STM32F4_中英文显示
目录
1. 液晶显示逻辑
2. 汉字显示原理
3. 实验程序
3.1 main.c
3.2 text.c
3.3 text.h
3.4 fontupd.c
3.5 fontupd.h
1. 液晶显示逻辑
字符编码:
由于计算机只能识别 0 和 1,文字也只能以 0 和 1 的形式在计算机里存储,所以我们需要对文字进行编码才能让计算机进行处理,编码的过程就是规定特定的 01数字串 来表示特定的文字,最简单的字符编码例子就是ASCII码。例如在C语言的编译环境下,我们输入"abcd",实际上存储到内存中的是0x61 0x62 0x63 0x64(也就是字符对应的ASCII码)
ASCII编码:
在程序设计中使用ASCII编码表约定了一些控制字符、英文及数字。它们在存储器中,本质也是二进制数,只是我们约定这些二进制数可以表示某些特殊意义,如以ASCII编码解释数字 “0x41” 时,它表示英文字符 “A”
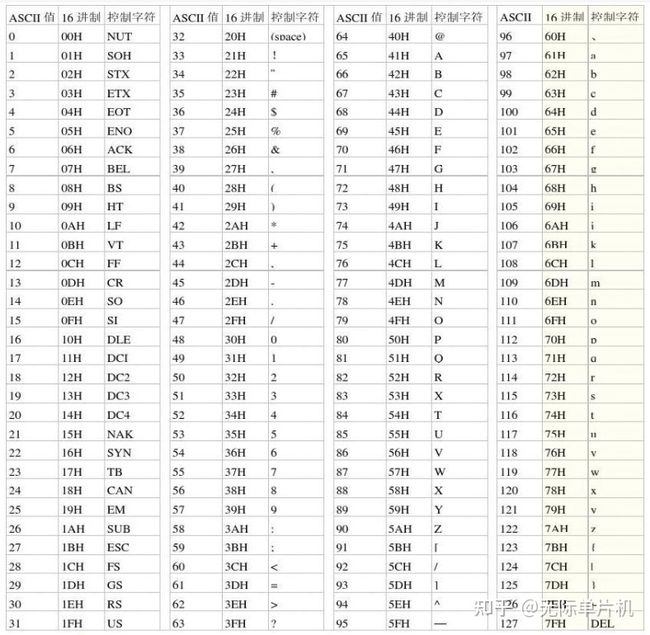
ASCII码表分为两部分,第一部分是控制字符和通讯专用字符,它们的数字编码从0~31,它们并没有特定的图形显示,但会根据不同的应用程序,对文本显示有不同的影响。ASCII码的第二部分包括空格、阿拉伯数字、标点符号、大小写英文字母以及 “DEL(删除控制)”,这部分符号的数字编码从32~127,除最后一个DEL符号外,都能以图形的方式来表示,它们属于传统文字书写系统的一部分。
后来,随着计算机被引入到其他国家,由于它们使用的不是英语,他们使用的字母在ASCII码表中没有定义,所以他们采用了127号之后的位来表示这些新的字母,在此基础之上加入了各种形状,一直编码到255。从128到255这些字符被称为ASCII扩展字符集。
中文编码:
英文书写系统是由26个基本字母组成,利用26个字母可以组合出不同的单次,所以用ASCII码表就能表示整个英文书写系统。
中文书写系统中的汉字是独立的方块,由于汉字非常多,常用字就有6000多个,如果像ASCII编码表那样只使用1个字节最多只能表示256个汉字,所以我们使用2个字节来编码。打个比方说:B0A3 =哎 ,通过两个字节的1011 0000 1010 0011来表示一个中文汉字哎。
GB2312标准:
我国首先定义的是GB2312标准。它把ASCII码表127号之后的扩展字符集直接取消掉,规定小于127的编码按原来ASCII标准解释字符。当两个大于127的字符连在一起时,就表示一个汉字,第一个字节使用(0xA1~0xFE)编码,第二个字节使用(0xA1~0xFE)编码,这样的编码组合起来可以表示7000多个符号,其中包括6763个汉字。

如上表,当我们设定系统使用GB2312标准的时候,他遇到一个字符串时,会按字节检测字符值的大小,若遇到连续两个字节的数值都大于127时就把这两个连续的字节合在一起,用GB2312解码,若遇到的数值小于127,就直接用ASCII把它解码。
区位码:
GB2312编码对所收录字符进行了 “分区” 处理,共94个区,每个区含94个位,共8836个码位。这种表示方式也称为区位码。
- 01-09区收录除汉字外的682个字符。
- 10-15区为空白区,没有使用。
- 16-55区收录3755个一级汉字,按拼音排序。
- 56-87区收录3008个二级汉字,按部首/笔画排序。
- 88-94区为空白区,没有使用。
比如说: “啊” 字是GB2312编码中的第一个汉字,它位于 16 区的 01 位,所以它的区位码就是1601.
GBK编码:
虽然GB2312编码中表示的6763个汉字已经覆盖中国大陆99.75%的使用率,但是有些生僻字在人名、文言文中出现的频率还是非常高的。
为此在GB2312标准的基础上又增加了14240个新汉字和符号,这个方案被称为GBK标准。如果按照GB2312原来的标准进行编码,2个字节已经存储不下了,因此GBK标准中只要第一个字节大于127就表示这是一个汉字的开始,这样同时也兼容ASCII和GB2312标准。
Gig5编码:
在台湾、香港等地区,使用较多的是Gig5编码,它的主要特点是收录了繁体字。Big5编码和GBK编码是不兼容的。
Unicode编码:
由于各个国家或地区都根据使用自己的文字系统制定标准,同一个编码在不同的标准里表示不一样的字符,各个标准互不兼容,无法用一个标准表示所有的字符。国际标准化组织ISO舍弃了地区性的方案,重新给全球上所有文化使用的字母和符号进行编号,该编号集被称为Universal Multiple-OcteCoded Character Set,简称UCS,也被称为Unicode。
2. 汉字显示原理
汉字在液晶上的显示其实就是一些点的显示与不显示,这就相当于我们的笔一样,有笔经过的地方画出来,没有经过的地方就不画出来。所以我们要显示汉字,首先要知道汉字的点阵数据,这些数据可以由专门的软件来生成。只要知道了汉字点阵的生成方法,那么我们在程序里面就可以把这个点阵数据解析成一个汉字了。(同51点阵屏的显示原理一样)
知道显示了一个汉字,就可以推及整个汉字库了。汉字在各种文件里面的存储不是以点阵数据的形式存储的(否则那占用的空间就太大了),而是以内码的形式(1个高8位,1个低8位)存储的,就是GB2312/GBK/BIG5等这几种的一种,每个汉字对应着一个内码,再知道这个内码之后再去字库里面查找这个汉字的点阵数据,然后在液晶上显示出来。这个过程我们是看不到的,但是计算机是要去执行的。
汉字内码(GBK/GB2312)--->查找点阵库--->解析--->显示
接下来很大的问题就是:制作一个与汉字内码对得上号的汉字点阵库。方便单片机的查找。每个GBK码由2个字节组成,第一个字节为0x81~0xFE,第二个字节分成两部分,一是0x40~0x7E,二是0x80~0xFE。
我们习惯上把第一个字节代表的意义称为区,那么GBK里面总共有126个区(0xFE-0x81+1),每个区内有190个汉字(0xFE-0x80+0x7E-0x40+2),总共就有126*190=23940个汉字。我们的点阵库只要按照这个编码规则从0x8140开始,逐一建立,每个区的点阵大小为每个汉字所用的字节数*190(每个区有190个汉字,190乘以每个汉字所占的字节数=该区总的字节数,也就是每个区的点阵大小)
当 GBKL<0X7F时:Hp=((GBKH-0x81)*190+GBKL-0X40)*(size*2);
当 GBKL>0X80 时:Hp=((GBKH-0x81)*190+GBKL-0X41)*(size*2);
(注:因为第二字节被分成两部分,所以分开考虑)
其中 GBKH、GBKL 分别代表 GBK 的第一个字节和第二个字节(也就是高位和低位),size 代表汉字字体的大小(比如 16 字体,12 字体等),Hp 则为对应汉字点阵数据在字库里面的起 始地址(假设是从 0 开始存放)。
(GBKH-0x81)*190表示第一个字节相对于起始位置的偏移量,*乘以190表示这个字相对于起始位的总的偏移字节大小;GBKL-0X40表示第二个字节的偏移量
字库的生成,我们要用到一款由易木雨软件工作室设计的点阵字库生成器V3.8。

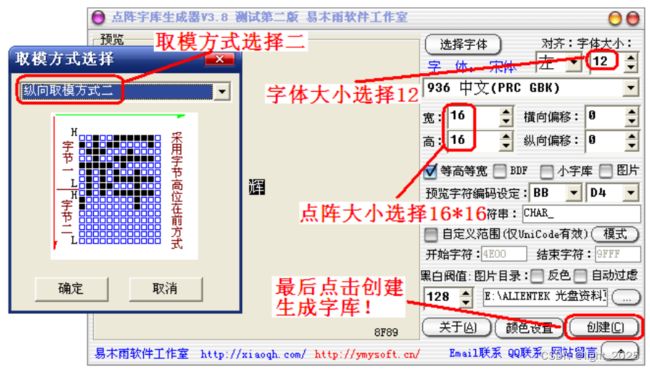
注意:
电脑端的字体大小与我们生成点阵大小的关系为:
fsize=dsize*6/8
其中,fsize是电脑端字体大小,dsize是点阵大小(12、16、24等)。所以16*16点阵大小对应的是12字体。
3. 实验程序
实验功能:
开机的时候先检测W25Q128中是否已经存在字库,如果存在,则按次序显示汉字(三种字体都显示)。如果没有,则检测SD卡和文件系统,并查找SYSTEM文件夹下的FONT文件夹。在该文件夹内查找 UNIGBK.BIN、GBK12.FON、GBK16.FON 和GBK24.FON。检测到这些文件之后,开始更新字库,更新完毕后才开始显示汉字。
3.1 main.c
#include "stm32f4xx.h"
#include "delay.h"
#include "usart.h"
#include "LED.h"
#include "lcd.h"
#include "Key.h"
#include "usmart.h"
#include "SRAM.h"
#include "Malloc.h"
#include "SDIO_Card.h"
#include "W25Q128.h"
#include "ff.h"
#include "exfuns.h"
#include "fontupd.h"
#include "text.h"
//LCD状态设置函数
void led_set(u8 sta)//只要工程目录下有usmart调试函数,主函数就必须调用这两个函数
{
LED1=sta;
}
//函数参数调用测试函数
void test_fun(void(*ledset)(u8),u8 sta)
{
led_set(sta);
}
int main(void)
{
u32 fontcnt;
u8 i,j;
u8 fontx[2];//gbk码
u8 key,t;
NVIC_PriorityGroupConfig(NVIC_PriorityGroup_2);//设置系统中断优先级分组2
delay_init(168); //初始化延时函数
uart_init(115200); //初始化串口波特率为115200
LED_Init(); //初始化LED
LCD_Init(); //LCD初始化
Key_Init(); //按键初始化
W25Q128_Init(); //初始化W25Q128
usmart_dev.init(168); //初始化USMART
my_mem_init(SRAMIN); //初始化内部内存池
my_mem_init(SRAMCCM); //初始化CCM内存池
exfuns_init(); //为fatfs相关变量申请内存
f_mount(fs[0],"0:",1); //挂载SD卡
f_mount(fs[1],"1:",1); //挂载FLASH.
while(font_init()) //检查字库
{
UPD:
LCD_Clear(WHITE); //清屏
POINT_COLOR=RED; //设置字体为红色
LCD_ShowString(30,50,200,16,16,"Explorer STM32F4");
while(SD_Init()) //检测SD卡
{
LCD_ShowString(30,70,200,16,16,"SD Card Failed!");
delay_ms(200);
LCD_Fill(30,70,200+30,70+16,WHITE);
delay_ms(200);
}
LCD_ShowString(30,70,200,16,16,"SD Card OK");
LCD_ShowString(30,90,200,16,16,"Font Updating...");
key=update_font(20,110,16,"0:");//更新字库
while(key)//更新失败
{
LCD_ShowString(30,110,200,16,16,"Font Update Failed!");
delay_ms(200);
LCD_Fill(20,110,200+20,110+16,WHITE);
delay_ms(200);
}
LCD_ShowString(30,110,200,16,16,"Font Update Success! ");
delay_ms(1500);
LCD_Clear(WHITE);//清屏
}
POINT_COLOR=RED;
Show_Str(30,50,200,16,"探索者STM32F407开发板",16,0); //在指定位置上开始显示一个字符
Show_Str(30,70,200,16,"GBK字库测试程序",16,0);
Show_Str(30,90,200,16,"正点原子@ALIENTEK",16,0);
Show_Str(30,110,200,16,"2023年20月23日",16,0);
Show_Str(30,130,200,16,"按KEY0,更新字库",16,0);
POINT_COLOR=BLUE;
Show_Str(30,150,200,16,"内码高字节:",16,0);
Show_Str(30,170,200,16,"内码低字节:",16,0);
Show_Str(30,190,200,16,"汉字计数器:",16,0);
Show_Str(30,220,200,24,"对应汉字为:",24,0);
Show_Str(30,244,200,16,"对应汉字(16*16)为:",16,0);
Show_Str(30,260,200,12,"对应汉字(12*12)为:",12,0);
while(1)
{
fontcnt=0;
for(i=0x81;i<0xff;i++) //0x81第一个字节的起始位
{
fontx[0]=i;
LCD_ShowNum(30+8*11,150,i,3,16); //显示内码高字节,1个汉字占两个字节
for(j=0x40;j<0xfe;j++) //第二字节
{
if(j==0x7f) //第二字节被分成两部分,一是0x40~0x7E,二是0x80~0xFE。中间间隔了0x7F,碰到0X7F跳过一次即可
continue;//continue语句的作用是跳过循环体中剩余的语句而强行执行下一次循环
fontcnt++;
LCD_ShowNum(118,170,j,3,16); //显示内码低字节
LCD_ShowNum(118,190,fontcnt,5,16);//汉字计数显示
fontx[1]=j;
Show_Font(30+132,220,fontx,24,0);
Show_Font(30+144,244,fontx,16,0);
Show_Font(30+108,260,fontx,12,0);
t=200;
while(t--)//延时,同时扫描按键
{
delay_ms(1);
key=KEY_Scan(0);
if(key==1)
goto UPD;
}
LED0=!LED0;
}
}
}
}
3.2 text.c
#include "sys.h"
#include "fontupd.h"
#include "W25Q128.h"
#include "lcd.h"
#include "text.h"
#include "string.h"
#include "usart.h"
//code 字符指针开始
//从字库中查找出字模
//code 字符串的开始地址,GBK码
//mat 数据存放地址 (size/8+((size%8)?1:0))*(size) bytes大小
//size:字体大小
void Get_HzMat(unsigned char *code,unsigned char *mat,u8 size)
{
unsigned char qh,ql;
unsigned char i;
unsigned long foffset;
u8 csize=(size/8+((size%8)?1:0))*(size);//得到字体一个字符对应点阵集所占的字节数
qh=*code;
ql=*(++code);
if(qh<0x81||ql<0x40||ql==0xff||qh==0xff)//非常用汉字,不在GBK定义的库里面
{
for(i=0;i0x80)
bHz=1;//中文
else //字符
{
if(x>(x0+width-size/2))//换行
{
y+=size;
x=x0;
}
if(y>(y0+height-size))
break;//越界返回
if(*str==13)//换行符号
{
y+=size;
x=x0;
str++;
}
else
LCD_ShowChar(x,y,*str,size,mode);//有效部分写入
str++;
x+=size/2; //字符,为全字的一半
}
}
else//中文
{
bHz=0;//有汉字库
if(x>(x0+width-size))//换行
{
y+=size;
x=x0;
}
if(y>(y0+height-size))
break;//越界返回
Show_Font(x,y,str,size,mode); //显示这个汉字,空心显示
str+=2;
x+=size;//下一个汉字偏移
}
}
}
//在指定宽度的中间显示字符串
//如果字符长度超过了len,则用Show_Str显示
//len:指定要显示的宽度
void Show_Str_Mid(u16 x,u16 y,u8*str,u8 size,u8 len)
{
u16 strlenth=0;
strlenth=strlen((const char*)str);
strlenth*=size/2;
if(strlenth>len)
Show_Str(x,y,lcddev.width,lcddev.height,str,size,1);
else
{
strlenth=(len-strlenth)/2;
Show_Str(strlenth+x,y,lcddev.width,lcddev.height,str,size,1);
}
}
3.3 text.h
#ifndef __TEXT_H__
#define __TEXT_H__
#include
#include "fontupd.h"
void Get_HzMat(unsigned char *code,unsigned char *mat,u8 size); //得到汉字的点阵码
void Show_Font(u16 x,u16 y,u8 *font,u8 size,u8 mode); //在指定位置显示一个汉字
void Show_Str(u16 x,u16 y,u16 width,u16 height,u8*str,u8 size,u8 mode); //在指定位置显示一个字符串
void Show_Str_Mid(u16 x,u16 y,u8*str,u8 size,u8 len);
#endif
3.4 fontupd.c
#include "fontupd.h"
#include "ff.h"
#include "W25Q128.h"
#include "lcd.h"
#include "string.h"
#include "Malloc.h"
#include "delay.h"
#include "usart.h"
//字库区域占用的总扇区数大小(3个字库+unigbk表+字库信息=3238700字节,约占791个W25Q128扇区)
#define FONTSECSIZE 791
//字库存放起始地址
#define FONTINFOADDR 1024*1024*12 //Explorer STM32F4是从12M地址以后开始存放字库
//前面12M被fatfs占用了.
//12M以后紧跟3个字库+UNIGBK.BIN,总大小3.09M,被字库占用了,不能动!
//15.10M以后,用户可以自由使用.建议用最后的100K字节比较好.
//用来保存字库基本信息,地址,大小等
_font_info ftinfo;
//字库存放在磁盘中的路径
u8*const GBK24_PATH="/SYSTEM/FONT/GBK24.FON"; //GBK24的存放位置
u8*const GBK16_PATH="/SYSTEM/FONT/GBK16.FON"; //GBK16的存放位置
u8*const GBK12_PATH="/SYSTEM/FONT/GBK12.FON"; //GBK12的存放位置
u8*const UNIGBK_PATH="/SYSTEM/FONT/UNIGBK.BIN"; //UNIGBK.BIN的存放位置
//显示当前字体更新进度
//x,y:坐标
//size:字体大小
//Entirefilesize:整个文件大小
//position:当前文件指针位置
u32 fupd_prog(u16 x,u16 y,u8 size,u32 Entirefilesize,u32 position)
{
float prog;
u8 t=0XFF;
prog=(float)position/Entirefilesize; //打印出小数
prog*=100;//乘以100 转换成百分比的形式
if(t!=prog)
{
LCD_ShowString(x+3*size/2,y,240,320,size,"%");
t=prog;
if(t>100) //最多100%
t=100;
LCD_ShowNum(x,y,t,3,size);//显示数值
}
return 0;
}
//更新某一个
//x,y:坐标
//size:字体大小
//fxpath:路径
//fx:更新的内容 0,ungbk;1,gbk12;2,gbk16;3,gbk24;
//返回值:0,成功;其他,失败.
u8 updata_fontx(u16 x,u16 y,u8 size,u8 *fxpath,u8 fx)
{
u32 flashaddr=0;
FIL * fftemp;
u8 *tempbuf;
u8 res;
u16 bread;
u32 offx=0;
u8 rval=0; //错误判断标志
fftemp=(FIL*)mymalloc(SRAMIN,sizeof(FIL)); //分配内存
if(fftemp==NULL)
rval=1;
tempbuf=mymalloc(SRAMIN,4096); //分配4096个字节空间
if(tempbuf==NULL)
rval=1;
res=f_open(fftemp,(const TCHAR*)fxpath,FA_READ);
if(res)
rval=2;//打开文件失败
if(rval==0)//表示没有出错
{
switch(fx) //fx表示更新的内容
{
case 0: //更新UNIGBK.BIN
ftinfo.ugbkaddr=FONTINFOADDR+sizeof(ftinfo); //信息头之后,紧跟UNIGBK转换码表
ftinfo.ugbksize=fftemp->fsize; //UNIGBK大小
flashaddr=ftinfo.ugbkaddr;
break;
case 1:
ftinfo.f12addr=ftinfo.ugbkaddr+ftinfo.ugbksize; //UNIGBK之后,紧跟GBK12字库
ftinfo.gbk12size=fftemp->fsize; //GBK12字库大小
flashaddr=ftinfo.f12addr; //GBK12的起始地址
break;
case 2:
ftinfo.f16addr=ftinfo.f12addr+ftinfo.gbk12size; //GBK12之后,紧跟GBK16字库
ftinfo.gbk16size=fftemp->fsize; //GBK16字库大小
flashaddr=ftinfo.f16addr; //GBK16的起始地址
break;
case 3:
ftinfo.f24addr=ftinfo.f16addr+ftinfo.gbk16size; //GBK16之后,紧跟GBK24字库
ftinfo.gkb24size=fftemp->fsize; //GBK24字库大小
flashaddr=ftinfo.f24addr; //GBK24的起始地址
break;
}
while(res==FR_OK)//死循环执行
{
res=f_read(fftemp,tempbuf,4096,(UINT *)&bread); //读取数据
if(res!=FR_OK)break; //执行错误
W25QXX_Write(tempbuf,offx+flashaddr,4096); //从0开始写入4096个数据
offx+=bread;
fupd_prog(x,y,size,fftemp->fsize,offx); //进度显示
if(bread!=4096)break; //读完了.
}
f_close(fftemp);
}
myfree(SRAMIN,fftemp); //释放内存
myfree(SRAMIN,tempbuf); //释放内存
return res;
}
//更新字体文件,UNIGBK,GBK12,GBK16,GBK24一起更新
//x,y:提示信息的显示地址
//size:字体大小
//src:字库来源磁盘."0:",SD卡;"1:",FLASH盘,"2:",U盘.
//提示信息字体大小
//返回值:0,更新成功;
// 其他,错误代码.
u8 update_font(u16 x,u16 y,u8 size,u8* src)
{
u8 *pname;
u32 *buf;
u8 res=0;
u16 i,j;
FIL *fftemp;
u8 rval=0;
res=0XFF;
ftinfo.fontok=0XFF;
pname=mymalloc(SRAMIN,100); //申请100字节内存
buf=mymalloc(SRAMIN,4096); //申请4K字节内存
fftemp=(FIL*)mymalloc(SRAMIN,sizeof(FIL)); //分配内存
if(buf==NULL||pname==NULL||fftemp==NULL)
{
myfree(SRAMIN,fftemp);
myfree(SRAMIN,pname);
myfree(SRAMIN,buf);
return 5; //内存申请失败
}
//先查找文件是否正常
strcpy((char*)pname,(char*)src); //copy src内容到pname
strcat((char*)pname,(char*)UNIGBK_PATH);
res=f_open(fftemp,(const TCHAR*)pname,FA_READ);
if(res)rval|=1<<4;//打开文件失败
strcpy((char*)pname,(char*)src); //copy src内容到pname
strcat((char*)pname,(char*)GBK12_PATH);
res=f_open(fftemp,(const TCHAR*)pname,FA_READ);
if(res)rval|=1<<5;//打开文件失败
strcpy((char*)pname,(char*)src); //copy src内容到pname
strcat((char*)pname,(char*)GBK16_PATH);
res=f_open(fftemp,(const TCHAR*)pname,FA_READ);
if(res)rval|=1<<6;//打开文件失败
strcpy((char*)pname,(char*)src); //copy src内容到pname
strcat((char*)pname,(char*)GBK24_PATH);
res=f_open(fftemp,(const TCHAR*)pname,FA_READ);
if(res)rval|=1<<7;//打开文件失败
myfree(SRAMIN,fftemp);//释放内存
if(rval==0)//字库文件都存在.
{
LCD_ShowString(x,y,240,320,size,"Erasing sectors... ");//提示正在擦除扇区
for(i=0;i3.5 fontupd.h
#ifndef __FONTUPD_H__
#define __FONTUPD_H__
#include
//字体信息保存地址,占33个字节,第1个字节用于标记字库是否存在.后续每8个字节一组,分别保存起始地址和文件大小
extern u32 FONTINFOADDR;
//字库信息结构体定义
//用来保存字库基本信息,地址,大小等
__packed typedef struct
{
u8 fontok; //字库存在标志,0XAA,字库正常;其他,字库不存在
u32 ugbkaddr; //unigbk的地址
u32 ugbksize; //unigbk的大小
u32 f12addr; //gbk12地址
u32 gbk12size; //gbk12的大小
u32 f16addr; //gbk16地址
u32 gbk16size; //gbk16的大小
u32 f24addr; //gbk24地址
u32 gkb24size; //gbk24的大小
}_font_info;
extern _font_info ftinfo; //字库信息结构体
u32 fupd_prog(u16 x,u16 y,u8 size,u32 fsize,u32 pos); //显示更新进度
u8 updata_fontx(u16 x,u16 y,u8 size,u8 *fxpath,u8 fx); //更新指定字库
u8 update_font(u16 x,u16 y,u8 size,u8* src); //更新全部字库
u8 font_init(void); //初始化字库
#endif