Hadoop HDFS分布式文件系统(介绍以及基础操作命令)
目录
一、为什么需要分布式存储?
二、分布式的基础架构分析
三、HDFS基础架构
1.HDFS简介
四、HDFS集群启停命令
1.一键启停脚本
2.单进程启停
五、HDFS基本操作命令
1.创建文件夹
2.查看指定目录下内容
3.上传文件到HDFS指定目录下
4.查看HDFS文件内容
5.下载HDFS文件
6.拷贝HDFS文件
7.追加数据到HDFS文件中
8.HDFS数据移动操作
9.HDFS数据删除操作
六、HDFS权限不足解决方法
1.超级用户
2.修改权限(和Linu一致)
一、为什么需要分布式存储?
①数据量太大,单机存储能力有上限,需要靠数量来解决问题。
②数量的提升带来的是网络传输、磁盘读写、CPU、内存等方面综合提升。分布式组合在引擎可以达到1+1>2的效果。
二、分布式的基础架构分析
大数据体系中,分布式的调度主要有两类价格模式:
1.去(无)中心化模式
去中心化模式没有明确的中心,众多服务器之间基于特定规则进行同步协调。区块链和P2P就是典型的去中心化模式。
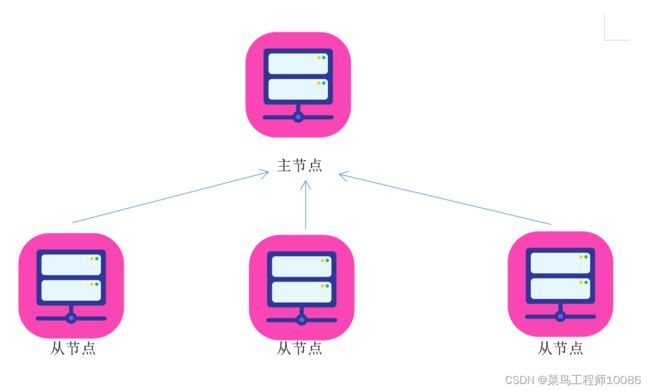
2.中心化模式(大部分基础架构)
以一个节点作为中心,去同意调度其他节点。这种模式也被称为一主多从模式,简称主从模式(Master And Slaves)。Hadoop就是典型的主从模式(中心化模式)架构的技术框架。
三、HDFS基础架构
1.HDFS简介
HDFS是Hadoop三大组件(HDFS、MApReduce、YARN)之一。全称是Hadoop Distributed File System(Hadoop分布式文件系统)。是Hadoop技术栈内提供的分布式数据存储解决方案,可以在多台服务器上构建集群,存储海量的数据。
2.HDFS基础架构
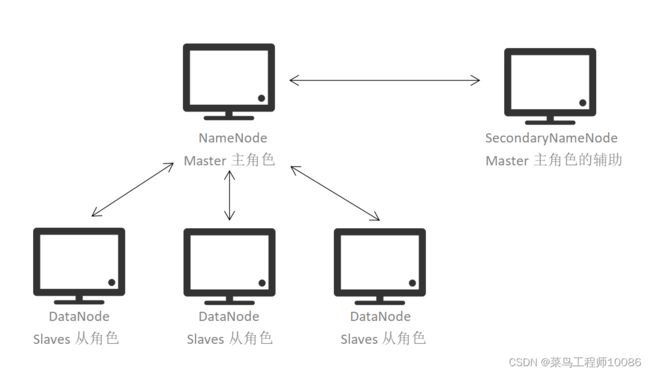
HDFS是一个典型的主从模式的架构
HDFS集群分为三个角色:
·主节点(NameNode):HDFS系统的主角色,是一个独立的进程,负责管理HDFS整个文件系统,负责管理DataNode。
·从节点(DataNode):HDFS系统的从角色,是一个独立进程,主要负责数据的存储,即存入数据和取出数据。
·主节点辅助节点(SecondaryNameNode):Name Node的辅助,是一个独立的进程,主要帮助NameNode完成元数据整理工作(打杂)。
四、HDFS集群启停命令
1.一键启停脚本
·$HADOOP_HOME/sbin/start-dfs.sh,一键启动HDFS集群
执行原理:
·在执行此脚本的机器上,启动SecondaryNameNode
·读取core-site.xml内容(fs.defaultFS项),确认NameNode所在的机器,启动NameNode
·读取workers内容,确认DataNode所在的机器,启动全部DataNode

·$HADOOP_HOME/sbin/stop-dfs.sh,一键关闭HDFS集群
执行原理:
·在执行此脚本的机器上,关闭SecondaryNameNode
·读取core-site.xml(fs.defaultFS项),确认NameNode所在机器,关闭NameNode
·读取workers内容,确认DataNode所在机器,关闭全部NameNode
2.单进程启停
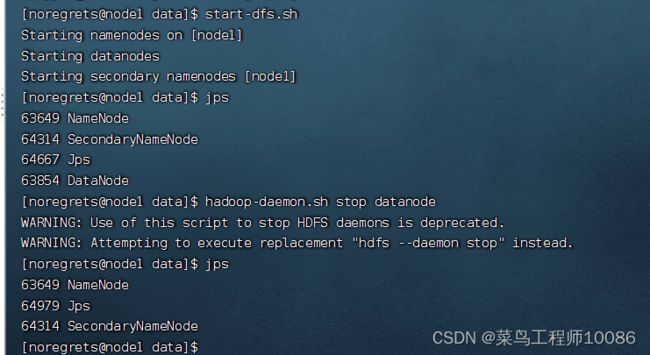
(1)$HADOOP_HOME/sbin/hadoop-daemon.sh,此脚本可以单独控制所在机器的进程的启停(只能在对应机器管理对应服务)
用法:hadoop-daemon.sh ( start | status | stop ) ( namenode | secondarynamenode | datanode )
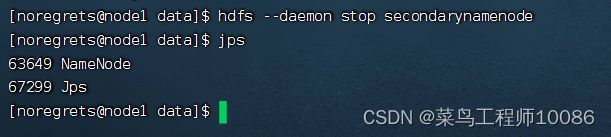
(2)$HADOOP_HOME/bin/hdfs,此程序也可以用以单独控制所在机器的进程的启停(只能在对应机器管理对应的服务)
用法:hdfs --daemon( start | status | stop )( namenode | secondarynamenode | datanode )
五、HDFS基本操作命令
HDFS文件系统基本信息
HDFS作为分布式存储的文件系统,有其对数据的路径表达方式。HDFS同Linux系统一样,均是以 / 作为根目录的组织形式。

路径表示:
·Linux:file:///
·HDFS:hdfs://namenode:port/
例:
Linux:file:///usr/local/hello.txt
HDFS: hdfs://node1:8020/usr/local/hello.txt
协议头 file:/// 或 hdfs://node1:8020/ 可以省略,需要提供Linux路径的参数,会自动识别为file://,需要HDFS路径的参数,会自动识别为hdfs://,除非你明确需要写或不写会有BUG,否则一般不用写协议头.
HDFS命令体系介绍
关于HDFS文件系统的操作命令,Hadoop提供了两套命令体系。
(1)hadoop命令(老版本用法),用法:hadoop fs [ generic options ]
(2)hdfs命令(新版本用法),用法:hdfs dfs [ generic options ]
两者在文件系统操作,用法完全一致,用哪个都可以。
1.创建文件夹
hadoop fs -mkdir [-p]
hdfs dfs -mkdir [-p]
path为待创建的目录
-p选项的行为与Linux mkdir -p 一致

2.查看指定目录下内容
hadoop fs -ls [-h] [-R] [
hdfs dfs -ls [-h] [-R] [
-h 人性化显示文件size
path 指定目录路径
-R 递归查看指定目录及其子目录

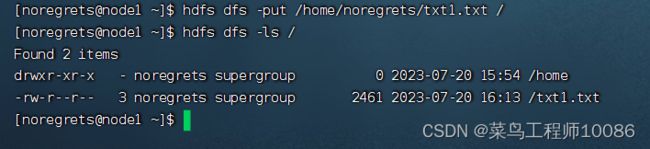
3.上传文件到HDFS指定目录下
hadoop fs -put [-f] [-p]
hdfs dfs -put [-f] [-p]
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限。
localsrc 本地文件系统(客户端所在机器)
dst 目标文件系统(HDFS)
4.查看HDFS文件内容
hadop fs -cat
hdfs dfs -cat

读取大文件可以使用管道符配合more对文件进行翻页处理
hadoop fs -cat
hdfs dfs -cat
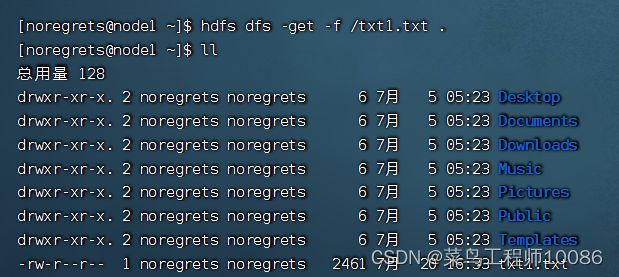
5.下载HDFS文件
hadoop fs -get [-f] [-p]
hdfs dfs -get [-f] [-p]
下载文件到本地文件系统指定目录,localdst必须是目录
-f 覆盖目标文件(已存在下)
-p 保留访问和修改时间,所有权和权限
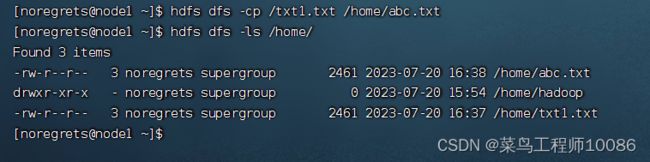
6.拷贝HDFS文件
hadoop fs -cp [-f]
hdfs dfs -cp [-f]
-f 覆盖目标文件(已存在下)
7.追加数据到HDFS文件中
hadoop fs -appendToFile
hdfs dfs -appendToFile
将所以给本地文件的内容追加到给定dst文件,如果dst文件不存在,将创建该文件,如果
8.HDFS数据移动操作
hadoop fs -mv
hdfs dfs -mv
移动文件到指定文件夹下
可以使用该命令移动数据,重命名文件的名称

9.HDFS数据删除操作
hadoop fs -rm -r [-skipTrash] URI [URI ...]
hdfs dfs -rm -r [-skipTrash] URI [URI ...]
删除指定路径的文件或文件夹(-r)
-skipTrash 跳过回收站,直接删除
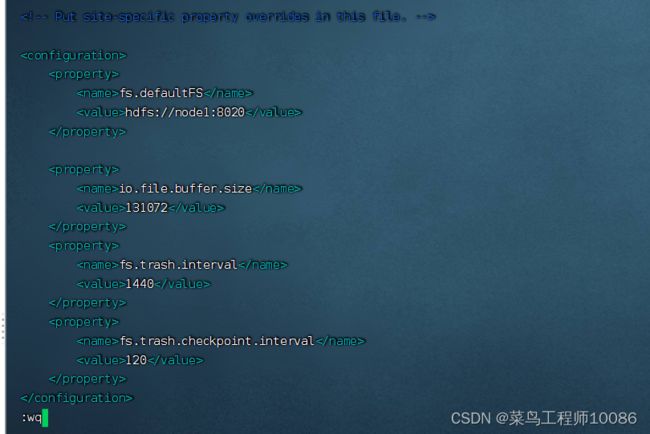
回收站功能默认关闭,如果要开启需要在 core-site.xml 内配置:
无需重启集群,在哪个机器配置的,在哪个机器执行命令就生效。
回收站默认位置在: /user/ 用户名 (hadoop)/.Trash
六、HDFS权限不足解决方法
1.超级用户
HDFS中,也是有权限控制的,其控制逻辑和Linux系统完全一致。但Linux的超级用户是root,HDFS文件系统的超级用户:是启动namenode的用户。

2.修改权限(和Linu一致)
(1)修改所属用户和组
hadoop fs -chown [-R] root:root /xxx.txt
hdfs dfs -chown [-R] root:root /xxx.txt
(2)修改权限
hadoop fs -chmod [-R] 777 /xxx.txt
hdfs dfs -chmod [-R] 777 /xxx.txt