【数据结构复习之路】栈和队列(本站最全最详细讲解)& 严蔚敏版
专栏:数据结构复习之路
复习完上面一章【线性表】,我们接着复习栈和队列,这篇文章我写的非常详细且通俗易懂,看完保证会带给你不一样的收获。如果对你有帮助,看在我这么辛苦整理的份上,三连一下啦ε٩(๑> ₃ <)۶з
目录:
☆ 栈 :
一、栈的基本概念
1、栈的定义
2、栈的基本操作
二、栈的顺序存储结构
1、顺序栈的定义
栈的初始化:
判断栈空:
2、基本操作(静态vs动态)
进栈:
出栈 :
读栈顶元素 :
动态分配:
3、共享栈
栈的初始化:
进栈:
出栈:
三、栈的链式存储结构
1、基本操作
链栈的初始化:
进栈:
出栈:
销毁链栈:
四、栈的应用
1、用栈解决括号匹配
2、栈排序
3、单调栈
4、栈在递归中的应用
5、栈的表达式求值(上)
6、栈的表达式求值(下)
☆ 队列 :
一、队列的基本概念
1、队列的定义
2、队列的基本操作
二、队列的顺序存储结构
1、队列的顺序实现(从顺序到循环)
三、队列的链式存储结构
1、基本操作 (带头结点vs不带头结点)
入队操作(带头结点),如上图(b)、(c)
入队操作(不带头结点)
出队操作(带头结点),如上图(d )
出队操作(不带头结点)
销毁队列
四、双端队列
1、正常和特殊
五、队列的应用
1、单调队列
2、树的层次遍历
3、图的广度优先遍历
结尾:
Reference
☆ 栈 :
一、栈的基本概念
1、栈的定义
从数据结构角度看,栈也属于线性表(当然也满足上一章线性表的特性),是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。

因此,栈又被称为后进先出的线性表(简称 LIFO 结构)。
补充:卡特兰数
n个不同元素进栈,则出栈元素不同排列的个数为 ![]()
2、栈的基本操作
InitStack(&S) : 初始化一个空栈,分配内存空间。
DestroyStack(&S) :销毁并释放栈S所占用的内存空间。
Push(&S , x) : 进栈,若栈S未满,则将x 加入使之成为新栈顶。
Pop(&S , &x) : 出栈,若栈S非空,则弹出栈顶元素,并用x返回。
GetTop(S , &x) : 读栈顶元素,若栈S非空,则用x返回栈顶元素。
StackEmpty(S):判断一个栈S是否为空,若S为空,则返回true,否则返回false;
…………………
这些都会在下文,结合栈的存储结构来实现。
二、栈的顺序存储结构
1、顺序栈的定义
栈的定义:
这里先介绍静态分配的栈实现,动态分配在下面。
#define MaxSize 10
typedef struct{
ElemType data[MaxSize]; //静态数组存放栈中元素
int top; //栈顶指针
}SqStack;栈的初始化:
void InitStack (SqStack &S)
{
S.top = -1;
}判断栈空:
bool StackEmpty (SqStack S)
{
if (S.top == -1) return true; //栈空
else return false;
}2、基本操作(静态vs动态)
进栈:
//进栈操作
bool Push (SqStack &S , ElemType x)
{
if (S.top() == MaxSize - 1) return false; //栈满,报错(数组下标是从0开始的)
S.data[++S.top] = x; //指针top先 + 1,新元素再入栈
return true;
} 出栈 :
//出栈操作
bool Pop (SqStack &S , ElemType &x)
{
if (S.top() == -1) return false; //栈空,报错
x = S.data[S.top--]; //栈顶元素先出栈,指针top再 -1
return true;
} 读栈顶元素 :
//读栈顶元素
bool GetTop (SqStack S , ElemType &x)
{
if (S.top() == -1) return false; //栈空,报错
x = S.data[S.top]; //栈顶元素出栈
return true;
} ⚠️:上述 top 初始化为 -1,指明的是当前栈顶元素位置。而有些时候,题目会将top初始化为0,指明的是下一个可以插入元素的位置,这时上述进栈和出栈操作就有点变化了:
//进栈:
S.data[S.top++] = x
//出栈:
x = S.data[--S.top]
动态分配:
栈的定义:
#define MAXSIZE 100 //存储空间初始分配量
#define Increasesize 10 //为存储空间分配的增量
typedef struct{
ElemType *base; //栈底指针
ElemType *top; //栈顶指针
int stacksize; //当前已分配的存储空间
} SqStack;栈的初始化:
void InitStack(SqStack &S)
{
S.base = (ElemType *)malloc(MAXSIZE * sizeof(ElemType));
//因为base作为栈底指针,所以要为其分配地址
S.top = S.base;
S.stacksize = MAXSIZE;
} 栈的判空就是:S.top == S.base
进栈操作:
void push(SqStack &S , ElemType e)
{
if (S.top - S.base >= S.stacksize) //栈满,追加存储空间
{
S.base = (ElemType *)realloc(S.base , (S.stacksize + Increasesize) * sizeof(ElemType));
S.top = S.base + S.stacksize; //因为重新申请了一片空间,导致base地址位置改变
S.stacksize += Increasesize;
}
*S.top++ = e; //先赋值,再 top + 1
}⚠️:这里我选择的是用realloc函数,语法简介:
指针名=(数据类型*)realloc(要改变内存大小的指针名,新的大小)。
注意:新的大小可大可小(如果新的大小大于原内存大小,则新分配部分不会被初始化,即数据会保留;如果新的大小小于原内存大小,可能会导致数据丢失 ,即部分不会保留。并且原来指针所指的存储空间是自动释放,不需要使用free )
当然只采用malloc 和 free 这两个函数也是一样,这我在讲上一章顺序表的顺序存储结构的IncreaseSize (SeqList &L ,int len) 函数时就写了源码,可以去看看哦。
出栈操作:
bool pop(SqStack &S , ElemType &e)
{
if (S.top == S.base) //栈空
{
return false;
}
e = * --S.top; //先top - 1 ,再赋值
return true;
}3、共享栈
共享栈:两个栈共享同一片存储空间,这片存储空间不单独属于任何一个栈,某个栈需要的多一点,它就可能得到更多的存储空间。
两个栈的栈底在这片存储空间的两端,当元素入栈时,两个栈的栈顶指针相向而行。

两个栈的栈顶指针都指向栈顶元素,top0 = -1时0号栈为空,top1 = MaxSize时1号栈为空;仅当两个栈顶指针相邻(top0 + 1 = top1)时,判断为栈满。当0号栈进栈时top0先加1再赋值,1号栈进栈时top1先减一再赋值,出栈时则刚好相反。
共享栈的定义:
#define MaxSize 10
typedef struct {
ElemType data[MaxSize];
int top0;
int top1;
}ShStack;栈的初始化:
void InitShStack (ShStack &S)
{
S.top0 = -1;
S.top1 = MaxSize;
}进栈:
//StackType表示在0号顺序栈插入,还是在1号顺序栈插入
bool Push (ShStack &S , ElemType x , int StackType)
{
if (S.top + 1 == S.top1) return false; //栈满
if (StackType == 0) {
S.data[++S.top0] = x;
}
else {
S.data[--S.top1] = x;
}
return true;
}出栈:
//StackType表示再那个0号顺序栈 插入,还是在1号顺序栈插入
bool Pop (ShStack &S , ElemType &x , int StackType)
{
if (StackType == 0) {
if (S.top0 == -1)
{
return false; //栈 0已空
}
x = S.data[S.top0--]; //非空即出栈
}
else {
if (S.top1 == MaxSize)
{
return false;
}
x = S.data[S.top1++];
}
return true;
}三、栈的链式存储结构
链式栈可以通过单链表的方式来实现,使用链式栈的优点在于它能够克服用数组实现的顺序栈空间利用率不高的问题,但是它也需要为每个栈元素分配额外的指针空间用来存放指针域。
上一章讲线性表时,已经着重介绍了单链表,在开始学习下文前,可以先去温习一下:
(点击即可穿越)

规定:链式栈的所以操作都是在单链表的表头进行的(因为给定链式栈以后,我们可以知道头结点的地址,在其后面插入新结点或删除首结点都很方便,且该操作的时间复杂度为O(1))。
当然带头结点和不带头结点都是一样的,下文主要介绍带头结点:
1、基本操作
链栈的定义:
typedef struct Linknode {
ElemType data;
struct Linknode *next;//存储下一个元素的地址(朝栈底方向)
}node , *LiStack; 链栈的初始化:
void InitLiStack (LiStack &S)
{
S = (LiStack)malloc(sizeof(node));
S -> next = NULL;
}判断链栈是否为空(在不考虑内存溢出的情况下,一般不考虑栈满情况 ):
bool LiStackEmpty(LiStack *S)
{
return (S -> next == NULL);
}进栈:
void Push (LiStack &S , ElemType x)
{
//不需要判断是否栈满
node *t;
t = (node *)malloc(sizeof(node));
t -> data = x;
//把 t节点添加到头节点的后面
t -> next = S -> next;
S -> next = t;
} 出栈:
bool Pop (LiStack &S , ElemType &x)
{
node *t;//指明要出栈的结点
if(S -> next != NULL)//栈不空
{
t = S -> next;
x = t -> data;
S -> next = t -> next;
free(t);
return true;
}
else
{
return false; //栈空
}
} 销毁链栈:
void DestroyStack(LinkStack &S)
{
ElemType m;
while (S -> next != NULL)//不空
{
Pop(S); //上面写的Pop函数形参含有出栈的结点值并且返回值为 bool,但这里可以不用
}
free(S); //删除头结点
S = NULL;
} 看到这里,是不是发现和上一章的单链表几乎完全一样,所以你可以先考虑自己独自完成,这样既能检验自己上一章有没有学扎实,又可以熟悉这一章的栈。
看到这里,是不是发现和上一章的单链表几乎完全一样,所以你可以先考虑自己独自完成,这样既能检验自己上一章有没有学扎实,又可以熟悉这一章的栈。
当然如果栈的变化在可控范围内,建议使用顺序栈会更好一些,毕竟好写一点 hh。
四、栈的应用
1、用栈解决括号匹配
假设表达式中允许包含三种括号:圆括号、方括号和中括号,其嵌套顺序随意,但必须同类型,且左右匹配。比如([ ] ())或者 [ ( [ ] ( [ ] ) ) ] 这些是满足的 ,但是[ ( ] 或者 [ ( [ ] ) 这些都是不行的。
用栈实现括号匹配的规则:
- 遇到左括号就入栈
- 遇到右括号就将栈中的一个左括号出栈看是否匹配
首先来看一个能成功匹配的动图:

不满足括号匹配有这三种情况:
- 遇到右括号就将栈中的一个左括号出栈,发现不匹配
- 括号已经全部扫描完了,发现栈中还有未出栈的左括号
- 当扫描到一个右括号时,发现栈已空,即没有左括号
这里就给出第三种不匹配动图:

但最重要的还是代码实现,你可以先思而后行,先自己敲代码,再来看看正确代码。
bool bracketCheck(char str[] , int length)
{
SqStack S;
InitStack (S);
for (int i = 0 ; i < length ; ++i)
{
if (str[i] == '(' || str[i] == '[' || str[i] == '{' ) //扫描到左括号,入栈
{
Push(S , str[i]);
}
else{
if (StackEmpty(S)) return false;//扫描到右括号,但是当前栈空
char topelem; //栈顶元素出栈
Pop(S , topelem);
if (str[i] == ')' && topelem != '(') return false;
if (str[i] == ']' && topelem != '[') return false;
if (str[i] == '}' && topelem != '{') return false;
}
}
return StackEmpty(S);//最后检索完全部括号后,还要检测此时栈是否为空
} 上面的InitStack函数、StackEmpty函数、Push函数、Pop函数都一一介绍了哦。
这题既然我们已经知道了length ,所以用栈的顺序存储(建议静态存储就行了)。
2、栈排序
如果给你一个装有元素的栈Stack1,并且里面的元素是乱序的,现在要求你只能格外再定义一个辅助栈Stack2,然后对Stack1进行排序,你如何实现这一过程呢?
做法思路:
- Stack2为空栈,直接将Stack1.top()压入Stack2。
- Stack2非空,若Stack1.top() <= Stack2.top(),Stack1.top()出栈并压入Stack2。
- Stack2非空,若Stack1.top() > Stack2.top(),Stack2.top()陆续出栈,并且压入Stack1,直至Stack1.top()【这个值是一开始的top值,不是陆续压入Stack1的top值】 <= Stack2.top(),Stack1.top()出栈并压入Stack2。
为了方便大家理解,我也是辛苦地画了图(![]() )
)
假设一开始Stack1的初始数据是:4、2、3、7
【1】
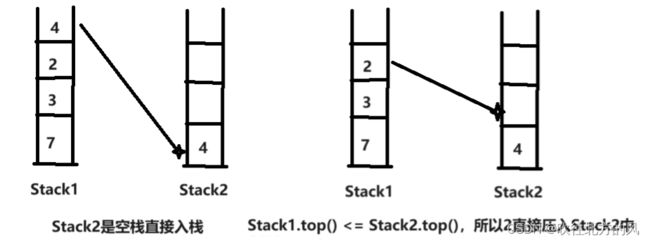
【2】
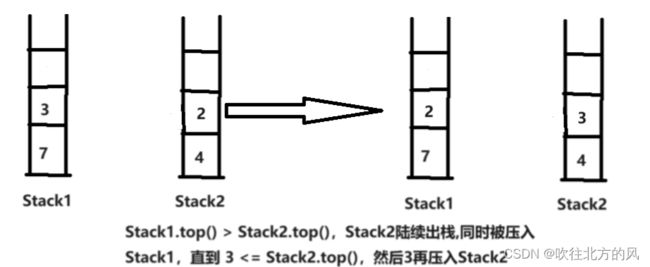
【3】
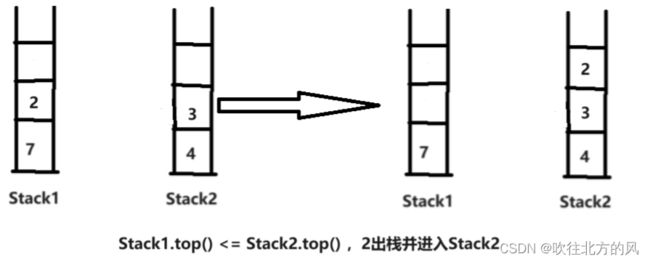
【4】
 【5】
【5】

最后要想得到Stack的降序,只需要将Stack2依次出栈压入Stack1,就了。
代码实现:
void Stacksort(SqStack &stack1)
{
SqStack stack2;
InitStack(stack2);
while (StackEmpty(stack1))
{
int top1 = Pop(stack1);
while (!StackEmpty(stack2) || top1 > GetTop(stack2))
{
Push(stack1 , Pop(stack2);
}
Push(stack2 , top1);
}
while (StackEmpty(stack2))
{
Push(stack1 , pop(stack2)); //最后就能得到排好序的stack1
}
}3、单调栈
见名知意,就是栈中元素,按递增顺序或者递减顺序排列。
优点:单调栈的最大好处就是时间复杂度是线性的,每个元素遍历一次!
这里例举一道非常常见且容易理解的粟子:
给定一个长度为 N 的整数数列,输出每个数左边第一个比它小的数,如果不存在则输出 −1。
输入样例:
5 3 4 2 7 5输出样例:
-1 3 -1 2 2
代码实现:
void question(int a[] , int length)
{
SqStack s;
InitStack(s);
for (int i = 0 ; i < length ; ++i)
{
while (EmptyStack(s) && GetTop(s) >= a[i]) //维持单调递增栈
{
Pop(s);
}
if (!EmptyStack(s)) printf("%s " , "-1");
else {
printf("%d ", GetTop(s));
}
Push(s , a[i]);
}
}感兴趣的可以刷刷这道题:柱状图中的最大矩形
4、栈在递归中的应用
我并不是教会你如何设计好一个递归算法,而是重点搞懂递归调用时,递归调用栈(也叫“递归工作站”)的变化过程,即了解栈在递归中的应用。
一个直接调用自己或通过一系列的调用语句间接地调用自己的函数,称作递归函数。
函数调用的特点:最后被调用的函数最先执行结束(栈的后进先出特点)。
函数调用时,需要用一个栈存储(每进入一层递归,就将递归调用所需要信息压入栈中):
- 调用后的返回地址
- 所有实参
- 所有局部变量
从主函数main()开始,其数据被压入栈中,然后执行到func1 ,将该函数的“工作记录”压入栈中,同时还有存储func1执行完后,下一条操作的地址#1,以便递归返回。
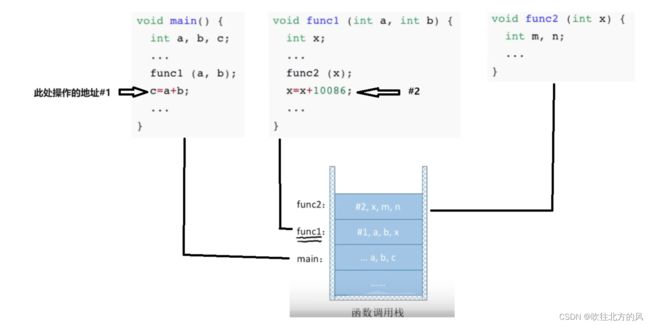
最后func2执行完后,就出栈,然后根据地址#2,执行func1中剩下的操作,最后func1执行完后,也会出栈,然后执行#1.................
递归的优缺点:
优点:代码更简洁清晰,可读性更好,比如求一个数的阶乘等。
缺点:
【1】时间和空间消耗比较大。每一次函数调用都需要在内存栈中分配空间以保存参数,返回地址以及临时变量,而且往栈里面压入数据和弹出都需要时间。
【2】另外递归会有重复的计算。递归本质是把一个问题分解为多个问题,如果这多个问题存在重复计算,有时候会随着n成指数增长。斐波那契的递归就是一个例子。
【3】递归还有栈溢出的问题,每个进程的栈容量是有限的。由于递归需要系统堆栈,所以空间消耗要比非递归代码要大很多。而且,如果递归深度(层数)太大,可能系统撑不住。
斐波那契递归的举例:
int Fib(int n)
{
if (n == 0) return 0;
else if (n == 1) return 1;
else return Fib(n - 1) + Fib(n - 2);
}
我们可以非常明显的发现F(2)、F(3)多次计算 。
当然聪明的你,也可以将递归算法改造成非递归算法(可能代码量很多),非递归算法的实现方式可以使用迭代、循环或者栈等数据结构来替代递归函数的调用。
著名的 Hanoi 塔问题就能通过递归直观的表示出来,感兴趣的家人们可以搜搜看。
5、栈的表达式求值(上)

其实我写的还不如视频里的讲的清楚明了,你可以先去看看视频(点这),再来温故一下我写的,基本就稳啦。
任何一个表达式都是由操作数、运算符、界限符组成。
为了叙述简洁,我们只探索简单的算术表达式(只含 + 、- 、*、/ 四种运算符)。
中缀转后缀:

为了和机算结果相同,请务必采用 “左优先原则” ,这样运算符就从左到右依次生效了。
手算后缀表达式的结果:

知道了后缀表达式的手算方法,那么栈实现的代码思路就了。

动图展示:
⚠️:
- 若中缀表达式合法,则最后栈中只会留下一个元素,即最终的计算结果。
- 先出栈计算的操作数,应位于运算符右边。
代码实现:
思路:我们使用一个整数数组来存储操作数,通过遍历后缀表达式的每个字符,根据字符的类型进行相应的操作。如果遇到操作数,将其转换为整数并入栈;如果遇到运算符,从栈中弹出两个操作数进行计算,并将结果入栈。最终,栈中剩余的元素即为计算结果。
⚠️:这个代码仅仅针对简单的算术表达式,并且初始操作数必须是正整数,这里给出这种代码,只是帮助你进一步理解计算机的栈实现代码流程(空格用来隔开操作数和运算符)。
// 计算后缀表达式的值
double evaluatePostfix(char* postfix) {
SqStack stack;
initStack(&stack);
int i = 0;
while (postfix[i] != '\0') {
int num = 0 , flag = 0;
// 如果是操作数,将其转换为整数并入栈
while (isdigit(postfix[i]) && postfix[i] != ' ') { //isdigit函数为判断ch是否为数字
flag = 1;
num = num * 10 + (ch - '0');
i++;
}
if (flag && isFull(stack) push(&stack, num); //将操作数入栈
else {
printf("Stack is full.\n");//因为我用的是静态存储,所以栈的大小是有限的
exit(EXIT_FAILURE);//程序会立即终止
}
if (postfix[i] == ' ')
{
//空格忽略
}
else {
double operand2 , operand1; //如果是运算符,从栈中弹出两个操作数进行计算,并将结果入栈
if (isEmpty(stack)){
operand2 = pop(&stack);
}else {
printf("Stack is empty.\n");
exit(EXIT_FAILURE);//程序会立即终止
}
//同理
if (isEmpty(stack)){
operand1 = pop(&stack);
}else {
printf("Stack is empty.\n");
exit(EXIT_FAILURE);//程序会立即终止
}
double result;
switch (postfix[i]) {
case '+':
result = operand1 + operand2; //先出栈计算的操作数,应位于运算符右边
break;
case '-':
result = operand1 - operand2;
break;
case '*':
result = operand1 * operand2;
break;
case '/':
result = operand1 / operand2;
break;
default:
printf("Invalid operator.\n");
exit(EXIT_FAILURE); //程序会立即终止
}
if (isFull(stack)){
push(&stack, result);
}else{
printf("Stack is full.\n");//因为我用的是静态存储,所以栈的大小是有限的
exit(EXIT_FAILURE);
}
}
i++;
}
// 返回栈顶元素,即为计算结果
return pop(&stack);
}中缀转前缀:

为了和机算结果相同,请务必采用 “右优先原则” ,这样运算符就从右到左依次生效了。
手算前缀表达式的结果:

当然方法和后缀的计算是非常相似的,只需要从右至左扫描后缀表达式……
栈实现:

⚠️:先出栈计算的操作数,应位于运算符左边。
 图解和代码基本和后缀的思想是一样,就略了。
图解和代码基本和后缀的思想是一样,就略了。
总结:

6、栈的表达式求值(下)
中缀转后缀,当表达式比较短时,手算是没有问题的,但当比较长时,就需要借助计算机来实现。

这里我们只考虑()、+、- 、* ,/ 。
中缀转后缀(机算)

过程展示:

如果想跟着计算机的思路走,可以自己模拟计算机实现下面这道题哦:
 代码实现就略了,只要思路明白,写起来不是很麻烦的(其实我就是懒
代码实现就略了,只要思路明白,写起来不是很麻烦的(其实我就是懒 )
)
中缀表达式的计算:
观察上面的中缀转后缀,然后通过后缀再计算出结果,我们可以发现,对于中缀转后缀我们用到了一个运算符栈,对于后缀的计算我们用到了一个操作数栈。当用代码实现这一过程时,我们就用这两个栈来实现这一计算,并且不需要先转后缀再计算,可以通过这两个栈同时维持它们的运算过程。

代码实现,也略了,只要思路懂了,考试时,不会让你写出完整的代码,可能会给你一个实现其部分功能的伪代码,然后留几个空让你填,不足畏惧!
总结:
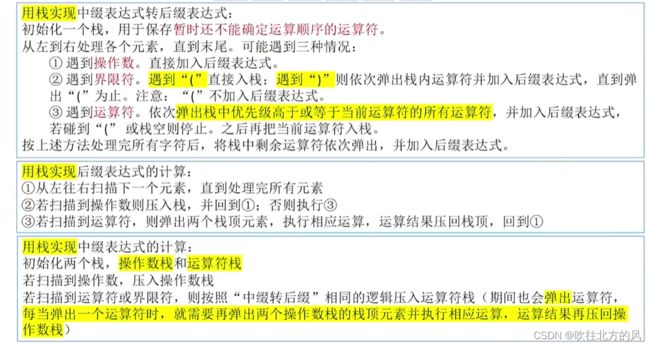
☆ 队列 :
一、队列的基本概念
1、队列的定义
队列 是只允许在一端进行插入,在另一端删除的线性表

队列的特点是:先进先出(FIFO结构)
2、队列的基本操作
InitQueue(&Q):初始化队列,构造一个空队列Q。
DestroyQueue(&Q):销毁队列。销毁并释放队列Q所占用的内存空间。
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
EnQueue(&Q, x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&Q, &x):出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(Q, &x):读队头元素,若队列Q非空,则将队头元素赋值给x。
……………………
这些都会在下文,结合队列的存储结构来实现。
二、队列的顺序存储结构
1、队列的顺序实现(从顺序到循环)
队列的定义:
#define MaxSize 10
typedef struct{
ElemType data[MaxSize]; //用静态数组存放队列元素
int front , rear; //对头指针和队尾指针
} SqQueue; 入队时:将新元素插入rear所指的位置,然后将rear加1。
出队时:删去front所指的元素,然后将front加1,并返回被删元素。
⚠️⚠️⚠️:
(1)当头尾指针相等时,队列为空。
(2)在非空队列里,队头指针始终指向队头元素,队尾指针始终指向队尾元素的下一位置。
相关问题:
在普通顺序队列中,入队操作就是先将元素值赋给rear单元(data[rear]=X),然后尾指针rear后移一个单元(rear++)。出队时.则是头指针front后移(front++)。像这样进行了一定数量入队和出队操作后,可能会出现这样的情况:尾指针rear已指到数组的最后一个元素.即rear == MaxSize.此时若再执行入队操作,便会出现队满“溢出”。然而,由于在此之前可能也执行了若干次出队操作.因而数组的前面部分可能还有很多闲置的元素空间,即这种溢出并非是真的没有可用的存储空间,故称这种溢出现象为“假溢出”。显然,必须要解决这一似溢出的问题,否则顺序队列就没有太多使用价值。

这时候,不能以为rear == MaxSize == 8 ,就以为队列已满。就如上面的图(b)所画的一样,该队列还有a[0]、a[1]、a[2]、a[3]的空闲空间,那我们怎么利用起来呢?
因为我们的rear指针始终指向队尾元素的下一位置 ,那如果我们将rear重新指向 a[0]这个位置,那这段空闲的空间就能利用起来,那怎么才能用最简单、最便捷的方式做到这一点呢:
取模操作,即我们在入队操作时,先将元素值赋给rear单元(data[rear]=X),然后尾指针rear采用取模的操作进行 + 1,即:
Q.data[Q.rear] = x;
Q.rear = (Q.rear + 1) % MaxSize; //队尾指针 + 1再取模这样做的好处就是当rear == MaxSize - 1 时,再进行入队操作后, rear = (MaxSize - 1 + 1) % MaxSize = 0;这样我们就非常轻松的解决了这一问题了。
因此通过这种取模运算将存储空间在逻辑上变成了”环状“ ,即循环队列。

那为什么a[7]这个存储空间,就不能再用来存数据呢?
因为我们一开始,是当头尾指针相等时,即front == rear,队列才为空。如果这里a[7]存了数据,那么rear再+ 1取模,就会导致 rear = 0 ,此时rear == front,队列应当为空,但实际上此时队列已满,这就会产生歧义,因此我们会将队列已满的条件定为:队尾指针的再下一个位置是队头,即:
(Q.rear + 1) % MaxSize == Q.front但这显然会以牺牲一个存储单元为代价。
同理,出队操作也应采用 + 1再取模的操作,即:
Q.front = (Q.front + 1) % MaxSize总结:
初始时:Q.front = Q.rear = 0
队首指针进1:Q.front = (Q.front + 1) % MaxSize
队尾指针进1:Q.rear = (Q.rear + 1) % MaxSize
队列长度:(Q.rear - Q.front + MaxSize) % MaxSize
队列已空: Q.front = Q.rear
队列已满:(Q.rear + 1) % MaxSize == Q.front⚠️⚠️⚠️:
对于我们平时做题来说,上述循环队列的方法就已经了,但是对于出题老师来说,这还没有完,就比如那个浪费的存储单元来说,如果让你不浪费这个存储单元,也必须要正常的判断队列是否已满或已空呢?
(1)这里你可以在定义队列时引入一个Size 来存队列当前的长度,当Size == 0 时,队列为空;当Size == MaxSize 时,队列已满。
#define MaxSize 10
typedef struct{
ElemType data[MaxSize]; //用静态数组存放队列元素
int front , rear; //对头指针和队尾指针
int Size;//队列当前长度,初始化时,应为0
} SqQueue; 每当入队一个元素,Size++
每当出队一个元素,Size - -
(2)当然还有一种简单的方式,熟悉上面的操作,我们知道:
● 只有删除操作,才可能导致队空
● 只有插入操作,才可能导致队满
因此我们将 Size 替换成 Tag (Tag初始化应为0),每次删除操作成功时,都令 Tag = 0;每当插入操作成功时,都令 Tag = 1,这样的话:
队满条件:front == rear && tag == 1
队空条件:front == rear && tag == 0⚠️⚠️⚠️:
 当然你的出题老师远远不止于此,如果他将rear 改为指向当前队尾元素,之前我们介绍的是指向队尾元素的下一位置。当然这对于你们这些聪明的脑袋,可能早已经想出来了,因此你不妨先思而后行。
当然你的出题老师远远不止于此,如果他将rear 改为指向当前队尾元素,之前我们介绍的是指向队尾元素的下一位置。当然这对于你们这些聪明的脑袋,可能早已经想出来了,因此你不妨先思而后行。
首先队列初始化时,应改为:
Q.front = 0
Q.rear = MaxSize - 1入队操作应改为:
Q.rear = (Q.rear + 1) % MaxSize
Q.data[Q.rear] = x出队操作还是一样的:
x = Q.data[Q.front]
Q.front = (Q.front + 1) % MaxSize判空操作应改为(如下面左图):
(Q.rear + 1) % MaxSize == Q.front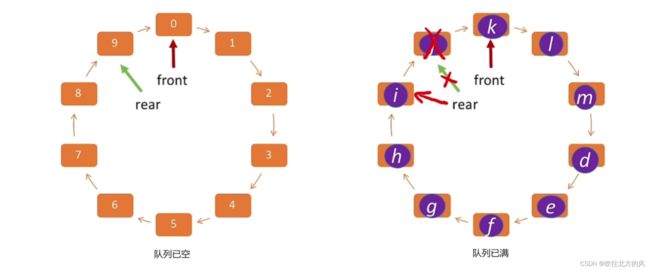
判断队列已满应改为(如上面右图):
t = (Q.rear + 1) % MaxSize
(t + 1) % MaxSize == Q.front 当然这种方法还是采取了牺牲一个存储单元为代价,不过既然我们已经掌握上面描述 Size = 0 和 Tag = 0 来解决这个问题的方法,那岂不是就能解决它了嘛?因此检验你有没有掌握上面方法的机会来了,快动手敲吧~
当然这种方法还是采取了牺牲一个存储单元为代价,不过既然我们已经掌握上面描述 Size = 0 和 Tag = 0 来解决这个问题的方法,那岂不是就能解决它了嘛?因此检验你有没有掌握上面方法的机会来了,快动手敲吧~
总结:

三、队列的链式存储结构
用链表表示的队列简称为链队列。一个链队列显然需要两个分别指示队头和队尾的指针(分别称为头指针和尾指针)才能唯一确定。新元素(等待进入队列的元素)总是被插入到链表的尾部,而读取的时候总是从链表的头部开始读取。
在之前线性表讲的单链表,它只需要一个头指针就能实现单链表基本操作,但对于在单链表尾部操作,我们仍然需要O(n)的复杂度,因此对于队列这种先进先出的结构,我们应该设置一个队尾指针,并且随着在队尾的插入,尾指针始终指向尾结点。
链队列的定义(分为结点、队头指针、队尾指针):
typedef struct LinkNode{ //定义链式队列的结点
ElemType data;
struct LinkNode *next;
} LinkNode;typedef struct{ //定义链式队列的头尾指针
LinkNode *front , *rear;
} LinkQueue; //一个由头指针和尾指针确定的链式队列 
如上图中(a)展示的就是带头结点的空队列,因此初始化操作为:
void InitQueue(LinkQueue &Q)
{
// 初始化时,front、rear都指向头结点
Q.front = Q.rear = (LinkNode*)malloc(sizeof(LinkNode));
Q.front -> next = NULL; //头结点指向NULL
} 同理不带头结点:
void InitQueue(LinkQueue &Q)
{
// 初始化时,front、rear都指向NULL
Q.front = Q.rear = NULL;
} 1、基本操作 (带头结点vs不带头结点)
入队操作(带头结点),如上图(b)、(c)
void EnQueue(LinkQueue &Q, ElemType x)
{
LinkNode *s = (LinkNode*)malloc(sizeof (LinkNode));
s -> data = x;
s -> next = NULL;
Q.rear -> next = s; //新结点插入到rear之后
Q.rear = s; //最后修改表尾指针
}入队操作(不带头结点)
void EnQueue(LinkNode &Q , ElemType x)
{
LinkNode *s = (LinkNode *)malloc(sizeof(LinkNode));
s -> data = x;
s -> next = NULL;
if (Q.front == NULL) //插入的第一个元素需要特殊处理一下
{
Q.front = s;
Q.rear = s;
}
else{
Q.rear -> next = s;
Q.rear = s;
}
}出队操作(带头结点),如上图(d )
bool DeQueue(LinkQueue &Q , ElemType &x)
{
if (Q.front == Q.rear) return false; //空队
LinkNode *p = Q.front -> next;//从队头开始出队
x = p -> data;
Q.front -> next = p -> next; //这种操作,已很easy了
if (Q.rear == p) //如果此次出队的已是最后一个结点
{
Q.rear = Q.front; //修改rear指向
}
free(p); //释放结点空间
return true;
}出队操作(不带头结点)
bool DeQueue(LinkQueue &Q , ElemType &x)
{
if (Q.front == NULL) return false; //空队
LinkNode *p = Q.front;
x = p -> data;
Q.front = p -> next; //这种操作,已很easy了
if (Q.rear == p) //如果此次出队的已是最后一个结点
{
Q.rear = NULL;
Q.front = NULL;
}
free(p); //释放结点空间
return true;
}销毁队列
//带头结点 和 不带头结点都适用
void DestroyQueue(LinkQueue &Q)
{
while (Q.front){
Q.rear = Q.front -> next;
free(Q.front);
Q.front = Q.rear;
}
}
四、双端队列
双端队列是限定插入和删除操作在表的两端进行的线性表。这两端分别称做前端和后端。
英文常缩写成:deque(double-ended queue,双端队列)
1、正常和特殊
正常的双端队列就如上面所定义的一样:

如上图中元素的位置,1从左边入队,你只能在2的后面,而1要出队可以从左边出队,或者让2、3、4、5都从右边出队,1才能从右边出队。同理其他元素也应遵循这个规则。
特殊的双端队列:
【1】 输入受限的双端队列

【2】 输出受限的双端队列

当然这三种双端队列都具有栈和队列的特点 ,考试的时候一般都是出现在选择题里面,例如给你进队的数,让你判断依次出队的序列,因此你首先要看清楚它是属于哪种双端队列,再结合它们的特点依次待入,看是否满足条件。
五、队列的应用
1、单调队列
单调队列和单调栈一样,实现起来是很简单的,。其本质上就是在线性的复杂度内找到某个区间内的最大值或最小值,
单调队列主要用于解决滑动窗口相关的问题,例如求滑动窗口的最大值、最小值等。
在实际开发中,滑动窗口问题经常出现在需要处理连续子数组或子序列的情况下。通过使用单调队列,我们可以高效地解决这类问题。
举个例子,假设我们有一个长度为n的数组,现在要求滑动窗口的长度为k,求每个滑动窗口的最大值。如果我们使用暴力解法,需要遍历每个窗口并找到其中的最大值,时间复杂度为O(n*k)。但是,如果我们使用单调队列,可以将时间复杂度降低到O(n)。
给定一个大小为 n≤1e6 的数组。
有一个大小为 k的滑动窗口,它从数组的最左边移动到最右边。
你只能在窗口中看到 k 个数字。
每次滑动窗口向右移动一个位置。
以下是一个例子:
该数组为 [1 3 -1 -3 5 3 6 7],k 为 3。
你的任务是确定滑动窗口位于每个位置时,窗口中的最大值和最小值。输入格式:
输入包含两行。
第一行包含两个整数 n 和 k,分别代表数组长度和滑动窗口的长度。
第二行有 n 个整数,代表数组的具体数值。
同行数据之间用空格隔开。
输出格式:
输出包含两个。
第一行输出,从左至右,每个位置滑动窗口中的最小值。
第二行输出,从左至右,每个位置滑动窗口中的最大值。
输入样例:
8 3
1 3 -1 -3 5 3 6 7
输出样例:-1 -3 -3 -3 3 3
3 3 5 5 6 7

具体实现时,我们可以使用两个单调队列,一个用于存储当前窗口的最大值,一个用于存储当前窗口的最小值。在遍历数组的过程中,我们不断更新队列,保持队列中的元素单调递减(最大值队列)或单调递增(最小值队列)。这样,每次窗口滑动时,我们只需要从队列的头部取出最大值和最小值即可。
代码(数组模拟队列,也可以直接用上面的链队列实现):
#include
const int N = 1000100;
//单调队列一般用双端队列保证其单调性
int a[N], q[N], n, k;
//队头和队尾,在队尾插入,队头获取
int front = 0, tail = -1;
int main() {
scanf("%d%d", &n, &k);
for (int i = 0; i < n; i++) scanf("%d", &a[i]);
//先找每个窗口的最小值
for (int i = 0; i < n; i++) {
//如果当前队头在数组的下标小于当前窗口的最小下标,这个窗口就不包含这个元素了那么无论如何都要剔除队头这个元素
//所以要在队头删除这个元素
if (front <= tail && i - k + 1 > q[front]) front++;
//保证单调性,在队尾删除(为什么要在队尾删除,简单来说在队头删除不能保证单调
//比如-3 5为当前队列,当前的元素为3,如果在队头操作,那么按照a[i] <= a[q[front],有3 > -3,因此不做删除操作
//但是接下来就出现问题了,3就要入队了。此时队列就是-3 5 3,不符合单调性了!
//但如果在队尾操作,按照a[i] <= a[q[tail],有3 < 5,就要让5出队
//之后3入队,队列就是-3 3,满足单调性
while (front <= tail && a[i] <= a[q[tail]]) tail--;
q[++tail] = i;
//队头为窗口的最小值
if (i >= k - 1) printf("%d ", a[q[front]]);
}
printf("\n");
//这次找最大值,同理
front = 0, tail = -1;
for (int i = 0; i < n; i++) {
if (front <= tail && i - k + 1 > q[front]) front++;
while (front <= tail && a[i] >= a[q[tail]]) tail--;
q[++tail] = i;
if (i >= k - 1) printf("%d ", a[q[front]]);
}
} 通过使用单调队列,我们可以高效地解决滑动窗口问题,提高算法的效率。
这里我用的数组模拟队列,仅仅是为了节省代码,看懂了这个思想,可以用上面讲的链队列实现具体的队列出队、入队等操作。
2、树的层次遍历
考虑到部分同学,这部分内容,等写到第6章《树和二叉树》时,会再次回来写这部分内容。
3、图的广度优先遍历
考虑到部分同学,这部分内容,等写到第7章《图》时,会再次回来写这部分内容。
结尾:
最后,非常感谢大家的阅读。我接下来还会更新 串,如果本文有错误或者不足的地方请在评论区(或者私信)留言,一定尽量满足大家,如果对大家有帮助,还望三连一下啦 。
。
我的个人博客,欢迎访问!
Reference
【1】严蔚敏、吴伟民:《数据结构(C语言版)》
【2】b站:王道数据结构