预训练相关知识
1、上下文无关语义表示方式存在问题
语义不同的词具有相同的表示,(apple 电子产品苹果/水果苹果)
容易出现oov问题
2、神经语言编码器
2.1、序列模型
cnn/rnn等,捕获局部信息和序列依赖信息,无法捕获长距离依赖。易训练
2.2、非序列模型
树/图模型,transformer等,参数较多,难训练;表达能力较强,但需要大量的训练语料
3、预训练模型的引入原因
3.1、标注数据有限
3.2、无标签数据可以学习到通用数据的表示,用来初始化模型,加快特定任务的收敛
3.3、防止在小样本标注数据中模型过拟合
4、预训练任务
4.1、mlm:通常可以堪看成为类别为词汇量|V|大小的分类;由于pretrain和fine-tuning不一致,在预训练的过程中采用了比较trick的方式,80%的采用[mask],10%随机token,10%原来的token,例如bert
4.2、seq2seq mlm:被mask的token先扔给encoder,encoder再通过decoder进行解码,生产一个句子,mass、t5就是这些方式。
4.3、动态mlm:动态掩码的方式,每次构建min-batch时,动态构建sampling一次,确定需要sample的对象,例如RoBERTa
4.4、unified ml:包含双向mlm、单向ml、seq2seq ml
4.5、XLMs: 即cross-lingual language models(包含mlm和tlms两个任务),在一个双语序列上执行MLM;特别的,其TLMs (translation LMs)把一个parallel sentence 串接起来,扔给BERT。类似于输入的序列为“[/s] 我 爱 你 [/s] I love you [/s]”。
4.6、SpanBERT:sbo+mlm语言模型,一个span的掩码语言模型,span大小由几何分布的期望多次采样决定,span论文中的大小为4.4左右。类似于enire(实体掩码)和wwm bert(整个词全部掩码);无type embedding和nsp任务
4.7、structbert:nsp和sop的结合,预测上个句子/下个句子/随机句子三分类问题;一个span内随机打乱次的顺序,在已知词的情况下,预测词正确位置的概率。
4.8、xnet:,解决pretrain和fine-tuning的鸿沟,排序语言模型Permuted Language Modeling (PLM)被提出,PLM中,排列顺序是从输入文本中的所有可能的token排列中随机抽取的排列。选择一些目标token,依据排列顺序中目标token前的字符和输入文本原本顺序的自然位置,训练模型(引入two-stream self-attention 机制,实际中,由于收敛速度较慢,仅选择排列序列中的最后几个token作为目标token)。
4.9、dae:DAE 将输入部分的损坏(corrupted),模型目标是恢复成原始的未失真的输入 (MLM 属于一种DAE)。DAE应该不限于BART以下几种方法损坏输入:1)、Token Masking: 从输入中随机采样token,并用【MASK】替换,类似 MLM;2)、Token Deletion: 从输入中随机删除token,输出需确定删除token的位置;3)、Text Infilling: 类似SpanBERT,对多个文本跨度进行采样并替换为单个[MASK]令牌。4)、Sentence Permutation: 根据句号将文档分为多个句子,然后将这些句子随机排列。5)、Document Rotation: 均匀地选择一个token并旋转,以便从该token开始。此任务训练模型识别开始位置。
BART期望可以应用任何的预训练目标,实现NLP中NLU、NLG两大类任务的统一模型
4.10、CTL:CTL核心思想是 通过比较来学习(learning by comparison)。与LM相比,CTL通常具有较少的计算复杂性,比较受欢迎。最小化x,与正负样本y+,y-的负项距离。
4.11、Deep InfoMax (DIM):序列的全局表示形式定义为上下文编码器![]() 输出的第一个token的隐状态。DIM的目的是计算得到的
输出的第一个token的隐状态。DIM的目的是计算得到的![]() 比
比 ![]() 大, 其中
大, 其中 ![]() 为从 i 到 j的n-gram,
为从 i 到 j的n-gram, ![]() 为被mask的序列,
为被mask的序列, ![]() 为随机的负样本。n-gram中的span 是从高斯分布 N(5,1) 中采样,并截取长度为1~10的值。
为随机的负样本。n-gram中的span 是从高斯分布 N(5,1) 中采样,并截取长度为1~10的值。
4.12、Replaced Token Detection (RTD):RTD是通过上下文预测token 是否被替换。
ELECTRA 模型利用一个generator G 和一个 discriminator D 网络,采用两部策略对其进行训练:step1:仅对 G 网络 进行MLM任务训练;step2:用G 的权重初始化D, 然后将G frozen,而D去判断G输出中,每个token是否被替换过,下游任务采用D网络 fine-tune。这里用G来生成的反例,相比随机生成的反例,能大大提高任务难度。
当然此任务同样有pre-training 和 fine-tune不匹配的问题。
4.13、nsp任务:NSP任务目标是判断两个输入句子是否是连续的,以此学习两个句子之间的关系,从而使双句子形式的下游任务受益,例如QA和NLI任务。 构造数据集时,第二个句子有50%的概率是第一个句子实际的下一个句子,50%是随机的句子。
4.14、Sentence Order Prediction (SOP):SOP使用同一文档中的两个连续片段作为正例;使用两个连续片段,但顺序互换为反例。为了更好地建模句子之间的连贯性,ALBERT 采用SOP 来代替了 NSP。ALBERT 认为 NSP 将 topic prediction 和 coherence prediction糅合到了一个任务中。 因此该数据集构造情况下,模型仅仅是依靠了较容易的任务:topic prediction 就实现了分类。
5、模型对应的损失函数
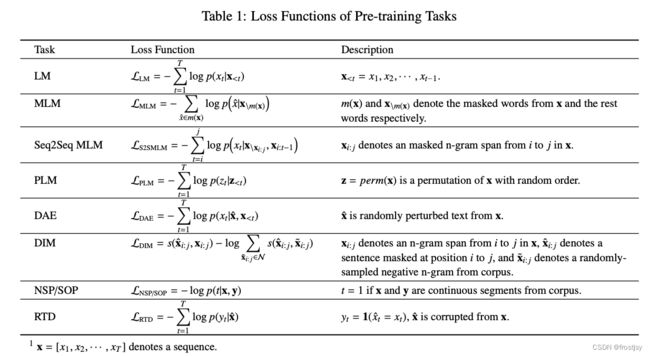
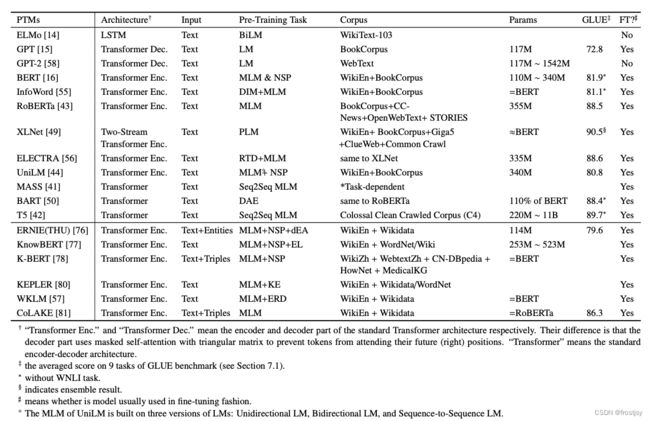
6、模型对应的语料、参数量、性能
7、参考文献
NLP中预训练模型的综述I[深度长文-慎点] - 知乎 (预训练综述文章)
SpanBert:对 Bert 预训练的一次深度探索 - 知乎 (spanbert)
https://arxiv.org/pdf/2003.08271.pdf (21年前预训练模型的综述论文)
NLP预训练模型分类及预训练任务 - 知乎 (与这篇论文对应https://arxiv.org/pdf/2003.08271.pdf)