汇编语言-王爽 笔记
目录
基础知识
寄存器
通用寄存器:AX、BX、CX、DX
物理地址
段寄存器(CS)与指针寄存器(IP)
修改CS、IP的指令
寄存器(内存地址)
内存中字的存储
DS和[address]
字的传送
mov、add、sub指令
栈
第一个程序
源程序的实现过程
源程序
伪指令
源程序中的”程序”
标号
程序的结构
程序返回
语法错误和逻辑错误
编辑源程序
编译
连接
程序执行过程
程序执行过程的跟踪
[BX]和loop指令
[BX]
loop指令
loop和[bx]的联合应用
包含多个段的程序
在代码段中使用数据
在代码段中使用栈
将数据、代码、栈放入不同的段
基础知识
汇编语言的产生是因为早期的程序员发现机器语言带来的麻烦,一长串的“01”代码实在是难于辨别和记忆,所以为了简化操作所以开发出了汇编语言。例如机器指令1000100111011000表示把寄存器BX的内容送到AX中,用汇编指令写出来就是mov ax,bx。但是计算机它只能看懂机器指令,也就是0和1,那么如何让计算机识别汇编指令呢?所以我们就需要一个翻译的程序我们叫做编译器,这样我们写出汇编指令由编译器翻译为机器指令再让计算机执行。
我们知道计算机的组成就是控制器、运算器、存储器、输入、输出这五个部分,我们首先要了解的就是存储器。
要学会汇编语言我们首先要知道汇编指令是如何被执行的,也就是说我们首先要知道CPU如何从内存中读入信息,以及如何向内存中写入信息。我们先了解存储器的存储单元。存储器被划分为若干个存储单元,每个存储单元从0开始编号,例如一个存储器有128个存储单元,那么编号从0~127,这些编号实际上就是我们所说的地址。通常一个存储单元可以存储一个Byte,即八个二进制位(bit)。
| 单位换算 | ||||
|---|---|---|---|---|
| 1TB=1024GB | 1GB=1024MB | 1MB=1024KB | 1KB=1024B | 1B=8bit |
我们知道一个操作的实现一般都有指令和数据两个部分,但是在内存或者磁盘上指令和数据并没有区别,都是二进制信息,例如
| 二进制信息 | 1000100111011000 |
| 指令 | mov ax,bx |
| 数据 | 89D8H |
(H代表16进制,下文不再重复)
因为指令和数据没有差别,所以CPU要想进行数据的读写,必须进行3类信息交互
- 存储单元的地址(地址信息)
- 器件的选择,读或写的命令(控制信息)
- 读或写的数据(数据信息)
这三种交互显然互不影响,所以我们有三个传输的道路也就是三条总线:地址总线、控制总线、数据总线。三种总线不在这里详细介绍,但是三个性质我们要知道:
- 地址总线的宽度决定了CPU的寻址能力
- 数据总线的宽度决定了CPU与其他其他器件进行数据传送的单次数据传送量
- 控制总线的宽度决定了CPU对系统中其他器件的控制能力
PC机中各类存储器的逻辑连接:
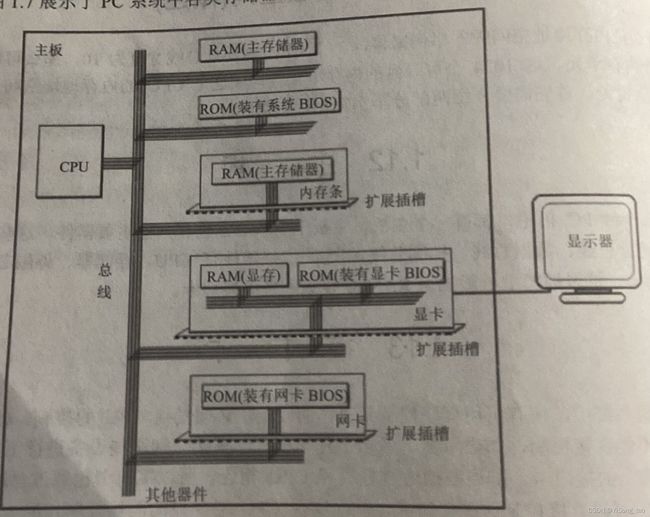
内存空间地址空间:
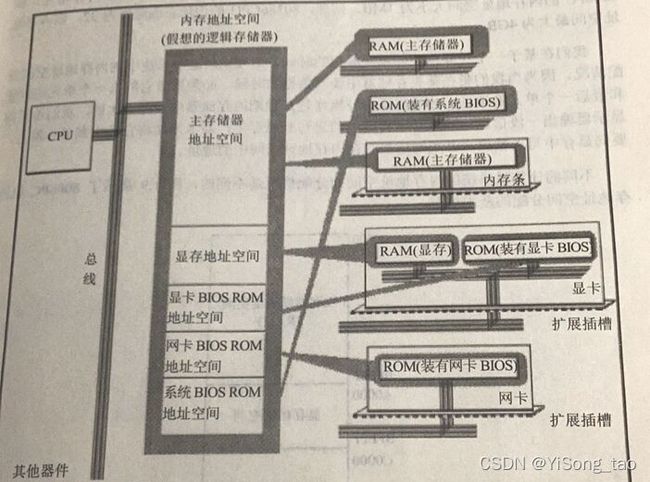
以上两张图为内存的逻辑结构,了解即可。
寄存器
CPU由运算器、控制器和寄存器等构成。对于学习汇编语言来说,寄存器是我们所关心的。我们可以通过改变各种寄存器的内容来实现对CPU的控制。8086CPU有14个寄存器:AX、BX、CX、DX、SI、DI、SP、BP、IP、CS、SS、DS、ES、PSW。8086CPU中的寄存器都是16位的,我们分类来看。
通用寄存器:AX、BX、CX、DX
通用寄存器的16位可以分为两个独立的8位寄存器来用,但是只有这四个通用寄存器可以分开使用。都可以分为高位和地位即AH、AL等。
8086CPU一次可以处理两种尺寸的数据字节型和字型,字节型就是1Byte,字型是2Byte,而一般的一条机器指令例如上面出现过的1000100111011000,这一条指令是16位,也就是16bit=2Byte即一个字型数据。
| 1000100111011000B | 16bit | 2Byte | 1字型 |
几条汇编指令:

注意:
- 当寄存器的值加上一个值后产生了进位,那么要舍弃最高位,例如mov ax,bx (ax=bx=8226H)那么此时ax=1044CH=044CH
- 当AH和AL单独使用时看作八位寄存器,也就是说当向第三位进位时要舍弃第三位,例如add al,93H (al=C5)那么此时al值为158H,但是我们将al看作独立的寄存器,所以此时ax为0058H
- 在进行数据传送或者运算时,要注意指令的两个操作对象的位数应当一致。
物理地址
CPU访问内存单元时需要给出内存单元的地址,不同的CPU可以有不同的形成物理地址的方式,我们这里介绍8086CPU如何在内部形成内存单元的物理地址。
8086CPU是16位结构,16位的结构有以下的特征:
- 运算器一次最多可以处理16位的数据
- 寄存器的最大宽度为16位
- 寄存器和运算器之间的通路为16位
也就是说在8086内部能够一次性处理、传输、暂时存储的信息的最大长度是16位。而8086CPU有20位地址总线,可以传送20位地址也就是 个地址即1MB的寻址能力。但是8086CPU是16位结构决定了它只能送出16位地址,所以我们用两个16位地址合成一个20位地址。我们这里给出一个公式:物理地址=段地址*16+偏移地址。具体操作过程如下图:
个地址即1MB的寻址能力。但是8086CPU是16位结构决定了它只能送出16位地址,所以我们用两个16位地址合成一个20位地址。我们这里给出一个公式:物理地址=段地址*16+偏移地址。具体操作过程如下图:
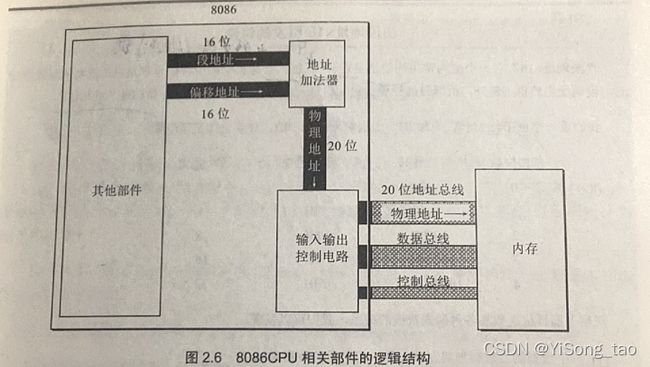
(详细了解关于物理地址的求法以及不同的段地址与偏移地址的组合方法可以看参考教材)
段寄存器(CS)与指针寄存器(IP)
8086寄存器中有四个段寄存器CS、DS、SS、ES,我们只看CS。
CS与IP:
CS与IP是8086最关键的两个寄存器,他们指示了CPU当前要读取指令的地址。假设CS中值为M,IP中的值为N,那么8086CPU从内存地址为M*16+N的存储单元开始读取指令并执行。即任意时刻,CPU将CS:IP指向的内容当作指令执行。
修改CS、IP的指令
因为8086CPU不支持mov指令直接设置CS、IP的值,而是用转移指令来改变CS、IP的值,最简单的转移指令是jmp指令。jmp 段地址:偏移地址功能为修改IP:CS。若只修改IP内容可以直接jmp 合法寄存器功能为修改IP为寄存器内容。
寄存器(内存地址)
首先解释一下什么是内存地址,之前我们学习过的寄存器主要侧重于CPU如何执行指令的角度来学习寄存器,这里我们从访问内存的角度学习寄存器。可以简单理解为上一章我们在学指令,这一章我们在学数据。
内存中字的存储
我们知道了一个字型数据需要占用两个字节的位置,所以我们就用两个内存单元来存放字型数据,我们将这两个连续的内存单元看作一个字单元。我们将起始地址为N的单元简称为N地址字单元。注意:如果两个连续的内存单元0和1分别是0(20H)1(4EH),那么0地址字单元的内容是(4E20H),以最低字节的地址作为数据地址。
DS和[address]
CPU要读或写一个内存单元时,首先要知道这个内存单元的地址,在8086CPU中,地址都是由段地址加偏移地址组成,对于内存,8086CPU有一个DS寄存器来存放要访问数据的段地址。如果我们要读取10000H单元的内容,就必须:
mov bx,1000H
mov ds,bs
mov al,[0]这是因为8086CPU不支持数据直接送入段寄存器,所以必须借助通用寄存器来实现对段寄存器的修改,在实现的时候直接这么输入指令是不行的,需要先使用-a命令,然后再修改cs:ip来实现几行代码的运行。
字的传送
8086CPU是十六位结构,那么依次传送就可以传送16位,也就是一个字型数据,只要在操作中给出16位的寄存器就可以进行16为数据的传送。我们执行指令mov ax,[0]时,就将0和1组成的字单元的数据传送到ax中。
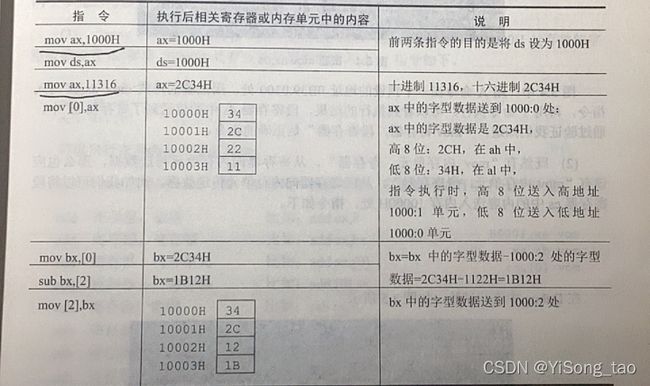
mov、add、sub指令
这三个指令的使用格式是一样的,所以我们只看mov指令就可以。
- mov 段寄存器,寄存器
- mov 内存单元,寄存器
- mov 段寄存器,内存单元
这三种格式都是合法的,我们可以在实验中去验证这些指令,add和sub指令和mov是一样的。这里就不再重复了。
栈
我们学过数据结构就知道什么是栈,就是我们说的“先进后出”,也叫“FILO”结构,那么在8086CPU中也提供了栈机制。也就是在基于8086CPU编程的时候可以将一段内存当作栈来访问。最基本的两个栈的指令就是PUSH(入栈)和POP(出栈)。这两个操作都是以字为单位进行的。给出书上的示意图:
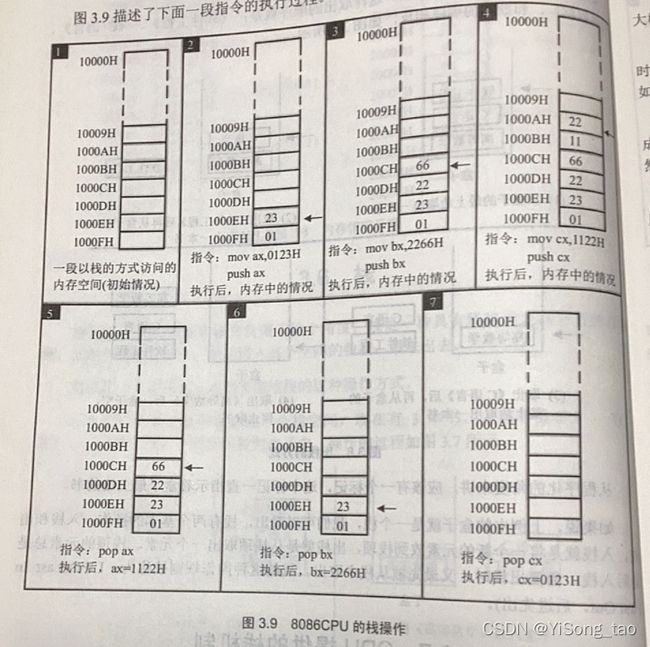
8086CPU中的两个寄存器SS和SP是指向栈顶元素的,其中SS是段寄存器,SP是指针寄存器,任意时刻,SS:SP指向栈顶元素。 PUSH和POP指令执行的时候都是从SS:SP处得到栈顶的地址。注意:8086CPU中一个十分重要的问题是CPU本身并没有考虑栈溢出问题,也就是说我们在编程或者使用的时候必须自己注意栈溢出问题!
push 寄存器(通用寄存器/段寄存器/内存单元)的执行:
- SP-=2,SS:SP指向当前栈顶前面的单元,以当前栈顶前面的单元为新的栈顶;
- 将ax中的内容送入SS:SP指向的内存单元处,此时SS:SP指向新的栈顶。

pop 寄存器(寄存器/段寄存器/内存单元)的执行:
- 将SS:SP指向的内存单元处的数据送入ax;
- SP+=2, SS:SP指向当前栈顶下面的单元,以当前栈顶下面的单元为新栈顶。

注意:pop指令只是将栈顶移动,并没有实际地删除内存中的数据,只是在下一次入栈操作时覆盖掉相关的内存单元。
第一个程序
我们将在这一章编写一个完整的汇编语言程序,用编译和连接程序将它们编译连接成为可执行文件如.exe文件,然后在操作系统上运行。
源程序的实现过程
- 编写汇编源程序:使用文本编辑器(如edit,记事本等),用汇编语言编写汇编源程序。
- 对源程序进行编译连接:使用汇编语言编译程序对源程序文件中的源程序进行编译,产生目标文件;再用连接程序对目标文件进行连接,生成可在操作系统中直接运行的可执行文件。可执行文件一般分为两部分:程序+相关的信息描述(程序多大,占用多少内存等等)
- 执行可执行文件中的程序:操作系统依照可执行文件中的信息描述,将可执行文件中的机器码和数据家载入内存,并进行相关的初始化,例如设置CS:IP指向第一条要执行的指令,然后有CPU执行程序。
源程序
我们给出一个简单的汇编语言源程序:
assume cs:codesg
codesg segment
mov ax,0123H
mov bx,0456H
add ax,bx
add ax,ax
mov ax,4c00H
int 21H
codesg ends
end在汇编语言源程序中,包含两种指令,一种是汇编指令,一种是伪指令。
汇编指令:有对应的机器码,可以被执行的指令,最终被CPU执行。
伪指令:由编译器来执行的指令,编译器根据伪指令来进行相关的编译工作。
伪指令
汇编指令我们已经了解过,接下来我们主要看一下伪指令,在上面的代码中出现了三个伪指令:
- XXX segment···XXX ends:这是一对成对使用的伪指令,这一对伪指令的功能是定义一个段,并用XXX来标识。一个汇编程序是由多个段组成的, 这些段会存放指令、数据、栈。
- end:end是一个汇编程序的结束标记,编译器只要遇到end,就结束对源程序的编译。
- assume 段寄存器:段的标识:这条伪指令的含义为”假设“,假设某一段寄存器和程序中的某一个用segment···ends定义的段相关联。这样在需要的时候编译程序可以将段寄存器和某一个具体的段关联起来,后面用到的时候再详细介绍。
源程序中的”程序”
源程序中有汇编指令和伪指令,而其中的汇编指令也就是可以被计算机执行、处理的指令或数据叫做“程序”,程序最先以汇编指令的形式存在于源程序中,经过编译连接后转变为机器码,存储在可执行文件中。
标号
汇编程序中除了汇编指令和伪指令外,还有一些标号就像我们上面代码中的“codesg”,这个段的名称最后编译连接处理为一个段的段地址。
程序的结构
如果在编写大程序的时候就需要考虑程序的结构,例如我们编写一个程序运算2^3。
- 我们定义一个段,名称为abc。
abc segment abc ends - 在这个段中写入汇编指令,实现我们的任务。
abc segment mov ax,2 add ax,ax add ax,ax adc ends - 然后,要指出程序在何处结束。
abc segment mov ax,2 add ax,ax add ax,ax adc ends end - abc被当做代码段来用,所以应该将abc和cs联系起来。
assume cs:abc abc segment mov ax,2 add ax,ax add ax,ax adc ends end
程序返回
得到程序的运行呢?我们知道在运行一个程序后,应该将CPU的控制权交还给上一个运行的程序,我们称这一过程为程序返回,我们应该在程序的末尾添加返回的程序段。也就是我们上面程序中的:
mov ax,4v00H
int 21H和end、XXX ends不同的是,mov ax,4v00H int 21H是由CPU执行的,前两个都是由编译器执行的。
语法错误和逻辑错误
如果没有最后两行的程序返回,那么这个程序在运行的时候肯定会引发一些问题,但是这个错误在编译时是不会表现出来的,它对编译器来说是正确的程序。
一般来说,被编译器发现的错误是语法错误,在源程序编译后,运行时发生的错误是逻辑错误。
编辑源程序
汇编语言的源程序最终将其存储为纯文本文件就可以了。比如在DOS中运行Edit,编辑程序后保存为.asm格式就可以了。
编译
我们编辑好源程序后,得到的是一个.asm文件,我们对这个文件进行编译就可以生成包含机器代码的目标文件。在编译源程序时需要有一个编译器,在这本教材中我们使用微软的masm5.0汇编编译器。我们只需要进入masm文件后,指定需要编译的源程序文件名称就可以进行编译了。编译后的文件输出为.obj格式
连接
在得到编译后的目标文件后,我们需要对目标文件进行连接,得到可执行文件。 连接需要使用微软的连接器Overlay linlker3.60。将obj文件输出为exe文件即可得到我们需要的可执行文件。
程序执行过程
程序从开始到结束的流程如下:
| 编程 | 1.asm | 编译 | 1.obj | 连接 | 1.exe | 加载 | 内存中的程序 | 运行 |
| Edit | masm | link | command | CPU |
这就是一个一个程序从编程到运行的全过程,其中command是DOS中的命令解释器,也就是将1.exe假如内存的 程序,也是DOS操作系统的shell。
程序执行过程的跟踪
DOS执行.exe文件的过程,首先找到一段起始地址为SA:0000的容量足够的空闲内存区,在这段内存的前256个字节中,创建一个PSP数据区(程序段前缀),DOS就是利用PSP来和被加载的程序进行通讯。从这段内存的256字节处开始,存放程序,程序的地址就是SA+10H:0,将这个内存区的段地址存入DS中,设置CS:IP指向程序的入口。这就完成了对.exe文件的加载。
| 内存 | 内存 | 内存 | 内存(将段地址放入DS中) |
| PSP | PSP | PSP | |
| 程序 | 程序 |
注意:这个过程忽略了一个叫做重定位的过程。
[BX]和loop指令
在教材中规定了()表示内容,具体的定义在教材中。
- ax的内容是0010H,可以写作(ax)=0010H
- 2000:1000处的内容为0010H,可以写作(21000H)=0010H
- 对于mov ax,[2]的功能可以写作(ax)=((ds)*16+2)
大致的定义就像这样,之后用到了再说。
[BX]
mov ax,[bx]
这个指令的意思是将DS:BX处的内容送到ax中。
mov [bx],ax
这个指令的意思是将ax的内容送到DS:BX处中。
可以看到[bx]和[0]是类似的,都表示一个偏移地址,[bx]在表示偏移地址使用时,所表示的内存单元长度是根据操作中的其他操作对象确定的,如果是mov ax,[bx]那么就是一个字型数据,如果是mov al,[bx]就是一个字节型数据,这一点要注意。还有很重要的一点是,在debug中我们直接给出[0]和[bx]都是可以被识别的,但是在汇编源程序中,也就是masm中是不区分0和[0],bx和[bx]的,例如
mov ax,[0]这种指令都被看作是mov ax,0.
解决方法就是将段地址给出,写成mov ax,ds:[0] 这种显式地指明内存单元的段地址成为段前缀
loop指令
loop指令是一个循环指令,通常loop的循环次数存放在cx中,我们通过例子计算2^12看下loop指令:
assume cs:code
code segment
mov ax,2
mov cx,11
s: add ax,ax
loop s
mov ax,4c00H
code ends
end这是一个loop指令的例子,其中s叫做一个标号,代表一个地址,这个地址中的内容就是add ax,ax这个命令,CPU在执行loop s时的步骤有两个:1、(cx)=(cx)-1 2、判断cx中的值,不为0则转至标号s所表示的地址处执行,如果为零则不跳转,执行下一条指令。(这个程序中的cx为11很好理解,因为我们在mov ax,2的时候相当于第一个2,下来就是连乘11个2.)
loop和[bx]的联合应用
我们给出一个程序:
assume cs:code
code segment
mov ax,0ffffH
mov ds,ax
mov bx,0 初始化ds:bx指向ffff:0
mov dx,0 初始化累加器
mov cx,12 初始化循环计数器
s: mov al,[bx]
mov ah,0
add dx,ax
inc bx bx指向下一个单元 inc的功能是寄存器中的内容加1
loop s 循环体
mov ax,4c00H 返回
int 21H
code ends
end所以[bx]配合loop使用就是以bx作为循环中不断变化的偏移地址,相当于我们C语言中
for(i=0;i 为什么我们要使用多个段来存放程序呢?因为有的时候,我们的程序比较大,而我们能直接使用的空间(不被其他程序或数据占用的空间)却比较小,那么我们希望我们可以将程序分成几个部分来进行存放,也就是这一章我们的主要目标。 为了得到安全的空间,我们最好是通过操作系统获取空间,这有两种方法,一个是在程序加载的时候就分配好,另一个是在程序执行的过程中再申请,我们只学习第一种方法。 有些时候我们在写一些程序时会直接使用数据,而不是通过寄存器的内容进行操作,比如将8个给出的数据相加,我们就希望可以通过一段连续的空间来存放这8个数据,然后用loop循环相加,我们书上给出了一个例子: 这段代码中的dw的意思是define word,定义字型数据的意思,数据之间用“,”分隔开,上面的代码就用dw定义了8个字型数据,他们所占内存空间的大小就是16个字节。并且,dw定义的数据存放在代码段的开始位置,也就是CS指向的段的开头,也就是偏移地址从0开始。 程序中用bx存放加2递增的偏移地址,用来进行循环地累加,cx存放循环次数,ax作为累加器存放结果。 现在还有一个问题,我们使用dw定义了数据后,我们代码段的开始就不是我们需要执行的程序了,而是我们存放的数据,如果直接编译的话肯定是有问题的,具体的解决方法就是我们在源程序中指明程序的入口: 在程序的第一条指令前加一个标号start,在最后的end后也加start表示一个程序的开始和程序的结束,这个结构可以写作 start: …… 代码 end start 我们现在有一种使用栈的情况:我们需要将8个程序中定义的数据进行逆序存放,我们希望借助栈来实现,先将8个数据入栈,再出栈就可以实现你逆序存放。我们需要一段空间来当作栈,这就需要系统来分配,和数据一样,我们也通过定义数据来获得一段空间,再把这段空间当作站来使用就可以了。代码: 其中mov sp,30h是让ss:sp指向栈底。 这个程序我们可以看到一个明显的问题是,数据和栈放在一个段中会很乱,我们一不小心就把数据给吞了,而且如果数据特别多的情况下,8086的一个段只有64KB的大小,那么数据和栈放在一个段中也放不下,那么我们就希望把数据和栈分开。 给出一个实现的代码: 观察这个代码,发现data、code、stack都可以看作是一个标记,代表了段地址,所以我们可以直接使用这个标记来确定地址。注意:我们不能直接得mov ds,data 因为这在8086中是非法的。必须借助ax完成这个过程。 实际上无论是data、code、还是stack都是标记,我们完全可以用其他的字母单词来替换,比如a表示data,b表示code都是可以的。而且我们的这些段的定义也只是为了我们阅读和操作的方便,CPU是不会识别这些的。 (一般情况下,ds就指向data段,cs就指向code段,ss就指向stack段。)包含多个段的程序
在代码段中使用数据
assume cs:code
code segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
mov bx,0
mov ax,0
mov cx,8
s: add ax,cs:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
endassume cs:code
code segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
start mov bx,0
mov ax,0
mov cx,8
s: add ax,cs:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start在代码段中使用栈
assume cs:codesg
codesg segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
start: mov ax,cs
mov ss,ax
mov sp,30h
mov bx,0
mov cs,8
s: pushu cs:[bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop cs:[bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
codesg ends
end start将数据、代码、栈放入不同的段
assume cs:code,ds:data,ss:stack 直接定义三个段:code、data、stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,20h 将ss:sp指向栈底
mov ax,data
mov ds,ax 将ds指向data段
mov bx,0
mov cx,8
s: push [bx]
add bx,2
loop s
mov bx,0
mov cx,8
s0: pop [bx]
add bx,2
loop s0
mov ax,4c00h
int 21h
code ends
end start