2021-06-29 MySql(未完待续)
目录
文章目录
-
- 目录
- 1、初识MySql
-
-
- 1.1、什么是数据库
- 1.2、数据库分类
- 1.3、MySQL简介
- 1.4、连接数据库
-
- 2、 操作数据库
-
-
- 2.1、操作数据库
- 2.2、数据库的列类型
- 2.3、数据库的字段属性(重点)
- 2.4、创建数据库表(重点)
- 2.5、 数据表的类型
- 2.6、操作表
-
-
- 1、复制表:
- 2、删除表:
- 3、修改表结构:
- 4、修改表名:
- 5、修改表的字段(重命名,修改约束!):
-
-
- 3、MySQL数据管理
-
-
- 3.1、外键(了解即可)
- 3.2、DML语言 (全部记住)
- 3.3、添加
- 3.4、修改
- 3.5、删除
-
- 4、查询数据(最重点)
-
-
- 4.1、查询语句
- 补充
- 4.2、**列别名**
-
- 1、第一种带as
- 2、第二种不带as
- 3、**消除重复行 distinct**
- 4.3、where条件子句 ---等值查询
- 4.4 、模糊查询:比较运算符
- 4.5、逻辑运算符 and or not
- 4.6、排序 order by
- 4.7、限制记录行数--limit ------分页
- 4.8、 连表查询 join(对比 )
-
- 5、函数
-
-
- 1、数学函数
-
-
- 1、聚合函数
- 2、常用函数
-
-
- 6、多表连接
-
-
- 1. **连接:**
- 2. **笛卡尔积现象:**
- 3. 表的别名(带as 不带as)
- 4. 自身连接
-
- 7、分组函数
-
- 1、 常用分组函数吗
- 2、子查询
- 3、MD5 加密
- 4、总结select
- 8、视图和索引
-
-
- 1、视图:
- 2、索引
- 3、测试索引
- 4、索引原则
-
- 9、事务
-
-
- 1、 事务的四个特性**(ACID)**:
- 2、事物的隔离所导致的问题
-
- 1、脏读:
- 2、不可重复读:
- 3、虚读(幻读)
-
- 10、权限管理和备份
-
-
- 10.1、用户管理
- 10.2、MySQL备份
-
- 11、规范数据库设计
- 12、JDBC(重点)
-
-
- 12.1、数据库驱动
- 12.2、JDBC
-
1、初识MySql
javaEE : 企业级java开发 Web
前端 (页面:展示,数据!)
后台 (连接点: 连接数据库JDBC , 链接前端 (控制试图跳转,和给前端传递数据))
数据库 (存数据,Txt, Excel, Word)
数据库是所有软件体系中最核心的存在 DBA(数据库管理员)
1.1、什么是数据库
数据库:按照数据结构,组织,管理信息,存放数据的仓库称作是数据库
数据库:(DB, DataBase)
概念: 数据仓库,软件, 安装在操作系统(window,linux,mac, …)之上
SQL 可以存储大量的数据,500万!(500万条以上需要优化)
作用:存储数据,管理数据
1.2、数据库分类
关系型数据库: (SQL)
- MySQL, Oracle, Sql Server, DB2, SQLlite
- 通过表和表之间,行和列之间的关系进行数据的存储。
非关系型数据库: (NoSQL) Not Only SQL
- Redis, MongDB
- 非关系型数据库,对象存储,通过对象的自身的属性来决定。
DBMS(数据库管理系统)
- 数据库的管理软件,科学有效的管理我们的数据。维护和获取数据;
- MySQL,数据库管理系统!
1.3、MySQL简介
- 是一个关系型数据库管理系统
- 前世:瑞典MySQL AB公司
- 今生:属于Oracle旗下产品
- 适用:中小型网站,大型网站,集群!
1.4、连接数据库
命令行连接!
mysql -uroot -p123456 --连接数据库 --------------------------------- --所有的语句都使用: 结尾 show databases; --查看所有的数据库 mysql> use school -- 切换数据库 use 数据库名 Databases changed show tables; -- 查看数据库中所有的表 descride student; --显示数据库中所有的表的信息 create database westos; --创建一个数据库 exit; --退出连接
2、 操作数据库
操作数据库> 操作数据库中的表> 操作数据库中白哦的数据
2.1、操作数据库
-
创建数据库
CREATE DATABASE IF NOT EXISTS zwz; -
删除数据库
DROP DATABASE IF EXISTS zwz; -
使用数据库
-- tab 键的上面,如果你的名字或字段名是一个特殊字符,就需要带`` USE `user` -
查看数据库
SHOW DATABASES;
2.2、数据库的列类型
数值
-
tinyint 十分小的数据 1个字节
-
smallint 较小的数据 2个字节
-
mediumint 中等大小的数据 3个字节
-
int 标准的整数 4个字节 常用
-
bigint 较大的数据 8个字节
-
float 浮点数 4个字节
-
double 浮点数 8个字节(精度问题!)
-
decimal 字符串形式的浮点数 金融计算的时候,一般是使用decimal
字符串
- char 字符串固定大小的 0~255
- varchar 可变字符串 0~65535 常用的变量 String
- tinytext 微型文本 2^8 - 1
- text 文本串 2^16 - 1 保存大文本
时间日期
java.util.Date
- date YYYY-MM-DD 日期格式
- time HH:mm:ss 时间格式
- datetime YYYY-MM-DD HH:mm:ss 最常用的时间格式
- timestamp 时间戳, 1970.1.1 到现在毫秒数! 也较为常用!
- year 年份表示
null
- 没有值,未知
- 注意,不用使用NULL进行运算,结果为NULL
2.3、数据库的字段属性(重点)
Unsinged :
- 无符号的整数
- 声明了该列不能声明为负数
aerofill :
- 0填充
- 不足的位数,使用0来填充, int(3),5 — 005
自增:
- 通常理解为自增,自动在上一条记录的基础上+1(默认)
- 通常用来设计唯一的主键~ index, 必须是整数类型
- 可以自定义设计的主键自增起始值和步长
**非空:**NULL not null
- 假设设置为 not null , 如果不给它赋值, 就会报错!
- NULL , 如果不填写值, 默认就是null !
默认:
- 设置默认的值!
- sex,默认值为 男 , 如果不指定该列的值, 则会有默认的值!
拓展:听听就好
/*
每一个表,都必须存在以下五个字段! 未来做项目用的,表示一个记录存在意义!
id 主键
`version` -- 乐观锁
is_delete -- 伪删除
gmt_create -- 创建时间
gmt_uodate -- 修改时间
*/
2.4、创建数据库表(重点)
格式
create database 数据库名; -- 创建数据库:
drop database 数据库名; -- 删除数据库:
-- 创建数据库表格式:
-- 1
CREATE TABLE [IF NOT EXISTS] `表名` (
'字段名' 列类型 [属性] [索引] [注释],
'字段名' 列类型 [属性] [索引] [注释],
......
'字段名' 列类型 [属性] [索引] [注释]
)[表类型][字符集设置][注释]
-- 2
create table 表名(
字段名 数据类型 [约束],
字段名 数据类型 [约束],
字段名 数据类型 [约束]
);
常用命令
SHOW CREATE DATABASE school -- 查看创建数据库的语句
SHOW CREATE TABLE student2 -- 查看student数据表的定义语句
DESC student2 -- 显示表的结构
select version(); -- 查看数据库的版本:
show databases; -- 查看有哪些数据库:
use 数据库名; -- 切换数据库命令:
show tables; -- 查看数据库中有哪些表:
desc 表名; -- 查看数据库的表结构:
2.5、 数据表的类型
设置数据库表的字符编码
CHARSET(utf8) -- 不设置的话,会是mysql默认的字符集编码Latin1,(不支持中文!)
在my.ini中配置默认的编码
character-set-server=utf
-- 存储引擎:指的是创建表的类型
show engines; -- 查看存储引擎
2.6、操作表
1、复制表:
-- 1、复制表结构
create table 表名 like 原表名
-- 2、复制表结构和内容
create table 表名 select * from 原表名
2、删除表:
-- DROP TABLE IF EXISTS 表名; 如果该表存在就删除
DROP TABLE IF EXISTS teacher1
-- 删除表的字段
-- ALTER TABLE 表名 DROP 字段名
3、修改表结构:
ALTER TABLE 表名 ADD 列名 数据类型和长度 列属性
ALTER TABLE 表名 MODIFY 列名 新数据类型和长度 新列属性
ALTER TABLE 表名 DROP COLUMN 列名
4、修改表名:
alter table 旧表名 rename as 新表名 -- 1
alter table 旧表名 rename 新表名 -- 2
5、修改表的字段(重命名,修改约束!):
-- ALTER TABLE 表名 MODIFY 字段名 列属性[]
-- ALTER TABLE 表名 MODIFY 旧名字 新名字 列属性[]
3、MySQL数据管理
3.1、外键(了解即可)
删除有外键表关系的时候,必须要先删除引用别人的表(从表),再删除被引用的表(主表)
方式一:在创建表的时候,增加约束(麻烦,比较复杂)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tYD8Ncu4-1624937364973)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210610141844162.png)]
方式二:创建表成功后,添加外键约束
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NC15edEn-1624937364974)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210610142002352.png)]
以上操作都是物理外键,数据库级别的外键,不建议使用!(避免数据库过多造成困扰)
- [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zp4UuYEU-1624937364975)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210610142150150.png)]
3.2、DML语言 (全部记住)
数据操作语言
- insert ioto
- delete
- update
- select
3.3、添加
插入语句insert
1.按照指定列进行插入 (字段的个数和类型要保持一致)
2.字段和字段之间使用英文逗号隔开
3.可以同时插入多条数据
insert into 表名 (字段名1, 字段名2, 字段名3…) values (值1,值2,值3…);
-- 插入语句insert
-- 1.按照指定列进行插入 (字段的个数和类型要保持一致)
-- 2.字段和字段之间使用英文逗号隔开
-- 3.可以同时插入多条数据
-- insert into 表名 (字段名1, 字段名2, 字段名3...) values (值1,值2,值3...);
-- 向部门表中插入数据 编号是1号 名称是研发部 地点是北京
insert into dept (deptno, dname, loc) values(1, "研发部", "北京");
-- 向员工表中插入数据 员工编号为1 姓名为张三 职位是工程师 入职日期2020-1-1 薪资4000 部门是1号部门
insert into emp (empno, ename, job, hiredate, sal, deptno) values(1, "张三", "工程师","2020-1-1", 4000, 1);
-- 插入空值
-- 向部门表中插入2号部门,名称是运营部
insert into dept (deptno, dname,loc) values(2,'运营部',null);
-- 插入日期
-- 向员工表中插入员工编号,员工姓名 员工入职日期 (SYSDATE() 获取当前日期)
insert into emp (empno, ename, hiredate) values(3,"李四",SYSDATE());
-- 1.向员工表中新增一个员工,员工编号为8888,姓名为BOB,岗位为CLERK,经理为号7788,入职日期为1985-03-03,薪资3000,奖金和部门为空。
insert into emp (empno, ename, job, mgr, hiredate, sal) values(8888,'BOB','CLERK',7788,'1985-03-03',3000);
-- 按照所有列插入数据
insert into 表名 values (值1,值2,值3....);
-- 向dept表中插入数据 编号为3 部门名称为后勤部
insert into dept values(3, "后勤部",null);
-- 批量插入数据
insert into 表名 values (值1,值2,值3....),(值1,值2,值3....),(值1,值2,值3....);
-- 向dept表中插入数据
insert into dept values(3, "后勤部",null),(4, "后勤部2",null)
3.4、修改
修改数据
update 修改谁 (条件) set原来的值=新值
-- 修改数据
update 表名 set 字段名 = 值, 字段名=值 [where 条件]
-- 将3号部门工作地点修改为大连
update dept set loc='大连' where deptno = 3
-- 将员工表中编号为3 的员工职位改为保洁,薪资改6000
update emp set job = '保洁', sal = 6000 where empno = 3;
-- 把员工编号为7782的部门编号修改为20
update emp set deptno = 20 where empno = 7782
-- 把部门编号为10的员工,部门编号调整为20,工资增加100
update emp set deptno = 20 , sal = sal+100 where deptno = 10
-- 将部门编号为1的员工的部门编号改为100
update emp set deptno = 100 where deptno = 1; -- 完整性约束错误
create table emp2(
eno int(4),
ename varchar(30),
deptno int(2),
FOREIGN key(deptno) REFERENCES dept (deptno)
);
-- 2.修改奖金为null的员工,奖金设置为0 (where 条件后面如果判断为空 是 is null)
update emp set comm = 0 where comm is null;
-- 将员工表中奖金为0的员工的奖金设置为null
update emp set comm = null where comm = 0
条件: where子句 运算符 id等于某个值,大于某个值,在某个区间内修改…
空值是指一种无效的、未赋值、未知的或不可用的值。不能正常参与运算。
** 任何包含空值的算术表达式运算后的结果都为空值NULL。通过ifnull可解决**
-- 查询员工表中员工编号,姓名,入职日期,部门编号,员工年薪(月薪* 12 + 奖金)
select empno, ename, hiredate, deptno , sal * 12 + IFNULL(comm,0) from emp;
操作符会返回 布尔值
| 操作符 | 含义 | 范围 | 结果 |
|---|---|---|---|
| = | 等于 | 5=6 | false |
| <>或!= | 不等于 | 5<>6 | true |
| > | 大于 | ||
| < | 小于 | ||
| <= | 小于等于 | ||
| >= | 大于等于 | ||
| BETWEEN … and … | 在某个范围内 | [2,5] | |
| AND | 我和你 && | 5>1 and 1>2 | false |
| OR | 我或你 || | 5>1 and 1>2 | true |
3.5、删除
– 删除数据
delete from 表 [where 条件]
-- 删除数据
delete from 表 [where 条件]
-- 删除职位是保洁的员工
delete from emp where job = "保洁";
-- 删除100号部门的员工信息
delete from emp where deptno = 100
-- 删除20号部门的部门信息(删除记录时完整性约束错误)
delete from dept where deptno = 20
-- 1.删除经理编号为7566的员工记录
delete from emp where mgr= 7566
-- 截断表
TRUNCATE table 表名
TRUNCATE table person;
-- TRUNCATE和DELETE区别(面试题)
-- DROP 是删除整个表
-- TRUNCATE是DDL,只能删除表中所有记录,自增会归零,不会影响事务。释放存储空间,使用ROLLBACK不可以回滚。
-- DELETE是DML,(条件删除)可以删除指定记录,不释放存储空间,使用ROLLBACK可以回滚。
4、查询数据(最重点)
4.1、查询语句
select 字段名1,字段名2,字段名3 … from 表名 [where 条件]
-- 查询员工表中员工编号,员工姓名,员工薪资 员工部门
select empno, ename,sal, deptno from emp
-- 查 询表中所有数据(* 表示所有列)
select * from emp;
-- 2.查询(EMP)员工编号、员工姓名、员工职位、员工月薪、工作部门编号。
select empno , ename, job, sal , deptno from emp ;
-- 算术运算符:可以在select语句中使用算数运运算符改变输出结果
-- 查询员工表中员工编号,员工名,和员工涨薪100块以后员工的薪资
select empno, ename, sal+100 from emp ;
-- 查询员工表中员工编号,员工姓名,员工薪资,入职日期,员工的年薪(月薪*12)
select empno, ename, sal, hiredate, sal*12 from emp;
-- 查询员工表中员工姓名,员工年薪(年薪+100元奖励)
select ename, sal * 12 + 100 from emp ;
-- 查询员工表总员工姓名,员工年薪(每个月增加100)
select ename, (sal+100) * 12 from emp;
-- 1.员工转正后,月薪上调20%,请查询出所有员工转正后的月薪。
select ename, sal* 1.2 from emp ;
-- 2.员工试用期6个月,转正后月薪上调20%,请查询出所有员工工作第一年的年薪所得(不考虑奖金部分,年薪的试用期6个月的月薪+转正后6个月的月薪)
select ename, sal * 6 + sal * 1.2 * 6 from emp;
补充
随机查询–rand()
SELECT
fbu.*,
fu.nickname,
fu.avatar,
fu.gender
FROM
fa_ball_userarticle AS fbu
LEFT JOIN fa_user AS fu ON fbu.user_id = fu.id
ORDER BY
RAND(fbu.createtime)
4.2、列别名
1、第一种带as
-- select 字段 as 名字, 字段 as 名字 ... from 表名
-- 查询员工表中员工编号,姓名,入职日期,部门编号,员工年薪(月薪* 12 + 奖金)
select empno as 'enum' , ename as '姓名' , hiredate as '日期',deptno as '部门编号',sal * 12 + ifnull(comm, 0) as '年薪'from emp ;
2、第二种不带as
-- 查询员工表中员工编号,姓名,入职日期,部门编号,员工年薪(月薪* 12 + 奖金)
select empno 'enum' , ename '姓名' , hiredate '日期',deptno '部门编号',sal * 12 + ifnull(comm, 0) '年 薪'from emp ;
例子
-- 1.员工试用期6个月,转正后月薪上调20%,请查询出所有员工工作第一年的所有收入(需考虑奖金部分),要求显示列标题为员工姓名,工资收入,奖金收入,总收入。
select ename as '姓名', sal as '工资收入', comm as '奖金', sal* 6+ sal* 1.2* 6 + ifnull(comm,0) as "年薪" from emp;
3、消除重复行 distinct
-- 查询有哪些部门?
select distinct deptno from emp ;
-- 查询员工表中一共有哪几种岗位类型
select distinct job from emp ;
4.3、where条件子句 —等值查询
作用:检索数据中符合条件的值
逻辑运算符
| 运算符 | 语法 | 描述 |
|---|---|---|
| and && | a and b a && b | 逻辑与,两个都为真,结果为真 |
| or || | a or b a || b | 逻辑或,其中一个为真,则结果为真 |
| Not ! | not a ! a | 逻辑非, 真为假,假为真! |
-- where 条件限定
-- 查询20号部门所有员工信息
select * from emp where deptno = 20;
-- 查询薪资大于3000 的员工编号,员工姓名,员工薪资 ,工作
select empno, ename, sal, job from emp where sal > 3000;
-- 查询没在20号部门工作的员工的姓名,员工职位,员工的入职日期,员工的部门编号
select ename , job, hiredate , deptno from emp where deptno <> 20;
select ename , job, hiredate , deptno from emp where deptno != 20;
-- 查询入职日期在'1982-1-1'之后的员工的姓名,职位。入职日期
select ename, job, hiredate from emp where hiredate > '1982-1-1'
-- .查询职位为SALESMAN的员工编号、职位、入职日期。
select empno, job, hiredate from emp where job = 'SALESMAN';
-- BETWEEN .. and 判断要比较的值是否在指定范围之内(包含头和尾)
-- 查询薪资在3000 到 5000 之间的员工编号, 姓名,薪资
select empno , ename, sal from emp where sal BETWEEN 3000 and 5000;
-- 查询入职日期在1985-1-1至1990-1-1之间的员工编号,员工姓名,员工薪资,员工入职日期
select empno, ename, sal, hiredate from emp where hiredate BETWEEN '1985-1-1' and '1990-1-1'
-- 判断要比较的值是否和集合列表中的任何一个值相等
-- 查询员工表中部门编号为10,20,30的员工编号,员工姓名,员工薪资,部门编号
select empno, ename, sal, deptno from emp where deptno in (10,20,30)
-- 查询员工表中职位是CLERK,MANAGER 的 员工信息
select * from emp where job in ("CLERK","MANAGER");
-- 查询工作地点在大连或者北京的部门信息
select * from dept where loc in ("北京","大连");
-- 查询领导是7839 或7788的员工姓名,员工编号,员工薪资,员工经理编号
select empno,ename, sal, mgr from emp where mgr in (7839, 7788)
-- 查询入职日期在82年至85年的员工姓名,入职日期。
select ename , hiredate from emp where hiredate BETWEEN '1982-1-1' and '1985-12-31'
4.4 、模糊查询:比较运算符
判断要比较的值是否部分匹配
| 运算符 | 语法 | 描述 |
|---|---|---|
| IS NULL | a is null | 如果操作符为NULL ,结果为真 |
| IS NOT NULL | a is not null | 如果操作符不为null,结果为真 |
| BETWEEN | a between b and c | 若 a 在 b 和 c 之间,则结果为真 |
| Like | a like b | SQL 匹配,如果a匹配b,则结果为真 |
| In | a in (a1,a2,a3…) | 假设a在a1,或者a2…其中的某一个值中,结果为真 |
例子
-- %:任意个数的任意字符
-- 查询名字中带有A的员工编号,员工姓名,员工入职日期
select empno, ename, hiredate from emp where ename like '%A%';
-- 查询名字是以张开头的员工姓名,员工薪资
select ename, sal from emp where ename like '张%';
-- _: 一个任意字符
-- 查询员工姓名中第二个字母是A的员工编号,姓名,薪资,入职日期
select empno, ename,sal , hiredate from emp where ename like '_A%'
-- 1.查询员工姓名以W开头的员工姓名。
select ename from emp where ename like 'W%'
-- 2.查询员工姓名倒数第2个字符为T的员工姓名。
select ename from emp where ename like '%T_';
-- 3.查询奖金为空的员工姓名,奖金。
select ename, comm from emp where comm is null
4.5、逻辑运算符 and or not
and 逻辑与,用来连接多个条件表达式。都是真则为真
-- 查询入职日期在81年之后,并且薪资大于3000的员工编号,姓名,入职日期,薪资
select empno, ename, hiredate, sal from emp where hiredate > "1981-12-31" and sal > 3000
or 逻辑或,用来连接多个条件表达式。 满足其中任意一个条件即可
-- 查询员工编号是7566 7369 7788 的员工信息
select * from emp where empno = 7566 or empno = 7369 or empno = 7788
-- 查询入职日期在81年之后,或者员工薪资大于3000的员工编号, 员工姓名,员工薪资 ,入职日期
select empno, ename, sal ,hiredate from emp where hiredate > '1981-12-31' or sal > 3000
not 非 用来否定
-- 查询薪资不在3000-5000之间的员工编号,姓名,薪资,入职日期
select empno, ename, sal, hiredate from emp where sal not BETWEEN 3000 and 5000
-- 查询不在20,30号部门工作的员工信息
select * from emp where deptno not in(20,30)
-- 查询有上级领导的员工信息
select * from emp where mgr is not null
4.6、排序 order by
作用:对查询的结果进行排序显示
升序 asc(默认)
降序 desc
-- 查询员工表中员工的编号,姓名,薪资,入职日期,要求按照薪资进行升序排序
select empno, ename, sal, hiredate from emp order by sal asc;
-- 查询员工表中员工编号,姓名 薪资 入职日期 部门编号,要去按照入职从近到远的时间排序
select empno , ename, sal, hiredate, deptno from emp order by hiredate desc;
-- 查询员工表中员工姓名和奖金 按照员工奖金降序排序(空值在升序排列中排在最前面,在降序排列中排在最后。)
select ename, comm from emp order by comm desc
-- 按照列别名排序
-- 查询员工表中员工姓名,员工薪资,员工的年薪(不考虑奖金) 要求按照年薪降序排序
select ename, sal, sal* 12 as yearSal from emp order by yearSal desc
select ename, sal, sal* 12 as yearSal from emp order by 3 desc -- 使用结果集的序列号排序
-- 多列参与排序
-- 查询员工姓名,部门编号,薪资 要求按照部门编号升序排序,薪资降序排序
select ename, deptno, sal from emp order by deptno , sal desc; -- (按照第一列进行排序,如果第一列相同按照第二列排序)
-- 1.查询部门在20或30的员工姓名,部门编号,并按照工资升序排序
select ename, deptno, sal from emp where deptno in (20,30) order by sal ;
-- 2.查询工资在2000-3000之间,部门不在10号的员工姓名,部门编号,工资,并按照部门升序,工资降序排序
select ename, deptno, sal from emp where sal BETWEEN 2000 and 3000 and deptno != 10 order by deptno asc, sal desc;
-- 3.查询入职日期在82年至83年之间,职位以SALES或者MAN开头的员工姓名,入职日期,职位,并按照入职日期降序排序。
select ename, hiredate, job from emp where hiredate BETWEEN '1982-1-1' and '1982-12-31' and (job like 'SALES%' or job like 'MAN%' ) order by HIREDATE desc;
4.7、限制记录行数–limit ------分页
分页:缓解数据库压力,给人的体验更好,瀑布流 (抖音)
select 字段 from 表 limit m,n; -- m表示从哪个位置开始取(0是起始位),n表示取几个
-- 查询员工表中前5名员工的信息
select * from emp limit 1,5
-- 从第3个位置起查询5个数据
select * from emp limit 2,5
-- 分页操作(当前页-1)* 每页显示条数
-- 查询第二页内容 每页显示5条
select * from emp limit (2-1)*5, 5 -- 不能用公式 必须是数字
select * from emp limit 5, 5
-- 查询入职日期最早的前5名员工姓名,入职日期。
select ename , hiredate from emp ORDER BY HIREDATE asc limit 0,5
4.8、 连表查询 join(对比 )
INNER JOIN 等值连接
INNER JOIN -- 等值连接

Right Join 右外连接
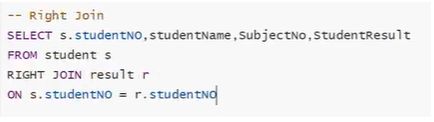
Left Join 左外连接

| 操作 | 描述 |
|---|---|
| Inner join | 如果表中至少有一个匹配,就返回行 |
| left join | 会从左表中返回所有的值,即使右表中没有匹配 |
| right join | 会从右表中返回所有的值,即使左表中没有匹配 |
- 总结
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qdNEBkwo-1624937364978)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210610180959541.png)]
- 拓展
-- 标准连接语法
-- 交叉连接:使用CROSS JOIN 子句完成。
-- 查询员工表,部门表所有信息
select * from emp cross join dept
-- 自然连接
-- 自然连接:使用NATURAL JOIN子句来完成。
-- 查询员工表,部门表所有信息
select * from emp NATURAL join dept
-- USING子句
-- 查询员工表,部门表所有信息
select * from emp join dept using(deptno)
-- ON子句:指定任意连接条件,或指定要连接的列,则可以使用ON子句(提高代码可读性)
-- 查询员工表,部门表所有信息
select * from emp e join dept d on e.empno = d.deptno
-- 外部连接
-- 左外连接left join(以FROM子句中的左边表为基表,该表所有行数据按照连接条件无论是否与右边表能匹配上,都会被显示出来)
-- 查询没有雇员工作的部门
select * from dept left join emp on dept.deptno = emp.deptno
-- 右外连接right join (以FROM子句中的右边表为基表,该表所有行数据按照连接条件无论是否与左边表能匹配上,都会被显示出来)
-- 查询没有雇员工作的部门
select * from emp right join dept on dept.deptno = emp.deptno
-- 查询所有雇员姓名,部门编号,部门名称,包括没有部门的员工也要显示出来
-- 左外连接
select ename, emp.deptno, dname from emp left join dept on dept.deptno = emp.deptno
5、函数
1、数学函数
(重点:切割、截取、替换)
1、聚合函数
见 7、常用分组函数
| 函数名称 | 描述 |
|---|---|
| count() | 计数 |
| SUM() | 求和 |
| AVG() | 平均值 |
| MAX() | 最大值 |
| MIN() | 最小值 |
| … | … |
2、常用函数
====================较常用函数======数学运算=========================
-- 求绝对值
select abs(-1)
select abs(sal) from emp;
-- 返回大于或者等于x的最小整数值(向上取整)
select CEIL(4.123)
-- 返回小于或者等于x的最大整数值(向下取整)
select FLOOR(4.123)
-- 返回保留小数点后面y位,四舍五入的整数
select ROUND(4.125,2)
-- 返回被舍弃的小数点后y位的数字x;
select TRUNCATE(4.125,2)
-- RAND():每次产生不同的随机数;
select rand()
-------------------------------不常用----------------------------
select SQRT(4); -- 返回非负数x的平方根;
select PI(); -- PI():返回圆周率;
select MOD(5,3); -- MOD(x,y)或%:返回x被y除的余数;
select SIGN(-4) -- SIGN(x):返回参数的符号;
select pow(2,3) -- 返回x的y次乘方的结果值;
select EXP(2); -- 返回以e为底的x乘方后的值;
select log(2) -- 返回x的自然对数,x相对于基数e的对数;
=========================字符串函数=================================
select LENGTH("mysql") -- 返回字符串str的长度;
select CHAR_LENGTH("mysql") -- 返回字符串str的所包含字符个数
select CONCAT("abc","***",null); -- 字符串连接(拼接)(如果有null,结果为null)
select CONCAT_WS(",","张三","李四","王五")
-- 插入字符串INSERT(s1,x,len,s2)
-- 第一个数字表示位置(1开始) 第二个数字表示原字符串的替换的个数
select INSERT("mysql",3,2,"data")
select LOWER("ABC"); -- 字符串转换为小写
select UPPER("abc"); -- 字符串转换为大写
select INSTR('student','d') -- 返回第一次出现的子串的索引
-- 替换出现的指定字符串
-- 字符串替换函数REPLACE(s,s1,s2):将s字符串中的s1字符替换成s2。
select REPLACE("i like mysql","like","喜欢")
-- 返回的指定的子字符串(原字符串, 截取的位置, 截取的长度)
-- 获取子串函数:SUBSTRING(s,n,len)带有len参数的格式从字符串s返回一个长度同len字符相同的子字符串,起始于位置n。
select substring("String",2,3);
select REVERSE("abc") -- (反转)字符串逆序函数REVERSE(s)
select ELT(2,"I","like","mysql") -- 返回指定位置的字符串
-------------------------不常用-------------------------------------
-- 显示所有员工姓名的前三个字符
select left(ename , 3) from emp
-- 获取指定长度的字符串的函数:LEFT(s,n)返回字符串s开始的最左边n个字符
select left("I like mysql",3);
-- 填充字符串函数:LPAD(s1,len,s2)返回字符串s1,其左边由字符串s2填补到len字符长度
select lpad("mysql",10,"*")
-- 删除字符串空格函数:LTRIM(s)返回字符串s,字符串左侧空格字符被删除。RTRIM(s)返回字符串s,字符串右侧空格字符被删除。
select LTRIM(" myql ")
-- 重复生成字符串函数
select REPEAT("abc",4);
-- 空格函数SPACE(n):返回一个由n个空格组成的字符串
select SPACE(3)
====================常用========时间和日期函数===================
select CURRENT_DATE() -- 获取当前日期;
select CURDATE() -- 获取当前日期;
select NOW() -- 返回服务器的当前日期和时间
SELECT LOCALTIME() -- 本地时间
select CURTIME() -- CURTIME():返回当前时间,只包含时分秒
SELECT SYSDATE() -- 系统时间
-- 选取日期时间的各个部分
SELECT year(now());
SELECT MONTH(now());
SELECT DAY(now());
SELECT HOUR(now());
SELECT MINUTE(now());
SELECT SECOND(now());
select TIMEDIFF("18:10:10","6:10:00") -- 返回两个日期相减相差的时间数
select DATEDIFF("2020-10-27","1990-10-10") -- 返回两个日期相减相差的天数
-- 计算日期和时间的函数,分别为给定的日期date加上(add)或减去(sub)一个时间间隔值expr
select date_add(NOW(), INTERVAL 1 Day)
==========================================================================
-- 流程控制函数
SELECT CASE 11
WHEN 11 THEN 'one'
WHEN 2 THEN 'two'
ELSE 'more' END;
SELECT CASE WHEN 1>0 THEN 'true' ELSE 'false' END;
-- 查询员工表中员工姓名,员工薪资,薪资列要求大于3000的显示high 否则显示low
select ename , sal , case when sal > 3000 then 'high' else 'low' end from emp ;
-- 流程控制函数
SELECT IF(1>2,2,3);
-- 其他函数
select user();
-- Inet_aton():给出一个作为字符串的网络地址的点地址表示,返回一个代表该地址数值的整数
select INET_ATON("127.0.0.1")
-- Inet_ntoa():给定一个数字网络地址, 返回作为字符串的该地址的点地址表示。
select INET_NTOA("2130706433")
-- 密码加密技术
select PASSWORD("123456"),MD5("123456");
6、多表连接
1. 连接:
-
是在多个表之间通过一定的连接条件,使表之间发生关联关系,进而取得多个表的数据
-
select 字段 from 表名 where a.字段= b.字段
-- 查询员工姓名,部门名称,部门工作点(出现笛卡尔积现象)
select ename, dname, loc from emp,dept
2. 笛卡尔积现象:
- 第一个表中的所有行数据和第二个表的每一行数据都发生连接(开发应该避免)
- 出现笛卡尔积现象的原因:1、连接条件被省略 2、连接条件无效
-- 查询员工表和部门表中所有有效信息
select * from emp , dept where emp.deptno = dept.deptno
-- 查询员工编号 员工姓名 员工入职日期 员工薪资 部门编号 员工部门名称 工作地点
select empno, ename, hiredate , sal , emp.deptno, dname, loc from emp , dept where emp.deptno = dept.deptno
-- 现在只想查询工作地点在NEW YORK的员工编号,姓名,部门编号,工作地点
select empno, ename, emp.deptno, loc from emp , dept where emp.deptno = dept.deptno and loc = "NEW YORK"
3. 表的别名(带as 不带as)
-- 查询员工编号,姓名,部门编号,工作地点
select empno, ename, e.deptno, loc from emp as e , dept as d where e.deptno = d.deptno;
-- 写一个查询,显示所有姓名中含有A字符的员工姓名,工作地点。
select ename, loc from emp e , dept d where e.deptno = d.deptno and ename like '%A%';
-- 查询每个员工的姓名,工资,工资等级(不等值连接)
select ename, sal, grade from emp e, salgrade s where sal BETWEEN losal and HISAL
-- 1.查询每个员工的编号,姓名,工资,工资等级,所在工作城市,按照工资等级进行升序排序
select empno,ename,sal, grade , loc FROM emp e , dept d,salgrade s where e.deptno = d.deptno and sal BETWEEN LOSAL and HISAL order by grade asc;
4. 自身连接
- 也叫自连接,是一个表通过某种条件和本身进行连接的一种方式,就如同多个表连接一样
- 自己的表和自己的表连接,核心:一张表拆成两张一样的表即可
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RqzWOWa9-1624937364979)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611104709979.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wZegP4lp-1624937364979)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611104723838.png)]
-- 查询每个员工的姓名和直接上级姓名?
select w.ename, m.ename from emp w , emp m where w.mgr = m.empno
-- 1.查询所有工作在NEW YORK和CHICAGO的员工姓名,员工编号,以及他们的经理姓名,经理编号。
SELECT
w.ename,
w.empno,
m.ename,
m.empno
FROM
emp w,
emp m,
dept d
WHERE
w.mgr = m.empno
AND w.deptno = d.deptno
AND d.loc IN ( "NEW YORK", "CHICAGO" )
7、分组函数
- 分组函数是对数据行的集合进行操作并按组给出一个结果,这个结果可直接输出,或者用来做判断条件。
- sum 求和 avg求平均值(注意:null值不参与运算,可以使用ifnull解决) 指针对数字
1、 常用分组函数吗
- sum avg min max count
-- 求查询职位是“MANAGER”每个月工资总和,平均奖金?
select sum(sal),avg(ifnull(comm,0)) from emp where job="MANAGER";
-- min 求最小值 max求最大值
-- 查询员工表中最高薪资和最低薪资 既可以是数字还可以是日期
select max(sal),min(sal)from emp
-- count:查询人数
-- 查询员工表中员工人数
select count(*) from emp
select count(empno) from emp -- 查询的优化
-- 创建数据组 group by
-- 查询每个部门的薪资总和,平均薪资
select sum(sal), avg(sal),deptno from emp group by deptno
-- 查询每个部门的最高薪资 最低薪资 部门人数
select max(sal), min(sal), count(empno) from emp GROUP BY deptno;
-- 查询每个岗位的工资总和。
select sum(sal),job from emp group by job;
-- 查询每个部门每个岗位的工资总和。
select sum(sal) ,deptno, job from emp group by deptno , job;
-- 1.查询每个部门的部门编号,部门名称,部门人数,最高工资,最低工资,工资总和,平均工资
select e.deptno, dname, count(empno), max(sal), min(sal), sum(sal), avg(sal) from emp e join dept d on e.deptno = d.deptno GROUP BY e.deptno
-- 查询每个经理所管理的人数,经理编号,经理姓名,要求包括没有经理的人员信息。
select count(e.empno), e.mgr, m.ename from emp e left join emp m on e.mgr = m.empno GROUP BY e.mgr
-- 排除组结果
-- 查询每个部门最高工资大于2900的部门编号,最高工资(分组函数不能和where连用)
select deptno, max(sal) from emp group by deptno having max(sal) > 2900
-- 查询每个职位的薪资总和大于5000的薪资总和,要求职位不能是sales开头的,并且最终按照薪资总和进行降序排序
select sum(sal), job from emp where job not like 'sales%' group by job having sum(sal) > 5000 order by sum(sal) desc
-- 1.查询部门人数大于2的部门编号,部门名称,部门人数。
select e.deptno, dname, count(e.empno) from emp e join dept d on e.deptno = d.deptno GROUP BY e.deptno having count(e.empno) > 2
2、子查询
- 单行子查询 > < >= <= <>
-- 查询出比JONES为雇员工资高的其他雇员
select * from emp where sal > (select sal from emp where ename = "JONES");
-- 比职位是manager的最低薪资还低的员工的信息
select * from emp where sal < (select min(sal) from emp where job= "MANAGER")
-- 显示和雇员7369从事相同工作并且工资大于雇员7876的雇员的姓名和工作。
select ename, job ,sal
from emp
where
job = (select job from emp where empno = 7369)
and
sal > (select sal from emp where empno = 7876)
-- 查询工资最低的员工姓名,岗位及工资
select ename, job, sal from emp where sal = (select min(sal) from emp)
-- 查询部门最低工资比20部门最低工资高的部门编号及最低工资
select deptno, min(sal) from emp group by deptno having min(sal) > (select min(sal) from emp where deptno = 20)
- 多行子查询 in all any
-- 查询是领导的员工姓名,工资
select ename, sal from emp where empno in (select mgr from emp)
-- 查询每个部门最低薪资的员工编号,员工姓名
select empno, ename ,sal from emp where sal in (select min(sal) from emp GROUP BY deptno)
-- ANY的使用:表示和子查询的任意一行结果进行比较,有一个满足条件即可
-- < ANY:表示小于子查询结果集中的任意一个,即小于最大值就可以。
-- > ANY:表示大于子查询结果集中的任意一个,即大于最小值就可以。
-- = ANY:表示等于子查询结果中的任意一个,即等于谁都可以,相当于IN。
-- 查询部门编号不为20,且工资比20部门任意一名员工工资高的员工编号,姓名,职位,工资。
select empno, ename, job , sal from emp where deptno != 20 and sal >any (select sal from emp where deptno = 20)
-- ALL:表示和子查询的所有行结果进行比较,每一行必须都满足条件
-- < ALL:表示小于子查询结果集中的所有行,即小于最小值。
-- > ALL:表示大于子查询结果集中的所有行,即大于最大值。
-- = ALL :表示等于子查询结果集中的所有行,即等于所有值,通常无意义
-- 查询部门编号不为20,且工资比20部门所有员工工资高的员工编号,姓名,职位,工资
select empno , ename, job, sal from emp where deptno != 20 and sal >all (select sal from emp where deptno = 20 )
-- 注意:只要空值有可能成为子查询结果集合中的一部分,就不能使用NOT IN 运算符。因为null 和所有条件比较都是空
-- 查询不是经理的员工姓名。
select ename from emp where empno not in(select mgr from emp ) -- ifnull 作业
-- 在 FROM 子句中使用子查询
-- 查询比自己部门平均工资高的员工姓名,工资,部门编号,部门平均工资
SELECT
ename,
sal,
a.deptno,
b.avg
FROM
emp a,
( SELECT deptno, avg( sal ) AS avg FROM emp GROUP BY deptno ) AS b
WHERE
a.deptno = b.deptno
AND a.sal > b.avg
3、MD5 加密
数据库级别的MD5加密(扩展)
- 主要增强算法复杂度和不可逆转性。
- MD5不可逆,具体的值的md5是一样的
- MD5破解网站的原理,背后有一个字典,MD5加密后的值,加密的前值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pn2o55N7-1624937364980)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611152404042.png)]
4、总结select
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hjNAwCvO-1624937364980)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611152907371.png)]
8、视图和索引
1、视图:
逻辑上来自一个或者多个表的集合(虚拟的表–临时存放用户给展示的表)
- 创建
-- 创建视图
create view 视图名
as select 字段 from 表 [where条件]
-- 创建一个视图v_emp20,通过该视图只能查看20号部门的员工编号,员工姓名,职位, 部门编号
create or REPLACE view v_emp20 -- or REPLACE 修改表结构
as select empno, ename, job, deptno from emp where deptno = 20
-- 创建一个视图,通过该视图可以查询到工资在2000-5000内并且姓名中包含有A的员工编号,姓名,工资
create view v_empsal
as select empno , ename, sal from emp where sal BETWEEN 2000 and 5000 and ename like '%A%';
-- 在创建视图时候,子查询中可以使用别名
-- 创建一个视图,通过该视图可以查询到员工编号。姓名,员工薪资,入职日期 要求82年之后的员工信息
create view v_empyear
as select empno num , ename xm, sal xz , hiredate rdate from emp where hiredate > '1982-12-31'
-- 创建复杂视图
-- 例:创建一个视图,通过该视图可以查看每个部门的名称,最低工资,最高工资,平均工资
create view v_emp
as select dname, min(sal), max(sal), avg(sal) from emp e cross join dept d on e.deptno = d.deptno GROUP BY e.deptno
- 查询
-- 查询视图v_emp中 所有信息
select * from v_emp
-- 视图上执行DML操作(会影响基表数据)
-- 删除操作
-- 通过视图删除表中姓名是JONES的员工
delete from v_emp20 where ename = "JONES"
-- 创建一个视图,通过视图可以查询每个部门的最低薪资,部门编号
create view v_minSal
as select deptno, min(sal)from emp group by deptno
-- 修改操作
-- 修改v_emp20视图中ADAMS的部门编号改为10
update v_emp20 set deptno = 10 where ename = "ADAMS"
-- 插入操作
-- 向v_emp20视图中国插入编号为9999姓名为李四,部门编号为20的员工信息
insert into v_emp20 (empno, ename, deptno) values(9999, "李四",20)
-- 删除视图:
drop view v_minsal
2、索引
MySQL 官方对索引的定义为: 索引(Index)时帮助MySQL高效获取数据的数据结构。
在一个表中,主键索引只能有一个,唯一索引可以有多个
提取句子主干,就可以得到索引的本质:索引是数据结构。
-- 创建索引
-- 创建普通索引
create table index1(
id int,
name varchar(20),
sex boolean,
Index(id)
)
-- 创建唯一性索引
create table index2(
id int unique,
name varchar(20),
UNIQUE index index2_id(id asc)
)
-- 全文索引
create table index3(
id int,
info varchar(20),
FULLTEXT index index3_info(info)
)ENGINE = myisam;
-- 单列索引
create table index4(
id int,
subject varchar(30),
index index4_st(SUBJECT(10))
)
-- 多列索引
create table index5(
id int,
name varchar(20),
sex char(4),
index index5_ns(name, sex)
)
-- 空间索引
create table index6(
id int,
space geometry not null,
SPATIAL index index6_sp(sapce)
)ENGINE=myisam
-- 删除索引
-- DROP INDEX 索引名 ON 表名 ;
3、测试索引
索引在小数据量的时候,用户不大,但是在大数据的时候,区别十分明显~
4、索引原则
- 索引不是越多越好
- 不要对进程变动数据加索引
- 小数据量的表不需要加索引
- 索引一般加在常用来查询的字段上!
9、事务
-
是一个工作单元,由一个或者多个sql语句组成,执行的时候要么都成功,要么都失败。由此保持数据的一致性。
-
事务处理语言:简称TPL
**commit:**对结果进行确认提交
**rollback:**对结果进行回滚
1、 事务的四个特性**(ACID)**:
原子性:(Atomicity)
要么都成功,要么都失败
一致性: (Consistency)
事务前后的数据完整性要保持一致
隔离性: (Isolation)
事物的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启事务,不会被其他事务的操作数据所干扰,事物之间要相互隔离。
持久性(事务提交): (Durability)
事务一旦提交则不可逆转,被初始化到数据库中!
-- 开启事务--标记一个事务的开始,从这个之后的sql都在同一个事务内
BEGIN 或者 START TRANSACTION
eg:
START TRANSACTION ;
-- 事务代码
commit;
-- 更新用户名
update t_user set usernaME='JACK' WHERE ID=1;
commit;
update dept set loc = '大连' where deptno = 1; -- 修改1号部门工作地点在大连
delete from dept where deptno = 2; -- 删除2号部门的信息
-- 提交: 持久化(成功!)
COMMIT;
-- 回滚数据: 回到的原来的样子(失败!)
-- ROLLBACK;
-- 事务结束
set autocommit = 1 -- 开启自动提交
-- mysql默认是自动提交的,也就是运行一个sql语句会,会自动提交执行
set autocommit = 0 禁止自动提交
set autocommit = 1 开启自动提交
2、事物的隔离所导致的问题
1、脏读:
指一个事务读取了另外一个事务未提交的数据。
2、不可重复读:
在一个事务内读取表中的某一行数据,多次读取结果不同,(这个不一定是错误,只是某些场合不对)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0NivqKFk-1624937364980)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611154201249.png)]
3、虚读(幻读)
是指在一个事务内读取到了别的事物插入的数据,导致前后读取不一致。(一般是行影响,多了一行)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7gtrgcyG-1624937364981)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611154353400.png)]
10、权限管理和备份
10.1、用户管理
-- 创建用户 CREATE USER 用户名 identified by '密码'
CREATE USER zwzyaya identified by '123456'
-- 修改密码 (修改当前用户密码)
SET PASSWORD = PASSWORD('123456')
-- 修改密码 (修改指定用户密码)
SET PASSWORD FOR zwzyaya = PASSWORD('123456')
-- 重命名 RENAME USER 原名 TO 新名
RENAME USER zwzyaya TO zwzhaha
-- 用户授权 ALL PRIVILEGES 全部的权限, 库 ,表
-- ALL PRIVILEGES 除了给别人授权,其他都能够干
GRANT ALL PRIVILEGES ON *.* TO zwzhaha
-- 查询权限
SHOW GRANTS FOR zwzhaha -- 查看指定用户的权限
SHOW GRANTS FOR root@localhost
-- ROOT 用户权限: GRANT ALL PRIVILEGES ON *.* TO 'root'@'localhost' WITH GRANT OPTION
-- 撤销权限 REVOKE 那些权限, 在哪个库撤销,给谁撤销
REVOKE ALL PRIVILEGES ON *.* FROM zwzhaha
-- 删除用户
DROP USER zwzhaha
10.2、MySQL备份
- 保证重要的数据不丢失
- 数据转移
备份的方式:
-
直接拷贝物理文件(data)
-
在Sqlyog这种可视化工具中手动导出
- 在想要导出的表或者库中,右键,选择备份或导出或转储选择结构和数据导出
-
使用命令行导出 mysqldump 命令行使用
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cdRSkId4-1624937364981)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210611174711567.png)]
11、规范数据库设计
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JHQqHJFk-1624937364982)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615102635010.png)]
三大范式(了解)— 有弊端(性能低 数据冗余)
第一范式(1NF)
原子性:保证每一不可再分
第二范式(2NF)
前提:满足第一范式
每张表只描述一件事情
第三范式(3NF)
前提:满足第一范式 和 第二范式
第三范式需要确保数据表中每一列数据都和主键直接相关,而不能间接相关。
(规范数据库的设计)
规范性 和 性能的问题(解决三大范式的弊端)
关联查询的表不得超过三张表
- 考虑商业化的需求和目标,(成本,用户体验!) 数据库的性能更加重要
- 在规范性能的问题的时候,需要适当的考虑一下规范性!
- 故意给某些表增加一些冗余的字段,(从多表查询中变为单表查询)
- 故意增加一些计算列(从大数据量降低为小数据量查询:索引)
12、JDBC(重点)
12.1、数据库驱动
驱动:声卡、显卡、数据库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2JhJIcpt-1624937364982)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615112256783.png)]
我们的程序会通过数据库 驱动,和数据库打交道!
12.2、JDBC
-
SUN公司为了简化开发人员的(对数据库的统一)操作, 提供了一个(java操作数据库的)规范,俗称JDBC
-
这些规范的实现由具体的厂商去做~
-
对于开发人员来说,我们只需要掌握 JDBC集接口的操作即可!
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-msJgOzV2-1624937364983)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615112405635.png)]
java.sql
javax.sql
数据库驱动包
步骤总结:
- 加载驱动
- 连接数据库 DriverManager
- 获得执行sql的对象 Statement
- 获得返回的结果集
- 释放链接
DriverManager
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QolGfTOX-1624937364983)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615115216541.png)]
URL
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fHXKW7ca-1624937364984)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615115246314.png)]
Statement 执行 SQL 的对象
PrepareStatement 执行 SQL 的对象
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qt4VGqhQ-1624937364984)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615115544391.png)]
ResultSet 查询的结果集:封装了所有的查询结果
获得指定的数据类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OhFCrPl4-1624937364984)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615115810393.png)]
遍历
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-U6kvDRu4-1624937364985)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615120122839.png)]
释放资源
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-re2IWiVv-1624937364985)(C:\Users\peisenjiayuan\AppData\Roaming\Typora\typora-user-images\image-20210615120210136.png)]
– 删除用户
DROP USER zwzhaha
#### 10.2、MySQL备份
- 保证重要的数据不丢失
- 数据转移
备份的方式:
- 直接拷贝物理文件(data)
- 在Sqlyog这种可视化工具中手动导出
- 在想要导出的表或者库中,右键,选择备份或导出或转储选择结构和数据导出
- 使用命令行导出 mysqldump 命令行使用
[外链图片转存中...(img-cdRSkId4-1624937364981)]
## 11、规范数据库设计
[外链图片转存中...(img-JHQqHJFk-1624937364982)]
> 三大范式(了解)--- 有弊端(性能低 数据冗余)
**第一范式(1NF)**
原子性:保证每一不可再分
**第二范式(2NF)**
前提:满足第一范式
每张表只描述一件事情
**第三范式(3NF)**
前提:满足第一范式 和 第二范式
第三范式需要确保数据表中每一列数据都和主键直接相关,而不能间接相关。
(规范数据库的设计)
**规范性 和 性能的问题**(解决三大范式的弊端)
关联查询的表不得超过三张表
- 考虑商业化的需求和目标,(成本,用户体验!) 数据库的性能更加重要
- 在规范性能的问题的时候,需要适当的考虑一下规范性!
- 故意给某些表增加一些冗余的字段,(从多表查询中变为单表查询)
- 故意增加一些计算列(从大数据量降低为小数据量查询:索引)
## 12、JDBC(重点)
#### 12.1、数据库驱动
驱动:声卡、显卡、数据库
[外链图片转存中...(img-2JhJIcpt-1624937364982)]
我们的程序会通过数据库 驱动,和数据库打交道!
#### 12.2、JDBC
- SUN公司为了简化开发人员的(对数据库的统一)操作, 提供了一个(java操作数据库的)规范,俗称JDBC
- 这些规范的实现由具体的厂商去做~
- 对于开发人员来说,我们只需要掌握 JDBC集接口的操作即可!
[外链图片转存中...(img-msJgOzV2-1624937364983)]
java.sql
javax.sql
数据库驱动包
步骤总结:
1. 加载驱动
2. 连接数据库 DriverManager
3. 获得执行sql的对象 Statement
4. 获得返回的结果集
5. 释放链接
> DriverManager
[外链图片转存中...(img-QolGfTOX-1624937364983)]
> URL
[外链图片转存中...(img-fHXKW7ca-1624937364984)]
> Statement 执行 SQL 的对象
>
> PrepareStatement 执行 SQL 的对象
[外链图片转存中...(img-qt4VGqhQ-1624937364984)]
> ResultSet 查询的结果集:封装了所有的查询结果
**获得指定的数据类型**
[外链图片转存中...(img-OhFCrPl4-1624937364984)]
遍历
[外链图片转存中...(img-U6kvDRu4-1624937364985)]
> 释放资源
[外链图片转存中...(img-re2IWiVv-1624937364985)]