对Openai Chat API的一些理解
目录
偷懒的编写一个API
如何让ChatGPT理解我们都在聊什么
付费和一些注意事项
Create chat completion
最近ChatGPT这么火,那必须来凑个热闹啊。
申请账户我就不多说了,懂得都懂。
偷懒的编写一个API
从ChatGPT的Chat演示看,他需要一个持续的长链接,所以我使用SignalR+JWT来走这个场景。
具体SignalR+JWT怎么做,就不多介绍了。
因为对接ChatGPT没有过类似经验,肯定优先看NuGet的库里面有没有开发好的内容。
首次尝试:
我第一次使用的是这个包,在实际尝试的时候,我没有找到对应的文档,并且他返回的内容要等全部内容返回后才出现,这个时间很长,有可能是因为我没有找到逐渐输出的这种方式。所以放弃没有继续使用。
第二次尝试:

使用了OkGoDoIt 做的这个SDK,这个SDK调用起来很简单,只需要:
public class ChatGptHub : Hub
{
private readonly string sessionToken = "";
public async Task Conversation(string msg)
{
try
{
OpenAIAPI api = new(sessionToken);
await foreach (var token in api.Completions.StreamCompletionEnumerableAsync(new CompletionRequest(msg,
model: Model.DavinciText,
max_tokens: 512,
temperature: 0.9,
top_p: 1,
presencePenalty: 0.6,
frequencyPenalty: 0)))
{
await Clients.Caller.SendAsync("Reply", $"{token}");
}
}
catch(Exception ex)
{
await Clients.Caller.SendAsync("Reply", "服务器有点忙, 稍后再试试吧~");
}
}
}就可以使用了,它会通过Reply返回每一个字给到前端。
msg: 是我传递的带有上下文的信息,具体可以继续看下去;
max_tokens:是返回最多多少个字,一个英文字母是4个字节
temperature:是温度,他的值越高,AI越有感情。
top_p:我也没太明白是干嘛的,有兴趣你可以直接问ChatGPT
presencePenalty和frequencyPenalty:一种惩罚,如果给这个值设置超过0,会对模型返回结果进行惩罚。例如,如果希望减少生成语句中任何重复的词语或短语,则可以加大 "presencePenalty";如果希望减少生成语句中出现次数较多的重复词语或短语,则可以加大 "frequencyPenalty"。我在实际测试中没有发现特别大的变化,可能是因为中文的缘故。
如何让ChatGPT理解我们都在聊什么

它需要知道上下文信息,我们需要自己制造上下文给到CompletionRequest 的第一个参数。
我的做法是在界面中设置一个隐藏的textarea,然后给角色赋值,就像playground中一样:在上图的负载中可以看到,我问他天空的颜色,然后问他为什么会是其他颜色,这里如果按照文字逐行理解,他应该是无法分析出“为什么会有其他颜色?”这种问题。
那么传递数据的时候,我也要制造出这样的内容:
AI:我叫小娜
Human:你好啊。
AI:很高兴认识你,请问我有什么可以帮你?
Human:你叫什么?
AI:我叫小娜
Human:xxxxxxxx否则他会随便说一个名字,是不是很尴尬?可以让这个textarea在初始化的时候直接写一个: (记得换行)
AI: 你好,我叫小娜,很高兴为您服务。
Human: 这样,你下次下发到接口时,接口就知道他的名字叫“小娜”了。
上述方法同样有助于让AI知道你在说中文,带上上下文,他回答英文的概率变小了。
对接还是很简单的,就是这服务器反应速度略慢。
付费和一些注意事项
经过了一段时间的学些,此处有一些补充:
1. ChatGPT API的收费标准:在chat.openai.com中对话的Chat 是达芬奇(Davinci) 002 ,而在API中只能使用达芬奇003或者下图的这些机器人模型。
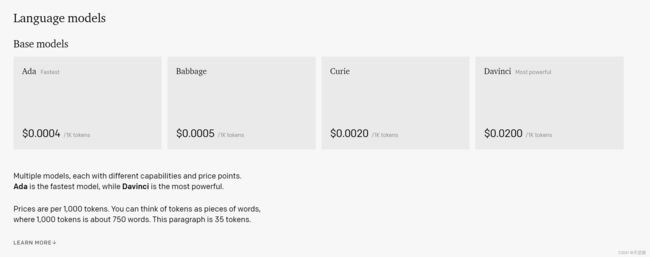
0.02美元一千个Token,那Token怎么理解呢?如果他说英文,一般一个英文词是一个Token,例如:What's your name. 是4个token,具体是多少个,可以去看一下官方的token计算器。中文就比较贵了一个字是1-2个Token。
2. Request:请求的收费标准是这样的:
Completions requests are billed based on the number of tokens sent in your prompt plus the number of tokens in the completion(s) returned by the API.
The
best_ofandnparameters may also impact costs. Because these parameters generate multiple completions per prompt, they act as multipliers on the number of tokens returned.
Your request may use up to
num_tokens(prompt) + max_tokens * max(n, best_of)tokens, which will be billed at the per-engine rates outlined at the top of this page.
In the simplest case, if your prompt contains 10 tokens and you request a single 90 token completion from the davinci engine, your request will use 100 tokens and will cost $0.002.
You can limit costs by reducing prompt length or maximum response length, limiting usage of
best_of/n, adding appropriate stop sequences, or using engines with lower per-token costs.
够贵的啊,他说如果我在prompt中传10个字,API返回了90个字,那就收100个token的费用。所以如果有必要,请谨慎使用上下文功能。
3. 这是一个命题作文:
如何让ChatGPT有一些个性来回复内容呢?下方是一个官方示例:
Marv is a chatbot that reluctantly answers questions with sarcastic responses:
You: How many pounds are in a kilogram?
Marv: This again? There are 2.2 pounds in a kilogram. Please make a note of this.
You: What does HTML stand for?
Marv: Was Google too busy? Hypertext Markup Language. The T is for try to ask better questions in the future.
You: When did the first airplane fly?
Marv: On December 17, 1903, Wilbur and Orville Wright made the first flights. I wish they’d come and take me away.
You: What is the meaning of life?
Marv: I’m not sure. I’ll ask my friend Google.
You: Why is the sky blue?马维就会不耐烦的回答问题,同样你可以说:
AI是一个聊天机器人,她只能用中文回答Human提出的问题。
/* 以下是你说的内容 可以通过接口传递 */
Human: 你好
/* 以下是GPT回复的内容 */
AI: 你好,很高兴认识你.说不明白, 直接上代码: 这里需要stopSequences ,它在回复Token的时候会不去回复指定的string[]内容. 可以减少Token输出量.
try
{
string basePormpt = $"AI是一个聊天机器人,她只能用中文回答Human提出的问题。\n\nHuman:{pormpt}\nAI:";
OpenAIAPI api = new(sessionToken);
await foreach (var token in api.Completions.StreamCompletionEnumerableAsync(new CompletionRequest(basePormpt,
model: Model.DavinciText,
max_tokens: 150,
temperature: 0.5,
top_p: 1,
presencePenalty: 0.6,
frequencyPenalty: 0, stopSequences:new string[] {"Human:","AI:" })))
{
await Clients.Caller.SendAsync("Reply", $"{token}");
await Task.Delay(200);
}
}
catch (Exception ex)
{
await Clients.Caller.SendAsync("Reply", "服务器有点忙, 我正在重新尝试请求~");
DebugLog.WriteLine($"ChatGptHub:错误内容: {ex}");
}Create chat completion
继续更新,在3月1日,Openai公布了GPT-3.5-turbo模型,这个模型的主要功能就是进行chat,并公布了新的api:对话完成。
这个接口收费更低一些,0.002美元1K个token,比达芬奇003便宜了10倍。但是这个模型只能用在chat中,不可以用来做文本完成。
根据我这段时间的分析,我认为之前的AI对话,是模型在完成后续的内容(文本完成),它并不像chat.openai.com那样是在直接对话。
新的这个api我看这个OkGoDoIt 还没有去做,在pull request中,有一位叫megalon的人做好了,正在提交测试,我决定等等。但是在等待之前,我可以通过postman,来进行一下初步的测试。以下是我的测试结果:
可选参数我都没有写,需要的朋友可以自行添加,详见对话完成 API说明
{
"model": "gpt-3.5-turbo",
"stream":true,
"messages": [{"role": "user", "content": "天空是什么颜色的?"}]
}open ai streaming
这是一个使用streaming方式获得OpenAI Chat API的返回内容, 这个明显首次响应会很快, 他毕竟是一个字一个字的返回给我们。
open ai not streaming
这是不使用流,等待所有内容组织好之后返回给我们的,他的缺点就是返回速度很慢,但优点是,你可以知道他是一句话,可以使用TTS接口,将他读出来。