【理论学习】Vision-Transformer
文章目录
- 1. self-attention理论
-
- 1.1. Attention(Q,K,V)的实现
- 2. Multi-head Self-Attention理论
- 3. Positional Encoding
- 4. Vision Transformer
声明:本篇文章是我再b站观看博主霹雳吧啦Wz的视频后,做的一篇笔记,推荐大家看完视频在来简单浏览该文章。文章如有不妥之处,欢迎大家指出。
1. self-attention理论
vit-transformer中最核心的理论就是self-attention理论。对下图从右→左看,依次是vit-transformer总体框架、多头注意力机制(Multi-Head Attention)、单个注意力头机制(我自己的取得名字,方便理解)。
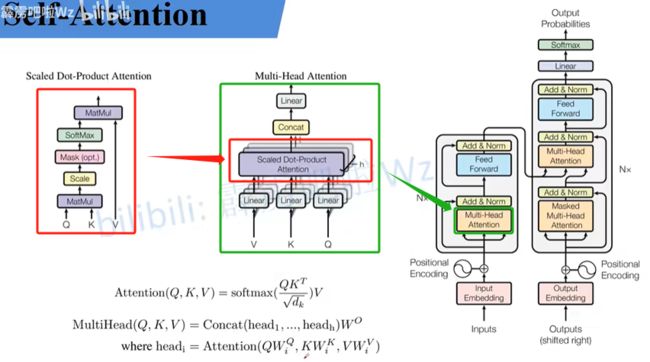
从上图可以看出:vit-transformer总体框架的核心部分就是多头注意力机制,而多头注意力机制正是由多个单头注意力机制组成。这样是不是就很好理解了,也就是说只要把单头注意力机制搞懂,这个模型也就理解了七八十。
1.1. Attention(Q,K,V)的实现
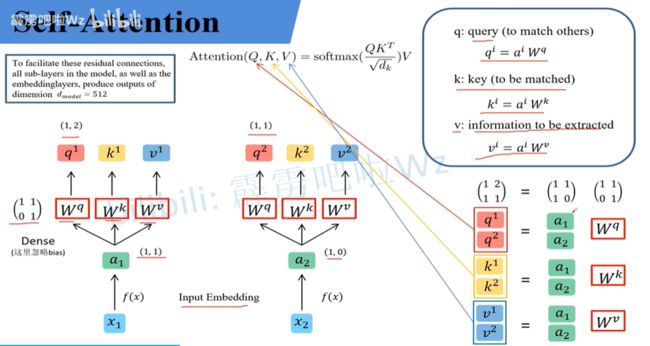
如上图所示,假设有两个输入 x i ( i = 1 , 2 , . . . ) x_i(i=1,2,...) xi(i=1,2,...),把 x i x_i xi看做信息的输入,经过Embedding层 f ( x ) f(x) f(x)得到特征信息 a i a_i ai,然后通过权重矩阵 W q 、 W k 、 W v W^q、W^k、W^v Wq、Wk、Wv(权重矩阵在代码实现中是一个Linear层)得到各自的 q i 、 k i 、 v i q^i、k^i、v^i qi、ki、vi。
q:query和k去匹配
v:从a中提取的信息
右下角是将 a 1 a_1 a1、 a 2 a_2 a2(可能还有 a 3 a_3 a3、 a 4 a_4 a4、…)并行化,和矩阵 W q W^q Wq、 W k W^k Wk$W^v$相乘得到相应q、k、v。
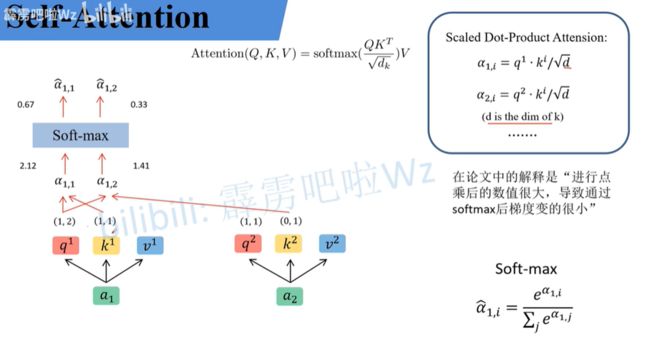
首先, q i q^i qi 和 k j k^j kj 进行点乘, d d d 是 k k k 的维度。
(例如: 因为 k k k 里面有两个元素,所以 d d d =2,如上图所示 q 1 q^1 q1 和 k 1 k^1 k1
点乘等于3,然后除以√2,最后结果等于2.12)。
q i q^i qi 和 k j k^j kj 点乘得到的输出 a i , j a_{i,j} ai,j 经过softmax层得到 a ^ i , j \widehat{a}_{i,j} a i,j , a ^ i , j \widehat{a}_{i,j} a i,j对应 v m v^m vm 的权重大小。
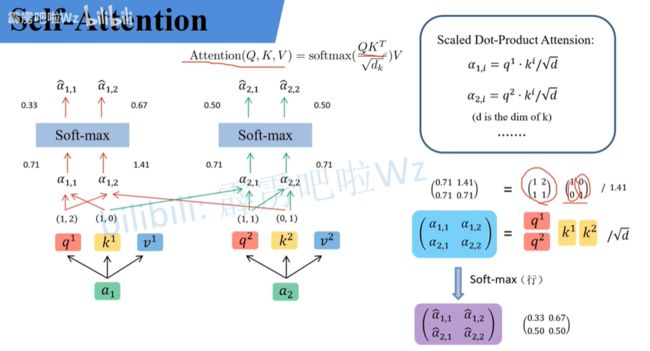
v m v^m vm参与运算过程:
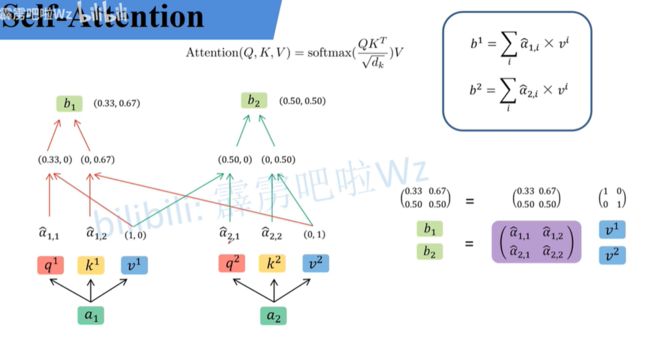
a ^ \widehat{a} a 与 v v v 相乘得到 b i b_i bi,即 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V)。到这里实现公式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dkQKT)V。
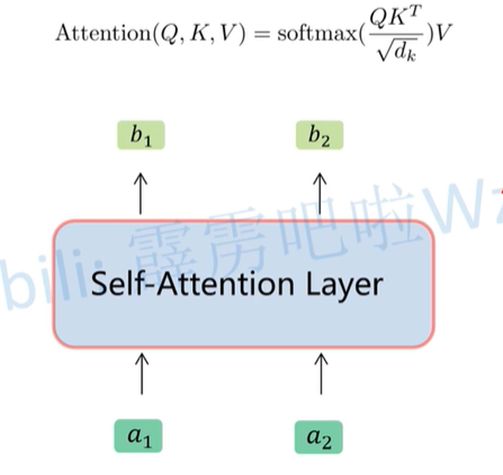
上述过程可简化为:
输入a序列和b序列,简化结构如下:
2. Multi-head Self-Attention理论
根据 h e a d head head个数,均分 q 、 k 、 v q、k、v q、k、v,如下:
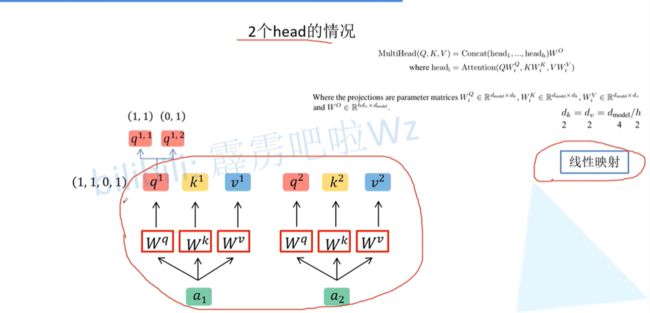
q 、 k 、 v q、k、v q、k、v 第二个上标为1的定义为 h e a d 1 head1 head1 ,第二个上标为2的定义为 h e a d 2 head2 head2 。
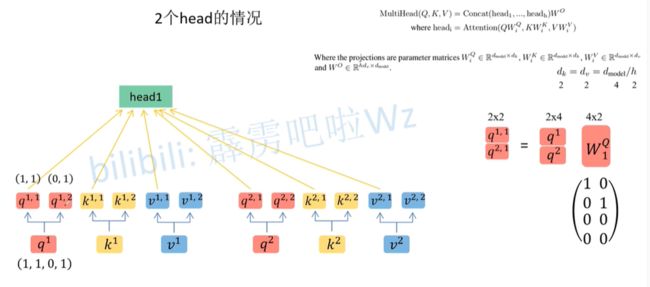
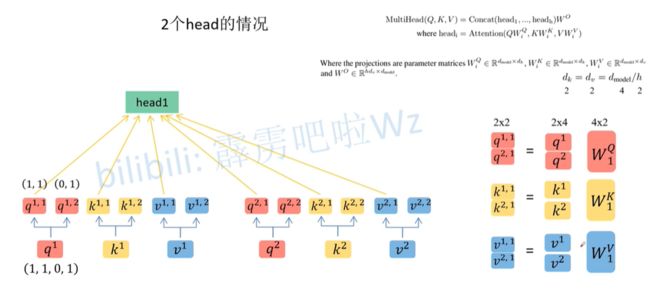




上述过程可简化为:
输入a序列和b序列,简化结构如下:
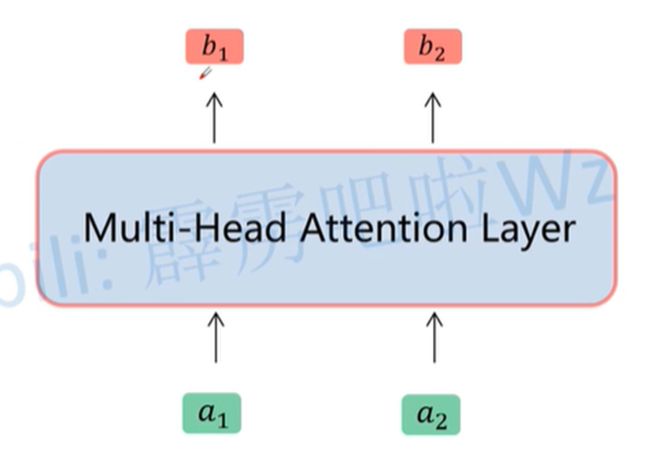
3. Positional Encoding

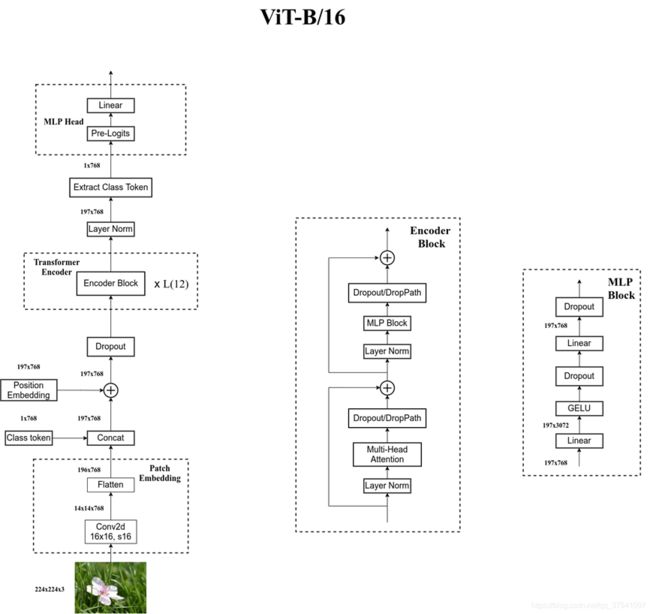
4. Vision Transformer
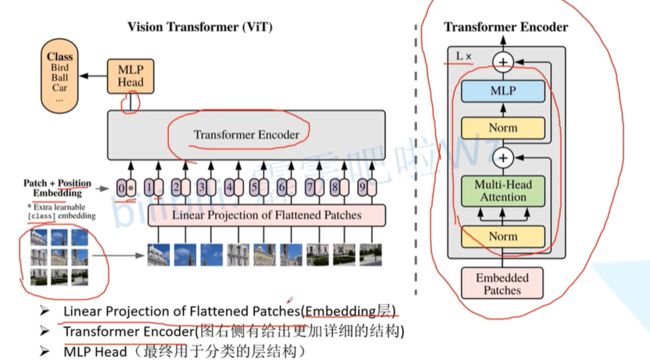
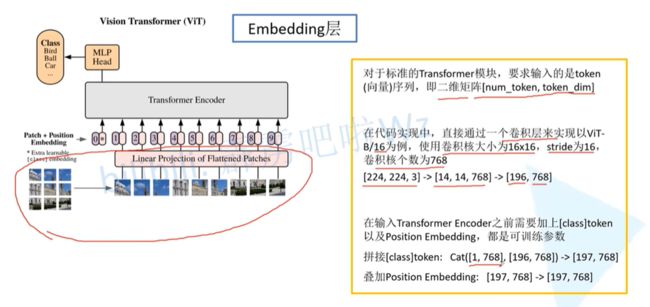
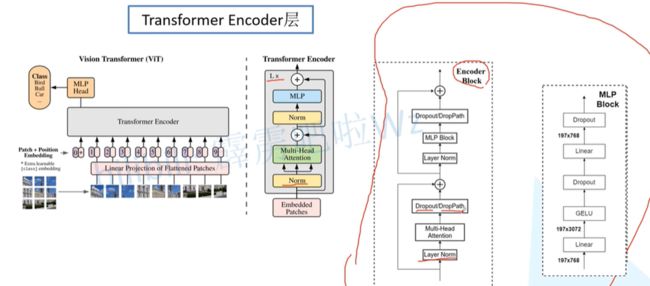
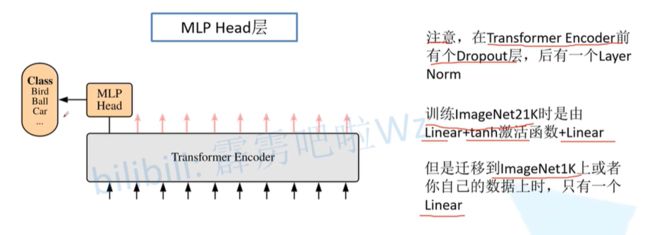
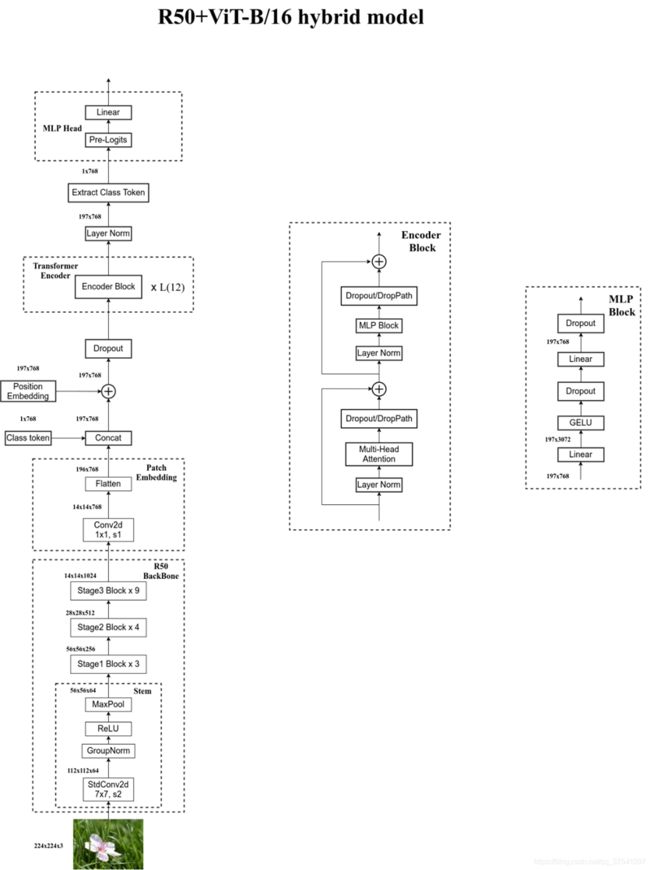
- Vision Transformer网络结构(以ViT-B/16为例):
- Hybrid模型
(1) R50的卷积层采用的stdConv2d不是传统的Conv2d
(2) 将所有的BatchNorm层替换成GroupNorm层
(3) 把stage4中的3个Block移至stage3中