数据结构之链表
数据结构之链表
链表以线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表的插入和删除操作可以达到O(1)的复杂度。而链表有指向性可以分为单向链表和双向链表。
单向链表(单链表)是链表的一种,它由节点组成,每个节点都包含下一个节点的指针,下图就是一个单链表。
![]()
可以由图看出,链表中每个节点都指向下个节点。一般在设置链表时,头节点我一般会设成空节点。
在编写单向链表时,我一般会这样设置链表节点的结构体。
// 定义链表结构体
typedef struct ListNode
{
int data; //数据域
struct ListNode* next; //下个节点的地址
}List;
数据域可以是自定义类型的数据,这里只是举个例子。其中还有一个指针变量用于指向下一个节点。通常链表中最后一个节点的指针变量指向的是空地址。
单向链表的基本操作有:
初始化链表,用于创建一个表头方便以后的数据的存储。代码我是运行过的,但是也可能会有bug,如果有发现还望告知。
// 初始化链表
List* InitList()
{
// 申请链表头空间
List* pHead = (List*)malloc(sizeof(struct ListNode));
if (pHead == NULL) return NULL; //如果申请空间失败返回空
//初始化头节点
pHead->data = -1;
pHead->next = NULL;
ListSize = 0;
printf("请输入节点数据,以-1结束:\n");
int val;
List* pCurrent = pHead;
while (1)
{
scanf("%d",&val);
if (val == -1) break;
//创建新节点
List* newNode = (List*)malloc(sizeof(struct ListNode));
newNode->data = val;
newNode->next = NULL;
ListSize += 1;
pCurrent->next = newNode;
pCurrent = newNode;
}
return pHead;
}
一般为了知道链表中有那些数据我们需要遍历链表。
// 遍历链表
void foreach_list(List* pHead)
{
if (!pHead) return;
List* pCurrent = pHead->next;
while (pCurrent)
{
printf("%d\n", pCurrent->data);
pCurrent = pCurrent->next;
}
}
关于链表节点的插入我写了四种插入方式,其实具体操作都大同小异。
// 链表尾插
void insert_tail(List* pHead, int val)
{
if (!pHead) return;
List* pCurrent = pHead;
while (pCurrent->next)
{
pCurrent = pCurrent->next;
}
List* newNode = (List*)malloc(sizeof(struct ListNode));
newNode->data = val;
newNode->next = NULL;
pCurrent->next = newNode;
}
// 链表头插
void insert_head(List* pHead, int val)
{
if (!pHead) return;
List* newNode = (List*)malloc(sizeof(struct ListNode));
newNode->data = val;
newNode->next = pHead->next;
pHead->next = newNode;
}
// 根据下标插入节点
void insert_index(List* pHead, int index, int val)
{
if (!pHead) return;
int i = 0;
List* pCurrent = pHead->next;
while (i < index)
{
pCurrent = pCurrent->next;
if (!pCurrent)
{
printf("超出链表范围!\n");
return;
}
i++;
}
List* newNode = (List*)malloc(sizeof(struct ListNode));
newNode->data = val;
if (!pCurrent->next)
{
newNode->next = NULL;
}
newNode->next = pCurrent->next;
pCurrent->next = newNode;
}
// 根据指定元素位置插入节点(插在指定位置的后面)
void insert(List* pHead, int oldval, int newval) // oldval代表指定元素,newval表示插入节点的值
{
if (!pHead) return;
List* pCurrent = pHead->next;
while (pCurrent->data != oldval)
{
pCurrent = pCurrent->next;
if (pCurrent == NULL)
{
printf("找不到指定元素!\n");
return;
}
}
List* newNode = (List*)malloc(sizeof(struct ListNode));
newNode->data = newval;
if (!pCurrent->next)
{
newNode->next = NULL;
}
newNode->next = pCurrent->next;
pCurrent->next = newNode;
}
删除节点,一般链表不会大规模的删除节点,因为每次删除节点都要遍历链表,会大大的浪费内存资源。
// 删除尾部节点
void del_tail(List* pHead)
{
if (!pHead || !pHead->next) return;
List* pCurrent = pHead->next;
List* pNext = pCurrent->next;
while (pNext->next)
{
pCurrent = pNext;
pNext = pNext->next;
}
free(pNext);
pNext = NULL;
pCurrent->next = NULL;
}
// 删除头部节点
void del_head(List* pHead)
{
if (!pHead || !pHead->next) return;
List* pCurrent = pHead->next;
pHead->next = pCurrent->next;
free(pCurrent);
}
// 删除指定位置节点
void del_node(List* pHead, int val)
{
if (!pHead || !pHead->next || val == -1) return;
List* pre = pHead;
List* pCurrent = pHead->next;
while (pCurrent->data != val)
{
pre = pCurrent;
pCurrent = pCurrent->next;
if (pCurrent == NULL)
{
printf("找不到指定元素!\n");
return;
}
}
pre->next = pCurrent->next;
free(pCurrent);
}
链表的清空,销毁操作。
// 清空链表
void clear_list(List* pHead)
{
if (!pHead || !pHead->next) return;
List* pCurrent = pHead->next;
List* Node = pCurrent;
while (!pCurrent)
{
pCurrent = pCurrent->next;
free(Node);
Node = pCurrent;
}
pHead->next = NULL;
}
// 销毁链表
void destory_list(List* pHead)
{
clear_list(pHead);
free(pHead);
pHead = NULL;
}
有时候我们需要翻转链表。
// 反转链表
void reverse_list(List* pHead)
{
if (!pHead || !pHead->next) return;
List* pCurrent = pHead->next;
if (!pCurrent->next) return;
List* Next = pCurrent->next;
List* Node = NULL;
pCurrent->next = NULL;
while (Next)
{
Node = Next->next;
Next->next = pCurrent;
pCurrent = Next;
Next = Node;
}
pHead->next = pCurrent;
}
在获取链表大小,一般有两种方法,一种就是设定一个变量记录链表中节点的数量,另一种是遍历链表,获取链表大小。前者浪费内存,后者浪费时间。
// 返回链表大小
int listsize(List* pHead)
{
if (!pHead || !pHead->next) return 0;
int count = 0;
List* pCurrent = pHead->next;
while (pCurrent)
{
count++;
pCurrent = pCurrent->next;
}
return count;
}
既然单向链表在存储数据的时候这么麻烦,为什么还要用单向链表也不用数组等便于访问的数据结构呢?
一、链表的插入和删除一个节点的操作是O(1)的复杂度,而数组的除了尾插或尾删其他操作的复杂度都要大于链表。
二、在存储空间方面,链表的存储空间可以是不连续的,因为链表可以通过地址的指向性链接所有节点,并且可以实现动态内存申请。而数组方面,则需要先申请一段连续的空间保存数据,如果空间不足需要再申请更大的空间,将原有的数据拷贝到新空间的地址上,再释放旧空间。若空间申请过大会造成资源浪费。
三、留给你们说?
同时链表的缺点也很明显:
一、访问某一节点要遍历链表,不像数组通过下标访问数据。
二、翻转链表时不仅要遍历链表还有多个变量辅助。
通过,改进链表结构体可以提高链表翻转的效率,就是使用双向链表。
先看看双向链表的实现代码
typedef struct Double_List // 双向链表结构体
{
struct Double_List* pre; // 前驱节点的地址
int data; // 数据域
struct Double_List* next; // 后继节点的地址
}d_list;
d_list* Init_dlist() // 双向链表
{
// 为头节点申请空间
d_list* head = (d_list*)malloc(sizeof(struct Double_List));
// 初始化头节点
head->pre = NULL;
head->data = -1;
head->next = NULL;
d_list* pCurrent = head;
int val;
printf("输入节点数据,以-1结束:\n");
d_list* newNode = NULL;
while (1)
{
scanf("%d", &val);
if(val == -1)
{
break;
}
newNode = (d_list*)malloc(sizeof(struct Double_List));
newNode->data = val;
newNode->pre = pCurrent;
newNode->next = NULL;
pCurrent->next = newNode;
pCurrent = newNode;
}
return head;
}
void foreach_dlist(d_list* head) // 遍历双向链表
{
if (!head) return;
d_list* pCurrent = head->next;
while (pCurrent)
{
printf("%d\n", pCurrent->data);
pCurrent = pCurrent->next;
}
}
void insert(d_list* head, int data) //头插
{
if (!head) return;
d_list* newNode = (d_list*)malloc(sizeof(struct Double_List));
newNode->pre = head;
newNode->next = head->next;
newNode->data = data;
if (head->next)
{
head->next->pre = newNode;
}
head->next = newNode;
}
void insert_tail(d_list* head, int data) //尾插
{
if (!head) return;
d_list* pCurrent = head;
while (pCurrent->next)
{
pCurrent = pCurrent->next;
}
d_list* newNode = (d_list*)malloc(sizeof(struct Double_List));
newNode->data = data;
newNode->pre = pCurrent;
newNode->next = NULL;
pCurrent->next = newNode;
}
void insertbydata(d_list* head, int oldval, int newval) //根据现有数据的值插入新节点
{
if (!head) return;
d_list* pCurrent = head->next;
while (pCurrent)
{
if (pCurrent->data == oldval)
{
break;
}
pCurrent = pCurrent->next;
}
if (!pCurrent)
{
printf("找不到关键字!\n");
return;
}
d_list* newNode = (d_list*)malloc(sizeof(struct Double_List));
newNode->data = newval;
newNode->pre = pCurrent;
newNode->next = pCurrent->next;
pCurrent->next = newNode;
}
void insertbyindex(d_list* head, int index, int data) //根据下标插入数据
{
if (!head) return;
if (index == 0)
{
insert(head, data);
return;
}
d_list* pCurrent = head->next;
int i = 0;
while (i < index)
{
pCurrent = pCurrent->next;
i++;
if (!pCurrent)
{
printf("超出链表范围!\n");
return;
}
}
if (!pCurrent->next)
{
insert_tail(head, data);
return;
}
d_list* newNode = (d_list*)malloc(sizeof(struct Double_List));
newNode->data = data;
newNode->pre = pCurrent->pre;
newNode->next = pCurrent;
pCurrent->pre->next = newNode;
pCurrent->pre = newNode;
}
void del_node(d_list* head, int data) // 删除某节点
{
if (!head) return;
d_list* pCurrent = head->next;
while (pCurrent)
{
if (pCurrent->data == data)
{
break;
}
pCurrent = pCurrent->next;
}
pCurrent->pre->next = pCurrent->next;
free(pCurrent);
pCurrent = NULL;
}
void find_node(d_list* head, int data) // 寻找某个节点
{
if (!head) return;
d_list* pCurrent = head->next;
while (pCurrent)
{
if (pCurrent->data == data)
{
printf("找到了,%d\n", pCurrent->data);
return;
}
pCurrent = pCurrent->next;
}
printf("没找到!\n");
}
void alter_node(d_list* head, int olddata, int newdata) // 修改某个节点
{
if (!head) return;
d_list* pCurrent = head->next;
while (pCurrent)
{
if (pCurrent->data == olddata)
{
pCurrent->data = newdata;
return;
}
pCurrent = pCurrent->next;
}
printf("没有找到想要替换的值!\n");
}
void clear_list(d_list* head) // 清空链表
{
if (!head) return;
d_list* pCurrent = head->next;
d_list* next = NULL;
while (pCurrent)
{
next = pCurrent->next;
free(pCurrent);
pCurrent = next;
}
head->next = NULL;
}
void destory_list(d_list* head) // 销毁链表
{
clear_list(head);
if (head)
{
free(head);
head = NULL;
}
}
void reverse_list(d_list* head) // 翻转链表
{
if (!head) return;
d_list* pCurrent = head->next;
head->next = NULL;
d_list* next = NULL;
while (pCurrent)
{
next = pCurrent->next;
pCurrent->next = head->next;
pCurrent->pre = next;
head->next = pCurrent;
pCurrent = next;
}
}
int list_size(d_list* head) // 返回链表大小
{
if (!head)return;
d_list* pCurrent = head->next;
int count = 0;
while (pCurrent)
{
count++;
pCurrent = pCurrent->next;
}
return count;
}
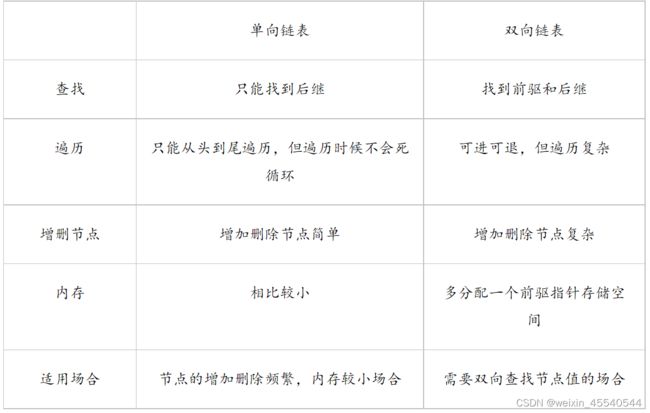
接下来介绍一下单向链表和双向链表的区别
单向链表:
由两部分组成:数据域和指针域,每个结点都有一个指针,每个节点指针的指向都是指向自身结点的下一个结点,最后一个结点的head指向为null,对单链表的操作只能从一端开始,如果需要查找链表中的某一个结点,则需要从头开始进行遍历。
双向链表:
对于双向链表来说,它的每个节点要指向“直接前驱”和“直接后继”,所以节点类需要含有两个指针域。指向直接前驱的指针使用pre表示,指向后继的指针使用next表示。双向链表是在单向链表基础上的一个改进,每个节点指向其直接前驱和直接后继节点。因此,从双向链表的任意位置开始,都能访问所有的节点。
双向链表从节点的结构上可以看出,双向链表的所需的存储空间大于单向链表。同时,对于插入和删除等操作来说,双向链表的节点操作更加复杂,涉及到节点的前后两个节点。