Spark内核调度
目录
一、DAG
(1)概念
(2)Job和Action关系
(3)DAG的宽窄依赖关系和阶段划分
二、Spark内存迭代计算
三、spark的并行度
(1)并行度设置
(2)集群中如何规划并行度
四、spark任务调度
五、Spark运行概念名词
(1)概率名词
(2)Spark运行层级梳理
一、DAG
Spark的核心是根据RDD来实现的,Spark Scheduler则为Spark核心实现的重要一环,其作用就是任务调度。Spark的任务调度就是如何组织任务去处理RDD中每个分区的数据,根据RDD的依赖关系构建DAG,基于DAG划分Stage,将每个Stage中的任务发到指定节点运行。基于Spark的任务调度原理,可以合理规划资源利用,做到尽可能用最少的资源高效地完成任务计算。
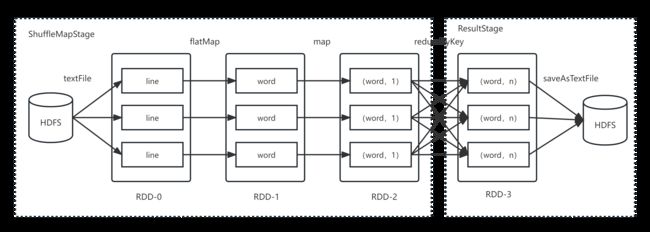 wordcount_DAG流程图
wordcount_DAG流程图
(1)概念
DAG:有向无环图。有方向没有形成闭环的一个执行流程图。
有向:有方向。
无环:没有形成闭环。
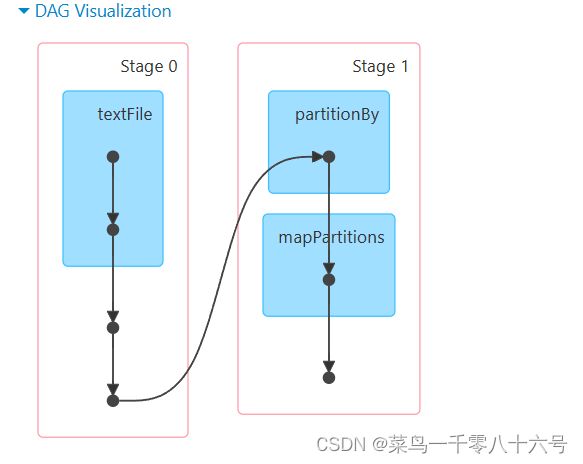
(2)Job和Action关系
一个Action会产生一个Job(一个应用程序内的子任务),每个Job会产生各自自己的DAG流程图。如上图,有三个Action,所以有三个Job,每一个链路对应这每个Job的DAG流程图。
(3)DAG的宽窄依赖关系和阶段划分
在SparkRDD前后之间的关系,分为:
①窄依赖:父RDD的一个分区,全部将数据发给子RDD的一个分区(一对一)。
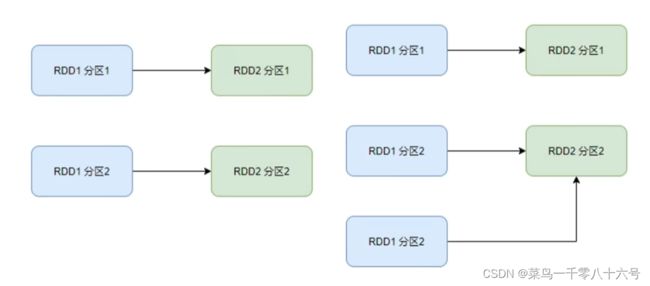
②宽依赖(别名:shuffle):父RDD的一个分区,将数据发给子RDD的多个分区(一对多)。
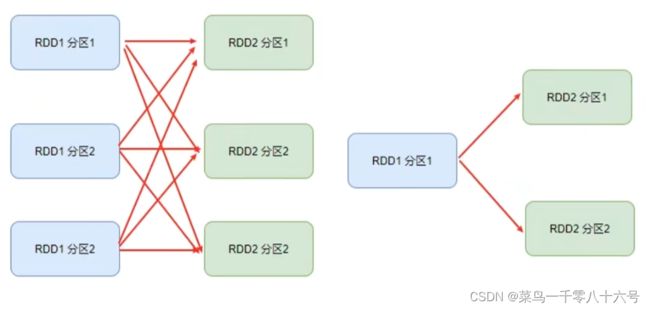
对于Spark来说,会根据DAG,按照宽依赖,划分不同的DAG阶段。
划分依据:从后向前,遇到宽依赖就划分出一个阶段,称为Stage。在Stage内部一定是窄依赖。
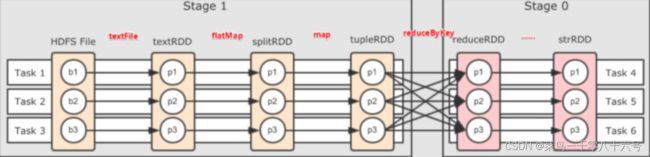
二、Spark内存迭代计算
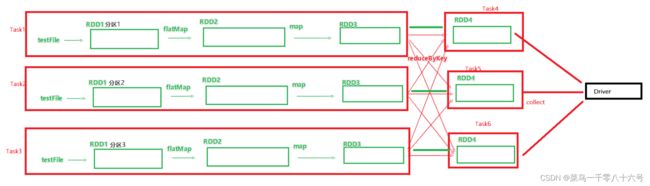
如图,基于带有分区的DAG以及阶段划分。可以从图中得到逻辑上最优的task分配,一个task是一个线程来具体执行那么如上图, task1中rdd1、rdd2、rdd3的迭代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算。
如上图,task1、task2、task3就形成了三个并行的内存计算管道。Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数。如果全局并行度是3,其实大部分算子分区都是3。
注意::Spark我们一般推荐只设置全局并行度,不要再算子上设置并行度,除了一些排序算子外,计算算子就让他默认开分区就可以了。
面试题1 : Spark是怎么做内存计算的? DAG的作用? Stage阶段划分的作用?
①Spark会产生DAG图。
②DAG图会基于分区和宽窄依赖关系划分阶段。
③一个阶段的内部都是窄依赖,窄依赖内,如果形成前后1:1的分区对应关系,就可以产生许多内存迭代计算的管道这些内存迭代计算的管道,就是一个个具体的执行Task。
④一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计儿了。
面试题2: Spark为什么比MapPeduce快
①Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务。很多的复杂任务,是需要写多个MapReduce进行串联。多个MR串联通过磁盘交互数据。
②Spark可以执行内存迭代,算子之间形成DAG基于依赖划分阶段后,在阶段内形成内存迭代管道。但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的。
总结:
编程模型上Spark占优(算子够多)。
算子交互上,和计算上可以尽量多的内存计算而非磁盘迭代。
三、spark的并行度
Spark的并行:在同一时间内,有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑。在有了6个task并行的前提下,rdd的分区就被规划成6个分区了。
(1)并行度设置
可以在代码中和配置文件中以及提交程序的客户端参数中设置优先级从高到低:
①代码中
②客户端提交参数中配置文件中
③默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
全局并行度配置的参数:
spark.default.parallelism

全局并行度是推荐设置,不要针对RDD改分区,可能会影响内存迭代管道的构建,或者会产生额外的Shuffle。
(2)集群中如何规划并行度
结论:设置为CPU总核心的2-10倍。比如集群可用CPU核心是100个,建议并行度是200-1000。确保是CPU核心的整数倍即可,最小是2倍,最大一般是10或更高(适量)即可。
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情。所以,在100个核心的情况下,设置100个并行,就能1让CPU 100%出力。这种设置下,如果task的压力不均衡,某个task先执行完了。就导致某个CPu核心空闲。所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待。但是可以确保,某个task运行完了。后续有task补上,不让cpu闲下来,最大程度利用集群的资源。规划并行度,只看jiqunzongCPU核数。
四、spark任务调度
Spark的任务,由Driver进行调度,这个工作包含:
①逻辑DAG产生
②分区DAG产生
③Task划分
④将Task分配给Executor并监控其工作
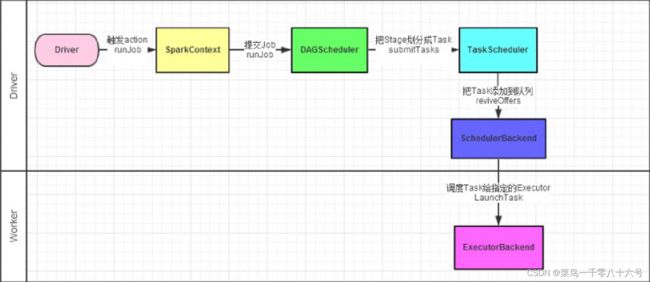
如图,Spark程序的调度流程如图(1-4都是Driver的工作,5是Worker的工作):
①Driver被构建出来
②构建SaprkContext(执行环境入口对象)
③基于DAG Scheduler(DAG调度器)goujainluojiTask分配
④基于TaskScheduler(Task调度器)将逻辑Task分配到各个Executor上干活,并监控他们
⑤Worker(Executor),被TaskScheduler管理监控,听从它们的指令干活,并定期汇报进度
DAG调度器(DAG Scheduler):将逻辑的DAG图进行处理,最终得到逻辑上的Task划分(重点)
Task调度器(Task Scheduler):基于DAG Scheduler的产出,来规划这些逻辑的task,应该在哪些物理的Executor上运行,以及监控管理它们的运行。
五、Spark运行概念名词
(1)概率名词
| Term | Meaning |
| Application | 用户编写的Spark应用程序,当该应用程序在集群上运行时包含一个driver program和多个executors。 |
| Application jar | 包含Spark的应用程序的jar包 |
| Driver program | 是一个进程,包含Spark应用程序(application)的main方法,并且创建SparkContext。其中创建SparkContext的目的是为了准备Spark应用程序的运行环境。在Spark中由SparkContext负责和ClusterManager通信,进行资源的申请、任务的分配和监控等;当Executor部分运行完毕后,Driver负责将SparkContext关闭。通常用SparkContext代表Driver。 |
| Cluster manager | 集群的管理者,SparkContext会与之进行通信,主要负责集群资源的管理,包括yarn、mesos。 |
| Deploy mode | 运行模式,用来设定driver端在哪里运行,主要包括client和cluster。cluster模式中,driver端运行在集群中一个节点,client模式下,driver运行在集群之外。 |
| Worker node | 集群中运行spark任务的节点。 |
| Executor | 一个进程,在worker node 运行应用程序,他可以运行task(计算),和保存应用程序中所用的数据到内存或者磁盘上。每一个应用程序拥有其独有的executor。在Spark on Yarn模式下,其进程名称为CoarseGrainedExecutorBackend,类似于Hadoop MapReduce中的YarnChild。一个CoarseGrainedExecutorBackend进程有且仅有一个executor对象,它负责将Task包装成taskRunner,并从线程池中抽取出一个空闲线程运行Task。每个CoarseGrainedExecutorBackend能并行运行Task的数量就取决于分配给它的CPU的个数了。 |
| Task | 被送到某个Executor上的工作单元,和hadoopMR中的MapTask和ReduceTask概念一样,是运行Application的基本单位,多个Task组成一个Stage,而Task的调度和管理等是由TaskScheduler负责。 |
| Job | 并行化的运算集合 |
| Stage | Stage是每一个Job处理过程要分为的几个阶段,一个Stage可以有一个或多个Task。 |
| TaskScheduler | 实现Task分配到Executor上执行。 |
(2)Spark运行层级梳理
①一个Spark环境可以运行多个Application
②一个代码运行起来,会成为一个Application
③Application内部可以有多个Job
④每个Job由一个Action产生,并且每个Job有自己的DAG执行图
⑤一个Job的DAG图会基于宽窄依赖划分成不同的阶段
⑥不同阶段内基于分区数量,形成多个并行的内存迭代管道
⑦每一个内存迭代管道形成一个Task ( DAG调度器划分将Job内划分出具体的task任务,一个Job被划分出来的task在逻辑上称之为这个job的taskset )