C语言基础知识
目录
一、顺序程序设计
1.1 C语言中的结构类型
1.2 常量与变量
1.3运算符与表达式
1.4数据的输入输出
二、选择程序结构
2.1选择语句
三、循环程序结构
3.1循环语句
四、数组
4.1 一维数组
4.2 二维数组
4.3 字符数组
五、函数
5.1函数基本信息
5.2、定义函数的方法
5. 3、函数的调用
5.4、函数的声明
六、指针
6.1、指针类型的意义:
6.2、野指针
6.3、指针的运算:
6.4、字符指针
6. 5、指针数组(存放指针的数组)
6.6、数组指针 (指向数组的指针)
6.7、函数指针(指向函数的指针,存放函数的地址)
6.8、函数指针数组(把函数的地址存放到数组中)
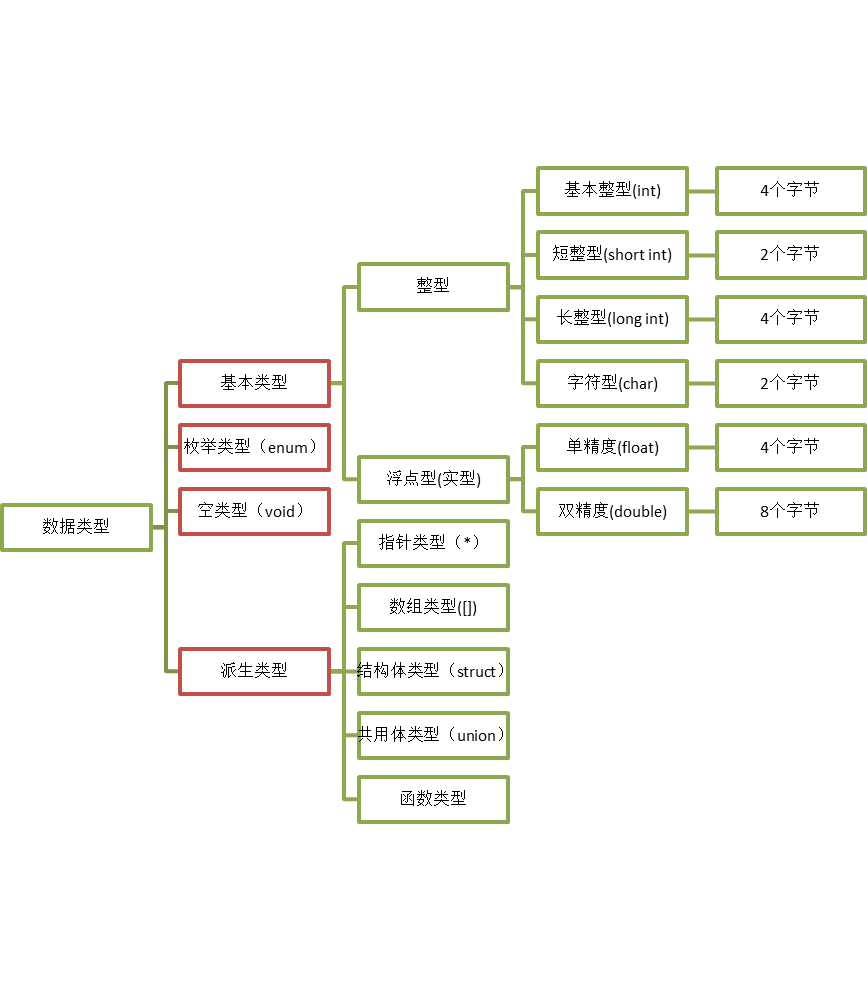
七、数据类型
7.1结构体含义
7.2结构体内存对齐
7.3位运算符
7.4位段
7.5枚举
7.6共用体 (联合体)
八、文件
8.1文件的分类
8.2文件的使用
8.3文件的顺序读写
九、预处理
9.1宏定义
9.2条件编译
9.3文件包含处理
一、顺序程序设计
1.1 C语言中的结构类型
1.2 常量与变量
1.常量
(1)整型常量。如100,12345,0,-1232
(2)实型常量。
①十进制小数形式。如12.232,-23.43等
②指数形式。如12.34e3(代表12.34×10^3),0.123E-2(代表0.123×10^-2)等。注意:e或E之前必须有数字,后面必须为整数。
(3)字符常量。
①普通字符,用单撇号括起来的一个字符,如:‘a’,‘Z’,‘3’,‘?’。
②转义字符。

(4)字符串常量。用双撇号括起来的若干个字符,如"boy","123"等。
(5)符号常量。用#define指令,指定用一个符号名称代表一个常量(符号常量不占内存,只是一个临时符号,代表一个值,在预编译后这个符号就不存在了,因此不能对符号常量赋新值)。
2.变量
先定义,后使用
3.常变量
在定义变量时,前面加一个关键字const。
#define Pi 3.14159 //定义符号常量
const float pi=3.14159; //定义常变量符号常量 Pi和常变量 pi都代表 3.14159,在程序中都能使用。但二者性质不同:定义符号常量用#define指令,它是预编译指令,它只是用符号常量代表一个字符串,在预编译时仅进行字符替换,在预编译后,符号常量就不存在了(全置换成 3. 14159 了),对符号常量的名字是不分配存储单元的。而常变量要占用存储单元,有变量值,只是该值不改变而。从使用的角度看,常变量具有符号常量的优点,而且使用更方便。有了常变量以后,可以不必多用符号常量。
4.标识符
标识符就是一个对象(变量、符号常量名、函数、数组、类型)的名字,并且只能由字母、数字、下划线3中字符组成,且第一个字符必须为字母或下划线,标识符不可与关键字相同。
1.3运算符与表达式
优先级:! > 算术运算符 > 关系运算符 > && > || > 赋值运算符
(1)算术运算符(+ - * / % ++ --)
%两侧必须为整型
(2)关系运算符(> < == >= !=)
(3) 逻辑运算符 (&& || !)与 或 非
a&&b 如果a和b都为真,则结果为真;
当使用逻辑与&&时,如果最左边是假(0),那么后边的都不算了,如下:
#include
int main()
{
int i=0,a=0,b=2,c=3,d=4;
i=a++ && ++b && d++;
printf("a=%d b=%d c=%d d=%d",a,b,c,d);
return 0;
} a=1 b=2 c=3 d=4a||b a和b有一个以上为真,则结果为真,二者都为假时,结果为假(0为假 非0为真)。
当使用逻辑或||时,如果最左边为真(非0) ,那么后边都不需要计算了,如下:
#include
int main()
{
int i=0,a=1,b=2,c=3,d=4;
i=a++ || ++b || d++;
printf("a=%d b=%d c=%d d=%d",a,b,c,d);
return 0;
} a=2 b=2 c=3 d=4(4)位运算符(<< >> ~ | ^ &) 只能作用于整数
移位运算: 左移<< 左边丢弃,右边补零,即乘2;右移>>,移动的是二进制位,即除2。
按位与:00000111(7) 0&0=0,0&1=0,1&1=1
(&) 00000101(5)
————————————————————
00000101(5)
按位或:00000111(7) 0|0=0,0|1=1,1|1=1
(|) 00000101(5)
——————————————————-
00000111(7)
异或运算。
一道面试题:请写代码交换两个变量的值,不创建临时变量
#include
int main() // 0^0=0,0^1=1,1^1=0
{
int a=3; // a=011
int b=4; // (^) b=100
a=a^b; // ————————————
b=b^a; // a=111 (a^b的结果,a变为7)
a=a^b; // (^) b=100
printf("a=%d,b=%d",a,b); // ————————————
return 0; // b=011 (b^a的结果,b变为3)
} // (^) a=111
// ————————————
// a=100 (a^b的结果,a变为4) (5) 赋值运算符
(6)条件运算符(?:)
a>b?a:b
(7) 逗号运算符(,)
逗号表达式,从左向右依次执行,但表达式的结果是最后一个表达式的结果。
(8)指针运算符(*和&)
(9)求字节数运算符(sizeof)
(10) 强制类型转换运算符( (类型) )
(11)成员运算符(. ->)
(12) 下标运算符( [ ] )
(13) 其他(如函数调用运算符())
1.4数据的输入输出
1.printf(格式输出) scanf(格式输入)、
2.putchar(输出字符) getchar(输入字符)
3.puts(输出字符串) gets(输入字符串)
printf 格式字符如下:
| 格式字符 | 含义 |
|---|---|
| d,i | 以带符号的十进制形式输出整数(正数不输出符号) |
| o | 以八进制无符号形式输出整数(不输出前导符0) |
| x | 以十六进制无符号形式输出整数(不输出前导符0x),输出字母时按照其小写形式 |
| X | 以十六进制无符号形式输出整数(不输出前导符0x),输出字母时按照其大写形式 |
| u | 以无符号十进制形式输出整数 |
| c | 输出一个字符 |
| s | 输出一个字符串 |
| l | 以小数形式输出单、双精度,隐含输出6位小数 |
| e | 以指数形式输出实数,指数以“e”表示,如1.2e+02 |
| E | 以指数形式输出实数,指数以“E”表示,如1.2E+02 |
| g | 选用%f或者%e格式中宽度较短的一种格式进行输出,不输出无意义的0 |
| G | 选用%f或者%E格式中宽度较短的一种格式进行输出,不输出无意义的0 |
| l | 用于长整型整数,可加在格式符d,o,x,u前面 |
| m | 数据最小宽度 |
| n | 对实数,表示输出n位小数;对字符串,表示截取的字符个数 |
| - | 输出的数字或字符在域内向左靠 |
scanf 格式字符如下
| 格式字符 | 含义 |
|---|---|
| d,i | 用来输入有符号的十进制整数 |
| u | 用来输入无符号的十进制整数 |
| o | 用来输入无符号的八进制整数 |
| x,X | 用来输入无符号的十六进制整数,大小写作用相同 |
| c | 用来输入一个字符 |
| s | 用来输入一个字符串到一个字符数组中,以非空白字符开始,以第一个非空白字符结束,(自动)以结束标志’\0’作为最后一个字符 |
| f | 用来输入实数,可以以小数形式或指数形式输入 |
| e,E,g,G | 与f作用相同,可以互相替换,大小写作用相同 |
| l | 加在格式符d,o,x,u前面用于输入长整型整数,加在格式符f或者e前面用于输入double类型数据 |
| h | 加在格式符d,o,x前面用于输入一个短整型数据 |
| 域宽m | 指定输入数据所占宽度,m应为正整数 |
| * | %后面跟*表示跳过它指定的列数 |
二、选择程序结构
2.1选择语句
1、C语言有两种选择语句:(1) if语句,用来实现两个分支的选择结构;(2) switch语句,用来实现多分支的选择结构。
2、在if语句中,else一定是与离它最近的if匹配。
3、switch(表达式),括号内表达式的值的类型应为整数类型(包括字符型)。
在执行switch语句时,根据switch表达式的值找到想匹配的case,并不在此进行条件检查,在执行万一个case标号后面的语句后,就从此标号开始执行下去,不在进行判断。
一般情况下,在执行一个case子句后,应当用break语句使流程跳出switch结构。即终止switch语句的执行。
三、循环程序结构
3.1循环语句
1、C语言有三种循环语句:(1)whlie语句,先判断后执行。(2)do...while语句,先无条件的执行循环体,然后判断;whlie后面的“;”不能忘。(3)for语句。
2、break语句,提前终止整个循环。 continue语句,提前结束本次循环。
四、数组
4.1 一维数组
1、数组中存放的元素属于同一个数据类型,在内存中连续存放。
2、①sizeof(数组名),计算整个数组的大小,sizeof内部单独存放一个数组名,数组名表示整个数组。②&数组名,取出的是整个数组的地址,表示整个数组。
除了上述两种情况,所有的数组名都是首元素的地址。
3、sizeof 计算所占空间大小
4.2 二维数组
1、二维数组的行可以省略,列不可以。
4.3 字符数组
1、C语言中没有字符串类型,也没有字符串变量,字符串是存放在字符数组中的。
2、字符数组的两种表现形式:
char c[]={"China"};
char c[]="China";
char c[6]={'C','h','i','n','a','\0'};
//上方三种形式均等价,字符数组c的长度都为6
char c[]={'C','h','i','n','a'};//此字符数组c的长度为53、处理字符串的函数
①strcat(字符数组1,字符数组2)--字符串连接函数(不能自己连接自己)。
字符数组1要足够大.连接前两个字符串后面都有'\0',连接时将字符串1后面的'\0'取消,只在新字符串最后保留'\0'。
②strcpy(字符数组1,字符串2)--字符串复制函数,连同'\0一起复制'。
“字符数组1”必须写成数组名形式,“字符串2”可以是字符数组名,也可以是一个字符串常量。
③strcmp(字符串1,字符串2)--字符串比较函数
比较规则:将两个字符串从左自右逐个字符相比较(比较的是ASCII码值),直到出现不同的字符或'\0'为止。
④strlen(字符数组)
求字符串的长度(\0之前停止,并且\0不算个数)。
⑤strlwr--转换为小写的函数
⑥strupr--转换为大写的函数
五、函数
5.1函数基本信息
1、所有函数都是平行的,即在定义函数时是分别进行的,是相互独立的。一个函数并不从属于另一个函数,即函数不能嵌套定义。函数间可以相互调用,但不能调用main函数。main函数是被操作系统调用的。
5.2、定义函数的方法
1、//无参函数
类型名 函数名()
{
函数体
}
或
类型名 函数名(void)
{
函数体
}
2、//有参函数
类型名 函数名(形式参数列表)
{
函数体
}5. 3、函数的调用
①传值调用:二者分别占有不同的内存块,对形参的修改不会影响实参。
传址调用:二者内存块相同,对形参的修改影响实参。
②实参可以是常量、变量或表达式。
③一个函数可以有一个以上的return语句,但只能有一个返回值。
④嵌套调用
⑤递归
5.4、函数的声明
①函数的声明与函数的定义基本上相同,只是函数的声明比函数定义中的首行多一个分号(被调函数在main函数后面时需要声明)。
②函数声明中的形参名可以省略,而只写形参的类型。
int Add(int,int);
int Add(int a,int b);
//二者均可六、指针
6.1、指针类型的意义:
①指针类型决定了指针进行解引用操作能够访问几个字节。char *p,*p访问一个字节;int *p,*p访问四个字节。
②指针类型决定了指针加减整数, 加或者减的是几个字节(即指针的步长,单位是字节)。char*p,p+1跳过一个字节;int*p,p+1跳过四个字节。
6.2、野指针
成因:①指针未初始化②指针指向的空间被释放③指针越界访问
6.3、指针的运算:
①指针加 / 减整数,指向不同的内容
②指针-指针(结果的绝对值是中间元素的个数)
③指针关系运算(比较大小)
6.4、字符指针
char arr[]="abcdef";
char *p=arr; //将字符串的首字符的地址a放进p中
printf("%c\n",*p); //a
printf("%s\n",p); //abcdef
return 0;6. 5、指针数组(存放指针的数组)
应用如下:
#include
int main()
{
int arr1[]={1,2,3,4,5};
int arr2[]={2,3,4,5,6};
int arr3[]={3,4,5,6,7};
int*arr[]={arr1,arr2,arr3};
int i;
for(i=0;i<3;i++)
{
int j=0;
for(j=0;j<5;j++) //打印的结果为 1 2 3 4 5
printf("%d ",*(arr[i]+j)); //2 3 4 5 6
printf("\n"); //3 4 5 6 7
}
return 0;
} 6.6、数组指针 (指向数组的指针)
一般应用于二维数组以上 ([ ]的优先级高于 *)
int arr[10]={1,2,3,4,5,6,7,8,9,10};
int(*p)[10]=&arr;
char* arr[5];
char*(*pa)[5]=&arr;
/*pa是个指针
它指向一个数组
指向的数组的元素类型是char* */6.7、函数指针(指向函数的指针,存放函数的地址)
&函数名和函数名都表示函数的地址
#include
void print(char* str)
{
printf("%s\n",str);
}
int main()
{ // 函数类型
void (*p)(char*)=print;
(*p)("hello"); //传参
} 6.8、函数指针数组(把函数的地址存放到数组中)
#include
int Add(int x,int y)
{
return x+y;
}
int Sub(int x,int y)
{
return x-y;
}
int Mul(int x,int y)
{
return x*y;
}
int Div(int x,int y)
{
return x/y;
}
int main()
{
int(*pa[4])(int,int)={Add,Sum,Mul,Div};
int i=0;
for(i=0;i<4;i++)
{
printf("%s ",pa[i](2,3)); //5 -1 6 0
}
return 0;
} 七、数据类型
7.1结构体含义
结构体是一些值的集合,这些值为成员变量,结构体的每个成员可以是不同类型的变量。
结构体成员的变量可以说标量、数组、指针,甚至是其它结构体,如下;
#include
struct S //struct为结构体的关键字 S为结构体名 struct S为结构体类型
{
int a;
char b;
char arr[20];
double d;
}s1,s2,s3; //此时s1 s2 s3为全局变量。要尽量少的使用全局变量
struct T
{
char ch[10];
struct S s;
char *pc;
};
int main()
{
char arr[]="hello\n";
struct T t={"haha",{10,"w","hello world",3.14},arr};
printf("%s\n",t.ch); //haha
printf("%s\n",t.s.arr); //hello word
return 0;
} 7.2结构体内存对齐
对齐规则:①第一个成员在与结构体变量偏移量为0处
②其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数=编译器默认的对齐数与该成员的较小值
③结构体的总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
④如果嵌套了结构体,嵌套的结构体对齐到(开始于)自己的最大对齐数的整数倍处;结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
7.3位运算符
(<< >> ~ | & ^) 只能作用于整数
移位运算: 左移<< 左边丢弃,右边补零,即乘2;右移>>,移动的是二进制位,即除2。
按位与:00000111(7) 0&0=0,0&1=0,1&1=1
(&) 00000101(5)
————————————————————
00000101(5)
按位或:00000111(7) 0|0=0,0|1=1,1|1=1
(|) 00000101(5)
——————————————————-
00000111(7)
异或
#include
int main() // 0^0=0,0^1=1,1^1=0
{
int a=3; // a=011
int b=4; // (^) b=100
a=a^b; // ————————————
b=b^a; // a=111 (a^b的结果,a变为7)
a=a^b; // (^) b=100
printf("a=%d,b=%d",a,b); // ————————————
return 0; // b=011 (b^a的结果,b变为3)
} // (^) a=111
// ————————————
// a=100 (a^b的结果,a变为4) 7.4位段
1、位段与结构体相似,位段的成员后面有一个冒号和一个数字,且成员位整型数据类型。位段不具有跨平台性。
2、位段的使用时为了节省空间,位段成员后面的数字为bit,一个字节=8个bit。
3、一个位段必须存储在同一存储单元中,不能跨两个单元,如果第一个单元空间不能容纳下一位段位,则该空间不用,而从下一个单元起存放该位段。
7.5枚举
1、枚举就是指把可能的值一一列举出来,变量的值只限于列举出来的值的范围内。
2、每一个枚举元素都代表一个整数,默认的顺序从0开始,也可以给每个元素赋初值,但是不能给每个元素赋值
enum Weekday {sun=7,mon,tue,wed,thu,fri,sat,};
// 1 2 3 4 5 67.6共用体 (联合体)
1、几个不同的变量共享同一段内存的结构,称为"共用体"类型的结构。
2、共用体变量所占的内存大小等于最大的成员的大小。当最大成员的大小不是最大对齐数的整数倍时,就要对齐到最大对齐数的整数倍。
union un
{
int i; //4
char arr[5]; //5
}
int main()
{
union un u;
printf("%d",sizeof(u)); //结果为8
return 0;
}八、文件
8.1文件的分类
数据文件分为ASCII文件(文本文件)和二进制文件。
字符一律以ASCII形式存储,数值型数据既可以用ASCII形式存储也可以用二进制形式存储。
8.2文件的使用
#include
#include
#include
int main()
{
FILE *fp;
fp=fopen("text.txt","r");
if(fp==NULL)
{
printf("%s\n",strerror(erron));//打开失败
}
//打开成功
//读写文件
//关闭文件
fclose(fp);
fp=NULL;
return 0;
} 

8.3文件的顺序读写
stdin键盘 stdout屏幕
| 函数名 | 调用形式 | 功能 |
| fgetc(输入) | fgetc(fp) | 从fp指向的文件读入一个字符。 |
| fputc | fputc(ch,fp) | 把字符ch写到文件指针变量fp指向的文件中。 |
| fgets(输入) | fgets(str,n,fp) | 从fp指向的文件读入一个长度为n-1的字符串,存放到字符数组str中。 |
| fputs | fputs(str,fp) | 把str所指向的字符串写到文件指针变量fp所指向的文件中。 |
| fscanf(输入) | (文件指针,格式字符串,输出表列) 读 | |
| fprintf | (文件指针,格式字符串,输入表列) 写 | |
| fread | (buffer,size,count,fp) | buffer:是一个地址;size:要读写的字节数;count:要读写多少个数据项;fp:FILE类型指针。二者为二进制方式 |
| fwrite | (buffer,size,count,fp) | |
struct S
{
char name[20];
int age;
double score;
};
int main()
{
struct S s={"张三",20,60.6};
FILE *pf=fopen("text.txt","wb");
if(pf==NULL)
{
return 0;
}
fwrite(&s,sizeof(struct S),1,pf);
fclose(pf);
pf= NULL;
return 0;
}九、预处理
就是进行文本操作:①#include 头文件的包含 ②注释删除,使用空格替换注释③#define
C语言内定的预定义符号 ,如下:
__FILE__ //代码的名称以及绝对路径
__LINE__ //代码所在的行号
__DATE__ //代码执行日期
__TIME__ //代码执行时间9.1宏定义
#define 标识符 字符串
宏是完整替换,不是传参!
在书写宏时,要注意括号的使用。
#define Fun(x) x*x
int main()
{
int a=5,b=2;
Fun(a); //5*5=25
Fun(a)+Fun(b); //5*5+2*2=29
Fun(a+b); //5+2*5+2=5+10+2=17
Fun(a)/Fun(b); //5*5/2*2=25/2*2=25
}宏的优点:①宏比函数在程序的规模和速度方面更胜一筹 ②宏是类型无关的,可适用于整型、长整型、浮点型等的关系运算。
宏的缺点:①无法调试②无类型,不严谨③由于运算优先级的问题,结果可能会出错④每次使用宏的时候,都会有一段宏定义的代码插入到程序中。
9.2条件编译
条件编译:有时希望程序中的一部分内容只在满足一定条件时才能进行编译。
#ifdef 表示符
程序段1
#else
程序段2 //也可以没有#else
#endif若所指定的标识符已经被#define指令定义过,则在程序编译阶段对程序段1进行编译;否则编译程序段2。
#ifndef 表示符
程序段1
#else
程序段2 //也可以没有#else
#endif与第一种形式相比,只是第一行不同:将ifdef改为ifndef。它的作用是:若指定的标识符未被定义过,则编译程序段1;否则编译程序段2.这种形式与第一种形式的作用相反。
9.3文件包含处理
#include<文件名> 应用库函数
#include"文件名" 自己创建