“我有一个大胆的想法”?Meta AI 新技术让你的思维图像一览无余!
夕小瑶科技说 原创
作者 | 付奶茶
大家之前是否想象过未来的技术进步会带来读脑器,计算界面是否有可能越过触摸屏、键盘进入我们思维内部读取我们脑袋中所想。尽管当前我们社会尚未达到这一阶段,但我们确实逐渐接近这一愿景!

不久前,Meta AI宣布了一项名为Image Decoder的深度学习应用,由FAIR-Paris与巴黎文理大学(PSL)巴黎高师(ENS)合作完成。该研究实现了一个重要的里程碑,即可以将人类大脑活动几乎实时地转化为高精度图像,展示观察者的视觉或思维内容。这一系统由图像编码器、大脑编码器、图像编码器组成,在Meta在4月份发布的自监督学习模型DINOv2[1]上训练,利用脑电信号(Magnetoencephalography, MEG)对人脑活动进行解码和可视化。
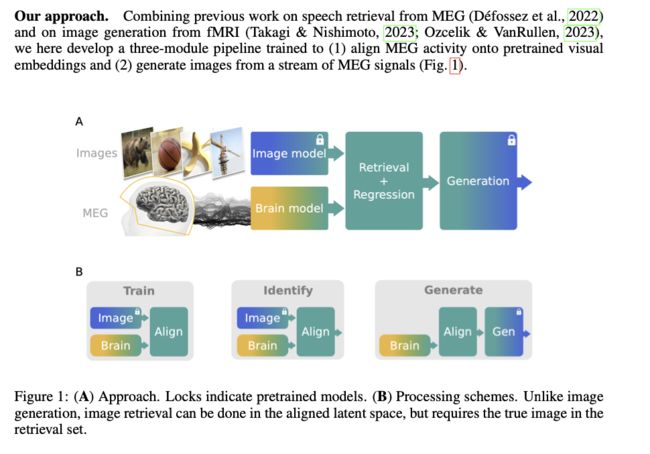


这项工作是Meta长期研究计划的一部分,其最终目标是构建一个完全模拟人类学习和推理能力的AI系统。接下来让我们看看他们究竟是怎样做的吧!
论文题目:
《Brain decoding: Toward real-time reconstruction of visual perception》
论文链接:
https://ai.meta.com/static-resource/image-decoding
文章速览
在这里我们首先先介绍一下脑磁图(Magnetoencephalography,MEG)是什么~脑磁图被广泛用于脑功能检测技术,是对脑内神经电流发出的极其微弱的生物磁场信号的直接测量,并记录整个大脑的瞬态数据。通过计算机综合影象信息处理,将获得的信号转换成脑磁曲线图,等磁线图等。
Image Decoder将机器学习和脑磁图(MEG)结合在一起。首先,分析标记过的数据,然后对新数据进行检查并尽量正确地标记。然后利用脑磁图在头部外侧测量记录大脑活动,使用仪器捕捉人类在思考时大脑磁场的微小变化。这样的做法可以在检索阶段从一组候选的图像中选择正确的图像,然后通过训练直接预测潜在的表示用来调整生成图像模型。

▲MEG记录连续地与图像的深度表示对齐,然后可以在每个瞬间调节图像的生成。
大脑编码器
作者ConvNet架构进行了调整,标记为fθ,以学习从MEG窗口Xi ∈ RC×T到潜在图像表示zi ∈ R F的投影,针对每个输入进行单一潜在值的回归,并添加了一个时间聚合层和两个MLP头部1,用于从F′投影到目标潜在维度F。
图像编码器
图像编码器学习将 MEG 信号与这些构建出来的图像进行嵌入对齐。作者使用卷积神经网络架构去提取特征,在此基础之上,添加了时序聚合层,以减少维度,节约计算开销。
生成解码器
作者从预训练的嵌入图像中生成图像,使用了基于三个嵌入条件的潜扩散模型:CLIP-Vision(257 tokens × 768), CLIP-Text(77 tokens × 768)和变分自编码器潜AutoKL(4 × 64 × 64),集合这些以及大脑表征生成可信的图像。
训练目标
作者提出的pipeline有多个部分,因此采用多目标优化策略,并在图像检索中采用CLIP Loss。
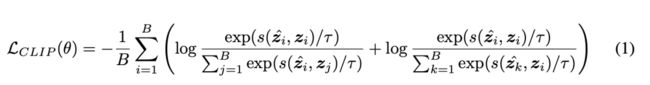
为了评估生成图像的质量,使用MSE Loss:
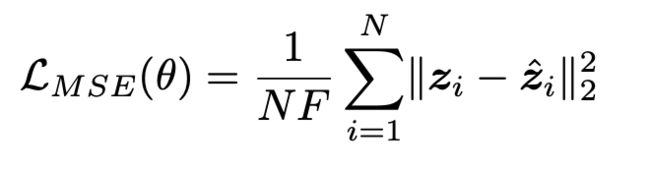
最后采用凸组合方方式结合CLIP和MSE进行训练:
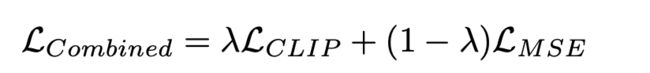
实验分析
数据集
作者选择在THINGS-MEG数据集上测试方法的有效性,对四位参与者包括两名女性和两名男性,平均年龄23岁)产生的63,000个历史MEG数据进行训练。这些数据来源自患者观看来自12次对话中记录的22,448张不同的图片以及原始图库中200张重复的图片。以这种方式,研究员通过图像解码器可以观察被试者的脑活动看到他们正在想象的内容。

▲THINGS-MEG1
机器学习是大脑表征的有效模型
作者采用线性岭回归模型(Linear Ridge regression models)来验证检索图像的性能。在实验结果中,所有图像的解码效果都明显高于随机猜测的检索性能,在监督学习和文本/图像对齐模型(如VGG和CLIP)产生了最高的检索分数。
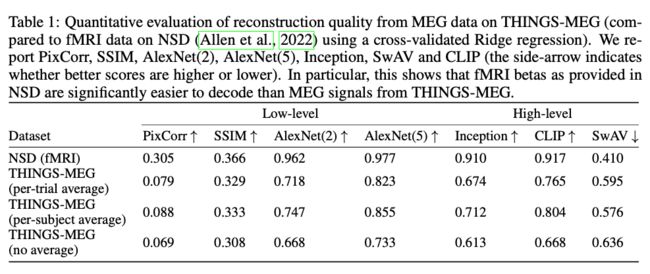
机器学习是拟合大脑反应过程的有效工具
作者将这些线性基线与相同任务上训练的深度卷积神经网络架构进行比较,即在给定MEG窗口的情况下检索匹配的图像。使用深度模型相对于线性基线实现了7倍的改进。多种类型的图像嵌入产生良好的检索性能,其中VGG-19(监督学习)、CLIP-Vision(文本/图像对齐)和DINOv2(自监督学习)的前5准确率分别为70.33 ± 2.80%,68.66 ± 2.84%和68.00 ± 2.86%。

时序级图像检索
作者尝试了时间分辨的图像检索实验,尝试拟合大脑中是处理和识别图像的过程。首先对时间进行了切割(250毫秒长的滑动窗口),每次只看大脑处理图像的一小段时间。拟合大脑研究每一帧的视频。在图像未呈现之前,所有的模型表现都很差,就像是随机猜测一样。首次明显的峰值可以在0到250毫秒的窗口上观察到,随后在图像结束后出现第二个峰值,在图像消失后,它们的性能又迅速恢复到了随机猜测的水平。而论文中指出,DINOv2在图像消失后表现仍然表现出了特别好的检索性能。
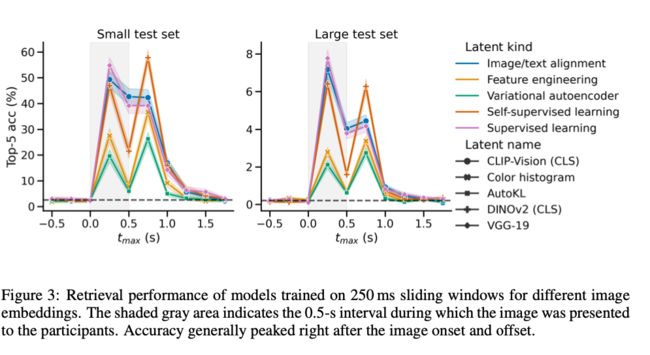
为了更好理解解码指标,作者构建了一个由原有测试集与3659张参与者未见过的额外图像合并而成的附加集,结果上来看,检索到的图像往往来自正确的类别,比如“演讲者(Speaker)”或“西兰花(brocoli)”,主要出现在前几个子窗口(t≤1秒)。
从MEG信号中生成图像
虽然检索任务展现了令人鼓舞的效果,但是他要求真实的样本必须存在于检索集中,这限制了实践中使用的可能性。为了缓解这样的限制,作者训练了三个不同的脑模块,用于预测使用的三个嵌入来生成图像(图5)。
生成的图像从评估结果中看相对不错,其中多个生成的图像与正确的实际类别相匹配。但是,生成的图像似乎包含有关真实图像的低级视觉信息 虽在最佳的情况下,系统根据MEG数据准确地检索、重建图像的准确率达到了70%,这比过去的方法提高了7倍数。从结果中可以看出,图像解码器虽然可以顺利地从潜在图像库中获取一些简单的图片,例如西兰花、毛毛虫等,但是对于更加复杂多样化的图像比如塔克斯、鳄梨酱料等成功率较低。
背后的伦理
然而,这种技术真的符合伦理标准吗?

研究者们也意识到,这项技术突破的确带来了多个伦理问题。因为深入探查一个人的思维并将其可视化,是一种未被明确定义的新型侵入方式,这涉及到人类心理隐私的保护。
作者在这项技术在伦理隐私上的问题没能给出明确的回复,但是提到目前技术在处理一个人所看到过的具体物体和现实图像时表现最出色。而当个体被要求想象一幅未曾见过的图像时,解码器的准确性就会显著降低。简而言之,获得受试者的同意不仅是法律上的要求,更是脑解码技术实现的基本前提。
此外,作者称如果一个人的脑活动图像是在未经同意的情况下被解码,那么他们可以采用抗干扰来抵抗这种情况,但是,这的的确地需要具备足够的意识和反应速度来反应他们正在处于这样的情况。
