Python爬虫—爬取京东商品信息(自动登录,换关键词,换页)
目录
- 前言
- 一、需要的Python库安装
-
- 1.设置默认pip默认安装路径
- 2.下载浏览器驱动(以chrome为例)
- 二、使用步骤(代码以函数为单位分开展示)
-
- 1.引入库
- 2.设置关键词和浏览器设置
- 3.定义获取密码函数
- 4.定义获取图片信息,返回最佳匹配位置函数
- 5.定义滑动函数
- 6.定义实现登录函数
- 7.定义文件保存函数
- 8.定义爬取函数
- 9.定义首次运行函数
- 10.定义继续运行函数
- 11.定义主函数
- 三、代码整体展示
- 总结
前言
最近需要些简单的商品数据信息,听说淘宝反爬虫反的厉害,自己Python学习花的时间少,人菜的抠脚,就打起了京东的注意这gif去重后晃得我眼痛
一、需要的Python库安装
1.设置默认pip默认安装路径
安装前注意pip默认安装目录设置
查看位置为python目录下的Lib\site.py文件
设置参数(因为需要转义 写成r‘Path和单反斜的形式’ 或 ‘Path和双反斜的形式’)
USER_SITE=r‘D:\Python\Lib\site-packages’
USER_BASE =r‘D:\Python\Scripts’
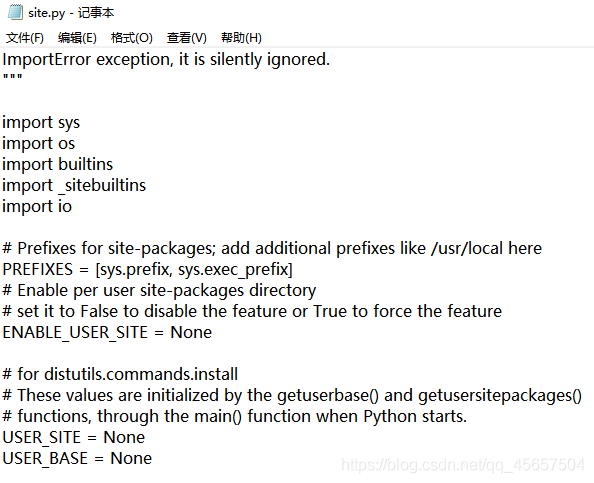
↑site.py文件示意↑
如果你不想设置保存位置参数
①手动跳转到你的python安装目录下再使用pip命令安装(不然要么在c盘给你安装整个python,要么迫害你的c盘剩余容量)
②使用pip命令时使用 --target=Path 参数指定安装目录
↑pip安装示意图↑
2.下载浏览器驱动(以chrome为例)
打开谷歌浏览器访问下面的地址,查看谷歌浏览器版本
chrome://version/
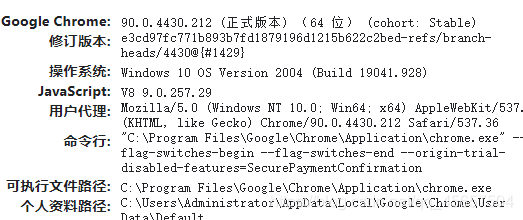
↑查看chrome版本示意图↑
驱动下载链接
链接: 谷歌浏览器驱动下载.
下载相应版本的驱动(或者最接近的版本)
将终端放在chrome目录下(放其他地方注意改环境变量就行)
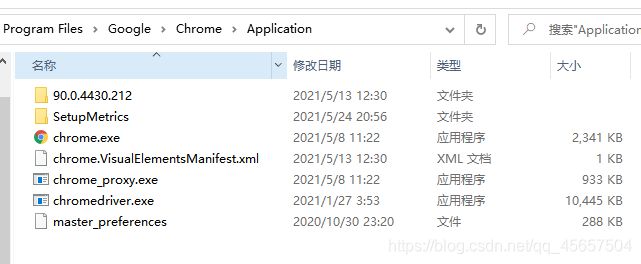
↑chrome目录↑
![]()
↑Win10设置驱动环境变量↑
二、使用步骤(代码以函数为单位分开展示)
1.引入库
代码如下:
import time
from urllib import request
import cv2
from selenium import webdriver
# from random import random
import pyautogui
from numpy import random
from lxml import etree
2.设置关键词和浏览器设置
代码如下:
#设置搜索关键词(根据需要修改)
keyword=['显卡','cpu','主板','内存','硬盘','散热器','机箱','外设','显示器','整机','笔记本电脑','平板','手机']
#对浏览器驱动进行设置
option=webdriver.ChromeOptions()
# option.add_argument('headless') #隐藏浏览器窗口(因为登录滑块需要使用鼠标,只能改为最小化)
option.add_argument("disable-blink-features=AutomationControlled") #去掉chrome的webdriver痕迹
browser = webdriver.Chrome(options=option)
驱动设置为不隐藏窗口;去除webdriver信息。
3.定义获取密码函数
代码如下:
#获取密码函数
def getLoginText():
f=open('D:\\PyCode\\txt\\JDLogin.txt', 'r', encoding='utf-8')
temp = f.readlines()
doc=[]
#去除元素中的换行转义
for t in temp:
t=t.strip('\n')
doc.append(t)
return doc
文件第一行是用户名,第二行是密码(没有任何前后缀。
直接在登录代码中明文定义账号密码不太好,容易泄露
4.定义获取图片信息,返回最佳匹配位置函数
代码如下:
#获取图片信息,返回最佳匹配位置
def findPic(target="img1.jpg", template="img2.png"):
# 读取图片
target_rgb = cv2.imread(target)
# 图片灰度化
target_gray = cv2.cvtColor(target_rgb, cv2.COLOR_BGR2GRAY)
# 读取模块图片
template_rgb = cv2.imread(template, 0)
# 匹配模块位置
res = cv2.matchTemplate(target_gray, template_rgb, cv2.TM_CCOEFF_NORMED)
# 获取最佳匹配位置
value = cv2.minMaxLoc(res)
# 返回最佳X坐标
return value[2][0]
5.定义滑动函数
代码如下:
#验证码滑动
def LoginSlide():
#获取滑块图像
target = browser.find_element_by_xpath('//div[@class="JDJRV-bigimg"]/img')
template = browser.find_element_by_xpath('//div[@class="JDJRV-smallimg"]/img')
# 获取模块的url路径
src1 = target.get_attribute("src")
src2 = template.get_attribute("src")
# 下载图片(参数二可以用 filename=‘想存放的目录位置+文件名’ 设置图片保存位置,只设置文件名默认保存在和代码统一目录下)
request.urlretrieve(src1,"img1.jpg")
request.urlretrieve(src2,"img2.png")
x = findPic()
w1 = cv2.imread('img1.jpg').shape[1]
w2 = target.size['width']
x = x / w1 * w2
# 按钮坐标(可以打开浏览器自己量一下,这里是1080p下大概坐标)
offset_x,offset_y = 1169,484
# pyautogui库操作鼠标指针
pyautogui.moveTo(offset_x,offset_y,duration=0.1 + random.uniform(0,0.1 + random.randint(1,100) / 100))
pyautogui.mouseDown()
offset_y += random.randint(9,19)
pyautogui.moveTo(offset_x + int(x * random.randint(15,25) / 20),offset_y,duration=0.28)
offset_y += random.randint(-9,0)
pyautogui.moveTo(offset_x + int(x * random.randint(17,23) / 20),offset_y,
duration=random.randint(20,31) / 100)
offset_y += random.randint(0,8)
pyautogui.moveTo(offset_x + int(x * random.randint(19,21) / 20),offset_y,
duration=random.randint(20,40) / 100)
offset_y += random.randint(-3,3)
pyautogui.moveTo(x + offset_x + random.randint(-3,3),offset_y,duration=0.5 + random.randint(-10,10) / 100)
offset_y += random.randint(-2,2)
pyautogui.moveTo(x + offset_x + random.randint(-2,2),offset_y,duration=0.5 + random.randint(-3,3) / 100)
pyautogui.mouseUp()
time.sleep(random.randint(2,5))
6.定义实现登录函数
代码如下:
#实现登录
def startLogin():
time.sleep(random.randint(2,5))
browser.maximize_window()
#点击账户登录
login=browser.find_element_by_xpath('//div[@class="login-tab login-tab-r"]/a')
login.click()
time.sleep(1)
#获取账号和密码
doc=getLoginText()
user=browser.find_element_by_id('loginname')
user.send_keys(doc[0])
upass=browser.find_element_by_id('nloginpwd')
upass.send_keys(doc[1])
time.sleep(2)
#点击登录
# loginSubmit=browser.find_element_by_xpath('//div[@class="login-btn"]/a')
loginSubmit=browser.find_element_by_id('loginsubmit')
time.sleep(1)
loginSubmit.click()
time.sleep(random.randint(2,5))
#调用滑动函数
LoginSlide()
#获取当前url并进行判断是否为登录网页
nowurl=browser.current_url
print('现在是Login界面?:'+str(str(nowurl).startswith('https://passport.jd.com/')))
if(str(nowurl).startswith('https://passport.jd.com/uc/login')):
#若滑块失败,则再调用滑动函数
LoginSlide()
browser.minimize_window()
time.sleep(random.randint(2,5))
7.定义文件保存函数
代码如下:
#将爬取内容保存到文件函数
def save(content):
with open('C:\\Users\\Administrator\\Desktop\\goods.txt', 'a', encoding='utf-8')as f:
f.writelines(content)
8.定义爬取函数
代码如下:
#定义信息爬取函数
#keyindex是当前keyword的下标
#index是当前搜索结果的页数
def paser_index(keyindex,index):
time.sleep(random.randint(5,10))
#若跳转到了登录界面,重新登录,并从上次断点继续爬取
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
return continueRun(index,keyindex)
#跳转到页面最下面,使页面完全加载60条
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(5,10))
#获取htmletree
selector = etree.HTML(browser.page_source)
#定位到商品list
items = selector.xpath('//div[@class="gl-i-wrap"]')
#获取当前页数
index= selector.xpath('//div[@id="J_topPage"]/span/b/text()')
index_max= selector.xpath('//div[@id="J_topPage"]/span/i/text()')
#循环将每个商品处理后写入文件
for item in items:
price= '/'.join('%s' %id for id in item.xpath('./div[@class="p-price"]/strong/i/text()') )
title= ''.join('%s' %id for id in item.xpath('./div[@class="p-name p-name-type-2"]/a/em/text()') )
desc= '/'.join('%s' %id for id in item.xpath('./div[@class="p-name p-name-type-2"]/a/i/text()') )
comment= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-commit"]//a/text()') )
shop= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-shop"]/span/a/text()') )
shop_tag= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-icons"]/i/text()') )
info = [title,price,desc,comment,shop,shop_tag]
print(info)
save('\n'+','.join('%s' %x for x in info))
#打印当前参数
print('index:'+str(index)+' index_max:'+str(index_max)+' keyindex:'+str(keyindex)+' keyword:'+str(keyword[keyindex])+' keyword_len:'+str(len(keyword)-1))
#若当前页码不是最大值,则随机等待后点击下一页
if(int(index[0])<int(index_max[0])):
#进行翻页操作,index+1
time.sleep(random.randint(2,5))
temp=int(index[0])*2+1
#执行翻页的js脚本
browser.execute_script("SEARCH.page("+str(temp)+", true);")
9.定义首次运行函数
代码如下:
#定义首次运行函数,用于首次执行(从keyword[0]第一页开始)
def fristRun(urls):
browser.get(urls)
#判定需不需要登录
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
print('正在登录账号……')
startLogin()
print('正式开始执行爬虫')
for i in range(0,len(keyword)):
#搜索关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[i])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
for j in range(1,int(index_max)+1):
paser_index(i,j)
browser.quit()
10.定义继续运行函数
代码如下:
#定义继续运行函数,用于程序意外停止后继续上次进度运行
def continueRun(urls,keyindex,index):
browser.get(urls)
#判定需不需要登录
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
print('正在登录账号……')
startLogin()
print('正式开始执行爬虫')
#搜索上次的关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[keyindex])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#跳转到指定页面
temp=int(index*2-1)
browser.execute_script("SEARCH.page("+str(temp)+", true);")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
#先将上次搜索词的剩余页面爬取
for k in range(index,int(index_max)+1):
paser_index(keyindex,k)
#再从上次搜索词的后面循环爬取
for i in range(keyindex+1,len(keyword)):
#搜索关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[i])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
#循环爬取页面
for j in range(1,int(index_max)+1):
paser_index(i,j)
browser.quit()
11.定义主函数
代码如下:
if __name__ == '__main__':
print('-----------开始-----------')
#定义要打开的网页url
urls='https://passport.jd.com/uc/login' #京东登录界面
# urls='https://www.jd.com/' #京东首页
# fristRun(urls) #首次运行使用这个,将下面的两句注释掉
#程序意外中断后,想继续运行时,使用这两句,将上面的fristRun()注释掉
continueRun(urls,4,11) #根据中断前控制台输出的参数,设置参数(keyindex,index)
print('-----------结束-----------')
三、代码整体展示
完整代码如下:
import time
from urllib import request
import cv2
from selenium import webdriver
# from random import random
import pyautogui
from numpy import random
from lxml import etree
#版本特性:在5.0基础上,将各种点击方法该为直接执行按钮的onclick属性调用的js脚本
#设置搜索关键词(根据需要修改)
keyword=['显卡','cpu','主板','内存','硬盘','散热器','机箱','外设','显示器','整机','笔记本电脑','平板','手机']
#对浏览器驱动进行设置
option=webdriver.ChromeOptions()
# option.add_argument('headless') #隐藏浏览器窗口(因为登录滑块需要使用鼠标,只能改为最小化)
option.add_argument("disable-blink-features=AutomationControlled") #去掉chrome的webdriver痕迹
browser = webdriver.Chrome(options=option)
#获取密码函数
def getLoginText():
f=open('D:\\PyCode\\txt\\JDLogin.txt', 'r', encoding='utf-8')
temp = f.readlines()
doc=[]
#去除元素中的换行转义
for t in temp:
t=t.strip('\n')
doc.append(t)
return doc
#获取图片信息,返回最佳匹配位置
def findPic(target="img1.jpg", template="img2.png"):
# 读取图片
target_rgb = cv2.imread(target)
# 图片灰度化
target_gray = cv2.cvtColor(target_rgb, cv2.COLOR_BGR2GRAY)
# 读取模块图片
template_rgb = cv2.imread(template, 0)
# 匹配模块位置
res = cv2.matchTemplate(target_gray, template_rgb, cv2.TM_CCOEFF_NORMED)
# 获取最佳匹配位置
value = cv2.minMaxLoc(res)
# 返回最佳X坐标
return value[2][0]
#验证码滑动
def LoginSlide():
#获取滑块图像
target = browser.find_element_by_xpath('//div[@class="JDJRV-bigimg"]/img')
template = browser.find_element_by_xpath('//div[@class="JDJRV-smallimg"]/img')
# 获取模块的url路径
src1 = target.get_attribute("src")
src2 = template.get_attribute("src")
# 下载图片(参数二可以用 filename=‘想存放的目录位置+文件名’ 设置图片保存位置,只设置文件名默认保存在和代码统一目录下)
request.urlretrieve(src1,"img1.jpg")
request.urlretrieve(src2,"img2.png")
x = findPic()
w1 = cv2.imread('img1.jpg').shape[1]
w2 = target.size['width']
x = x / w1 * w2
# 按钮坐标(可以打开浏览器自己量一下,这里是1080p下大概坐标)
offset_x,offset_y = 1169,484
# pyautogui库操作鼠标指针
pyautogui.moveTo(offset_x,offset_y,duration=0.1 + random.uniform(0,0.1 + random.randint(1,100) / 100))
pyautogui.mouseDown()
offset_y += random.randint(9,19)
pyautogui.moveTo(offset_x + int(x * random.randint(15,25) / 20),offset_y,duration=0.28)
offset_y += random.randint(-9,0)
pyautogui.moveTo(offset_x + int(x * random.randint(17,23) / 20),offset_y,
duration=random.randint(20,31) / 100)
offset_y += random.randint(0,8)
pyautogui.moveTo(offset_x + int(x * random.randint(19,21) / 20),offset_y,
duration=random.randint(20,40) / 100)
offset_y += random.randint(-3,3)
pyautogui.moveTo(x + offset_x + random.randint(-3,3),offset_y,duration=0.5 + random.randint(-10,10) / 100)
offset_y += random.randint(-2,2)
pyautogui.moveTo(x + offset_x + random.randint(-2,2),offset_y,duration=0.5 + random.randint(-3,3) / 100)
pyautogui.mouseUp()
time.sleep(random.randint(2,5))
#实现登录
def startLogin():
time.sleep(random.randint(2,5))
browser.maximize_window()
#点击账户登录
login=browser.find_element_by_xpath('//div[@class="login-tab login-tab-r"]/a')
login.click()
time.sleep(1)
#获取账号和密码
doc=getLoginText()
user=browser.find_element_by_id('loginname')
user.send_keys(doc[0])
upass=browser.find_element_by_id('nloginpwd')
upass.send_keys(doc[1])
time.sleep(2)
#点击登录
# loginSubmit=browser.find_element_by_xpath('//div[@class="login-btn"]/a')
loginSubmit=browser.find_element_by_id('loginsubmit')
time.sleep(1)
loginSubmit.click()
time.sleep(random.randint(2,5))
#调用滑动函数
LoginSlide()
#获取当前url并进行判断是否为登录网页
nowurl=browser.current_url
print('现在是Login界面?:'+str(str(nowurl).startswith('https://passport.jd.com/')))
if(str(nowurl).startswith('https://passport.jd.com/uc/login')):
#若滑块失败,则再调用滑动函数
LoginSlide()
browser.minimize_window()
time.sleep(random.randint(2,5))
#将爬取内容保存到文件函数
def save(content):
with open('C:\\Users\\Administrator\\Desktop\\goods.txt', 'a', encoding='utf-8')as f:
f.writelines(content)
#定义信息爬取函数
#keyindex是当前keyword的下标
#index是当前搜索结果的页数
def paser_index(keyindex,index):
time.sleep(random.randint(5,10))
#若跳转到了登录界面,重新登录,并从上次断点继续爬取
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
return continueRun(index,keyindex)
#跳转到页面最下面,使页面完全加载60条
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(random.randint(5,10))
#获取htmletree
selector = etree.HTML(browser.page_source)
#定位到商品list
items = selector.xpath('//div[@class="gl-i-wrap"]')
#获取当前页数
index= selector.xpath('//div[@id="J_topPage"]/span/b/text()')
index_max= selector.xpath('//div[@id="J_topPage"]/span/i/text()')
#循环将每个商品处理后写入文件
for item in items:
price= '/'.join('%s' %id for id in item.xpath('./div[@class="p-price"]/strong/i/text()') )
title= ''.join('%s' %id for id in item.xpath('./div[@class="p-name p-name-type-2"]/a/em/text()') )
desc= '/'.join('%s' %id for id in item.xpath('./div[@class="p-name p-name-type-2"]/a/i/text()') )
comment= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-commit"]//a/text()') )
shop= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-shop"]/span/a/text()') )
shop_tag= '/'.join('%s' %id for id in item.xpath('.//div[@class="p-icons"]/i/text()') )
info = [title,price,desc,comment,shop,shop_tag]
print(info)
save('\n'+','.join('%s' %x for x in info))
#打印当前参数
print('index:'+str(index)+' index_max:'+str(index_max)+' keyindex:'+str(keyindex)+' keyword:'+str(keyword[keyindex])+' keyword_len:'+str(len(keyword)-1))
#若当前页码不是最大值,则随机等待后点击下一页
if(int(index[0])<int(index_max[0])):
#进行翻页操作,index+1
time.sleep(random.randint(2,5))
temp=int(index[0])*2+1
#执行翻页的js脚本
browser.execute_script("SEARCH.page("+str(temp)+", true);")
#定义首次运行函数,用于首次执行(从keyword[0]第一页开始)
def fristRun(urls):
browser.get(urls)
#判定需不需要登录
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
print('正在登录账号……')
startLogin()
print('正式开始执行爬虫')
for i in range(0,len(keyword)):
#搜索关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[i])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
for j in range(1,int(index_max)+1):
paser_index(i,j)
browser.quit()
#定义继续运行函数,用于程序意外停止后继续上次进度运行
def continueRun(urls,keyindex,index):
browser.get(urls)
#判定需不需要登录
nowurl=browser.current_url
if(str(nowurl).startswith('https://passport.jd.com/')):
print('正在登录账号……')
startLogin()
print('正式开始执行爬虫')
#搜索上次的关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[keyindex])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#跳转到指定页面
temp=int(index*2-1)
browser.execute_script("SEARCH.page("+str(temp)+", true);")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
#先将上次搜索词的剩余页面爬取
for k in range(index,int(index_max)+1):
paser_index(keyindex,k)
#再从上次搜索词的后面循环爬取
for i in range(keyindex+1,len(keyword)):
#搜索关键词
key=browser.find_element_by_id('key')
key.clear()
key.send_keys(keyword[i])
#执行搜索的js脚本
browser.execute_script("search('key');return false;")
time.sleep(random.randint(2,5))
#获取页面最大值
index_max=browser.find_element_by_xpath('//div[@id="J_topPage"]/span/i').text
print("当前页面最大值为:"+str(index_max))
#循环爬取页面
for j in range(1,int(index_max)+1):
paser_index(i,j)
browser.quit()
if __name__ == '__main__':
print('-----------开始-----------')
#定义要打开的网页url
urls='https://passport.jd.com/uc/login' #京东登录界面
# urls='https://www.jd.com/' #京东首页
# fristRun(urls) #首次运行使用这个,将下面的两句注释掉
#程序意外中断后,想继续运行时,使用这两句,将上面的fristRun()注释掉
continueRun(urls,4,11) #根据中断前控制台输出的参数,设置参数(keyindex,index)
print('-----------结束-----------')
总结
参考了不少爬虫代码修修改改好几天才搞好(菜的抠脚,刚开始用递归写,结果老爆栈)
主要以selenium库为核心的玩具级爬虫
京东商品会显示不少重复的商品,鉴于爬取量不大,可以使用set()对文本去重,简单的清洗重要参数为空的行后食用
目前未解决的问题:
①登录模块,有一定概率点不到登录按钮,导致运行失败(不管是通过xpath还是id都有概率点了不跳出滑动验证……);
②单线程爬取太慢,平均一个关键词要30分钟才爬完(可以再调低些等待时间,目前中间极少需要重新登录)
a.强制等待函数积累间隔时间长
b.程序太快了会被强制退出登录(即便是这样的慢速,时间长了也会被强制退出登录)
c.单位时间内请求过多登录时需要短信验证码,或扫描登录
③有些商品信息获取不到,例如title中带有京东国际标签的产品,无法获取title,price,desc,comment(原因不明)
④不能全程隐藏窗口执行,登录需要最大化,并且鼠标与被控制浏览器之间不能有遮挡物(被强制登出后会突然最大化开始登录,幸好请求速度慢频率低)
⑤偶尔会卡在当前关键词的最大页,一直循环好久,不自动换关键词 或 换关键词失败(原因不明) 改搜索点击为执行js搜索函数,解决此问题
⑥占用c盘缓存空间,win10会把浏览过的网页或其他记录保存在C:\Users\Administrator\AppData\Local\Temp\目录下,所以要定期清理缓存……