ebpf之bcc程序入门
原理
参考:高效入门eBPF_哔哩哔哩_bilibili
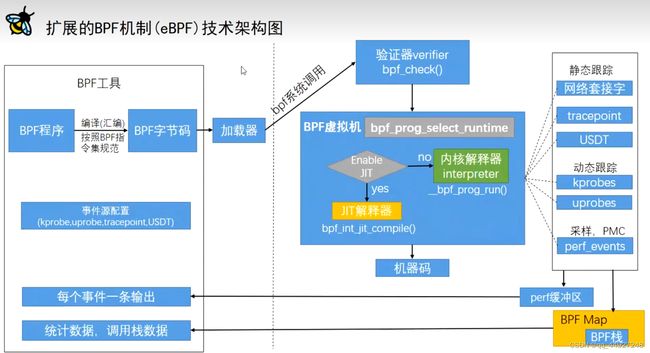
环境安装
参考:https://github.com/iovisor/bcc/blob/master/INSTALL.md#ubuntu—source
前置工具
To build the toolchain from source, one needs:
•LLVM 3.7.1 or newer, compiled with BPF support (default=on)
•Clang, built from the same tree as LLVM
•cmake (>=3.1), gcc (>=4.7), flex, bison
•LuaJIT, if you want Lua support
安装构建依赖关系
# Trusty (14.04 LTS) and older
VER=trusty
echo "deb http://llvm.org/apt/$VER/ llvm-toolchain-$VER-3.7 main
deb-src http://llvm.org/apt/$VER/ llvm-toolchain-$VER-3.7 main" | \
sudo tee /etc/apt/sources.list.d/llvm.list
wget -O - http://llvm.org/apt/llvm-snapshot.gpg.key | sudo apt-key add -
sudo apt-get update
# For Bionic (18.04 LTS)
sudo apt-get -y install bison build-essential cmake flex git libedit-dev \
libllvm6.0 llvm-6.0-dev libclang-6.0-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
# For Focal (20.04.1 LTS)
sudo apt install -y bison build-essential cmake flex git libedit-dev \
libllvm12 llvm-12-dev libclang-12-dev python zlib1g-dev libelf-dev libfl-dev python3-distutils
# For Hirsute (21.04) or Impish (21.10)
sudo apt install -y bison build-essential cmake flex git libedit-dev \
libllvm11 llvm-11-dev libclang-11-dev python3 zlib1g-dev libelf-dev libfl-dev python3-distutils
# For Jammy (22.04)
sudo apt install -y bison build-essential cmake flex git libedit-dev \
libllvm14 llvm-14-dev libclang-14-dev python3 zlib1g-dev libelf-dev libfl-dev python3-distutils
# For other versions
sudo apt-get -y install bison build-essential cmake flex git libedit-dev \
libllvm3.7 llvm-3.7-dev libclang-3.7-dev python zlib1g-dev libelf-dev python3-distutils
# For Lua support
sudo apt-get -y install luajit luajit-5.1-dev
安装和编译BCC
git clone https://github.com/iovisor/bcc.git
mkdir bcc/build; cd bcc/build
cmake ..
make
sudo make install
cmake -DPYTHON_CMD=python3 .. # build python3 binding
pushd src/python/
make
sudo make install
popd
以上是官方提供的安装教程,但在由于官网的安装地址有一些问题,不能直接在apt官方库安装,因为有一些名字上的不同,并且有一些tools和文件没有下载下来,不能够完全使用
所以推荐使用源码安装,下载bcc-src-with-submodule.tar.gz。
目前安装bcc有两种方式,一种是直接使用发行版提供的软件包,Ubuntu里叫bpfcc-tools,CentOS7中的是bcc-tools。另一种方式是源码编译安装。推荐通过源码编译安装。第一种和第二种方式只能二选一,否则会有冲突导致不可用,目前通过源码编译安装是最稳定最安全的方法。
具体安装可以参考BCC在ubuntu18.04源码安装
示例代码
在一个bcc程序中其实是有两个程序的,一个内核态程序用于对内核态数据的采集,一个用户态程序对采集到的数据进行处理。虽然在编写时可能是在一个程序里,但在实际运行中两个程序是分开运行的,这是我在学习过程中有过迷惑的点。
内核态程序可以使用bpf_trace_printk()函数直接将运行结果打印到trace_pipe,也可以使用BPF_PERF_OUTPUT将定义的事件数据输出,这个是将数据推送到用户态的建议方法。
在传输高级复杂的数据结构时可以使用MAP,通过MAP可以很方便的对传输的数据进行增删改查等操作。一般来说我们是通过BPF_MAP将数据传输到用户态程序中,然后通过用户态程序对数据进行处理和打印。
在获取内核结构体中的值的时候pt_regs是很重要的结构体,通过这个结构体我们可以很方便的获得传入要采集的函数的数据。
数据打印
helloworld.py
from bcc import BPF
BPF(text='
int kprobe__finish_task_switch(void *ctx) {
bpf_trace_printk("Hello, World!\\n"); //printf() 到 trace_pipe
return 0;
}
').trace_print()//一个 bcc 实例会通过这个读取 trace_pipe 并打印
1.kprobe__finish_task_switch() 这是一个通过内核探针(kprobe)进行内核动态跟踪的快捷方式。如果一个 C 函数名开头为 kprobe__ ,则后面的部分实际为设备的内核函数名,这里是 finish_task_switch() 。
2.bpf_trace_printk():一个用于printf()到公共trace_pipe(/sys/kernel/debug/tracing/trace_pipe)的简单内核设施。对于一些快速示例来说,这是可以的,但有局限性:最多三个参数,只能有一个字符串,以及trace_pipe是全局共享的,因此并发程序将有冲突的输出。更好的接口是通过BPF_PERF_OUTPUT()。
通过
python3 helloworld.py
运行程序,如出现权限问题则切换到管理员再使用上边的命令再运行程序。
下图为trace_pipe中的内容
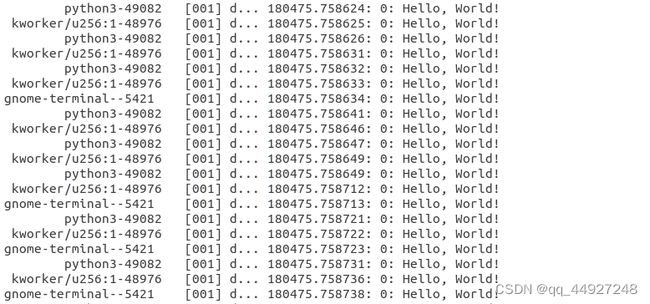
运行结果

hello_fields.py
from bcc import BPF
# define BPF program
prog = """
int hello(void *ctx) {
bpf_trace_printk("Hello, World2!\\n");
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# b.attach_kprobe(event="sys_clone", fn_name="hello")
# b.attach_kprobe(event_re="^finish_task_switch$|^finish_task_switch\.isra\.\d$",fn_name="count_sched")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# format output
while 1:
try:
(task, pid, cpu, flags, ts, msg) = b.trace_fields()
except ValueError:
continue
print("%-18.9f %-16s %-6d %s" % (ts, task, pid, msg))
1.b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello") 这里建立了一个内核探针,以便内核系统出现 clone 操作时执行 hello() 这个函数。你可以多次调用 attch_kprobe() ,这样就可以用你的 C 语言函数跟踪多个内核函数。
2.b.attach_kprobe(event="sys_clone", fn_name="hello"):同样是在内核出现 clone 操作时执行hello()函数,但没有使用get_syscall_fnname()函数,直接将event="sys_clone",在不同版本中同一函数可能会有不同的名字,所以使用这种方法会使程序通用性更小,但在同一版本的内核开发时,这种方法可能会更方便而且灵活性更强。
3.b.attach_kprobe(event_re="^finish_task_switch$|^finish_task_switch\.isra\.\d$",fn_name="count_sched"):这是在bcc示例代码task_switch.c中的挂载语句,在event的赋值中使用了正则表达式来使它能够适配不同的内核。
4.get_syscall_fnname("clone"):返回syscall对应的内核函数名,此助手函数将尝试不同的前缀,并使用正确的前缀与syscall名称连接。
5.b.trace_fields() 这里从 trace_pipe 返回一个混合数据
运行结果

hello_perf_output.py
from bcc import BPF
# define BPF program
prog = """
#include
// define output data structure in C
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
};
BPF_PERF_OUTPUT(result);
int hello(struct pt_regs *ctx) {
struct data_t data = {};
data.pid = bpf_get_current_pid_tgid();
data.ts = bpf_ktime_get_ns();
bpf_get_current_comm(&data.comm, sizeof(data.comm));
result.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
# load BPF program
b = BPF(text=prog)
b.attach_kprobe(event=b.get_syscall_fnname("clone"), fn_name="hello")
# header
print("%-18s %-16s %-6s %s" % ("TIME(s)", "COMM", "PID", "MESSAGE"))
# process event
start = 0
def print_event(cpu, data, size):
global start
event = b["result"].event(data)
if start == 0:
start = event.ts
time_s = (float(event.ts - start)) / 1000000000
print("%-18.9f %-16s %-6d %s" % (time_s, event.comm, event.pid,
"Hello, perf_output!"))
# loop with callback to print_event
b["result"].open_perf_buffer(print_event)
while 1:
b.perf_buffer_poll()
struct data_t一个简单的 C 语言结构体,用于从内核态向用户态传输数据。BPF_PERF_OUTPUT(result)表明内核传出的数据将会打印到 “result” 这个通道内(实际上这就是 bpf 对象的一个 key,可以通过bpf_object["result"]的方式读取。)struct data_t data = {};创建一个空的 data_t 结构体,之后在填充。bpf_get_current_pid_tgid()返回以下内容:位于低 32 位的进程 ID(内核态中的 PID,用户态中实际为线程 ID),位于高 32 位的线程组 ID(用户态中实际为 PID)。我们通常将结果通过 u32 取出,直接丢弃最高的 32 位。我们优先选择了 PID(← 指内核态的)而不是 TGID(← 内核态线程组 ID),是因为多线程应用程序的 TGID 是相通的,因此需要 PID 来区分他们。通常这也是我们代码的用户所关心的。bpf_get_current_comm(&data.comm, sizeof(data.comm));将当前参数名填充到指定位置。reault.perf_submit()通过 perf 缓冲区环将结果提交到用户态。def print_event()定义一个函数从result流中读取 event。(这里的 cpu, data, size 是默认的传入内容,连接到流上的函数必须要有这些参数)。b["events"].event(data)通过 Python 从result中获取 event。b["events"].open_perf_buffer(print_event)将print_event函数连接在result流上、while 1: b.perf_buffer_poll()阻塞的循环获取结果。
运行结果

数据传输(内核态到用户态)
MAP是将复杂数据结构从内核态传输到用户态的重要结构,较常使用的是BPF_HASH和BPF_ARRAY。
sync_timing.py
from __future__ import print_function
from bcc import BPF
# load BPF program
b = BPF(text="""
#include
BPF_HASH(last);
int do_trace(struct pt_regs *ctx) {
u64 ts, *tsp, delta, key = 0;
// attempt to read stored timestamp
tsp = last.lookup(&key);
if (tsp != 0) {
delta = bpf_ktime_get_ns() - *tsp;
if (delta < 1000000000) {
// output if time is less than 1 second
bpf_trace_printk("%d\\n", delta / 1000000);
}
last.delete(&key);
}
// update stored timestamp
ts = bpf_ktime_get_ns();
last.update(&key, &ts);
return 0;
}
""" )
b.attach_kprobe(event=b.get_syscall_fnname("sync"), fn_name="do_trace")
print("Tracing for quick sync's... Ctrl-C to end")
# format output
start = 0
while 1:
(task, pid, cpu, flags, ts, ms) = b.trace_fields()
if start == 0:
start = ts
ts = ts - start
print("At time %.2f s: multiple syncs detected, last %s ms ago" % (ts, ms))
bpf_ktime_get_ns()以纳秒为单位返回当前时间。BPF_HASH(last)创建一个名为 last 的 BPF hash 映射。我们使用了默认参数,所以它使用了默认的 u64 作为 key 和 value 的类型。(这里可以理解为一个储存数据用的全局变量,因为一些原因可能在 BPF 中只能使用 hash 映射这种形式作为全局变量,以便通信。)key = 0我们只储存一个键值对,每次存在 key 为 0 的位置即可。所以 key 固定为 0。last.lookup(&key)在 hash 映射中寻找一个 key 对应的 value。不存在会返回空。我们将 key 作为地址指针传入函数。last.delete(&key)顾名思义,移除一个键值对。last.update(&key, &ts)顾名思义,传入两个参数,覆盖更新原有的键值对。ts是时间戳。- 在用户态程序中使用
b["last"]来使用last哈希表,实际上在python的用户态程序中b[“last”]是一个hash字典,对b[“last”]的操作也和字典基本相同,如遍历该表可以使用b["last"].items(),清除该表可以使用b["last"].clear()。
运行结果
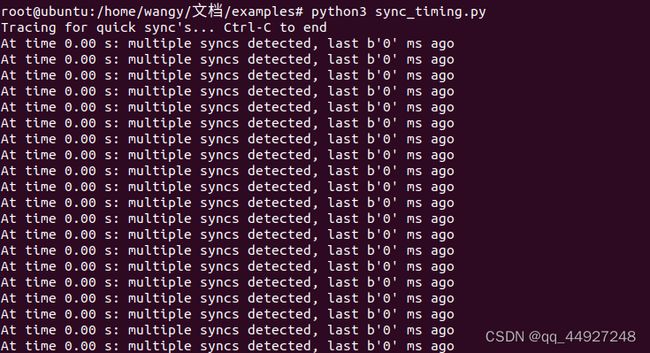
MAPS
maps是BPF数据的存储方式,是更高级对象类型的基础,包括table表、hashes哈希和histograms直方图。
1.BPF_TABLE
语法:BPF_TABLE(_table_type, _key_type, _leaf_type, _name, _max_entries)
创建一个映射名字为_name。大多数时候会被高层宏使用,例如BPF_HASH,BPF_HIST等。
还有map.lookup(), map.lookup_or_init(), map.delete(), map.update(), map.insert(), map.increment().
2.BPF_HASH
语法BPF_HASH(name [, key_type [, leaf_type [, size]]])
创建一个name哈希表,中括号中是可选参数。
默认:BPF_HASH(name, key_type=u64, leaf_type=u64, size=10240)
相关函数:map.lookup(), map.lookup_or_init(), map.delete(), map.update(), map.insert(), map.increment().
3.BPF_ARRAY
语法:BPF_ARRAY(name [, leaf_type [, size]])
创建一个整数索引整列,用于快速查询和更新。
默认参数如下:BPF_ARRAY(name, leaf_type=u64, size=10240)
相关函数:map.lookup(), map.update(), map.increment().
整列中数据是预分配的,不能删除,所有没有删除操作了。
4.BPF_HISTOGRAM
语法:BPF_HISTOGRAM(name [, key_type [, size ]])
创建一个直方图,默认是由64整型桶索引。
相关函数:map.increment().
5. BPF_STACK_TACK
语法:BPF_STACK_TRACE(name, max_entries)
创建一个栈跟踪映射,叫做stack_traces。相关函数:map.get_stackid().
6.BPF_PERF_ARRAY
语法:BPF_PERF_ARRAY(name, max_entries)
创建perf array,参数中max_entries保持和系统中CPU数量一致。这个映射用于获取硬件性能计数器.
例如:
text="""
BPF_PERF_ARRAY(cpu_cycles, NUM_CPUS);
"""
b = bcc.BPF(text=text, cflags=["-DNUM_CPUS=%d" % multiprocessing.cpu_count()])
b["cpu_cycles"].open_perf_event(b["cpu_cycles"].HW_CPU_CYCLES)
创建一个名字为cpu_cycles的perf array,入口和cpu数量一致。
Array配置计数器HW_CPU_CYCLES,后续可以通过map.perf_read函数读取到。每个表一次只能配置一种硬件计数器。
7.BPF_PERCPU_ARRAY
语法:BPF_PERCPU_ARRAY(name [, leaf_type [, size]])
创建NUM_CPU个整数索引数组,优化了快速查找和更新。每个CPU的数组相互之间不用同步。
8.BPF_LPM_TRIE
语法:BPF_LPM_TRIE(name [, key_type [, leaf_type [, size]]])
创建LPM trie映射。
9.BPF_PROG_ARRAY
语法:BPF_PROG_ARRAY(name, size)
创建映射程序的数组,每个值要么是一个文件描述符指向bpf程序要么是NULL.
这个数组可以作为跳转表,可以同跳转到其他的bpf程序。
相关函数:map.call()
10. Map.lookup
语法:*val map.lookup(&key)
寻找map中键为key的值,如果存在则返回指向该健值的指针。
11. Map.lookup_or_init
语法:*val map.lookup_or_init(&key, &zero)
在map中寻找键,找到返回健值的指针,找不到则初始化为第二个参数。
12. Map.delete
从map中删除某个健值。
13. Map.update
语法:map.update(&key, &val)
更新健值。
14. Map.insert
插入健值。
15. Map.increment
增加指定键的值,用于直方图。
16. Map.get_stackid
该函数从堆栈中寻找指定参数,返回栈跟踪的唯一ID。
17. Map.perf_read
从BPF_PERF_ARRAY中定义的数组返回硬件性能计数。
18. Map.call
语法:void map.call(void *ctx, int index)
调用bpf_tail_call来执行BPF_PROG_ARRAY数值中索引指向的程序,调用方式为tail-call表示不会返回到原先调用的函数。
数据采集
在内核数据采集时,pt_regs是很重要的一个结构体,bpf也为这个结构体定义了宏来完成对数据的采集。
以下的程序只是一个bcc程序中的内核态程序,主要功能为获得rq中nr_running和nr_uninterruptible的值。
get_myrq.c
#include 1.BPF_ARRAY(map_rq,struct rq,1):为struct rq分配一个存储空间。
2.BPF_HASH(my_rq,struct myrq,u64,1024):创建一个存储struct myrq结构的hash表,用来向用户态传递数据。
3.p_rq = (struct rq *)map_rq.lookup(&key);if (!p_rq) { return 0;}:将BPF_ARRAY中为rq分配的存储空间赋给p_rq,并对安全性进行检查。
4.bpf_probe_read_kernel(p_rq,sizeof(struct rq),(void *)PT_REGS_PARM1(ctx)):通过bpf_probe_read_kernel()函数读取挂载函数的传入参数,其中PT_REGS_PARM1(ctx)返回的是指向函数传入的第一个参数的指针,sizeof(struct rq)则说明从PT_REGS_PARM1(ctx)返回的指针开始将sizeof(struct rq)大小的地址复制给p_rq指向的地址。
5.my_rq.lookup_or_try_init(&mrq,&zero):在map中寻找键,找到返回健值的指针,找不到则初始化为第二个参数。
探针与其对应的数据获取方式:
| 事件 | C语法 | Python方式 | 参数获取 |
|---|---|---|---|
| kprobes | kprobe__ | BPF.attach_kprobe() | struct pt_regs *ctx |
| kretprobes | kretprobe__ | BPF.attach_kretprobe() | PT_REGS_RC |
| uprobes | BPF.attach_uprobe() | struct args | PT_REGS_PARM |
| uretprobes | BPF.attach_uretprobe() | PT_REGS_RC |
在使用kretprobes和uretprobes探针时,可以通过PT_REGS_RC(ctx)获取挂载函数的返回值。在使用kprobes和uprobes探针时,可以使用PT_REGS_PARM*宏来获取传入挂载函数的参数,不过区别在于使用uprobes探针时,程序本身名字使用宏PT_REGS_PARM1,第一个参数使用宏PT_REGS_PARM2;而在使用kprobes探针时,PT_REGS_PARM1指向程序的第一个参数。
关于pt_regs的详细内容可以参考:
ebpf中的bpf_probe_read_kernel和pt_regs_qq_44927248的博客-CSDN博客
linux 进程内核栈 - 知乎 (zhihu.com)
内核中的结构体
在内核态使用内核不允许访问的结构体时,需要自己对结构体进行定义,当只使用结构体较前的一部分时,可以只定义该结构体的前边要使用的部分,也只使用bpf_probe_read_kernel获取结构体的前部分内容,这点在lmp/map.c中也有提现。关于这一点,我个人感觉是与c语言中结构体内存分配有关。
在要使用全部的结构体时,则需要从源码中寻找对应的结构体定义,但在源码中可能会有定义的嵌套,这时我们可以使用(需要较高版本的bpftool)
bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
生成一个包含了系统运行 Linux 内核源代码中使用的所有类型定义的头文件vmlinux.h,但是这个文件不可以直接引用到内核态函数中,会报一个结构体重定义的错误,只是有了这个文件之后我们可以十分方便的从这个文件中查找和提取需要的结构体。(但是在go的ebpf环境下好像可以直接引用这个头文件)
总结
在我个人的学习过程中,认为对有一定c语言基础的人,在了解bcc程序的大体结构之后,了解内核态如何向用户态传递数据(BPF_ARRAY,BPF_HASH等和相应增删改查函数,用户态中如何读取数据b[“”].items()等函数),了解在挂载函数时如何选择相应的探针(kprobes、kretprobes、uprobes、uretprobes),了解如何从挂载的函数中获取数据(PT_REGS_PARM*、PT_REGS_RC、以及bpf中定义的有关函数,如bpf_get_current_pid_tgid()),就可以尝试自己编写bcc程序了。
以上内容部分摘抄自参考资料,内容有作修改;部分内容是我按照自己的理解写的,可能会有缺漏或错误,如有请指出,会在之后进行修改。
参考资料
ebpf & bcc 中文教程及手册 | Cyrus Blog (cyru1s.com)
bcc Reference Guide 中文翻译_JinrongLiang的博客-CSDN博客_bcc检查的方法
Linux source code (v5.4) - Bootlin
bcc: BCC 是一个开源的 Linux 动态跟踪工具 (gitee.com)
eBPF监控工具bcc系列八BPF C_badman250的博客-CSDN博客
BPF数据传递的桥梁——BPF Map(一)_米开朗基杨的博客-CSDN博客
聊聊对 BPF 程序至关重要的 vmlinux.h 文件 | 深入浅出 eBPF