MySQL - InnoDB 内存结构解析
下面是官方的 InnoDB 引擎架构图,主要分为内存结构和磁盘结构两大部分。

一、Buffer Pool 概述
Buffer Pool:缓冲池,简称 BP。其作用是用来缓存表数据与索引数据,减少磁盘 IO 操作,提升效率。
Buffer Pool 由缓存数据(Page) 和对缓存数据页进行描述的控制块组成,控制块中存储着对应缓存页的所属的表空间、数据页的编号、以及对应缓存页在 Buffer Pool 中的地址等信息。
Buffer Pool 默认大小是 128M, 以 Page 页为单位,Page 页默认大小 16K,而控制块的大小约为数据页的5%,大概是800字节。
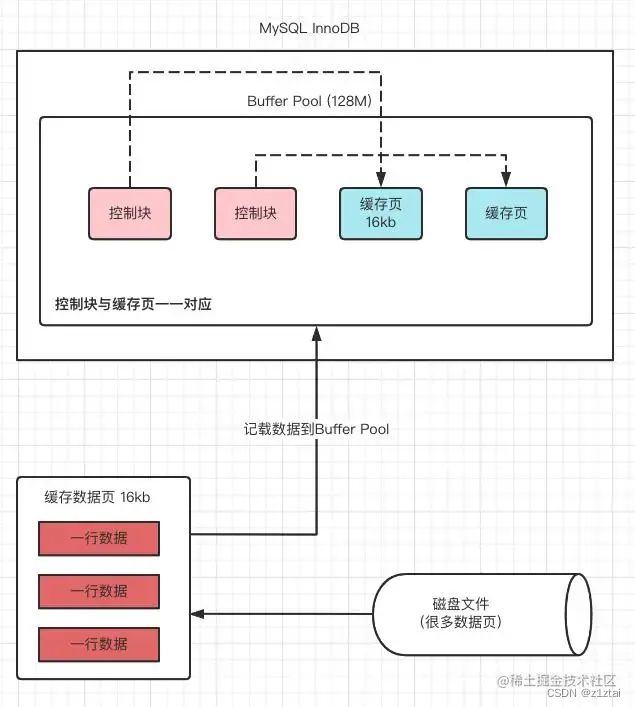
注:Buffer Pool 大小为 128M 指的就是缓存页的大小,控制块则一般占5%,所以每次会多申请 6M 的内存空间用于存放控制块。
如何判断一个页是否在 BufferPool 中缓存 ?
MySQl 中有一个哈希表数据结构,它使用表空间号+数据页号,作为一个 key,然后缓冲页对应的控制块作为 value。

当需要访问某个页的数据时,先从哈希表中根据表空间号和页号看看是否存在对应的缓冲页。如果有,则直接使用;如果没有,就从 free 链表中选出一个空闲的缓冲页,然后把磁盘中对应的页加载到该缓冲页的位置。
二、Page 页分类
Page 根据状态可以分为三种类型:

- Free Page:空闲 Page,未使用
- Clean Page:被使用 Page 但是数据没有修改过
- Dirty Page:脏页,使用过数据被修改过,与磁盘数据产生不一致
针对上面所说的三种 page 类型,InnoDB 通过三种链表结构来维护和管理。
BP 的底层采用链表数据结构管理 Page。在 InnoDB 访问表记录和索引时会在 Page页 中缓存,以后使用可以减少磁盘 IO 操作,提升效率。
2.1、Page 页管理之 Free 链表
free list:表示空闲缓冲区,管理 free page
Buffer Pool 的初始化过程中,是先向操作系统申请连续的内存空间,然后把它划分成若干个控制块&缓冲页的键值对。
free 链表是把所有空闲的缓冲页对应的控制块作为一个个的节点放到一个链表中,这个链表便称之为 free 链表
基节点:free 链表中只有一个基节点是不记录缓存页信息(单独申请空间),它里面就存放了 free 链表的头节点的地址,尾节点的地址,还有 free 链表里当前有多少个节点。

磁盘加载页的流程:
- 从 free 链表中取出一个空闲的控制块,对应缓冲页。
- 把该缓冲页对应的控制块的信息填上,例如:页所在的表空间、页号之类的信息。
- 把该缓冲页对应的 free 链表节点即控制块从链表中移除。表示该缓冲页已经被使用了。
2.2、Page 页管理之 Flush 链表
flush list: 表示需要刷新到磁盘的缓冲区,管理 dirty page,内部 page 按修改时间排序。
InnoDB 引擎为了提高处理效率,在每次修改缓冲页后,并不是立刻把修改刷新到磁盘上,而是在未来的某个时间点进行刷新操作。
所以需要使用到 flush 链表存储脏页,凡是被修改过的缓冲页对应的控制块都会作为节点加入到 flush 链表。
flush 链表的结构与 free 链表的结构相似

脏页即存在于 flush 链表,也在 LRU 链表中,但是两种互不影响,LRU 链表负责管理 page 的可用性和释放,而 flush 链表负责管理脏页的刷盘操作。
2.3、Page 页管理之普通 LRU 链表
LRU = Least Recently Used(最近最少使用):就是末尾淘汰法,新数据从链表头部加入,释放空间时从末尾淘汰。

- 当要访问某个页时,如果不在 Buffer Pool,需要把该页加载到缓冲池,并且把该缓冲页对应的控制块作为节点添加到 LRU 链表的头部。
- 当要访问某个页时,如果在 Buffer Pool中,则直接把该页对应的控制块移动到 LRU 链表的头部。
- 当需要释放空间时,从最末尾淘汰。
2.4、普通 LRU 链表的优缺点
优点: 所有最近使用的数据都在链表表头,最近未使用的数据都在链表表尾,保证热数据能最快被获取到。
缺点:如果发生全表扫描(比如:没有建立合适的索引 or 查询时使用 select * 等),则有很大可能将真正的热数据淘汰掉。由于MySQL中存在预读机制,很多预读的页都会被放到 LRU 链表的表头。如果这些预读的页都没有用到的话,会导致很多尾部的缓冲页很快就会被淘汰。

2.5、Page 页管理之改进型 LRU 链表
改进型 LRU:链表分为 new 和 old 两个部分,加入元素时并不是从表头插入,而是从中间 midpoint 位置插入(就是说从磁盘中新读出的数据会放在冷数据区的头部),如果数据很快被访问,那么 page 就会向 new 列表头部移动,如果数据没有被访问,会逐步向old尾部移动,等待淘汰。
 冷数据区的数据页什么时候会被转到到热数据区呢 ?
冷数据区的数据页什么时候会被转到到热数据区呢 ?
- 如果该数据页在 LRU 链表中存在时间超过1s,就将其移动到链表头部(链表指的是整个LRU 链表)。
- 如果该数据页在 LRU 链表中存在的时间短于1s,其位置不变(由于全表扫描有一个特点,就是它对某个页的频繁访问总耗时会很短)。
- 1s这个时间是由参数 innodb_old_blocks_time 控制的。
三、Change Buffer
3.1、概述
Change Buffer:写缓冲区,是针对二级索引(辅助索引) 页的更新优化措施
作用::在进行 DML 操作时,如果请求的是辅助索引(非唯一键索引)没有在缓冲池中时,并不会立刻将磁盘页加载到缓冲池,而是在 CB 记录缓冲变更,等未来数据被读取时,再将数据合并恢复到 BP 中。
ChangeBuffer 占用 BufferPool 空间,默认占25%,最大允许占50%,可以根据读写业务量来进行调整。参数 innodb_change_buffer_max_size ;

3.2、Change Buffer 数据更新流程
场景1: 对于唯一索引来说,需要将数据页读如内存,判断没有冲突,插入这个值,语句执行结束;
场景2: 对于普通索引来说,则是将更新记录在 change buffer 流程如下

- 更新一条记录时,该记录在 bp 存在,直接在 bp 修改,一次内存操作。
- 如果该记录在 bp 不存在(没有命中),在不影响数据一致性的前提下,InnoDB 会将这些更新操作缓存在 change buffer 中不用再去磁盘查询数据,避免一次磁盘 IO。
- 当下次查询记录时,会将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
问题一:为什么写缓冲区,仅适用于非唯一普通索引页?
如果在索引设置唯一性,在进行修改时,InnoDB 必须要做唯一性校验,因此必须查询磁盘,做一 次 IO 操作。会直接将记录查询 Buffer Pool 中,然后在缓冲池修改,不会在 Change Buffer 操作。
问题二:什么情况进行 merge?
将 change buffer 中的操作应用到原数据页,得到最新结果的过程称为 merge。
change buffer,实际上它是可以持久化的数据。也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上,以下情况会进行持久化:
- 访问这个数据页会触发 merge。
- 系统有后台线程会定期 merge。
- 在数据库正常关闭( shutdown )的过程中,也会执行 merge 操作。
3.3、change buffer 使用场景
change buffer 的主要目的就是将记录的变更动作缓存下来,所以在 merge 发生之前应当尽可能多的缓存变更信息,这样 change buffer的优势发挥的就越明显。
应用场景:对于写多读少的业务来说,页面在写完以后马上被访问到的概率比较小,此时 change buffer 的使用效果最好。这种业务模型常见的就是账单类、日志类的系统。
4、Log Buffer
Log Buffer:日志缓冲区,用来保存要写入磁盘上的 Log 文件(redo/undo)的数据,日志缓冲区内容定期刷新道磁盘 Log 文件中,日志缓冲区满时会自动将其刷新到磁盘,节省磁盘 io
Log Buffer 主要记录 innoDB 引擎日志,在 DML 操作时会产生 Redo 和 Undo 日志
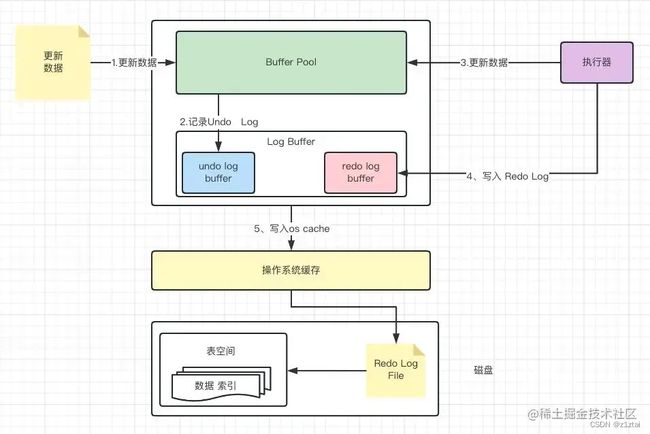
Log Buffer 空间满了,会自动写入磁盘。可以通过将将 innodb_log_buffer_size 参数调大,减少磁盘 IO 频率
innodb_flush_log_at_trx_commit 参数控制日志刷新行为,默认为1
- 每隔1秒写日志文件和刷盘操作(写日志文件 LogBuffer–>OS cache,刷盘 OS cache–>磁盘文件),最多丢失1秒数据
- 事务提交,立刻写日志文件和刷盘,数据不丢失,但是会频繁 IO 操作
- 事务提交,立刻写日志文件,每隔1秒钟进行刷盘操作
SHOW VARIABLES LIKE ‘innodb_flush_log_at_trx_commit’;

SHOW VARIABLES LIKE ‘innodb_log_buffer_size’;

5、Adaptive Hash Index
自适应哈希索引,用于优化 bp 数据查询
6、总结
本期讲了关于 InnoDB 内存结构,后续有机会在继续介绍 InnoDB 磁盘结构。