代码随想录刷题-链表-相交链表
文章目录
-
- 相交链表
-
- 习题
- 题目说明
- 暴力解法
- 进阶解法
- 双指针解法
相交链表
本节对应代码随想录中:代码随想录,暂无讲解视频
习题
题目链接:160. 相交链表 - 力扣(LeetCode)
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:

题目数据保证整个链式结构中不存在环。
注意,函数返回结果后,链表必须保持其原始结构。
自定义评测:
评测系统的输入如下(你设计的程序不适用此输入):
- intersectVal - 相交的起始节点的值。如果不存在相交节点,这一值为 0
- listA - 第一个链表
- listB - 第二个链表
- skipA - 在 listA 中(从头节点开始)跳到交叉节点的节点数
- skipB - 在 listB 中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被视作正确答案。
示例 1:
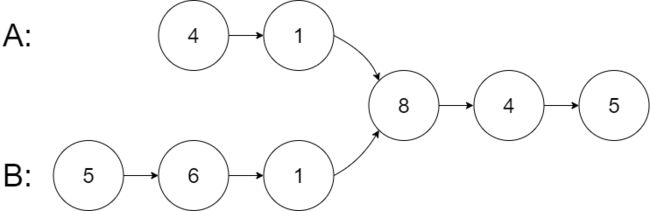
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at ‘8’
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
题目说明
相信会有不少小伙伴看到题目会有点疑惑,尤其是在代码随想录中跳转到的 面试题 02.07. 链表相交 - 力扣(LeetCode) 这个题目,两个题是一样的,只不过 160. 相交链表 - 力扣(LeetCode)的题目描述更加清楚。
上面的示例,不少人刚看到会疑惑为什么相交的节点不是1?而是8。注意题目中说的是节点相同,示例中 A 的1和 B 的1是地址不一样,只不过两个地址的数值是一样的。比如 A 中的节点1的地址0x1111,而 B 中的节点1的地址为0x2222。A 中的节点4的 next 指向的是地址为0x1111的数值为1的节点,而 B 中的节点6的 next 指向的是地址为0x2222的数值为1的节点。而节点8是两个链表相交的节点,因为两个链表中节点8的地址是一样的。
至于怎么判断两个节点是否相同,只需判断两个指针是否相同即可,如 curA==curB,如果你用 curA->val==curB->val 进行判断就会导致上面的例子程序输出1而不是正确答案8。
并且在本地的代码和官方的评测系统是不一样的,就是说你创建了上面示例的两个链表,数值相同的节点地址不一定是相同的,而评测系统根据 skipA 和 skipB 参数会找到正确的结果。因此在本地运行极有可能得不到正确答案,要在评测系统上提交才行。
暴力解法
这种解法简单粗暴,既然要判断是否有相交的节点。那我们直接遍历链表 A 的每个节点,对于每个节点,分别遍历 B 中的各个节点看看是否有和当前节点相同的节点,只要相同,说明后续节点肯定都一样,直接返回当前节点即可。
curA == curB 说明节点相同,并且地址也相同,那么 curA 和 curB 的后续 next 肯定都相同
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* curA = headA;
ListNode* curB = headB;
while(curA!=nullptr){
curB = headB;
while(curB!=nullptr){
if(curA == curB){
return curA;
}
curB = curB->next;
}
curA = curA->next;
}
return nullptr;
}
};
- 时间复杂度:O(mn)。其中m和n分别为链表headA和headB的长度。因为算法需要遍历headA和headB中的所有节点,时间复杂度与链表长度成正比。
- 空间复杂度:O(1)。因为算法只使用了常数级别的额外空间,即两个指针变量。无论输入的链表有多长,算法所需的额外空间都是固定的,与链表长度无关。
进阶解法
如图,如果两个链表相交,那么它们的后面几个节点一定是相同的。那么我们就可以先让节点数多的那个链表向后移动两个链表节点数量的差值。在下图中就是 B 中的指针 curB 先移动到 b2位置,curA 指针指向 a1,然后两个指针每次都向后移动一个位置,判读两个指针是否相等。当相等的时候,说明节点相同,返回当前指针。
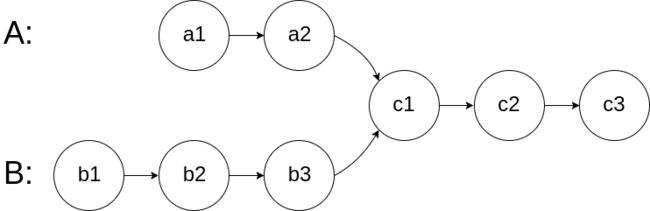
代码如下,大致思路就是先计算两个链表的长度,然后将两个指针分别向后移动对应的步数(节点数少的移动步数为0),最后 while 循环判断指针是否相等,不等就分别向后移动一个位置。
class Solution {
public:
ListNode* getIntersectionNode(ListNode* headA, ListNode* headB) {
int sizeA = 0, sizeB = 0;
ListNode* dummyHeadA = new ListNode(0,headA);
ListNode* dummyHeadB = new ListNode(0,headB);
ListNode* curA = dummyHeadA;
ListNode* curB = dummyHeadB;
// 计算两个单链表的长度,循环结束后curA和curB指向的是各自链表最后一个节点
while (curA->next != nullptr) {
curA = curA->next;
sizeA++;
}
while (curB->next != nullptr) {
curB = curB->next;
sizeB++;
}
// 如果两个链表的最后一个节点不同,说明一定没有相交的节点
if (curA != curB)
return nullptr;
curA = headA;
curB = headB;
// 计算两个指针移动的步数
int moveA = sizeA > sizeB ? sizeA - sizeB : 0;
int moveB = sizeB > sizeA ? sizeB - sizeA : 0;
// 两个指针分别移动各自的步数
for (int i = 0; i < moveA; i++)
curA = curA->next;
for (int i = 0; i < moveB; i++)
curB = curB->next;
// 开始向后遍历,当两个节点相同时则返回
while (curA != nullptr) {
if (curA == curB) {
return curA;
}
curA = curA->next;
curB = curB->next;
}
return nullptr;
}
};
- 时间复杂度:O(m+n)。其中m和n分别为链表headA和headB的长度。因为算法需要遍历headA和headB中的所有节点,时间复杂度与链表长度成正比。
- 空间复杂度:O(1)。因为算法只使用了常数级别的额外空间,即四个指针变量和两个虚拟头节点。无论输入的链表有多长,算法所需的额外空间都是固定的,与链表长度无关。
双指针解法
该双指针解法来源于 LeetCode 官方题解:相交链表 - 相交链表 - 力扣(LeetCode)。和上面的进阶解法其实是一个思路,只不过官方的题解太简洁了!
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
if (headA == nullptr || headB == nullptr) {
return nullptr;
}
ListNode *pA = headA, *pB = headB;
while (pA != pB) {
pA = pA == nullptr ? headB : pA->next;
pB = pB == nullptr ? headA : pB->next;
}
return pA;
}
};
- 时间复杂度:O(m+n)。其中m和n分别为链表headA和headB的长度。因为算法需要遍历headA和headB中的所有节点,时间复杂度与链表长度成正比。
- 空间复杂度:O(1)。因为算法只使用了常数级别的额外空间,即两个指针变量。无论输入的链表有多长,算法所需的额外空间都是固定的,与链表长度无关。
首先,判断了特殊情况,即链表 headA 或链表 headB 为空的情况,如果其中一个链表为空,则说明它们没有相交节点,直接返回 nullptr。
接着,定义了两个指针 pA 和 pB,分别指向链表 headA 和链表 headB 的头节点。
然后,代码进入循环,判断 pA 和 pB 是否指向同一个节点,如果不是则继续循环。在循环中,pA 和 pB 分别向后移动一个节点,如果移动到链表的末尾,则将其指向另一个链表的头节点,这样可以保证两个指针同时遍历链表 headA 和链表 headB,直到找到相交节点或者遍历完所有节点。
最后,代码返回 pA 或 pB,因为它们指向的是相交节点。如果没有相交节点,则返回 nullptr。
其中的 pA = pA == nullptr ? headB : pA->next; 可以写成如下代码:
if (pA == nullptr) {
pA = headB;
} else {
pA = pA->next;
}
至于为什么遍历完自己的链表后将指针指向另一个链表的头部就能同时到达相交的节点,理由如下:
链表 headA 和 headB 的长度分别是 m 和 n。假设链表 headA 的不相交部分有 a 个节点,链表 headB 的不相交部分有 b 个节点,两个链表相交的部分有 c 个节点,则有 a+c=m, b+c=n。
指针 pA 会遍历完链表 headA,指针 pB 会遍历完链表 headB,两个指针不会同时到达链表的尾节点,然后指针 pA 移到链表 headB 的头节点,指针 pB 移到链表 headA 的头节点,然后两个指针继续移动,在指针 pA 移动了 a+c+b 次、指针 pB 移动了 b+c+a 次之后,两个指针会同时到达两个链表相交的节点,该节点也是两个指针第一次同时指向的节点,此时返回相交的节点。
如果链表不相交,在指针 pA 移动了 m+n 次、指针 pB 移动了 n+m 次之后,两个指针会同时变成空值 null,此时返回 null。也就是说两个指针都最多走 m+n 次。
理由解释来自 LeetCode 官方
举个例子,链表 headA 的节点为 1 2 7 8,链表 headB 的节点为 4 5 6 7 8。则 a = 2,b=3,c=2。
- PA 指向 headA 的8时,PB 指向 headB 的7。
- 然后 PA 指向 headB 的头结点级4,PB 指向 headB 的8。
- 然后 PA 指向 headB 的5,PB 指向 headA 的1。
- 然后 PA 指向 headB 的6,PB 指向 headA 的2。
- 然后 PA 指向 headB 的7,PB 指向 headA 的7。
- 两个节点相同,返回 PA。
PA 走了 a+c+b=2+2+3=7步,PB 走了 b+c+a=3+2+2=7步,然后剩余的链表都还有 c=2步没有走。为什么剩余的都是 c 步?因为两个指针都最多走 m+n 次即 a+c+b+c 步。虽然 PA 和 PB 走的顺序不一样但都把前面的 abc 走了,只剩下最后的 c 步了。