" + value);
}
}
}
});
result.print();
env.execute();
}
}
运行效果: