Taichi(太极)粗糙的学习笔记&TaichiNeRF代码分析
最近搞实时渲染要用Taichi,遂学 https://github.com/taichi-dev/taichi-nerfs#train-with-preprocessed-datasets
我的Taichi版本: v1.6.0 (不同版本区别还挺大的)
reference: https://docs.taichi-lang.cn/docs/hello_world

文章目录
- 一、快速上手
- 二、Kernel与function
-
- 2.1 Taichi核与Taichi函数
- 2.2 Taichi核的输入与返回值
- 2.3 全局变量是编译时常量
- 2.4 Taichi函数
- 三、数据类型
-
- 3.1 基础数据类型
- 3.2 数据类型转换
- 3.3 复合类型(Compound)
- 四、数据容器
-
- 4.1 Field
-
- 4.1.1 Scalar Field
- 4.1.2 vector Field
- 4.1.3 Matrix Field
- 4.1.4 Structure Field
- 4.1.4 布局101: 从shape到ti.root.x
- 4.1.5 行主序 vs. 列主序
- 4.1.6 AoS(Array of Structures) vs. SoA(Structure of Arrays)
- 4.1.7 Field的手动分配和销毁
- 4.2 Taichi Ndarray
- 4.3 空间稀疏数据结构
-
- 4.3.1 指针SNode
- 4.3.2 位掩码SNode
- 4.3.3 动态SNode
- 4.3.4 空间稀疏数据结构的计算
- 4.4 偏移坐标
- 4.5 与外部数组进行交互
- 五、可微编程
-
- 5.1 `ti.ad.Tape()`
-
- 5.1.1 案例:粒子势能模拟
- 5.2 `kernel.grad()`
- 六、高级编程
-
- 6.1 元编程
-
- 6.1.1 field/Matrix/Vector的元数据
- 6.1.2 编译时评估
- 6.2 面向数据对象式的编程
- 6.3 `@ti.data_orineted`
- 6.4 `@ti.dataclass`
- 七、可视化
-
- 7.1 GUI
-
- 7.1.1 坐标系统
- 7.1.2在窗口上绘画
- 7.2 GUI窗口部件
- 7.3 GGUI
- 八、性能调优
-
- 8.1 ScopedProfiler
- 8.2 KernelProfiler
- 8.3 性能优化
- 九、Taichi的Debug
- 十、内部设计
-
- 10.1 SNode
- 10.2 一个Taichi Kernel的生命周期
- 十一、数学函数库
-
- 11.1 常用运算符
- 11.2 稀疏矩阵
- 十二、常用API
-
- 12.1 变量和循环
- 12.2 语法糖
- 十三、Taichi + InstantNGP ⭐
-
- 13.1 简介
- 13.2 Taichi-InstantNGP代码结构图
- Reference:
一、快速上手
Taichi是一个嵌入在Python中的领域特定语言(DSL)。
Taichi实现功能依靠两个装饰器: @ti.func和 @ti.kernel,这两个装饰器使得Taichi接管计算任务并借助Taichi的JIT(Just In Time)机制将被装饰的函数编译为机器码。
在CPU或GPU上使用Taichi,相比于原生的python程序,可以提速50到100倍。
Taichi还提供了一个叫AOT(A head Of Time)的东西,可以将代码直接变成可执行文件,甚至在没有Python环境的地方运行。
支持Python3.7,3.8,3.9,3.10
import taichi as ti
# taichi.math模块提供了内置的低维度的向量和矩阵数据结构。
import taichi.math as tm
ti.init(arch=ti.gpu) # ti.init()函数用于初始化Taichi运行时环境,arch参数用于指定运行时环境的硬件平台,这里指定为GPU。
n = 320
# ti.field()函数用于定义一个Taichi域,这里定义了一个二维的浮点数域,用于存储图像的像素值。
pixels = ti.field(dtype=float, shape=(n*2, n))
- Taichi域是一种很常用的数据结构,和ndarray类似,但是Taichi域可以是稀疏的数据。
- 被
@ti.func装饰的函数叫Taichi函数,被@ti.kernel装饰的叫Taichi核,这俩都不会被Python解释器执行,而是由于Taichi JIT Complier执行并部署在并行CPU或者GPU上。- (1)
@ti.kernel类似于C语言的main函数,可以在程序的任意位置调用。 - (2)
@ti.func只能被其他@ti.func或者@ti.kernel调用。 - (3) 被
@ti.kernel和@ti.func修饰的函数的传入参数和返回值都必须标明类型(Type Hinted)。 - (4)
@ti.func不支持递归。
- (1)
# 下面是用 Taichi 写的一个简单的
import taichi as ti
import taichi.math as tm
ti.init(arch=ti.gpu) # ti.init()函数用于初始化Taichi运行时环境,arch参数用于指定运行时环境的硬件平台,这里指定为GPU。
n = 320
# ti.field()函数用于定义一个Taichi域,这里定义了一个二维的浮点数域,用于存储图像的像素值。
pixels = ti.field(dtype=float, shape=(n*2, n))
@ti.func
def complex_sqrt(z):
return ti.Vector([z[0]**2 - z[1]**2, z[1] * z[0] * 2])
@ti.kernel
def paint(t: float):
for i, j in pixels:
c = tm.vec2(-0.8, tm.cos(t) * 0.2)
z = tm.vec2(i / n - 1, j / n - 0.5) * 2
iterations = 0
while z.norm() < 20 and iterations < 50:
z = complex_sqrt(z) + c
iterations += 1
pixels[i,j] = 1 - iterations * 0.02
[Taichi] Starting on arch=cuda
Taichi中并行执行的for循环
- Taichi为并行化任务提供了一种方便的语法,kernel中最外层范围的任何for循环都会自动并行化,免去了手动分配多线程。
- 嵌套在if/else下面的for循环不会自动并行化,而是按顺序处理。且并行循环不支持break语句。
为了将结果渲染到屏幕上,Taichi内置一个GUI系统,使用gui.set_image()可以设置窗口内容,调用gui.show()进行可视化。
Taichi 的 GUI 系统使用标准的笛卡尔坐标系来定义像素坐标。 坐标系的原点位于屏幕的左下角。 以像素为单位的(0, 0)元素会映射到窗口的左下角,(639, 319)元素会映射到窗口的右上角,如下图所示:
import taichi as ti
gui = ti.GUI("Julia Set", res=(n * 2, n))
i = 0
while gui.running:
paint(i*0.03)
gui.set_image(pixels)
gui.show()
i += 1
在当前单元格或上一个单元格中执行代码时 Kernel 崩溃。请查看单元格中的代码,以确定故障的可能原因。有关详细信息,请单击 此处。有关更多详细信息,请查看 Jupyter log。

Taichi支持的系统和后端:
| 平台 | CPU | GPU | OpenGL |
|---|---|---|---|
| windows | √ | √ | √ |
| linux | √ | √ | √ |
| macOS | √ | × | × |
# Python的大型for循环,或嵌套 for 循环总是导致运行时性能不佳。 下面的 demo 计算在指定范围内的质数,并用到了嵌套 for 循环。
# 统计质数个数 Python版本
import time
start_time = time.time()
def is_prime(n: int):
result = True
for k in range(2, int(n ** 0.5) + 1):
if n % k == 0:
result = False
break
return result
def count_prime(n: int):
count = 0
for i in range(2, n):
if is_prime(i):
count += 1
return count
end_time = time.time()
print(count_prime(100000))
9592
import taichi as ti
import time
ti.init(arch=ti.cpu)
start_time = time.time()
# 统计质数个数 Taichi版本
@ti.func
def is_prime(n: int):
result = True
for k in range(2, int(n ** 0.5) + 1):
if n % k == 0:
result = False
break
return result
@ti.kernel
def count_prime(n: int) -> int:
count = 0
for i in range(2, n):
if is_prime(i):
count += 1
return count
end_time = time.time()
print(count_prime(100000))
[Taichi] Starting on arch=x64
9592
-
Taichi 让物理模拟程序变得更易读和直观,同时仍然达到与 C++ 或 CUDA 相当的性能。 只需拥有基本 Python 编程技能,就可以使用 Taichi 用更少的代码编写高性能并行程序,从而关注较高层次的算法本身,把诸如性能优化的任务交由 Taichi 处理。
-
Taichi加速Pytorch,就算疯狂写for循环,Taichi对并行的控制更精细。之后介绍两个例子来介绍Taichi如何与Pytorch结合。
二、Kernel与function
2.1 Taichi核与Taichi函数
-
Taichi主要有两个装饰器:
@ti.kernel和@ti.func@ti.kernel被称作Taichi核(Taichi Kernel), 被Taichi核装饰的函数是Taichi接管整个程序的入口(将计算密集型的任务丢给Taichi),Taichi核可以被普通python函数调用; Taichi核的输入和返回值是需要指明数据类型的。@ti.func被称作Taichi函数(Taichi Functions), Taichi函数只能被其他Taichi函数或者Taichi核调用。
-
Taichi核或者Taichi函数内部的代码是Taichi的作用域。Taichi作用域内的代码在多核CPU或GPU设备上并行编译和执行这些代码,以实现高性能计算端。
# 简单演示ti.kernel和ti.function
import taichi as ti
ti.init(arch=ti.cpu)
@ti.func
def inv_square(x):
return 1.0 / (x*x)
@ti.kernel
def partial_sum(n: int) -> float:
total = 0.0
for i in range(1, n+1):
total += inv_square(i) # ti.kernel调用ti.function
return total
partial_sum(1000) # python直接调用ti.kernel
[Taichi] Starting on arch=x64
2.2 Taichi核的输入与返回值
- Taichi核从python虚拟中接管程序,一个Taichi Program中可以定义多个Taichi核,这些核是彼此独立的,他们的编译和运行顺序是按照第一次调用的顺序排布的,调用过的Taichi核会存到cache里,以便下一次调用。
注意: 只有普通Python能调用Taichi核,在另一个Taichi核或者Taichi函数里是无法调用Taichi核的。 - Taichi核接收的参数一定要是静态的,因为这个是编译执行的且只编译一次。
- Taichi核可以接受的参数包括:
scalars,ti.types.matrix(),ti.types.vector(),ti.types.struct(),ti.types.ndarray(),ti.types.template()。 - 注意:
ti.types.matrix(),ti.types.vector(),ti.types.struct()传的是值,但是ti.types.ndarray(),ti.types.template()传的是指针。 - 下面是一个传入数据的演示:
import numpy as np
@ti.kernel
def my_kernel(x: ti.types.ndarray()) -> float:
sum_x = 0.0
x[0] += 1
for i in range(x.shape[0]):
sum_x += x[i]
return sum_x
my_array = np.array([1, 2, 3])
print(my_kernel(my_array))
print(my_array)
# -----------------------------
# 原始的array也被修改了
# 7.0
# [2 2 3]
7.0
[2 2 3]
- 下面是一个传变换矩阵结构体的例子:
import taichi as ti
ti.init(arch=ti.cpu)
transform_type = ti.types.struct(R=ti.math.mat3, T=ti.math.vec3)
pos_type = ti.types.struct(x=ti.math.vec3, trans=transform_type)
@ti.kernel
def kernel_with_struct(p: pos_type) -> ti.math.vec3:
return p.trans.R @ p.x + p.trans.T
trans = transform_type(ti.math.mat3(1), [1, 1, 1]) # 单位阵和(1,1,1)平移矩阵
p = pos_type(x=[1, 1, 1], trans=trans)
print(kernel_with_struct(p))
# ----------------------------
# [Taichi] Starting on arch=x64
# [4. 4. 4.]
[Taichi] Starting on arch=x64
[4. 4. 4.]
- 将NumPy中的ndarray或PyTorch中的张量传递到内核。Taichi识别这些数据结构的形状和数据类型,这允许您在内核中访问它们的属性。
- 返回值: taichi核的返回值最多有一个, 而且只能属于以下数据类型:
ti.types.matrix(),ti.types.vector(),ti.types.struct() - 如果返回的是
ti.types.struct(), 注意这个结构体不能超过32个成员,如果超过了,内核仍旧会编译,但是会报warning。
# 下面是一个返回值为ti.struct的代码示例
import taichi as ti
s0 = ti.types.struct(a=ti.math.vec3, b=ti.i16)
s1 = ti.types.struct(a=ti.f32, b=s0)
@ti.kernel
def foo() -> s1:
return s1(a=1.0, b=s0(a=[1, 2, 3], b=4))
print(foo())
# -----------------------------------
# {'a': 1.0, 'b': {'a': [1.0, 2.0, 3.0], 'b': 4}}
{'a': 1.0, 'b': {'a': [1.0, 2.0, 3.0], 'b': 4}}
- taichi.kernel的返回值是可以进行简单的自动类型转换的。
- taichi.kernel做多只能有一个return语句
import taichi as ti
@ti.kernel
def my_kernel() -> ti.i32:
return 1.234
print(my_kernel())
# ------------------------
# 1
1
2.3 全局变量是编译时常量
在Taichi中,Taichi核将全局变量视作编译时的常量,即: 在编译的时候,这个变量就定下来了,即便后面再修改这个变量也无济于事。下面这个例子可以看得到:
运行kernel_1的时候,整体编译第一次,a = 1,之后kernel_1存在cache里面,不需要编译了
运行kernel_2的时候,又编译了一次,a的值才发生变化。
import taichi as ti
ti.init()
a = 1
@ti.kernel
def kernel_1():
print(a)
@ti.kernel
def kernel_2():
print(a)
kernel_1()
a = 2
kernel_1()
kernel_2()
# ------------------------
# 1
# 1
# 2
[Taichi] Starting on arch=x64
2.4 Taichi函数
-
一个Taichi函数可以传多个参数,包括:
scalar,ti.types.matrix(),ti.types.vector(),ti.types.struct(),ti.types.ndarray(),ti.field(),ti.template()。 -
有一些对于ti.kernel的限制对ti,function并不适用:
- @ti.functions不需要hint,但还是推荐这样。
- 输入参数的数量不限制。
-
不同于Taichi核,Taichi函数可以有多个返回值,类型包括:
scalars,ti.types.matrix(),ti.types.vector(),ti.types.struct()。
下面介绍一些基础背景:
-
Taichi核与Taichi函数对比:
kernel function 调用范围 Python Scope Taichi Scope 参数与返回值的类型提示(Hint) 必须 不必须 返回类型 scalarti.types.matrix()ti.types.struct()almost all return返回元素上限 1 无限制 -
一些专业术语
- 后端: 这里的后端指的是执行代码的地方,比如cpu, opengl,cuda和vulkan。
- 元编程: 元编程是指程序操纵程序,就Taichi而言,元编程的意思是使用编译出的实例运行程序。
-
要记住,kernel 是 Taichi 运行时执行的最小单位!
三、数据类型
-
Taichi是一种静态的编程语言,即一个变量的数据类型在编译的时候就定死了,即一个变量名只能用来表达一种数据类型,不同重复用一个变量名去命名不同的数据类型。
-
ti.types里面包含了taichi支持的所有数据类型,数据类型主要分为两类:- (1)
私有(private)变量: 包含一些常见的数据类型,ti.i32,tiu8,ti.f64。 - (2)
复合(compound)变量: 不是单个数的就叫compound,比如:ti.types.matrix,ti.types.ndarry,ti.types.struct
- (1)
# 如果在taichi scope中,我重复对一个变量赋值
import taichi as ti
ti.init()
@ti.kernel
def test():
x = 1
x = 3.14 # 这里不会报错,因为还是相同的数据类型
# x = ti.Vector([1, 1])
test()
# RuntimeError: [type_factory.cpp:taichi::lang::promoted_type@228]
# a = i32, b = [Tensor (2) i32], only one of them is a tensor type
[Taichi] Starting on arch=x64
3.1 基础数据类型
- Taichi中的private变量就是标量(scalar),下表是不同后端上的的数据类型都有啥:
| 后端 | i8 | i16 | i32 | i64 | u8 | u16 | u32 | u64 | f16 | f32 | f64 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| CPU | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| CUDA | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| OpenGL | ❌ | ❌ | ✔️ | ⭕ | ❌ | ❌ | ❌ | ❌ | ❌ | ✔️ | ✔️ |
| Metal | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ❌ | ✔️ | ❌ |
| Vulkan | ⭕ | ⭕ | ✔️ | ⭕ | ⭕ | ⭕ | ✔️ | ⭕ | ✔️ | ✔️ | ⭕ |
-
在初始化Taichi的时候,Taichi会默认使用
ti.i32和ti.f32作为默认的标量数据类型。但是你可以修改这个默认设定:ti.init(default_ip=ti.i64) ti.init(default_fp=ti.f64) -
在Taichi Scope中,
int()和float()其实就是ti.i64和ti.f64的化名。 -
在python作用域中,当声明 Taichi的containers 时候使用
ti.field,ti.Vector,ti.Matrix等等import taichi as ti x = ti.field(float, 5) # 等价于x = ti.field(ti.f64, 5)
3.2 数据类型转换
一个变量的数据类型在Taichi Scope中定义时就已经确定了,说明Taichi中的变量是静态变量。Taichi编译器在编译的时候会检查类型检查。当一个Taichi Variable被定义了以后,就不能再用赋值的方式更换这个变量名的数据类型了。
# 显示数据类型转换
import taichi as ti
# ti.cast()可以进行显示的数据类型转换,例如:
@ti.kernel
def foo():
a = 3.14
print(a)
b = ti.cast(a, ti.i32)
c = ti.cast(b, int)
print(c)
foo()
# 隐式数据类型转换
# 当一个变量在某个不合理的位置引用时候就会自动进行隐式的数据类型转换
# i32 + f32 -> f32
# i16 + f16 -> f16
# i16 + i32 -> i32
# f16 + f32 -> f32
# u8 + u16 -> u16
import taichi as ti
@ti.kernel
def foo()->ti.f32:
a = 1
b = 2.0
c = a + b
return c
foo()
3.0
3.3 复合类型(Compound)
复合类型是User自定义的数据类型,由多个元素组成,支持的复合类型包括: ti.types.vector(), ti.types.matrix(), ti.types.ndarray(), ti.types.structure()。
import taichi as ti
ti.init()
vec4d = ti.types.vector(4, ti.f64)
mat4x3i = ti.types.matrix(4, 3, int)
# 你可以自定义一个复合类型,然后用这个自己取的名字去初始化变量或者用作hint
v = vec4d(1, 2, 3, 4)
@ti.func
def length(w):
return w.norm()
@ti.kernel
def test() -> ti.f64:
return length(v)
test()
[Taichi] Starting on arch=x64
5.4772257804870605
# 用Taichi结构体写个球
vec3 = ti.types.vector(3, float) # 球心
sphere_type = ti.types.struct(center=vec3, radius=float)
sphere1 = sphere_type(center=[0, 0, 0], radius=1.0)
但是上面的方法定义结构体太难受了,因此taichi支持用@ti.dataclass这种装饰器来定义结构体类型ti.types.struct。
使用@ti.dataclass还可以声明结构体的函数,实现Taichi的面向对象编程
@ti.dataclass
class Sphere:
center: vec3
radius: float
sphere2 = Sphere(center=[0, 0, 0], radius=1.0)
Taichi中只有vectors和matrices支持数据类型转换
import taichi as ti
ti.init()
@ti.func
def foo():
u = ti.Vector([2.3, 4.7])
v = int(u)
v = ti.cast(u, ti.i32)
return v
@ti.kernel
def main():
print(foo())
main()
[Taichi] Starting on arch=x64
四、数据容器
Taichi Field是全局数据容器,从Python Scope还是Taichi Scope都能访问。
Field对于Taichi就像tensor对于torch,ndarray对于numpy。
Field中的元素可以是Scalar,Vector,Matrix,Struct。
4.1 Field
4.1.1 Scalar Field
-
scalar field存储的是标量,是最基本的field。零维的scalar field是单个标量。一维的scalar field是由标量组成的一个一维数组。一个二维标量field是由标量组成的二维数组。
-
如何定义scalar field?
ti.field(dttype, shape),其中dtype是private variable type, shape是元组。 -
需要改field的value话直接赋值就行
import taichi as ti
ti.init()
# 初始化的时候默认值为0
f_0d = ti.field(ti.f32, shape=())
# ---------------------------------
# ┌─────┐
# │ │
# └─────┘
# └─────┘
# f_0d.shape=()
f_1d = ti.field(ti.i32, shape=9)
# ---------------------------------
# ┌───┬───┬───┬───┬───┬───┬───┬───┬───┐
# │ │ │ │ │ │ │ │ │ │
# └───┴───┴───┴───┴───┴───┴───┴───┴───┘
# └───────────────────────────────────┘
# f_1d.shape = (9,)
f_2d = ti.field(ti.f32, shape=(3, 6))
# ---------------------------------
# f_2d.shape[1]
# (=6)
# ┌───────────────────────┐
# ┌ ┌───┬───┬───┬───┬───┬───┐ ┐
# │ │ │ │ │ │ │ │ │
# │ ├───┼───┼───┼───┼───┼───┤ │
# f_2d.shape[0] │ │ │ │ │ │ │ │ │
# (=3) │ ├───┼───┼───┼───┼───┼───┤ │
# │ │ │ │ │ │ │ │ │
# └ └───┴───┴───┴───┴───┴───┘ ┘
[Taichi] Starting on arch=x64
# 零维field在索引的时候记得要加个None
print(f_0d[None])
print(f_1d[0])
# 循环索引
f_2d = ti.field(ti.f32, shape=(16, 16))
@ti.kernel
def loop_over_2d():
for i, j in f_2d:
f_2d[i, j] = i + j
loop_over_2d()
print(f_2d)
# ------------------------------
# 0.0
# 0
# [[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]
# [ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16.]
# [ 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.]
# [ 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.]
# [ 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19.]
# [ 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.]
# [ 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21.]
# [ 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22.]
# [ 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23.]
# [ 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24.]
# [10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25.]
# [11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26.]
# [12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27.]
# [13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.]
# [14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29.]
# [15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30.]]
0.0
0
[[ 0. 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15.]
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16.]
[ 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17.]
[ 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18.]
[ 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19.]
[ 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20.]
[ 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21.]
[ 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22.]
[ 8. 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23.]
[ 9. 10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24.]
[10. 11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25.]
[11. 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26.]
[12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27.]
[13. 14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28.]
[14. 15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29.]
[15. 16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30.]]
-
注意taichi不支持切片(slice)索引
for x in f_2d[0]:会报错f_2d[0][3:]=[4,5,6]会报错
-
查看Taichi field的数据类型或者大小,直接:
ti.shapeti.dtype
# 随机生成一张640×480的灰度图
import taichi as ti
ti.init()
w, h = 640, 480
gray_scale_img = ti.field(dtype=ti.f32, shape=(w, h))
@ti.kernel
def fill_image():
for i, j in gray_scale_img:
gray_scale_img[i, j] = ti.random()
fill_image()
# 创建一个GUI来可视化这个ti灰度图
gui = ti.GUI('gray scale random image', (w, h))
while gui.running:
gui.set_image(gray_scale_img)
gui.show()
[Taichi] Starting on arch=x64
# 填充field
x = ti.field(int, shape=(5, 5))
x.fill(1)
@ti.kernel
def test():
x.fill(-1)
4.1.2 vector Field
Scalar field的意思是基本索引单元是一个scalar,vector field的意思是基本索引单元为一个vector。
# 定义一个3D的vector field
import taichi as ti
ti.init()
f = ti.Vector.field(n=2, dtype=float, shape=(3, 3)) # 3*3的field,每一个vector的长度为2
f.shape # (3, 3)
# -----------------------------------
# f.shape[1]
# (=3)
# ┌────────────────────┐
# ┌ ┌──────┬──────┬──────┐ ┐
# │ │[*, *]│[*, *]│[*, *]│ │
# │ ├──────┼──────┼──────┤ │
# f.shape[0] │ │[*, *]│[*, *]│[*, *]│ │ [*, *]
# (=3) │ ├──────┼──────┼──────┤ │ └─────┘
# │ │[*, *]│[*, *]│[*, *]│ │ n=2
# └ └──────┴──────┴──────┘ ┘
[Taichi] Starting on arch=x64
(3, 3)
box_size = (300, 300, 300)
volumetric_field = ti.Vector.field(n=4, dtype=ti.f32, shape=box_size)
# 要分开一个读vectore field 一个读vector
volumetric_field[0, 0, 0][0] # 这样可以访问
volumetric_field[0, 0, 0].x = 1
print(volumetric_field[0, 0, 0].xyz)
# --------------------------------------------
# [1. 0. 0.]
n, w, h = 3, 128, 64
vec_field = ti.Vector.field(n, dtype=float, shape=(w, h))
@ti.kernel
def fill_vector():
for i, j in vec_field:
for k in ti.static(range(n)):
vec_field[i, j][k] = ti.random()
fill_vector()
print(vec_field.to_numpy()[w-1, h-1, n-1])
# --------------------------------------------
# 0.9816982
[1. 0. 0.]
0.8765496
4.1.3 Matrix Field
Matrix Field的每一个元素是一个2D矩阵,靠n,m定义
import taichi as ti
ti.init()
matrix_field = ti.Matrix.field(n=2, m=3, dtype=ti.f32, shape=(300, 400, 500))
@ti.kernel
def test():
for i in ti.grouped(matrix_field):
matrix_field[i] = [[1, 1, 1], [1, 1, 1]]
test()
# shape尽可能大一些,然后nm尽可能小一些,能缩短编译时间
[Taichi] Starting on arch=x64
4.1.4 Structure Field
- 下面的代码片段用
ti.Struct.field()来声明粒子信息的1D字段(位置、速度、加速度和质量),请注意:- 成员变量
pos,vel,acc和质量均以字典格式提供。 - 可以将复合类型(compound):
ti.types.vector,ti.types.matrix,ti.types.struct作为结构体成员。
- 成员变量
# 定义n个结构体
import taichi as ti
n = 10
particle_field = ti.Struct.field({
"pos": ti.math.vec3,
"vel": ti.math.vec3,
"acc": ti.math.vec3,
"mass": ti.f32,
}, shape=(n,)) # 定义n个结构体
# 也可以这样定义
# vec3 = ti.math.vec3
# n = 10
# particle = ti.types.struct(
# pos=vec3, vel=vec3, acc=vec3, mass=float,
# )
# particle_field = particle.field(shape=(n,))
particle_field[0].pos = [1, 2, 3]
particle_field[0].mass = 1.0
print(particle_field[0].mass, particle_field.mass[0]) # 怎么索引都行
1.0 1.0
cpu的运算速度是远快于内存的,为了缩小这一性能差距,计算机架构中采用了多级缓存系统和高带宽多通道内存。之后介绍如何高效的组织数据布局和管理内存占用。
4.1.4 布局101: 从shape到ti.root.x
-
在基本使用中,我们用
shape描述符来构建一个field,Taichi提供了灵活的语句:ti.root.x,用于描述更复杂的数据组织。 -
ti.root.x语句逐步将field的形状绑定到对应的轴,Taichi编译器能自动推断底层的数据布局并应用合适的数据读取顺序。 -
以下是用
ti.root.x替代shape描述符的例子:
import taichi as ti
x = ti.field(ti.f32)
ti.root.place(x)
# 等效于 x = ti.field(ti.f32, shape=())
# 声明一个shape=3的一维field
# x = ti.field(ti.f32, shape=3)
x = ti.field(ti.f32)
ti.root.dense(ti.i, 3).place(x)
# 声明一个shape=(3, 4)的二维field
# x = ti.field(ti.f32, shape=(3, 4))
x = ti.field(ti.f32)
ti.root.dense(ti.ij, (3, 4)).place(x)
# 也可以:
# x = ti.field(ti.f32)
# ti.root.dense(ti.i, 3).dense(ti.j, 4).place(x)

4.1.5 行主序 vs. 列主序
对于多维field,我们可以通过以下两种方式将高维索引引平展开到线性内存地址空间: 以一个形状为(M,N)的二维field为例,我们可以用长度为N的一维缓冲器存储M行,即行主序(base+i*N+j),或者存储N列,称为列主序(base+j*M+i)。
Taichi默认是行主序的,你可以通过ti.root这样定义field:
(尽管行主序和列主序不同,但是[i,j]访问的都是第i行第j列的元素)
import taichi as ti
ti.init()
M, N = 3, 4
x = ti.field(ti.f32)
y = ti.field(ti.f32)
ti.root.dense(ti.i, M).dense(ti.j, N).place(x) # 行主序
ti.root.dense(ti.j, N).dense(ti.i, M).place(y) # 列主序
# -----------------------------------------------------
# address: low ........................................... high
# x: x[0, 0] x[0, 1] x[1, 0] x[1, 1] x[2, 0] x[2, 1]
# y: y[0, 0] y[1, 0] y[2, 0] y[0, 1] y[1, 1] y[2, 1]
[Taichi] Starting on arch=x64
4.1.6 AoS(Array of Structures) vs. SoA(Structure of Arrays)
AoS是结构体组成的数组,用AoS存储RGB图像在内存中的线性地址是RGBRGBRGB, SoA是数组组成的结构体,用SoA存储的RGB图像在内存中的地址是RRRGGGBBB。 (每一个结构体是RGB)
正如前面说的,无论是AoS还是SoA,索引都是先行后列,因此可以在不改变索引的情况下直接修改数据在内存中的存储布局。
# 使用 `ti.root.x` 语句构建AoS和SoA
import taichi as ti
ti.init()
M, N = 3, 4
# SoA: 数组组成的结构体
x = ti.field(ti.f32)
y = ti.field(ti.f32)
ti.root.dense(ti.i, M).place(x, y)
# --------------------------------------
# 内存中:
# address: low ................................. high
# x[0] x[1] x[2] ... y[0] y[1] y[2] ...
# AoS: 结构体组成的数组
ti.root.dense(ti.i, M).place(x, y)
# --------------------------------------
# 内存中:
# address: low .............................. high
# x[0] y[0] x[1] y[1] x[2] y[2] ...
下面通过一个demo展示一下改变数据在内存中的结构有啥好处:
import taichi as ti
ti.init()
N = 2000000000
a = ti.field(ti.f32)
b = ti.field(ti.f32)
c = ti.field(ti.f32)
ti.root.dense(ti.i, N).place(a)
ti.root.dense(ti.i, N).place(b)
ti.root.dense(ti.i, N).place(c)
@ti.kernel
def step():
for i in range(N):
c[i] = a[i] + b[i]
# -----------------------------
# AoS存储,上面的代码需要5.2s
[Taichi] Starting on arch=x64
import taichi as ti
ti.init()
N = 2000000000
a = ti.field(ti.f32)
b = ti.field(ti.f32)
c = ti.field(ti.f32)
ti.root.dense(ti.i, N).place(a, b, c)
# Array of Structure说白了就是(a,b,c)作为一个structure连续存放
@ti.kernel
def step():
for i in range(N):
c[i] = a[i] + b[i]
# -----------------------------
# AoS存储,上面的代码需要5.8s
[Taichi] Starting on arch=x64
4.1.7 Field的手动分配和销毁
- 强烈建议使用二次幂形式的块形状,以便通过位运算加速索引。
- 一般情况下,Taichi对内存的分配和销毁是不可见的,不过,用户有时候会需要接管他们的内存分配。
- Taichi本身是有自动管理内存分配和回收的能力的。
import taichi as ti
ti.init()
@ti.kernel
def func(v: ti.template()):
for I in ti.grouped(v):
v[I] += 1
fb1 = ti.FieldsBuilder()
x = ti.field(dtype=ti.f32)
fb1.dense(ti.ij, (5,5)).place(x)
fb1_snode_tree = fb1.finalize() # 删除
func(x)
fb1_snode_tree.destroy()
[Taichi] Starting on arch=x64
4.2 Taichi Ndarray
-
Taichi Ndarray是一个多维连续存储的对象,和
np.ndarray差不多,但是它存储在用户设定的taichi arch上,并且有Taichi Runtime管理。 -
大多数情况下可以直接把
ti.field当作数据容器用,但是ti.field的存储结构可能是稀疏且复杂的,外部库无法直接把存储在ti.field的数据直接拿过来用,ti.ndarray这种数据类型是连续存储的,并且很容易和外部库进行交互。 -
注意:
- 定义
ti.ndarray时候用:x = ti.ndarray(dtype=ti.f32, shape=(4,4)) - hint输入输出类型时候用:
ti.dtypes.ndarray(dtype=ti.f32, ndim=2)
- 定义
-
和field一样,ti.ndarray只能在python scope下定义,不能在taichi scope下定义!
-
ti.field和ti.ndarray都是存储在ti.init指定的架构里。
-
建议在单个Taichi内核中执行计算密集型任务,而不是在Python范围内单独对数组元素进行操作。
import taichi as ti
ti.init()
# 在Python Scope中使用 Taichi Ndarray
# dtype可以是scalar type: ti.f32等, 也可以是vector/matrix type: ti.math.vec3等
arr = ti.ndarray(dtype=ti.math.vec3, shape=(4, 4)) # [4, 4] * [3]
# 填充
arr.fill(1.0)
# 读写
# print(arr[0, 0])
arr[0, 0] = [1.0, 2.0, 3.0]
arr[0, 0][1] = 1.9
# print(arr[0, 0])
# -----------------------------------
# [Taichi] Starting on arch=x64
# [1. 1. 1.]
# [1. 1.89999998 3. ]
# Copy(Deep&Shallow)
b = ti.ndarray(dtype=ti.math.vec3, shape=(4, 4))
b.copy_from(arr)
import copy
c = copy.copy(b)
d = arr.to_numpy()
d[0,0,0] = 100.0
print(arr[0,0], d[0,0])
# to_numpy之后,修改Numpy不影响之前的field
# [1. 1.89999998 3. ] [100. 1.9 3. ]
[Taichi] Starting on arch=x64
[1. 1.89999998 3. ] [100. 1.9 3. ]
# 在Taichi核中使用 Taichi Ndarray
@ti.kernel
def foo(A: ti.types.ndarray()):
pass
import taichi as ti
ti.init(arch=ti.cuda)
arr_ty = ti.types.ndarray(dtype=ti.math.vec3, ndim=2)
@ti.kernel
def proc(rgb_map: arr_ty):
for I in ti.grouped(rgb_map):
rgb_map[I] = [1.0, 2.0, 3.0]
rgb = ti.ndarray(dtype=ti.math.vec3, shape=(8, 8))
proc(rgb)
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=cuda
import taichi as ti
import numpy as np
import torch
ti.init(arch=ti.cuda)
@ti.kernel
def add_one(arr: ti.types.ndarray(dtype=ti.f32, ndim=2)):
for I in ti.grouped(arr):
arr[I] += 1.0
arr_np = np.ones((8, 8), dtype=np.float32)
add_one(arr_np)
# field和tensor都在cuda上,直接修改tensor,不会浪费内存
arr_torch = torch.ones((8, 8), dtype=torch.float32).to('cuda:0')
add_one(arr_torch)
arr_np, arr_torch
# =============================
# [Taichi] Starting on arch=cuda
# (array([[2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.]], dtype=float32),
# tensor([[2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.],
# [2., 2., 2., 2., 2., 2., 2., 2.]], device='cuda:0'))
[Taichi] Starting on arch=cuda
(array([[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.]], dtype=float32),
tensor([[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.],
[2., 2., 2., 2., 2., 2., 2., 2.]], device='cuda:0'))
4.3 空间稀疏数据结构
-
在物理建模、图形学仿真和三维重建中,经常用到高分辨率2D/3D mesh,这种数据结构是sparse的,如果我们用dense的数据结构存储这些mesh,就要存好多空值,这很浪费内存。
-
以往,稀疏数据存储在四叉树(2D)或者八叉树(3D),考虑到计算机架构中,解引用指针的计算成本也比较高,四叉树和八叉树对性能的友好程度不如支因子更大的浅层树,例如VDB,SPGrid。在Taichi中,你可以使用SNode组成类似与VDB和SPGrid的数据结构。
-
Taichi的数据结构是用
SNode(Structure Node)组织的,这个听起来很迷,SNode主要包含:SNode containers,SNode cells,SNode components:SNode containers: 一个SNode容器有很多SNode cells, 例如S = ti.root.dense(ti.i, 128)代表S这个SNode有128个 S cells。SNode cell:一个SNode cell有很多SNode componentsSNode components: 每个SNode Component是较低级别SNode的SNode容器。
-
Taichi中的空间稀疏数据结构由
pointer,bitmasked,dynamic,denseSNode组成。 -
在空间稀疏数据结构中,如果一个像素,体素或者一个网格节点被分配参与计算,我们就认为它是活跃的,网格其他部分就是不活跃的。我们用一个布尔值表示是否活跃,称为该体素/像素的激活值。
4.3.1 指针SNode
- 指针块 + 每个指针指向一个dense block
block=ti.root.pointer+block.dense
import taichi as ti
ti.init()
x = ti.field(ti.f32)
block = ti.root.pointer(ti.ij, (4, 4)) # 4*4的指针
pixel = block.dense(ti.ij, (2, 2)) # 每个指针指向一个2*2的block
pixel.place(x)
@ti.kernel
def activate():
x[2,3] = 1.0
x[2,4] = 2.0
@ti.kernel
def print_active():
for i, j in block:
print("Active block", i, j)
for i, j in x:
print("Field x[{}, {}] = {}".format(i, j, x[i, j]))
activate()
print_active()
# ------------------------------------------------
# [Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
# [Taichi] Starting on arch=x64
# Active block 1 1
# Active block 1 2
# Field x[2, 2] = 0.000000
# Field x[2, 3] = 1.000000
# Field x[2, 4] = 2.000000
# Field x[3, 2] = 0.000000
# Field x[2, 5] = 0.000000
# Field x[3, 4] = 0.000000
# Field x[3, 3] = 0.000000
# Field x[3, 5] = 0.000000
[Taichi] Starting on arch=x64
x[2,3]被赋值,block[1,1]被激活,导致x[2,2], x[2,3], x[3,2], x[3,3]也被激活
x[2,4]被赋值,block[1,2]被激活,导致x[2,4], x[2,5], x[3,4], x[3,5]也被激活

上面的图只是示例,实际上是按照下图存储的:

4.3.2 位掩码SNode
-
用指针SNode的话,对于空的区域,也要浪费内存来存储指针(
block = ti.root.pointer(ti.ij, (4, 4))) -
为了避免指针的内存开销,之前的一个指针对应的块是稠密的,指针选中,则对应的block全活跃,为解决这个问题,在指针和block之间再插入一个mask即可。
-
block=ti.root.pointer+block.bitmasked
import taichi as ti
ti.init()
x = ti.field(ti.f32)
block = ti.root.pointer(ti.ij, (4, 4)) # 4*4的指针
pixel = block.bitmasked(ti.ij, (2, 2)) # 每个指针指向一个2*2的block,之前是block.dense
pixel.place(x)
@ti.kernel
def activate():
x[2,3] = 1.0
x[2,4] = 2.0
@ti.kernel
def print_active():
for i, j in block:
print("Active block", i, j)
for i, j in x:
print("Field x[{}, {}] = {}".format(i, j, x[i, j]))
[Taichi] Starting on arch=x64


4.3.3 动态SNode
-
v1.4.0之后,Taichi开始支持动态数据结构,可以把Taichi的动态SNode想象成和列表一样,它支持三种API:
append: 等效于python的appenddeactivate: 等效于python的clearlength: 等效于python的len
-
上面的三种方法必须在Taichi Scope下作用
-
遗憾的是,由于并行计算的编译难度,动态SNode不支持remove和pop。
-
动态SNode下不能再放置其他SNode,动态SNode必须放置在field中。
-
从SNode到根节点root的路径上如果有SNode,那么这两个SNode不能与当前Snode相同的轴。
import taichi as ti
ti.init()
# S的父节点是ti.root, 如果调用 S = P.dynamic()意思是S的父节点是P,这句话表明了S节点在Snode Tree中的位置
S = ti.root.dynamic(ti.i, 1024, chunk_size=32)
# dynamic的第一个参数是S所在的轴。
# 这个轴必须是一维的,不能被S的任何父节点使用。这里我们使用轴ti.i(相当于NumPy中的轴=0)。
# 1024代表S的最大长度,动态SNode按需动态分配内存: 有数据才占内存
x = ti.field(int)
S.place(x)
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=x64
import taichi as ti
ti.init()
@ti.kernel
def add_data():
for i in range(10):
x[i] = i
print(x.length())
add_data()
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=x64
---------------------------------------------------------------------------
TaichiNameError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_56756\1181762831.py in
8 print(x.length())
9
---> 10 add_data()
e:\APPS\anaconda3\envs\nice-slam\lib\site-packages\taichi\lang\kernel_impl.py in wrapped(*args, **kwargs)
974 return primal(*args, **kwargs)
975 except (TaichiCompilationError, TaichiRuntimeError) as e:
--> 976 raise type(e)("\n" + str(e)) from None
977
978 wrapped.grad = adjoint
TaichiNameError:
File "C:\Users\wuke\AppData\Local\Temp\ipykernel_56756\1181762831.py", line 7, in add_data:
x[i] = i
Name "x" is not defined
- 我们可以调用
deactive方法来清空激活单元的存储
import taichi as ti
ti.init()
# S的父节点是ti.root, 如果调用 S = P.dynamic()意思是S的父节点是P,这句话表明了S节点在Snode Tree中的位置
S = ti.root.dynamic(ti.i, 1024, chunk_size=32)
# dynamic的第一个参数是S所在的轴。
# 这个轴必须是一维的,不能被S的任何父节点使用。这里我们使用轴ti.i(相当于NumPy中的轴=0)。
# 1024代表S的最大长度,动态SNode按需动态分配内存: 有数据才占内存
x = ti.field(int)
S.place(x)
@ti.kernel
def clear_data():
x.deactivate()
print(x.length()) # will print 0
clear_data()
[Taichi] Starting on arch=x64
在arch中,使用类似linked lists的结构存储Dynamic SNode,一个node(或者叫chunk)内的存储是dense的,上面定义的Dynamic SNode x:
S = ti.root.dynamic(ti.i, 1024, chunk_size=32)
x = ti.field(int)
S.place(x)

因此,上图中的chunk数量=ceil(x.length()/chunk_size)
import taichi as ti
ti.init()
S = ti.root.dense(ti.i, 10).dynamic(ti.j, 1024, chunk_size=32)
# 10*1024的动态SNode
# ti.root.dense(ti.i, 10)是一个Dense SNode
# ti.root.dense(ti.i, 10).dynamic(ti.j, 1024, chunk_size=32)这个SNode的子节点
# S沿着ti.i轴的维度是10,每个dense块有1024个chunk, 每个chunk的维度是32。
x = ti.field(int)
S.place(x)
# 之后可以直接用x[i].append添加chunk。
@ti.kernel
def add_data():
for i in range(10):
for j in range(i):
x[i].append(j)
print(x[i].length())
print('--------------------------------')
for i in range(10):
x[i].deactivate()
print(x[i].length())
# --------------------------------------------------
# 0
# 1
# 2
# 3
# 4
# 5
# 6
# 7
# 8
# 9
# --------------------------------
# 0
# 0
# 0
# 0
# 0
# 0
# 0
# 0
# 0
# 0
# --------------------------------
[Taichi] Starting on arch=x64
n = 10

# 使用Dynamic SNode存储struct
import taichi as ti
ti.init()
S = ti.root.dynamic(ti.i, 1024, chunk_size=32)
SphereType = ti.types.struct(center=ti.math.vec3, radius=float)
x = SphereType.field()
S.place(x)
[Taichi] Starting on arch=x64
4.3.4 空间稀疏数据结构的计算
在不规则的稀疏结构上进行有效的循环是非常具有挑战性的,尤其是在GPU等并行设备上,在Taichi,for循环具有对空间稀疏数据结构的原生支持,并且通过高效的自动并行机制,只遍历当前活跃的像素。
# 显示操作和查询稀疏性
# Taichi还提供了可以显示操作数据结构稀疏性的API,可以手动检查SNode的活跃度。
import taichi as ti
x = ti.field(int)
block1 = ti.root.pointer(ti.ij, (3, 3)) # 3*3的指针
block2 = block1.pointer(ti.ij, (2, 2)) # 每个指针指向一个2*2的pointer block
pixel = block2.bitmasked(ti.ij, (2, 2)) # 每个指针指向一个1*1的block
pixel.place(x)
# 1. 检查活跃度
@ti.kernel
def activity_checking(snode: ti.template(), i:ti.i32, j: ti.i32):
print(ti.is_active(snode, [i,j]))
def main_activity_checking():
print('-'*20)
for i in range(3):
for j in range(3):
activity_checking(block1, i, j)
for i in range(6):
for j in range(6):
activity_checking(block2, i, j)
for i in range(12):
for j in range(12):
activity_checking(pixel, i, j)
# 2. 激活
@ti.kernel
def activate_snodes():
ti.activate(block1, [1,0])
ti.activate(block2, [3,1])
ti.activate(pixel, [7,3])
print('-'*20)
activity_checking(block1, 1, 0)
activity_checking(block2, 3, 1)
activity_checking(pixel, 7, 3)
# 3. 失活
# (3.1) 使用 ti.deactivate(snode, [i,j,...])直接让最具体的单元失活
# (3.2) 使用 snode.deactivate_all() 取消激活这个snode的所有单元
# (3.3) 使用 ti.disactivate_all_snodes() 取消激活所有SNode单元
# ti.deactivate不会递归取消某一个活跃单元的所有后代
# 不会触发取消激活父容器
# 4. 祖先索引查询
print(ti.rescale_index(x, block1, ti.Vector([7, 3]))) # output: [1, 0]
print(ti.rescale_index(x, block2, [7, 3])) # output: [3, 1]
print(ti.rescale_index(x, pixel, [7, 3])) # output: [7, 3]
print(ti.rescale_index(block2, block1, [3, 1])) # output: [1, 0]
[1 0]
[3 1]
[7 3]
[1 0]
4.4 偏移坐标
Taichi场可以用偏移场来定义
# 例如: 一个含有 32*64 个元素的矩阵,坐标偏移(-16, 8)可以定义为:
import taichi as ti
a = ti.Matrix.field(2, 2, dtype=ti.f32, shape=(32, 64), offset=(-16, 8))
# 这样,field 的索引范围即从 (-16, 8) 到 (16, 72) (两边不包括)。
4.5 与外部数组进行交互
如何把外部的Numpy arrays, Pytorch Arrays, Paddle Tensors转换到Taichi Scope。
- 有两种将
np.ndarray转换到Taichi Scope的方法:- (1) 新建一个和ndarray的shape一致的Taichi field “f”(dtype不要求一致), 然后直接调用
f.from_numpy(arr)/from_torch(), 当f被用的很频繁的时候,推荐这个方法。这个方法不会改变之前的arr! 可以接受任意的。 - (2) 直接用
ti.types.ndarray()作为hint, 这个方法会改变之前的array,当你需要用Taichi函数改变之前的array的时候推荐使用这个方法。只能接受连续的ndarray或者tensor!
- (1) 新建一个和ndarray的shape一致的Taichi field “f”(dtype不要求一致), 然后直接调用
# f.from_numpy()
import numpy as np
import taichi as ti
ti.init()
# numpy -> field
x = ti.field(float, shape=(3, 3))
a = np.ones((3, 3)).astype(np.float32)
x.from_numpy(a)
# field -> numpy
arr = x.to_numpy()
[Taichi] Starting on arch=x64
import torch
import taichi as ti
ti.init()
# numpy -> field
x = ti.field(float, shape=(3, 3))
a = torch.ones((3, 3))
x.from_torch(a)
[Taichi] Starting on arch=x64
-
当在
ti.field/ti.Vector.field/ti.Matrix.field和numpy矩阵之间进行转换的时候,一定要确保array和feild的shape是一致的。 -
对于
scalar field: 保证scalar的shape和ndarray一致。 -
对于
n-dimensional vector: 保证shape一致,n无所谓
import taichi as ti
import torch
ti.init()
field = ti.Vector.field(3, int, shape=(256, 256))
# -------------------------------------------------------------------------------------------
# field.shape[1]=array.shape[1]
# (=512)
# ┌─────────────────────────────┐
# ┌ ┌─────────┬─────────┬─────────┐ ┐
# │ │[*, *, *]│[*, *, *]│[*, *, *]│ │
# │ ├─────────┼─────────┼─────────┤ │
# field.shape[0]=array.shape[0] │ │[*, *, *]│[*, *, *]│[*, *, *]│ │ [*, *, *]
# (=256) │ ├─────────┼─────────┼─────────┤ │ └───────┘
# │ │[*, *, *]│[*, *, *]│[*, *, *]│ │ n=array.shape[2]=3
# └ └─────────┴─────────┴─────────┘ ┘
[Taichi] Starting on arch=x64
五、可微编程
抽象,对于控制器优化系统而言,配备可微仿真器的系统比使用无模型强化学习算法的系统收敛速度快1~4个数量级。
假设你有两个field:
x = ti.field(float, ())
y = ti.field(float, ())
@ti.kernel
def compute_y():
y[None] = ti.sin(x[None])
假设你希望根据求 dy/dx , sin函数式直接求导的,但是Taichi有一种自动的求导机制(auto differentiation), 主要是ti.ad.Tape()以及更灵活的kernel.grad()。
5.1 ti.ad.Tape()
# 在dclare需要求导的field时,需要添加needs_grad=True
x = ti.field(dtype=ti.f32, shape=(), needs_grad=True)
y = ti.field(dtype=ti.f32, shape=(), needs_grad=True)
@ti.kernel
def compute_y():
y[None] = ti.sin(x[None])
with ti.ad.Tape(y): # 声明你想要自动微分的函数
compute_y()
print('dy/dx = ', x.grad[None], ' at x =', x[None])
dy/dx = 1.0 at x = 0.0
5.1.1 案例:粒子势能模拟
粒子的势能对于位置的微分是粒子收到的力(功=力×位移):
F i = − d U / d x i F_i = -dU / d x_i Fi=−dU/dxi

import taichi as ti
ti.init()
N = 8 # 8个粒子
dt = 1e-5
x = ti.Vector.field(2, dtype=ti.f32, shape=N, needs_grad=True) # 位置: 2 * (N, )
v = ti.Vector.field(2, dtype=ti.f32, shape=N) # 速度: 2 * (N, )
U = ti.field(dtype=ti.float32, shape=(), needs_grad=True) # 势能
@ti.kernel
def compute_U():
for i, j in ti.ndrange(N, N):
r = x[i] - x[j]
U[None] += -1 / r.norm(1e-3) # U += -1 / |r| # 两两之间的相对势能
@ti.kernel
def advance():
for i in x: # 第i个小球
v[i] += dt * -x.grad[i] # Δv = -ΔU/Δx * dt
for i in x:
x[i] += dt * v[i] # Δx/Δt = v
def substep():
with ti.ad.Tape(loss=U):
compute_U()
advance()
@ti.kernel
def init():
for i in x:
x[i] = [ti.random(), ti.random()]
def main():
init()
gui = ti.GUI('AutoDiff Gravity')
while gui.running:
for i in range(50): # 仿真50个时间步
substep()
gui.circles(x.to_numpy(), radius=5)
gui.show()
main()
[Taichi] Starting on arch=x64
5.2 kernel.grad()
ti.ad.Tape()的input必须是零维的,当你想实现多维的求导的时候,尝试kernel.grad(),在调用kernel.grad()之前,你需要人为地将输出变量的grad设置为1。(原因是输出变量本身的梯度将始终乘以反向传播结束时相对于输入的梯度。)
import taichi as ti
ti.init()
N = 16
x = ti.field(dtype=ti.f32, shape=N, needs_grad=True)
loss = ti.field(dtype=ti.f32, shape=(), needs_grad=True)
@ti.kernel
def func_break_rule_2():
loss[None] += x[1] ** 2
# Bad: broke global data access rule #2, it's not an atomic_add.
loss[None] *= x[2]
@ti.kernel
def func_equivalent():
loss[None] = (2 + x[1] ** 2) * x[2]
for i in range(N):
x[i] = i
loss.grad[None] = 1
loss[None] = 2
func_break_rule_2()
func_break_rule_2.grad()
# 调用 func_equivalent 查看正确结果
# func_equivalent()
# func_equivalent.grad()
[Taichi] Starting on arch=x64
六、高级编程
6.1 元编程
- 啥是元编程?
元编程就是代码生成代码,即代码的自复制。元编程有利于维度自适应代码的开发,例如即适用于2维也适用于3维的情况的物理模拟。
# 下面代码的传入参数是ti.template(), 这样搞的话,输入数据的维度就可以变化了
import taichi as ti
ti.init()
@ti.kernel
def copy_1D(x: ti.template(), y: ti.template()):
for i in x:
y[i] = x[i]
a = ti.field(dtype=ti.f32, shape=4)
b = ti.field(dtype=ti.f32, shape=4)
c = ti.field(ti.f32, 12)
d = ti.field(ti.f32, 12)
# Pass field a and b as arguments of the kernel `copy_1D`:
copy_1D(a, b)
# Reuse the kernel for field c and d:
copy_1D(c, d)
[Taichi] Starting on arch=x64
6.1.1 field/Matrix/Vector的元数据
# ti.group()的作用是将循环下标组合成ti.Vector,使得独立于维度的编程成为可能
import taichi as ti
ti.init()
@ti.kernel
def copy_1D(x: ti.template(), y: ti.template()):
for i in x:
y[i] = x[i]
@ti.kernel
def copy_2D(x: ti.template(), y: ti.template()):
for i, j in x:
y[i, j] = x[i, j]
@ti.kernel
def copy_2D(x: ti.template(), y: ti.template()):
for i, j, k in x:
y[i, j, k] = x[i, j, k]
@ti.kernel
def copy(x: ti.tempplate(), y: ti.template()):
for I in ti.grouped(x):
# I 是一个维度和 x 相同的向量
# 如果 x 是 0 维的,则 I = ti.Vector([]),就相当于`None`被用于 x[I]
# 如果 x 是 1 维的,则I = ti.Vector([i])
# 如果 x 是 2 维的,则 I = ti.Vector([i, j])
# 如果 x 是 3 维的,则 I = ti.Vector([i, j, k])
y[I] = x[I]
# 无论在Taichi Scope还是在Python Scope,都使用field,.dtype和field.shape来查看field的属性
import taichi as ti
ti.init()
# 在Python Scope下
x = ti.field(dtype=ti.f32, shape=())
print(x.dtype, x.shape)
print('-'*20)
# 在Taichi Scope下
@ti.kernel
def print_field_metadata(x: ti.template()):
# 直接print(x.dtype, x.shape)会报错
print(x.shape)
ti.static_print(x.dtype)
print_field_metadata(x)
[Taichi] Starting on arch=x64
f32 ()
--------------------
f32
# 矩阵&向量 的元数据
# .m代表列数, .n代表行数
# Taichi把 矩阵/向量 看作是只有一列的矩阵
# vector.n 表示的是向量的元素个数,vetor.m恒为1,即向量是列矩阵
import taichi as ti
ti.init()
@ti.kernel
def foo():
matrix = ti.Matrix([[1, 2], [3, 4]])
print(matrix.n, matrix.m)
vector = ti.Vector([1, 2, 3])
print(vector.n)
print(vector.m)
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=x64
6.1.2 编译时评估
-
使用编译时评估可以将部分计算量移到内核实例化时进行。 这有助于编译器实现最优化以减少运行时的计算开销。
-
静态作用域:
ti.static
import taichi as ti
ti.init()
enable_projection = True
@ti.kernel
def static():
if ti.static(enable_projection):
x[0] = 1
6.2 面向数据对象式的编程
- Taichi是一种面向数据编程(DOP)语言,即: 将一切都视作可以操作的数据,这将功能与数据区分开,这种面向数据的方式允许你在 类 中组织数据和方法,并调用方法来操纵Taichi作用域内的数据,Taichi提供了两种方法实现这一功能:
@ti.data_orineted: 面向数据的类用这个装饰器。@ti.dataclass: 数据类由这个装饰,你可以把ti.func定义为它的方法。
6.3 @ti.data_orineted
- 定义一个Taichi核为Python类成员函数:
- (1) 使用
@ti.data_orineted装饰器来装饰该类 - (2) 在面向数据的python类定义kernel和func。
- (1) 使用
import taichi as ti
ti.init()
@ti.data_oriented
class TiArray:
def __init__(self, n):
self.x = ti.field(dtype=ti.i32, shape=n)
@ti.kernel
def inc(self):
for i in self.x:
self.x[i] += 1
a = TiArray(10)
a.inc()
[Taichi] Starting on arch=x64
# Taichi field不仅可以在init函数中定义,也可以在面向数据的类中任一Python作用域函数内定义。
import taichi as ti
ti.init()
@ti.data_oriented
class MyClass:
@ti.kernel
def inc(self, temp: ti.template()):
for I in ti.grouped(temp):
temp[I] += 1
def call_inc(self):
self.inc(self.temp)
def allocte_temp(self, n):
self.temp = ti.field(dtype=ti.i32, shape=n)
a = MyClass()
a.allocte_temp(4)
a.call_inc()
a.call_inc()
print(a.temp)
[Taichi] Starting on arch=x64
[2 2 2 2]
import taichi as ti
ti.init()
@ti.data_oriented
class Calc:
def __init__(self):
self.x = ti.field(dtype=ti.f32, shape=16)
self.y = ti.field(dtype=ti.f32, shape=4)
@ti.kernel
def func(self, temp: ti.template()):
for i in range(8):
temp[i] = self.x[i*2] + self.x[i*2+1]
for i in range(4):
self.y[i] = ti.max(temp[i*2], temp[i*2+1])
def call_func(self):
fb = ti.FieldsBuilder()
temp = ti.field(dtype=ti.f32)
fb.dense(ti.i, 8).place(temp)
tree = fb.finalize()
self.func(temp)
tree.destroy()
a = Calc()
for i in range(16):
a.x[i] = i
a.call_func()
print(a.y)
[Taichi] Starting on arch=x64
[ 5. 13. 21. 29.]
如果一个类是 data_oriented 的,那么它的子类也是 data_oriented 的。
# data_oriented的类的继承
import taichi as ti
ti.init()
class BaseClass:
def __init__(self):
self.n = 10
self.num = ti.field(dtype=ti.i32, shape=(self.n, )) # n*1的field
@ti.kernel
def sum(self) -> ti.i32:
# 就是求个和
ret = 0
for i in range(self.n):
ret += self.num[i]
return ret
@ti.kernel
def add(self, d: ti.i32):
for i in range(self.n):
self.num[i] += d
@ti.data_oriented
class DataOrientedClass(BaseClass):
pass
class DeviatedClass(DataOrientedClass):
@ti.kernel
def sub(self, d: ti.i32):
for i in range(self.n):
self.num[i] -= d
a = DeviatedClass()
a.add(1)
a.sub(1)
print(a.sum())
b = DataOrientedClass()
b.add(2)
print(b.sum())
# ----------------------------------------------------
# [Taichi] Starting on arch=x64
# 0
# 20
[Taichi] Starting on arch=x64
0
20
# static method
import taichi as ti
ti.init()
@ti.data_oriented
class Array2D:
def __init__(self):
self.arr = ti.Vector([0.] * n)
@staticmethod
@ti.func
def clamp(x):
return max(0, min(1,x))
[Taichi] Starting on arch=x64
# classmethod
import taichi as ti
ti.init(arch=ti.cuda)
@ti.data_oriented
class Counter:
num_ = ti.field(dtype=ti.i32, shape=(32, ))
def __init__(self, data_range):
self.range = data_range
self.add(data_range[0], data_range[1], 1)
@classmethod
@ti.kernel
def add(cls, l: ti.i32, r: ti.i32, d: ti.i32):
for i in range(l, r):
cls.num_[i] += d
@ti.kernel
def num(self) -> ti.i32:
ret = 0
for i in range(self.range[0], self.range[1]):
ret += self.num_[i]
return ret
a = Counter((0, 5))
print(a.num())
b = Counter((4,10))
print(a.num())
print(b.num())
# ======================================
# [Taichi] Starting on arch=cuda
# 5
# 6
# 7
[Taichi] Starting on arch=cuda
5
6
7
6.4 @ti.dataclass
import taichi as ti
vec3 = ti.math.vec3
@ti.dataclass
class Sphere:
center: vec3
radius: ti.f32
# 等同于 Sphere = ti.types.struct(center=vec3, radius=ti.f32)
# 将函数与结构体类型关联
import math
import taichi
ti.init()
@ti.dataclass
class Sphere:
center: vec3
radius: ti.f32
@ti.func
def area(self):
return 4 * math.pi * self.radius**2
def is_zero_sized(self):
return self.radius == 0.0
a_python_struct = Sphere(center=ti.math.vec3(0.0), radius=1.0)
a_python_struct.is_zero_sized()
@ti.kernel
def get_area() -> ti.f32:
a_taichi_struct = Sphere(center=ti.math.vec3(0.0), radius=1.0)
return a_taichi_struct.area()
get_area()
[Taichi] Starting on arch=x64
12.566370964050293
七、可视化
7.1 GUI
Taichi有一个内置的GUI系统,用于对Taichi fields或者Numpy Array等数据容器内的数据进行视觉模拟。
import taichi as ti
ti.init()
gui = ti.GUI('Hello World!', (640, 360))
while gui.running: # 关闭窗口 设置gui.running = False就行辣
gui.show()
[Taichi] Starting on arch=x64
7.1.1 坐标系统
-
调用
gui.set_image()显示Taichi field 或 numpy ndarray, 该方法接收上面两种类型作为输入。 -
如果你只需要展示图片,即只调用
gui.set_image()这一种方法的话,可以调用:
gui = ti.GUI('Fast GUI', res=(400, 400), fast_gui=True)
gui.set_image的输入必须是ti.f32,ti.f64,ti.u8的其中之一
import taichi as ti
ti.init()
gui = ti.GUI('Hello World!', (640, 360))
image = ti.Vector.field(3, ti.f32, (640, 360))
while gui.running:
# 因为field是一个全局的数据容器,如果field image在while循环之间被更新过,
# GUI窗口将会刷新以显示最新图像,请保证field和gui的分辨率一致
gui.set_image(image)
gui.show()
[Taichi] Starting on arch=x64
7.1.2在窗口上绘画
Taichi GUI支持画简单的几何图形,比如线、圆形、三角形和文本。
import numpy as np
gui = ti.GUI('Single Line')
begin = [0.1, 0.1] # 可以是列表,numpy 或者ti.vector
end = [0.9, 0.9]
while gui.running:
gui.line(begin, end, radius=1, color=0x068587)
gui.show()

# 画圆
import taichi as ti
ti.init()
gui = ti.GUI('Single Circle', res=(400, 400))
center = [0.5, 0.5]
while gui.running:
gui.circle(pos=center, radius=30, color=0xED553B)
gui.show()
[Taichi] Starting on arch=x64

# 画三角形
import numpy as np
import taichi as ti
gui = ti.GUI('Single Triangle', res=(400, 400))
p1 = [0.5, 0.5]
p2 = [0.6, 0.5]
p3 = [0.5, 0.6]
while gui.running:
gui.triangle(a=p1, b=p2, c=p3, color=0xEEEEF0)
gui.show()
# 画矩形
import taichi as ti
gui = ti.GUI('Single Rectangle', res=(400, 400))
p1 = [0.3, 0.4]
p2 = [0.7, 0.6]
while gui.running:
gui.rect(topleft=p1, bottomright=p2, color=0xFFFFFF)
gui.show()

# 画个箭头
import taichi as ti
import numpy as np
gui = ti.GUI('Single Arrow', res=(400, 400))
begin = [0.3, 0.3]
increment = [0.5, 0.5]
while gui.running:
gui.arrow(orig=begin, direction=increment, color=0xFFFFFF)
gui.show()

# 写文字
import taichi
gui = ti.GUI('Text', res=(400, 400))
position = [0.3, 0.5]
while gui.running:
gui.text(content='Hello Taichi', pos=position, font_size=34, color=0xFFFFFF)
gui.show()

# 画多个图形,直接多维的numpy就行
import taichi as ti
import numpy as np
pos = np.random.random((50, 2))
indices = np.random.randint(0, 2, size=(50,))
gui = ti.GUI("circles", res=(400, 400))
while gui.running:
gui.circles(pos, radius=5, palette=[0x068587, 0xED553B, 0xEEEEF0], palette_indices=indices)
gui.show()

7.2 GUI窗口部件
import taichi as ti
gui = ti.GUI('GUI widgets')
radius = gui.slider('Radius', 1, 50, step=1)
xcoor = gui.label('X-coordinate')
okay = gui.button('OK')
xcoor.value = 0.5
radius.value = 10
while gui.running:
for e in gui.get_events(gui.PRESS):
if e.key == gui.ESCAPE:
gui.running = False
elif e.key == 'a':
xcoor.value -= 0.05
elif e.key == 'd':
xcoor.value += 0.05
elif e.key == 's':
radius.value -= 1
elif e.key == 'w':
radius.value += 1
elif e.key == okay:
print('OK clicked')
gui.circle((xcoor.value, 0.5), radius=radius.value)
gui.show()

7.3 GGUI
-
之前的是在CPU上进行的渲染,GGUI是在GPU上进行渲染。
-
GGUI可以展示三种东西:
- 2D Canvas用来画一些简单的2D geometry,不如circle, triangle, 3D scene。
- 交互件: 比如按钮,文本框
# GGUI画3D图形
import taichi as ti
ti.init(arch=ti.cuda)
N = 10
particles_pos = ti.Vector.field(3, dtype=ti.f32, shape = N)
points_pos = ti.Vector.field(3, dtype=ti.f32, shape = N)
@ti.kernel
def init_points_pos(points : ti.template()):
for i in range(points.shape[0]):
points[i] = [i for j in ti.static(range(3))]
init_points_pos(particles_pos)
init_points_pos(points_pos)
window = ti.ui.Window("Test for Drawing 3d-lines", (768, 768))
canvas = window.get_canvas()
# 创建场景
scene = ti.ui.Scene()
# 配置相机
camera = ti.ui.Camera()
camera.position(5, 2, 2)
while window.running:
camera.track_user_inputs(window, movement_speed=0.03, hold_key=ti.ui.RMB)
scene.set_camera(camera)
scene.ambient_light((0.8, 0.8, 0.8))
# 添加点光源
scene.point_light(pos=(0.5, 1.5, 1.5), color=(1, 1, 1))
scene.particles(particles_pos, color = (0.68, 0.26, 0.19), radius = 0.1)
# 添加3D几何图形
scene.lines(points_pos, color = (0.28, 0.68, 0.99), width = 5.0)
canvas.scene(scene)
window.show()
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=cuda
在当前单元格或上一个单元格中执行代码时 Kernel 崩溃。请查看单元格中的代码,以确定故障的可能原因。有关详细信息,请单击 此处。有关更多详细信息,请查看 Jupyter log。

八、性能调优
- Taichi提供了profiling tools(查看资源占用)的工具用来逮bug或者优化算法。
- Taichi主要提供了两种profiling tools:
-
(1) ScopedProfiler: 用来分析Taichi JIT编译器的表现。
-
(2) KernelProfiler: 用来分析Taichi kernel的表现,这个基于CUDA,能提供很多low level details。
-
8.1 ScopedProfiler
ScopedProfiler可以帮助我们追踪host task的时间,比如JIT的编译时间,ScopedProfiler默认是开启的。
如果你需要分层的打印,可以调用:ti.profiler.print_scoped_profiler_info()
import taichi as ti
ti.init(arch=ti.cpu)
var = ti.field(ti.f32, shape=1)
@ti.kernel
def compute():
var[0] = 1.0
print('Setting var[0]=', var[0])
compute()
ti.profiler.print_scoped_profiler_info()
# --------------------------------------------
# [Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
# [Taichi] Starting on arch=x64
# Setting var[0]= 1.000000
# >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
# [Profiler thread 56676]
# 13.023 ms taichi::lang::TaichiLLVMContext::get_this_thread_runtime_module [2 x 6.511 ms]
# 13.003 ms 99.85% taichi::lang::LlvmModuleBitcodeLoader::load [1 x 13.003 ms]
# 13.000 us 76.47% [unaccounted]
# 2.000 us 8.70% taichi::lang::StructCompilerLLVM::generate_child_accessors [1 x 2.000 us]
# 4.000 us 17.39% [unaccounted]
# 361.000 us 81.31% taichi::lang::TaichiLLVMContext::add_struct_module [1 x 361.000 us]
# 7.000 us 1.58% [unaccounted]
# 1.032 ms taichi::lang::Program::compile [1 x 1.032 ms]
# >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
[Taichi] Starting on arch=x64
8.2 KernelProfiler
-
KernelProfiler从后端找记录,并将它们放到python scope里面,并打印到终端。
-
注意
KernelProfiler只支持CPU和GPU,如果你在GOU上面跑的话,请确保先调用ti.sync() -
使用方法:
-
ti.init(ti.cpu, kernel_profiler=True)
-
- 打印profiling信息:
ti.profiler.print_kernel_profiler_info(MODE)
MODE='count': 一个kernel一个profiling result。MODE='trace':
- 打印profiling信息:
- 调用
ti.profiler.clear_kernel_profiler_info()清空信息。
-
import taichi as ti
ti.init(ti.cpu, kernel_profiler=True)
x = ti.field(ti.f32, shape=1024*1024)
@ti.kernel
def fill():
for i in x:
x[i] = i
for i in range(8):
fill()
ti.profiler.print_kernel_profiler_info('trace')
ti.profiler.clear_kernel_profiler_info()
for i in range(100):
fill()
# ----------------------------------------------------
# [Taichi] Starting on arch=x64
# =========================================
# Kernel Profiler(trace, default) @ X64
# =========================================
# [ start.time | kernel.time ] Kernel name
# -----------------------------------------
# [ 0.000 ms | 0.313 ms ] fill_c78_0_kernel_0_range_for
# [ 0.313 ms | 0.263 ms ] fill_c78_0_kernel_0_range_for
# [ 0.576 ms | 0.161 ms ] fill_c78_0_kernel_0_range_for
# [ 0.737 ms | 0.077 ms ] fill_c78_0_kernel_0_range_for
# [ 0.814 ms | 0.131 ms ] fill_c78_0_kernel_0_range_for
# [ 0.945 ms | 0.117 ms ] fill_c78_0_kernel_0_range_for
# [ 1.062 ms | 0.095 ms ] fill_c78_0_kernel_0_range_for
# [ 1.157 ms | 0.106 ms ] fill_c78_0_kernel_0_range_for
# -----------------------------------------
# Number of records: 8
# =========================================
[Taichi] Starting on arch=x64
=========================================
Kernel Profiler(trace, default) @ X64
=========================================
[ start.time | kernel.time ] Kernel name
-----------------------------------------
[ 0.000 ms | 0.311 ms ] fill_c78_0_kernel_0_range_for
[ 0.311 ms | 0.170 ms ] fill_c78_0_kernel_0_range_for
[ 0.481 ms | 0.155 ms ] fill_c78_0_kernel_0_range_for
[ 0.636 ms | 0.170 ms ] fill_c78_0_kernel_0_range_for
[ 0.806 ms | 0.141 ms ] fill_c78_0_kernel_0_range_for
[ 0.947 ms | 0.154 ms ] fill_c78_0_kernel_0_range_for
[ 1.101 ms | 0.167 ms ] fill_c78_0_kernel_0_range_for
[ 1.268 ms | 0.151 ms ] fill_c78_0_kernel_0_range_for
-----------------------------------------
Number of records: 8
=========================================
8.3 性能优化
- for循环装饰器: Taichi JIT 会自动并行for循环,会自动分配最佳的并行计算方案。
你可以使用ti.loop_config来设置循环的参数:parallelize: 设置CPU上的线程数量。block_dim: 设置一个GPU上的线程数量。serialize: 如果设置为True,代表串行,只有串行才能写break。
import taichi as ti
ti.init()
@ti.kernel
def break_in_serial_for() -> ti.i64:
a = 0
ti.loop_config(serialize=False)
for i in range(100000000):
a += i
return a
break_in_serial_for()
# ------------------------0.2s
def raw_for():
a = 0
for i in range(100000000):
a += i
return a
raw_for()
# ------------------------3.5s
[Taichi] Starting on arch=x64
887459712
-
后台: GPU线程架构: iter < thread < block < grid
- iter: 字面意思,就是for里的一个个iter
- thread: thread是最小的并行单元,一个thread内的iters是串行的,为了最大化效率,我们一般一个thread只分配一个iter
- block: 一个block内的所有thread是并行的,并且这些thread共享block local storage。
- grid: 一个grid是hosts启动的最小单元,一个grid内的所有block都是并行的。
-
Taichi利用了例如CUDA的shared memory,L1缓存。Taichi在可行的情况下用对局部存储器的快速访问代替对全局存储器的访问,并在结束的时候将局部存储器写回到全局存储器。
九、Taichi的Debug
- Parallel的程序没法debug,因此Taichi开发了以下机制:
-
- 在Taichi Scope下直接打印变量的值。
-
ti.init(debug=True),这个模式主要用来检测 out of bound 的array。
-
- static or non-static assert。
-
sys.tracebacklimit
-
编译时候的ti.static_print,类似于ti.static的作用(编译的时候就把结果计算出来)。
ti.static_print与print的唯一区别在于前者只在编译的时候输出一次。
import taichi as ti
ti.init()
x = ti.field(ti.f32, (2, 3))
y = 1
@ti.kernel
def inside_taichi_scope():
ti.static_print(y)
for i in range(4):
ti.static_print(i.dtype)
inside_taichi_scope()
[Taichi] Starting on arch=x64
部分串行: threads的运行顺序是随机的,如果你选择CPU作为后端(backend),你可以设置cpu_max_num_threads=1。这样程序就不会乱飞,而是老老实实的按顺序执行。
import taichi as ti
ti.init(arch=ti.cpu, cpu_max_num_threads=1)
import taichi as ti
ti.init(arch=ti.cpu)
n = 1024
val = ti.field(dtype=ti.i32, shape=n)
val.fill(1)
@ti.kernel
def prefix_sum():
ti.loop_config(serialize=True)
for i in range(1, n):
val[i] += val[i-1]
for i in range(1, n):
val[i] += val[i-1]
prefix_sum()
print(val)
[Taichi] Starting on arch=x64
[ 1 3 6 ... 391425 392448 393472]
# Array out of bound
import taichi as ti
ti.init(arch=ti.cpu, debug=True)
f = ti.field(dtype=ti.i32, shape=(32, 32))
@ti.kernel
def test() -> ti.i32:
return f[0, 73]
print(test())
# ----------------------------------------
# TaichiAssertionError:
# (kernel=test_c106_0) Accessing field (S2place) of size (32, 32) with indices (0, 73)
# File "C:\Users\wuke\AppData\Local\Temp\ipykernel_1220\2639817073.py", line 8, in test:
# return f[0, 73]
[Taichi] Starting on arch=x64
---------------------------------------------------------------------------
TaichiAssertionError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_1220\3868931193.py in
8 return f[0, 73]
9
---> 10 print(test())
11
12 # ----------------------------------------
e:\APPS\anaconda3\envs\nice-slam\lib\site-packages\taichi\lang\kernel_impl.py in wrapped(*args, **kwargs)
974 return primal(*args, **kwargs)
975 except (TaichiCompilationError, TaichiRuntimeError) as e:
--> 976 raise type(e)("\n" + str(e)) from None
977
978 wrapped.grad = adjoint
TaichiAssertionError:
(kernel=test_c106_0) Accessing field (S2place) of size (32, 32) with indices (0, 73)
File "C:\Users\wuke\AppData\Local\Temp\ipykernel_1220\2639817073.py", line 8, in test:
return f[0, 73]
# assert 在asset之前记得要用debug mode
import taichi as ti
ti.init(arch=ti.cpu, debug=True)
x = ti.field(ti.f32, 128)
x.fill(-1)
@ti.kernel
def do_sqrt_all():
for i in x:
assert x[i] >= 0, f"The {i}-th element cannnot be negative!"
x[i] = ti.sqrt(x[i])
do_sqrt_all()
# ---------------------------------
# TaichiAssertionError:
# The 0-th element cannnot be negative!
[Taichi] Starting on arch=x64
---------------------------------------------------------------------------
TaichiAssertionError Traceback (most recent call last)
~\AppData\Local\Temp\ipykernel_1220\3734275677.py in
12 x[i] = ti.sqrt(x[i])
13
---> 14 do_sqrt_all()
e:\APPS\anaconda3\envs\nice-slam\lib\site-packages\taichi\lang\kernel_impl.py in wrapped(*args, **kwargs)
974 return primal(*args, **kwargs)
975 except (TaichiCompilationError, TaichiRuntimeError) as e:
--> 976 raise type(e)("\n" + str(e)) from None
977
978 wrapped.grad = adjoint
TaichiAssertionError:
The 0-th element cannnot be negative!
Taichi将python的代码translate成一种高性能的静态语言,在Taichi中,变量的数据类型在初始化的时候就定下了,之后不会改也不能改。
十、内部设计
10.1 SNode
import taichi as ti
ti.init(print_ir=True) # 打印IR(Intermediate Representation)
@ti.kernel
def foo():
for i in range(10):
if i < 4:
print(i)
foo()
# -----------------------------
# kernel {
# $0 = offloaded range_for(0, 10) grid_dim=0 block_dim=32
# body {
# $1 = loop $0 index 0
# $2 = const [4]
# $3 = cmp_lt $1 $2
# $4 = const [1]
# $5 = bit_and $3 $4
# $6 : if $5 {
# print $1, "\n"
# }
# }
# }
# ------------------------------
[Taichi] Starting on arch=x64
- Taichi是使用Structure Node(SNode)组织的, SNode由三部分组成(containers, cells, components)
- container是low-level的container,其实只需要记住container和cell就行了
- 每个SNode都有两种身份,container以及cell
import taichi as ti
# 创建一个 container S, 这个 container 有 128 个 S Cells
S = ti.root.dense(ti.i, 128)
# 在 S container 上创建 2 个 container, 分别是 P 和 Q,
P = S.dense(ti.i, 4)
Q = S.dense(ti.i, 4)
# SNode component 是 low-level 的 container
import taichi as ti
ti.init()
x = ti.field(ti.i32)
y = ti.field(ti.i32)
z = ti.field(ti.i32)
S0 = ti.root
S1 = S0.pointer(ti.i, 4)
S2 = S1.dense(ti.i, 2)
S2.place(x, y)
S5 = S1.dense(ti.i, 2)
S5.place(z)
- 上面的代码的意思是:
- S0 root container,内部包含1个S0 root cell
- S0 root cell里面只包含一个组件: S1 pointer container
- 一个S1 pointer container包含4个S1 container cells
- 每个S1 container cell 有两个组件: 一个S2container和一个S5 container
- 一个 S2 container 含有 2 个 S2 dense cell
- 一个 S2 dense cell 含有 x 和 y
- 一个 S5 container 含有 2 个 S5 dense cell
- 一个 S5 dense cell 含有一个 z
- 一个 S2 container 含有 2 个 S2 dense cell

-
我们有的containers:
- 1x S0root container
- 1x S1pointer container
- 4x S2dense containers
- 4x S5dense containers
- 8x S3place_x containers, each directly containing an i32 value
- 8x S4place_y containers, each directly containing an i32 value
- 8x S6place_z containers, each directly containing an i32 value
-
我们有的cells:
- 1x S0root cell
- 4x S1pointer cells
- 8x S2dense cells
- 8x S5dense cells
10.2 一个Taichi Kernel的生命周期
-
理解Taichi kernel的生命周期是很有帮助的,简单来说,编译仅会发生在第一次创建一个kernel实例时。
-
一个kernel的生命周期包括:
- Register Kernel
- 模板实例化及cache
- Python AST转换
- Taichi IR的编译、优化以及可执行文件的生成
- 启动

当执行ti.kernel的时候,一个名为add的kernel就被注册,具体来说,Taichi将记住add函数的python抽象语法树(Abstract Syntax Tree, AST)
import taichi as ti
ti.init()
@ti.kernel
def add(field: ti.template(), delta: ti.i32):
for i in field:
field[i] += delta
x = ti.field(dtype=ti.f32, shape=128)
y = ti.field(dtype=ti.f32, shape=16)
# Step 1: 向Taichi注册Kernel
add(x, 42) # 第一次调用的时候编译add函数
# Step 2:
add(x, 1) # 第二次调用的时候直接读取内存中编译好的二进制文件
[Taichi] Starting on arch=x64
十一、数学函数库
11.1 常用运算符
- 必须在Taichi Scope下调用Taichi Math Model.
- 可以手动设置运算的精度:
default_fp或者arch
import taichi as ti
import taichi.math as tm
ti.init()
@ti.kernel
def test():
a = 1.0
x = tm.sin(a)
t = tm.floor(a)
z = tm.degrees(a) # 角度弧度转化
w = tm.log2(a)
print(x, t, z, w)
test()
# -----------------------------------
# [Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
# [Taichi] Starting on arch=x64
# 0.841471 1.000000 57.295780 0.000000
[Taichi] Starting on arch=x64
import taichi as ti
import taichi.math as tm
@ti.kernel
def test():
a = ti.Vector([1.0, 2.0, 3.0])
x = tm.sin(a) # [0.841471, 0.909297, 0.141120]
y = tm.floor(a) # [1.000000, 2.000000, 3.000000]
z = tm.degrees(a) # [57.295780, 114.591560, 171.887344]
b = ti.Vector([2.0, 3.0, 4.0])
w = tm.atan2(b, a) # [1.107149, 0.982794, 0.927295]
import taichi as ti
mat2 = ti.math.mat2
vec3 = ti.math.mat3
vec4 = ti.math.vec4
m = mat2(1) # [[1., 1.], [1., 1.]]
m = mat2(1, 2, 3, 4) # [[1., 2.], [3, 4.]]
m = mat2([1, 2], [3, 4]) # [[1., 2.], [3, 4.]]
m = mat2([1, 2, 3, 4]) # [[1., 2.], [3, 4.]]
v = vec3(1, 2, 3)
m = mat2(v, 4) # [[1., 2.], [3, 4.]]
u = vec4([1, 2], [3, 4])
u = vec4(v, 4.0)
ti.Vector, ti.types.vector, ti.math.vec3的区别:
ti.Vector是一个一维的数组,返回一个只有一列的array:ti.Vector([1,2,3,4,5])ti.types.vector()返回的是一个vector type,不是vector,可以再用这个type去实例化vectorti.math.vec3其实就是vec3 = ti.types.vector(3, float)
11.2 稀疏矩阵
- 在解决线性系统的问题时常用到稀疏矩阵,Taichi提供了在CPU或者CUDA上面处理稀疏矩阵的API:
-
ti.linalg.SparseMatrixBuilder()
-
- 调用核函数: 用你的稀疏矩阵填充这个
builder
- 调用核函数: 用你的稀疏矩阵填充这个
-
- 从builder中构建稀疏矩阵
-
(注意: 稀疏矩阵在CPU上只支持f32和f64, CUDA上面只支持f16)
import taichi as ti
ti.init(arch=ti.cpu)
n = 4
K = ti.linalg.SparseMatrixBuilder(n, n, max_num_triplets=100)
@ti.kernel
def fill(A: ti.types.sparse_matrix_builder()):
for i in range(n):
A[i, i] += 1
fill(K)
K.print_triplets()
print('-------------------------------------')
A = K.build() # 实例化一个稀疏矩阵
print(A)
# ----------------------------------------------
# [Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
# [Taichi] Starting on arch=x64
# [Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
# [Taichi] Starting on arch=x64
# n=4, m=4, num_triplets=4 (max=100)
# [0, 0] = 1.0
# [1, 1] = 1.0
# [2, 2] = 1.0
# [3, 3] = 1.0
# -------------------------------------
# [1, 0, 0, 0]
# [0, 1, 0, 0]
# [0, 0, 1, 0]
# [0, 0, 0, 1]
[Taichi] version 1.6.0, llvm 15.0.1, commit f1c6fbbd, win, python 3.7.0
[Taichi] Starting on arch=x64
-------------------------------------
[1, 0, 0, 0]
[0, 1, 0, 0]
[0, 0, 1, 0]
[0, 0, 0, 1]
# 稀疏矩阵是支持+-*/操作滴
import taichi as ti
ti.init()
C = A + A
D = A - A
E = A @ A
F = A * 3.0
G = A.transpose()
print(C, D, E, F, G, sep='\n\n')
# -------------------------------
# [Taichi] Starting on arch=x64
# [2, 0, 0, 0]
# [0, 2, 0, 0]
# [0, 0, 2, 0]
# [0, 0, 0, 2]
# [0, 0, 0, 0]
# [0, 0, 0, 0]
# [0, 0, 0, 0]
# [0, 0, 0, 0]
# [1, 0, 0, 0]
# [0, 1, 0, 0]
# [0, 0, 1, 0]
# [0, 0, 0, 1]
# [3, 0, 0, 0]
# [0, 3, 0, 0]
# [0, 0, 3, 0]
# [0, 0, 0, 3]
# [1, 0, 0, 0]
# [0, 1, 0, 0]
# [0, 0, 1, 0]
# [0, 0, 0, 1]
[Taichi] Starting on arch=x64
[2, 0, 0, 0]
[0, 2, 0, 0]
[0, 0, 2, 0]
[0, 0, 0, 2]
[0, 0, 0, 0]
[0, 0, 0, 0]
[0, 0, 0, 0]
[0, 0, 0, 0]
[1, 0, 0, 0]
[0, 1, 0, 0]
[0, 0, 1, 0]
[0, 0, 0, 1]
[3, 0, 0, 0]
[0, 3, 0, 0]
[0, 0, 3, 0]
[0, 0, 0, 3]
[1, 0, 0, 0]
[0, 1, 0, 0]
[0, 0, 1, 0]
[0, 0, 0, 1]
- 有时候你可能希望用稀疏矩阵求解线性方程, 步骤如下:
-
(1) 创建一个solver,
ti.linalg.SparseSolver(solver_type, ordering), CPU上支持LLT,LDLT,LU。CUDA上仅支持LLT。 -
(2) 因式分界想要求解的稀疏矩阵: solver.analyze_pattern(Sparse_matrix)
分析稀疏矩阵:solver.factorize(Sparse_matrix) -
(3) 求解:
solver.solve()+ 查看求解是否成功:solver.info()
-
import taichi as ti
arch = ti.cpu # or ti.cuda
ti.init(arch=arch)
n = 4
K = ti.linalg.SparseMatrixBuilder(n, n, max_num_triplets=100)
b = ti.field(ti.f32, shape=n)
@ti.kernel
def fill(A: ti.types.sparse_matrix_builder(), b: ti.template(), interval: ti.i32):
for i in range(n):
A[i, i] += 2.0
if i % interval == 0:
b[i] += 1.0
fill(K, b, 3)
A = K.build()
print(">>>> Matrix A:")
print(A)
print(">>>> Vector b:")
print(b)
# outputs:
# >>>> Matrix A:
# [2, 0, 0, 0]
# [0, 2, 0, 0]
# [0, 0, 2, 0]
# [0, 0, 0, 2]
# >>>> Vector b:
# [1. 0. 0. 1.]
solver = ti.linalg.SparseSolver(solver_type="LLT")
solver.analyze_pattern(A)
solver.factorize(A)
x = solver.solve(b)
isSuccess = solver.info()
print(">>>> Solve sparse linear systems Ax = b with the solution x:")
print(x)
print(f">>>> Computation was successful?: {isSuccess}")
# outputs:
# >>>> Solve sparse linear systems Ax = b with the solution x:
# [0.5 0. 0. 0.5]
# >>>> Computation was successful?: True
[Taichi] Starting on arch=x64
>>>> Matrix A:
[2, 0, 0, 0]
[0, 2, 0, 0]
[0, 0, 2, 0]
[0, 0, 0, 2]
>>>> Vector b:
[1. 0. 0. 1.]
>>>> Solve sparse linear systems Ax = b with the solution x:
[0.5 0. 0. 0.5]
>>>> Computation was successful?: True
十二、常用API
12.1 变量和循环
-
在程序中,值的类型有两种: “编译期求值"和"运行期求值”,相应的就有两种值: “Python值” 和 “Taichi值”。
Python值只存在于编译期,在编译期求值后,所有余下的表达式将在运行期间被求值为Taichi值。 -
Taichi的变量是静态类型的,也就是说,变量在被定义后就不能再修改类型了。
-
Taichi采用词法作用域,因此,如果一个变量定义在一个块内,那么在块外部是不可见的。
# 观察下面的代码:
import taichi as ti
def test(p: ti.i32):
a = ti.Matrix([i * p for i in range(10)]) # 可以
b = ti.Matrix([i * p for i in range(p)]) # 不可,因p无法在编译期求得python值
-
静态表达式: 是指被
ti.static()包裹的表达式,positional_parties是在编译期求值的,其中的项必须求值为Python值。
ti.static()接收一个或者多个参数:- 当单个参数被传入的时候,它会返回这个参数
- 当多个参数被传入的时候,它会返回一个顺序与传入次序相同的包含所有这些参数的元素。
-
for语句(Taichi不支持在for语句中使用else), Taichi有四种for语句:
-
range-for 语句:
range(start, end), 当位于最外层作用域时候,会默认并行化。 -
ndrange-for 语句:
ti.grouped(ti.ndrange()) -
struct-for 语句: 用于遍历Taichi Field中的活跃的元素,struct-for语句的
iter_expression必须是一个Taichi Field那么它是一个组合形式的struct-for语句。 -
static-for 语句: 在编译期展开 range/ndrange-for 循环
-
12.2 语法糖
有时候为了创建别名(全局变量问题),可以借助ti.static()
import taichi as ti
ti.init()
field_a = ti.field(float, shape=(2,2))
field_b = ti.field(float, shape=(2,2))
a, b = ti.static(field_a, field_b)
[Taichi] Starting on arch=x64
- Taichi仅支持程序中的非静态
if/for/'while’作用于以外的return语句。 - 在
if/for/while代码块被定义的变量不能服从代码块之外被访问。 - 如果一个 Taichi kernel/函数没有 return 语句,那么它不可以有返回类型注释。
- 如果Taichi kernel 有 return 语句,那么它必须有返回类型注释。
十三、Taichi + InstantNGP ⭐
Referenced Repo: https://github.com/taichi-dev/taichi-nerfs
13.1 简介
Instant NGP 的一个重要的工程优化是将整个网络实现在一个 CUDA kernel 中 (Fully-fused MLP),使得网络的所有计算都在 GPU 的 local cache 中进行。据论文所称这会带来 10x 的效率提升。
Instant NGP 项目作者开源了他们的 CUDA 实现。项目使用 CUDA 编写并精心优化了所有核心组件,速度非常快,但是使用 CUDA 也意味着需要手动管理内存和编写并行计算代码的求导,非常痛苦而且容易出错。
纯 PyTorch 版本的运行效率要显著低于 CUDA 实现,这是因为虽然对 MLP 这样的网络,PyTorch 优化的是很好的,但是对 Instant NGP 中哈希编码和体渲染的部分,由于插值、光线采样等步骤涉及大量琐碎的操作,PyTorch 会被迫 launch 许多很小的 kernel,导致效率非常低。

原版的NeRF是一个八层的,宽度为256的很大的网络。训练这个网络需要很长时间的迭代。
Taichi具备自动微分的功能,CUDA算子如果需要反向传播,需要自己写微分的代码。

- 我自己下载下来跑了一下,效果还不错(on Single 3090) 它主要的教程写在了
notebook/pipeline.ipynb
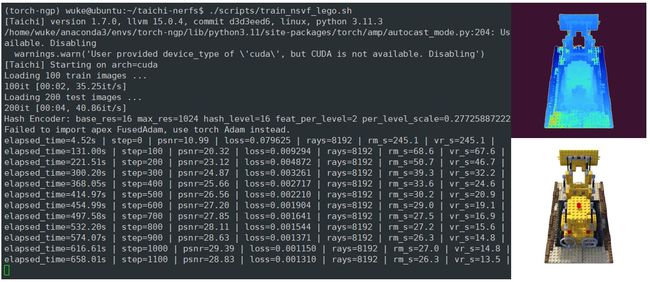
-
Ray Marching(od->sample points coordinate): Lego推土机的occupancy grid是128×128×128。当碰到的voxel的密度值比较低,就跳过,密度值高的话就采样。
-
Volume Rendering: 当点的透射率很高的时候,之后的点就不用再做体素渲染了(early stop)。
13.2 Taichi-InstantNGP代码结构图

Reference:
[1] https://taichi.graphics/
[2] https://zhuanlan.zhihu.com/p/612102573
[3] https://www.bilibili.com/video/BV1oV4y1S7RE/?spm_id_from=333.788&vd_source=b04c3e047b4a6bfd21dc2af34f9f7dc2