UCAS - AI学院 - 自然语言处理专项课 - 第2讲 - 课程笔记
UCAS-AI学院-自然语言处理专项课-第2讲-课程笔记
- 数学基础
-
- 概率论基础
- 信息论基础
-
- 熵(Entropy)
- 联合熵(Joint Entropy)
- 条件熵(Conditional Entropy)
- 熵率(Entropy Rate)
- 相对熵(Relative Entropy)
- 交叉熵(Cross Entropy)
- 困惑度(Perplexity)
- 互信息(Mutual Information)
- 噪声信道模型(Noisy Channel Model)
- 信道容量(Capacity)
- 应用举例
-
- 词汇歧义消解
-
- 问题提出
- 基本思路
- 实现方法
- 工作过程
数学基础
概率论基础
- 概率
- 最大似然估计
- 条件概率
- 全概率公式
- 贝叶斯决策理论
- 贝叶斯法则
- 二项式分布
- 期望
- 方差
- NLP中,以句子为基本处理单位时,一般假设与其他语句独立,句子的概率分布近似地符合二项式分布
信息论基础
熵(Entropy)
- 如果 X X X是一个离散型的随机变量,其概率分布为: p ( x ) = P ( X = x ) , x ∈ X p(x) = P(X = x), x\in X p(x)=P(X=x),x∈X,那么 X X X的熵 H ( X ) H(X) H(X)定义为:
H ( X ) = − ∑ x ∈ X p ( x ) log 2 p ( x ) H(X) = -\sum_{x \in X} p(x) \log_2 p(x) H(X)=−x∈X∑p(x)log2p(x)
- 约定 0 log 0 = 0 0 \log 0 = 0 0log0=0
- 单位为比特(bit)
- 又称为自信息
- 表示信源 X X X每发一个信号(发生一个事件)所提供的平均信息量
- 可视为描述一个随机变量的不确定性的数量
- 一个随机变量的熵越大,其不确定性越大,那么正确估计其值的可能性越小
联合熵(Joint Entropy)
- 如果 X X X和 Y Y Y是一对离散型随机变量 X , Y ∼ p ( x , y ) X, Y \sim p(x, y) X,Y∼p(x,y),其二者的联合熵 H ( X , Y ) H(X, Y) H(X,Y)定义为:
H ( X , Y ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( x , y ) H(X, Y) = - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(x, y) H(X,Y)=−x∈X∑y∈Y∑p(x,y)log2p(x,y)
- 实际上就是描述一对随机变量平均所需的信息量
条件熵(Conditional Entropy)
- 在给定随机变量 X X X的情况下,随机变量 Y Y Y的条件熵定义为:
H ( Y ∣ X ) = ∑ x ∈ X p ( x ) H ( Y ∣ X = x ) = ∑ x ∈ X p ( x ) [ − ∑ y ∈ Y p ( y ∣ x ) log 2 p ( y ∣ x ) ] = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( y ∣ x ) \begin{aligned} H(Y | X) &= \sum_{x \in X} p(x) H(Y | X = x) \\ &= \sum_{x \in X} p(x) \left[ - \sum_{y \in Y} p(y | x) \log_2 p(y | x) \right] \\ &= - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(y | x) \end{aligned} H(Y∣X)=x∈X∑p(x)H(Y∣X=x)=x∈X∑p(x)⎣⎡−y∈Y∑p(y∣x)log2p(y∣x)⎦⎤=−x∈X∑y∈Y∑p(x,y)log2p(y∣x)
- 将联合熵中的 log 2 p ( x , y ) \log_2 p(x, y) log2p(x,y)展开,有:
H ( X , Y ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( x , y ) = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 [ p ( x ) p ( y ∣ x ) ] = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) [ log 2 p ( x ) + log 2 p ( y ∣ x ) ] = − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( x ) − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( y ∣ x ) = − ∑ x ∈ X p ( x ) log 2 p ( x ) − ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( y ∣ x ) = H ( X ) + H ( Y ∣ X ) \begin{aligned} H(X, Y) &= - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(x, y) \\ &= - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 \left[p(x) p(y | x) \right] \\ &= - \sum_{x \in X} \sum_{y \in Y} p(x, y) \left[\log_2 p(x) + \log_2 p(y | x) \right] \\ &= - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(x) - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(y | x) \\ &= - \sum_{x \in X} p(x) \log_2 p(x) - \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(y | x) \\ &= H(X) + H(Y|X) \end{aligned} H(X,Y)=−x∈X∑y∈Y∑p(x,y)log2p(x,y)=−x∈X∑y∈Y∑p(x,y)log2[p(x)p(y∣x)]=−x∈X∑y∈Y∑p(x,y)[log2p(x)+log2p(y∣x)]=−x∈X∑y∈Y∑p(x,y)log2p(x)−x∈X∑y∈Y∑p(x,y)log2p(y∣x)=−x∈X∑p(x)log2p(x)−x∈X∑y∈Y∑p(x,y)log2p(y∣x)=H(X)+H(Y∣X)
- 第四行到第五行,实际上完成了对 p ( x , y ) p(x,y) p(x,y)中 y y y的边缘积分
- 连锁规则:联合熵为单个的熵和另外一个基于其的条件熵
- p ( x 1 ∣ y 1 ) = p ( x 1 , y 1 ) p ( y 1 ) p(x_1 | y_1) = \frac {p(x_1, y_1)}{p(y_1)} p(x1∣y1)=p(y1)p(x1,y1)
- 注意: H ( Y ∣ X ) ≠ H ( X ∣ Y ) H(Y | X) \neq H(X | Y) H(Y∣X)=H(X∣Y)
熵率(Entropy Rate)
- 对于一条长度为 n n n的信息,每一个字符或字的熵为:
H r a t e = 1 n H ( X 1 n ) = − 1 n ∑ 1 n p ( x 1 n ) log p ( x 1 n ) H_{rate} = \frac 1n H(X_{1n}) = - \frac 1n \sum_{1n} p(x_{1n}) \log p(x_{1n}) Hrate=n1H(X1n)=−n11n∑p(x1n)logp(x1n)
- 其中, X 1 n X_{1n} X1n表示随机变量序列 ( X 1 , … , X n ) (X_1, \ldots, X_n) (X1,…,Xn), x 1 n = ( x 1 , … , x n ) x_{1n} = (x_1, \ldots, x_n) x1n=(x1,…,xn)表示具体取值,有时亦写作 x 1 n x_1^n x1n
相对熵(Relative Entropy)
- 又称K-L散度
- 两个概率分布 p ( x ) p(x) p(x)和 q ( x ) q(x) q(x)的相对熵定义为:
D ( p ∥ q ) = ∑ x ∈ X p ( x ) log p ( x ) q ( x ) D(p \| q) = \sum_{x \in X} p(x) \log \frac{p(x)}{q(x)} D(p∥q)=x∈X∑p(x)logq(x)p(x)
- 约定, 0 log ( 0 / q ) = 0 0 \log (0 / q) = 0 0log(0/q)=0, p log ( p / 0 ) = ∞ p \log (p / 0) = \infty plog(p/0)=∞
- 常被用于衡量两个随机分布的差距,二者一样时,相对熵为0
交叉熵(Cross Entropy)
- 有一个随机变量 X ∼ p ( x ) X \sim p(x) X∼p(x), q ( x ) q(x) q(x)为用于近似 p ( x ) p(x) p(x)的概率分布,那么随机变量 X X X和模型 q q q之间的交叉熵定义为:
H ( X , q ) = H ( X ) + D ( p ∥ q ) = − ∑ x p ( x ) log q ( x ) H(X, q) = H(X) + D(p \| q) = -\sum_x p(x) \log q(x) H(X,q)=H(X)+D(p∥q)=−x∑p(x)logq(x)
- 用于衡量估计模型与真实概率之间的差异
- 对语言 L = ( X ) ∼ p ( x ) \mathcal L = (\bold X) \sim p(\bold x) L=(X)∼p(x),与其模型 q q q的交叉熵定义为:
H ( L , q ) = − lim n → ∞ 1 n ∑ x 1 n p ( x 1 n ) log q ( x 1 n ) H(\mathcal L, q) = - \lim_{n \to \infty} \frac 1n \sum_{x_1^n} p(x_1^n) \log q(x_1^n) H(L,q)=−n→∞limn1x1n∑p(x1n)logq(x1n)
- 对于语言来讲,不可能得到精确的概率分布,因此需要尽可能地取估算(理论值)
- 定理:假定语言 L \mathcal L L是稳态遍历性随机过程, x 1 n x_1^n x1n为 L \mathcal L L的样本,那么有:
H ( L , q ) = − lim n → ∞ 1 n log q ( x 1 n ) H(\mathcal L, q) = -\lim_{n \to \infty} \frac 1n \log q(x_1^n) H(L,q)=−n→∞limn1logq(x1n)
- 可以根据模型 q q q和一个含有大量数据的 L \mathcal L L的样本计算交叉熵
- 设计模型 q q q是,使交叉熵最小,从而接近真实分布 p ( x ) p(x) p(x)
困惑度(Perplexity)
- 设计语言模型时,常使用困惑都代替交叉熵衡量语言模型的好坏
- 避免交叉熵小数在计算时的下溢出的问题,尽量将其放大
- 对语言 L \mathcal L L的样本 l 1 n l_1^n l1n, L \mathcal L L的困惑度 P P q PP_q PPq的定义为:
PP q = 2 H ( L , q ) ≈ 2 − 1 n log q ( l 1 n ) = [ q ( l 1 n ) ] − 1 n \operatorname{PP}_q = 2^{H(\mathcal L, q)} \approx 2^{-\frac 1n \log q(l_1^n)} = \left[ q(l_1^n) \right]^{-\frac 1n} PPq=2H(L,q)≈2−n1logq(l1n)=[q(l1n)]−n1
- 语言模型设计的任务目标就是寻找困惑度最小的模型,使其接近真实的语言
互信息(Mutual Information)
- 如果有 ( X , Y ) ∼ p ( x , y ) (X, Y) \sim p(x, y) (X,Y)∼p(x,y), X X X和 Y Y Y之间的互信息 I ( X ; Y ) I(X;Y) I(X;Y)定义为:
I ( X ; Y ) = H ( X ) − H ( X ∣ Y ) = − ∑ x ∈ X p ( x ) log 2 p ( x ) + ∑ x ∈ X ∑ y ∈ Y p ( x , y ) log 2 p ( x ∣ y ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) ( log 2 p ( x ∣ y ) − log 2 p ( x ) ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) ( log 2 P ( x ∣ y ) p ( x ) ) = ∑ x ∈ X ∑ y ∈ Y p ( x , y ) ( log 2 P ( x , y ) p ( x ) p ( y ) ) \begin{aligned} I(X; Y) &= H(X) - H(X|Y) \\ &= -\sum_{x \in X} p(x) \log_2 p(x) + \sum_{x \in X} \sum_{y \in Y} p(x, y) \log_2 p(x | y) \\ &= \sum_{x \in X} \sum_{y \in Y} p(x, y) \left( \log_2 p(x | y) - \log_2 p(x) \right) \\ &= \sum_{x \in X} \sum_{y \in Y} p(x, y) \left( \log_2 \frac {P(x | y)}{p(x)} \right) \\ &= \sum_{x \in X} \sum_{y \in Y} p(x, y) \left( \log_2 \frac {P(x , y)}{p(x) p(y)} \right) \end{aligned} I(X;Y)=H(X)−H(X∣Y)=−x∈X∑p(x)log2p(x)+x∈X∑y∈Y∑p(x,y)log2p(x∣y)=x∈X∑y∈Y∑p(x,y)(log2p(x∣y)−log2p(x))=x∈X∑y∈Y∑p(x,y)(log2p(x)P(x∣y))=x∈X∑y∈Y∑p(x,y)(log2p(x)p(y)P(x,y))
- 互信息反映了知道 Y Y Y的值以后, X X X的不确定性的减少量,即 Y Y Y透露了多少关于 X X X的信息量
- 对 X X X和 Y Y Y在意义上是对称的
- 由于 H ( X ∣ X ) = 0 H(X | X) = 0 H(X∣X)=0,则有:
H ( X ) = H ( X ) − H ( X ∣ X ) = I ( X ; X ) H(X) = H(X) - H(X | X) = I(X; X) H(X)=H(X)−H(X∣X)=I(X;X)
- 上式反映了熵为什么又成为自信息
- 两个相互依赖的变量之间的互信息并不是常量,而是取决于它们的熵
- 汉语分词任务:
- 互信息值越大,两个字之间结合越紧密,越可能成词
- 两个汉字关联度强时,互信息 I ( X ; Y ) > 0 I(X; Y) \gt 0 I(X;Y)>0;二者关联度较弱,则 I ( X ; Y ) ≈ 0 I(X; Y) \approx 0 I(X;Y)≈0;当 I ( X ; Y ) < 0 I(X; Y) \lt 0 I(X;Y)<0时,二者成为“互补分布”
- 也可以用耦合度代替互信息:对汉字 c i c_i ci和 c i + 1 c_{i + 1} ci+1,统计连续出现在一个词中的次数和连续出现(同一个词,或者分别为两个连续词的结尾和开头)的总次数,二者之比为双字耦合度:
- 存在一类词,很少连续出现,一旦连续出现必然是一个词,这种情形下,互信息就很小(因为很少一起出现),但是耦合度就能很好的反应两个字的关系
Couple ( c i , c i = 1 ) = N ( c i c i + 1 ) N ( c i , c i + 1 ) + N ( … c i / / c i + 1 … ) \operatorname{Couple}(c_i, c_{i = 1}) = \frac{N(c_ic_{i+1})}{N(c_i,c_{i+1}) + N(\ldots c_i // c_{i+1} \ldots)} Couple(ci,ci=1)=N(ci,ci+1)+N(…ci//ci+1…)N(cici+1)
- 说明:两个单个离散事件 ( x i , y i ) (x_i, y_i) (xi,yi)之间的互信息 I ( x i , y i ) I(x_i, y_i) I(xi,yi)称为点式互信息,其可能为负值(从公式计算出发);两个随机变量 ( X , Y ) (X, Y) (X,Y)之间的互信息 I ( X , Y ) I(X, Y) I(X,Y)成为平均互信息,其不可能为负值(从定义出发)
噪声信道模型(Noisy Channel Model)
- 双重性处理:
- 压缩以消除冗余(空间占用)
- 增加可控冗余,保持经过噪声信道后,信息的可恢复性(错误校验)
- 模型的目标就是优化噪声信道中信号传输的吞吐量和准确率
- 基本假设:一个信道的输出以一定概率依赖于输入
- W W W -》编码器 -》 X X X -》噪声信道 p ( y ∣ x ) p(y | x) p(y∣x) -》 Y Y Y -》解码器 -》 W ^ \widehat W W
- 翻译过程中,大脑完成编码,翻译过程即通过信道,探究通过的过程,通过解码来推测输入
- 二进制对称信道:
- 输入符号集 X : { 0 , 1 } X:\{0, 1\} X:{0,1}
- 输出符号集 Y : { 0 , 1 } Y:\{0, 1\} Y:{0,1}
- 误传概率为 p p p,那么正确传输的概率为 1 − p 1 - p 1−p
信道容量(Capacity)
- 用降低传输速率来换取高保真通讯的可能性
- 定义可由互信息给出( p ( x ) p(x) p(x)为信号的概率分布):
C = max p ( X ) I ( X ; Y ) C = \max_{p(X)} I(X; Y) C=p(X)maxI(X;Y)
- 语言处理中,不需要编码,只需要进行解码,使系统的输出更接近于输入(如机器翻译)
应用举例
词汇歧义消解
问题提出
- 一种自然语言中,一词多义现象普遍存在
- 如何区分不同上下文中的词汇语义,即歧义消解问题,又称词义消歧(word sense disambiguation)
- NLP中的基本问题之一
基本思路
- 根据上下问区分词义
- 基本上下文的信息:词、词性、词的位置
实现方法
- 贝叶斯分类器
- 分类方法
- 假设某个多义词 w w w所处上下文环境为 C C C,针对其多个语义 s i s_i si,通过计算 arg max s i P ( s i ∣ C ) \arg \max_{s_i} P(s_i | C) argmaxsiP(si∣C)来确定词义
- 贝叶斯公式 p ( s i ∣ C ) = p ( s i ) p ( C ∣ s i ) p ( C ) p(s_i | C) = \frac{p(s_i) p(C | s_i)}{p(C)} p(si∣C)=p(C)p(si)p(C∣si)
- 独立性假设 p ( C ∣ s i ) = ∏ v k ∈ C p ( v k ∣ s i ) p(C | s_i) = \prod_{v_k \in C} p(v_k | s_i) p(C∣si)=∏vk∈Cp(vk∣si)
- 得到 s i ^ = arg max s i [ p ( s i ) ∏ v k ∈ C p ( v k ∣ s i ) ] \widehat{s_i} = \arg \max_{s_i} \left[ p(s_i) \prod_{v_k \in C} p(v_k | s_i) \right] si =argmaxsi[p(si)∏vk∈Cp(vk∣si)]
- 使用最大似然估计式中的概率项
- p ( v k ∣ s i ) = N ( v k , s i ) N ( s i ) p(v_k | s_i) = \frac{N(v_k, s_i)}{N(s_i)} p(vk∣si)=N(si)N(vk,si)
- p ( s i ) = N ( s i ) N ( w ) p(s_i) = \frac{N(s_i)}{N(w)} p(si)=N(w)N(si)
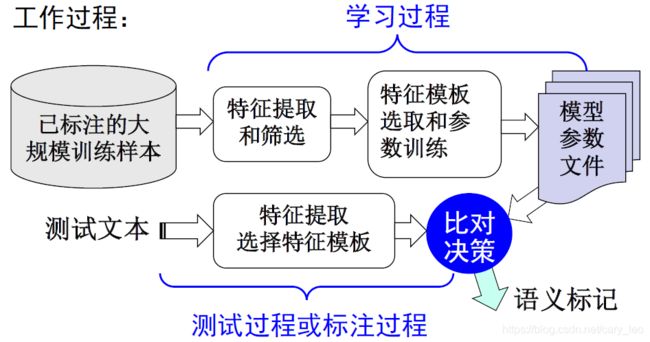
- 测试过程也称为标注过程
- 实际采用对数加法运算
- 基于最大熵的方法
- 分类方法
- 使熵值最大的概率分布能够最真实地反应事件的分布情况
- 在已知部分知识的前提下,关于位置分布最合理的推断应该是符合已知知识最不确定的推断
- 估计在条件 b ∈ B b \in B b∈B下,发生某事件 a ∈ A a \in A a∈A(分布未知)的概率 p ( a ∣ b ) p(a | b) p(a∣b),使熵 H ( p ( A ∣ B ) ) H(p (A | B)) H(p(A∣B))最大
- p ∗ ( a ∣ b ) = 1 Z ( b ) exp ( ∑ j = 1 l λ j f j ( a , b ) ) p^\ast (a | b) = \frac {1}{Z(b)} \exp(\sum_{j = 1}^l \lambda_j f_j(a, b)) p∗(a∣b)=Z(b)1exp(∑j=1lλjfj(a,b))
- 上式为近似估算,特征函数 f f f的取值为0或者1,表示特征分布存在或不存在, λ \lambda λ为特征权重, Z ( b ) Z(b) Z(b)为归一化因子(对 a a a归一化): Z ( b ) = ∑ a exp ( ∑ j = 1 l λ j f j ( a , b ) ) Z(b) = \sum_a \exp(\sum_{j = 1}^l \lambda_j f_j(a, b)) Z(b)=∑aexp(∑j=1lλjfj(a,b))
- A A A为所有义项的集合, B B B为所有上下文的集合,定义特征函数取值为0或者1,存在关系 ( a , b ) (a,b) (a,b)时为1
- 上下文信息
- 词形(词本身)
- 词性
- 词形+词性
- 上下文表示方法
- 位置无关,词袋模型
- 位置有关,模板表示
- 特征信息
- 上下文
- 窗口
- 位置
- 特征选择
- 出现频率超过阈值
- 满足互信息要求
- 增量式特征选择方法
- 最终选定的 k k k个特征对应 k k k个特征函数
- λ \lambda λ参数的获取
- GIS算法
- 对每个任意 ( a , b ) ∈ A × B (a,b) \in A \times B (a,b)∈A×B,有 ∑ j = 1 k f j ( a , b ) = C \sum_{j = 1}^k f_j(a, b) = C ∑j=1kfj(a,b)=C(特征空间固定)
- 若不满足,则取 C = m a x a ∈ A , b ∈ B ∑ j = 1 k f j ( a , b ) C = max_{a \in A, b \in B} \sum_{j = 1}^k f_j(a, b) C=maxa∈A,b∈B∑j=1kfj(a,b),并增加一个修正特征 f l ( a , b ) = C − ∑ j = 1 k f j ( a , b ) f_l(a, b) = C - \sum_{j = 1}^k f_j(a, b) fl(a,b)=C−∑j=1kfj(a,b)
- 具体算法查阅PPT-71,72,73
工作过程