CVPR 2021 Oral | 聊一聊使用NLP语言模型解决场景文本识别中问题的思路以及一些思考...
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
本文作者: Mounty | 来源:知乎
https://zhuanlan.zhihu.com/p/355232006

论文:arxiv.org/abs/2103.06495
代码链接(即将开源):https://github.com/FangShancheng/ABINet
文字识别与自然语言处理NLP
通常来说,无论是裁剪图像的文字识别还是端到端图像的文字识别,主要思想都是把文字识别问题当成CV中的(字符)图像分类问题,比如说传统特征时代检测并分割字符后识别的方法、到CNN共享计算的识别方法、到语义分割识别、甚至到现在主流的CTC方法,其本质上都是基于图像分类的纯CV方法。这种方法,在图像清晰可读的情况下,比如说文档图像、相对规整的手写及场景文本图像等,效果其实都可以做到比较好了(讲白了就是字符的外形清晰可读的情况)。
但场景文本识别中,大部分情况并不是字符外形清晰可读的(至少不是每个字符都可能清晰可读),那这种情况下单纯基于CV的思路就比较乏力了。从简单层面来看,o跟0、i跟l以及中文的未跟末、蓝跟篮,这些字符在外形上都比较接近,使用纯视觉特征进行区分难度比较大。从更常见更复杂的层面来下,比如说下边这些例子...

其实我们人类在识别文字的时候,当一个字符的外形特征无法判别其具体类别时,就会考虑到语言方面的特征。语言特征,就是说考虑字符之间的上下文来推断这个字符的类别,而非基于字符本身的外形特征。为了更好说明视觉特征跟语言特征的区别,这里拿special这个词中的c来举例。视觉特征,就是说根据图像中c的视觉外形,来推测这个字符是c;而语言特征呢,是根据c的上下文spe-ial来推测,这个字符应该是c。传统的方法主要仅考虑视觉特征,即便是使用CNN这种不需要显性分割字符的方法,由于CNN中心感受野的机制,本质上也是在做关于视觉特征的分类;包括CTC的方法在内,虽然使用了RNN在视觉特征层面做上下文建模,但本质上我们依然可以把这类方法划分为基于视觉特征的方法。
在考虑语言建模方面,先前也有不少方法(但其实并没有全面梳理语言建模这个问题,相关方法也没有得到很好的分类)。早期基于统计的n-gram方法以及现在流行的RNN或Transformer使用attention的方法,都可以理解为考虑语言特征的方法(但是不同考虑语言特征的方式有很大不同)。比如说基于attention的方法,本质上是隐性的、单向的语言建模。这里要提醒的一点是,并不是使用了RNN或者使用了Transformer的方法就是做了语言建模,只有形式上符合或部分符合根据spe-ial推理c的才可视为语言建模。比如说按照[1]中的定义,不少方法在CNN后边使用RNN或Transformer做序列建模(Sequence Modeling),这个阶段的其实是视觉特征的上下文建模,而非语言特征的上下文建模。
在我们《Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition》的工作中,围绕如何进行有效地建模语言这个问题展开了一些探索及讨论,总体上的思想就是从NLP字符级别拼写矫正的语言建模角度来思考场景文字识别问题,尤其是针对图像质量退化的这种场景文字识别。这里得再解释下,我们的语言建模主要是character级别的语言建模,而非NLP中更常用的word级别或者token级别的语言建模(尽管算法大部分情况下是通用的)。这也是为什么我们的论文中在描述语言的时候尽量得在使用linguistic而非semantic这个词,因为更准确来说我们是在模拟语言规则方面的特性,而非更高层的语义层。不过我相信,今后也会有不少方法可以实现更高语义层的结合,尤其是在篇章级长文本识别的时候,考虑词的语义是有意义的。
像人一样阅读的文本识别方法
正如文章标题所说的,我们ABINet的三个主要特点就是自治性(Autonomous)、双向性(Bidirectional)以及迭代性(Iterative)。这里分别阐述下三个特性的motivation:
自治性(Autonomous)
上一节说到比较典型的语言建模方法是基于attention的方法,这种方法可以理解为隐性(implicit)的自回归语言建模方法。隐性是指,语言建模的过程是含蓄进行的、是跟视觉模型耦合的、语言模型依赖于视觉特征来做预测的。首先,这种方法自回归的特性保证了其本质上是在做语言建模。其次,这种方法的耦合特性,一方面可解释性较差;另一方面由于语言模型以视觉特征为条件,学习到的语法规则为一种估计值,而非严格按照语言的学习目标进行的:在耦合的条件下,学习目标可以形式化为 ,而在解藕的方式下,却是严格按照语言规则的学习目标来的 ;此外,还有一方面的考虑是,隐性建模的方法中语言特征的学习跟视觉特征的学习是在同一个损失函数下进行的。而前边我们分析了,语言特征跟视觉特征还是有很大差别的,单一目标的损失函数下同时学习视觉特征跟语言特征本身就不够合理,这也是我们组之前在MM 2018[2]论文中使用视觉跟语言多任务损失函数的原因。
2. 双向性(Bidirectional)
上一节也说到标准的基于attention的方法是单向的语言模型,即 ,而双向的语言建模应该是 。传统基于attention方法的单向性是由自回归(auto-regression)的特性决定的。熟悉NLP的同学知道,像GPT这类自回归的语言模型,更适合于生成式的任务。而像BERT这类非自回归的自编码语言模型,在非生成式任务上通常更有效。现在我们的问题是,文字识别任务到底是生成式任务,还是非生成式任务。尽管语音识别跟文字识别有不少相似的地方,但除了模态不一样外,我认为还有一个相当重要的区别就是,语音识别式生成式任务,而文字识别是非生成式任务。
我们再看看传统的方法是怎么做的。ASTER[3]、DAN[4]是标准的RNN下的attention方法,采用标准的串行计算(RNN结构导致的)的自回归方式,为模拟文字识别从前到后以及从后到前的方式,使用两个相同的模型,一个从前往后计算,一个从后往前计算,最后在概率层面做拼接融合。发展到基于Transformer的SRN[5],尽管实现了并行的计算,但是本质上还是自回归的方式,当然SRN为了做到更好的双向,两个集成的模型是在网络最后一层的特征层面做拼接融合,但实际上跟前者没区别。仔细思考下会发现,这种两个自回归模型做拼接集成的方式,且不说参数规模跟计算效率上大打折扣,单个模型做预测时,还是按照 的方式做预测的,因此,只能算是“伪“双向。而在我们的工作中,以上的问题都得到了解决,仅使用单一模型自编码的方式,就实现了真正意义上的双向语言建模。
3. 迭代性(Iterative)
回到最开始的举例,在spe-ial推理c过程中,ASTER和DAN自回归的方法前向的计算过程可以看作是预测 ,如果在前几轮的计算中spe并没有被正确识别,比如说识别成了spc,那么预测c的难度将大很多,而且这种错误会累计到后边的i、a、l的预测中。在SRN中,放弃了这种串行的计算方式,而使用并行的方式。但同样的,如果其他时间步预测错了,同样会影响当前的字符预测。这个问题比较棘手,因为我们不大可能保证其他时间步的预测完全正常。这里我们给出了一种比较好的缓和方案,就是通过语言模型多轮迭代的方式,使得识别结果逐步修正,这样能保证语言模型的输入尽可能受噪声的影响小。
比较有意思的是,我们提出的ABINet在识别文字时,是比较符合人类识别阅读的运作模式的。首先,自治性描述了人脑中视觉的功能跟语言的功能本身具有一定独立性的,一来既能单独识别非语义的物体,也能在丧失视觉功能的情况下正常交流;其次,双向性反应了人类识别字符时同时考虑前边及后本的文字,即融合上下文信息后做决策;最后,迭代性模拟人们在猜测字符时推理的过程,通过逐渐地思考得出结论。当然,以上的猜测是基于观察的,双向性以及迭代性是相对显而易见的,而自治性除非我们完全搞清人脑视觉与语言的交互及学习机制,否则很难证实,当然也有可能二者在结构上是共享的,而在语言及视觉能力上是自治的。
这里再做一个总结,我们总体上的思路是,基于字符级完形填空的语言模型,通过语言修正的方式实现语言建模,其中自治性是描述文字识别模型中语言模型跟视觉模型的交互关系,双向性是描述语言模型自身结构应该满足的特性,而迭代性是描述语言模型的执行方式。我们希望,在这种总体框架下,能比较好的解决复杂场景文字识别问题,当然这种思维在端到端文字识别中是同样使用的,而区别主要在于视觉模型变为一个更强大的带定位功能的模型。
ABINet的主要思想
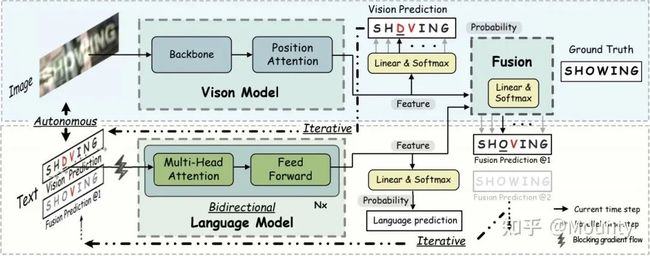 总体框架图
总体框架图
这部分针对ABINet中语言建模的一些关键思想展开介绍:
自治策略
如总体框架图所示,自治性在实现上,就是显性定义视觉模型与语言模型,视觉模型只负责图像分类的功能,而语言模型只负责语言建模的功能。视觉模型与语言模型的交互方式为视觉模型的预测概率分布直接作为语言模型的输入。语言模型的输入为概率向量,并使用线性函数实现概率映射(Probability Mapping)。二者分别使用损失函数进行训练,最终结果进行融合。其中,一个核心的点为视觉模型的输出概率向量到语言模型的输入概率向量,通过梯度阻塞的方式使得视觉模型跟语言模型进行分离,进而实现两个模型作为独立的功能个体进行学习,即实现显性地语言建模型。
这样做的好处其实有很多:
1)解藕之后,视觉模型跟语言模型就互相独立了。语言模型在做语言推理的适合也不再依赖于视觉特征,视觉模型跟语言模型都是独立的个体,比如说语言模型的语言修正功能可以直接使用和单独训练,这个是隐性的方法不具备的。因此,视觉模型可以单独训练(有监督/无监督均可),而语言模型更可以轻易从海量文本中无监督预训练学习。这就是为啥是叫自治的模型,而非解藕的模型。
2)强大的可解释性,我们甚至可以直接评估语言模型的性能,比如我们在实验章节单独针对语言模型展开定量以及可视化定性的评估,在这样的模式下,今后我们可以针对语言模型更加具体的问题提出解决方案。
3)足够的灵活性,一方面今后如果有更优秀的语言模型能代替ABINet中的BCN语言模型,那么可以在不调整其他结构比如视觉模型的前提下直接取代BCN;以及在端到端识别中,只需要替换视觉模型,而语言模型并不需要做改变(甚至已经学习到的模型可以直接拿来做fine-tune),这样成本就低很多了。
4)更好的拓展性,由于我们输入输出都是定义成概率的形式,拓展性就很强了,比如说在我们的框架下可以很简单的实现第三点迭代性的建模。
5)当然,在我的理解下,最大的优势是强迫语言模型真正地学习语言规则方面的建模。不像隐性语言模型那样,可能存在视觉特征作为混杂因子的某种关系导致了模型的偏倚,在反向传播过程中,某条作弊的路径让语言模型的学习是次优的。

这里还有一个比较有意思的问题是,尽管SRN中没注意到,但SRN使用了argmax的方式处理语言建模的输入。在分析之后可知道,argmax的方式本质上是我们这种方法的一种特例,因为argmax操作是不可导的,在这一步的时候直接阻塞了梯度的反向传播。
2. 双向表达
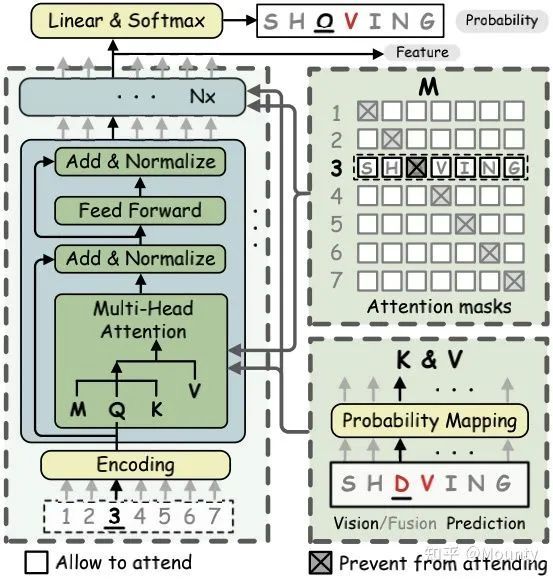 ABINet中双向建模的BCN
ABINet中双向建模的BCN
总体上,BCN(Bidirectional Cloze Network)是一个基于完型填空思想,作拼写矫正的语言模型。实现上是一个 层的Transformer decoder的变种,注意是decoder变种,而非encoder,也不是一些方法使用的encoder+decoder。为了实现双向的建模,BCN在很大程度上跟Transformer又有区别:
1)该网络以字符位置序号编码作为输入,为非字符概率向量。而字符概率向量直接传入multi-head attention模块。
2)网络通过multi-head attention模块中的对角注意力掩码mask控制字符信息的访问。对于第 个时间步的字符来说,注意力机制通过对角mask避免看到当前字符,且实现同时访问该字符左边及右边的信息,并综合左边及右边的信息同时做出预测。
3)为了避免信息泄露,传统Transformer decoder中的自注意模块self-attention并没有在BCN中使用,这样避免了跨时间步上的信息访问。因此BCN的每个时间步的计算均为独立且并行的,也具有高效的特点。
P.S:3)这一点是很关键的一点,设想下如果第 时间步尽管在网络输入的时候没有看到前后时间步的信息,但却在self-attention跨时间步的信息交互上看到了前后时间步的信息,那么语言模型就不需要费劲去预测了,只需要直接将‘偷看’的信息恒等映射即可,如果有self-attention,效果立竿见影地降低,这也是一些基于Transformer的方法效果不好的原因(这部分本应该在实验中体现的,原谅我这部分我觉得理所应当,当时没有记录下数据, = . =)。此外,1)中也不能将字符概率向量作为BCN的直接输入,仔细揣摩下会发现这种情况下Transformer的残差连接也会信息泄漏。因此,BCN的一切,都是为了精准实现 这个公式。
在论文中,我们从特征提取时信息熵值的角度分析单向特征跟BCN双向特征的区别。我们相信这种双向的特征能更加全面的实现拼写矫正的过程,正如BERT中介绍的那样。因此,BCN的这种方法可以学到比单向模型更好的特征表达,并且比两个单向模型拼接集成的方式无论是参数规模还是计算效率都更有优势。
说到BERT,还得对比下BCN跟BERT的区别。最开始我们是想直接使用BERT做语言建模的,因为BERT可是双向语言建模中的王牌。BCN跟BERT都是为了做双向建模,但机制上却有很大的不同。BERT的方式是将输入文本中的一个字符替换成[Mask]符号做预测,因此一次BERT的计算只能预测一个字符的结果。假设识别一个长度为 的文本串,那么BERT就得预测 次,这样的计算成本几乎是不可行的。除了BERT外,最开始我们的实验中,还尝试了不少复杂的NLP模型,比如说先检测错误预测字符,再计算编辑距离模拟增删改来实现拼写矫正的过程,这类方法模型复杂度大大提升,计算效率低下但却效果不够明显,在失败了很多次之后,我们痛定思痛决定朝模型既简单又有效的方向思考,所以才会有BCN这样的设计。
3. 迭代修正
如总体框架图所示,迭代修正的思想为反复多轮执行语言模型,使得识别的效果逐步修正。在我们这个框架下,语言模型在第一轮修正的目标为视觉模型的输出结果,而在第二轮及多轮以后修正的目标为上一轮ABINet的输出结果。这种方法巧妙的地方就在于,不需要修改任何其他的定义或结构,就能实现反复迭代了。并且,网络在非迭代的方式下训练,直接在推理阶段迭代,也是有效的!当然,我们跑的实验来看,训练阶段迭代效果更好些。但得注意的是,迭代的方法也得看使用的场景,通常来说针对hard的样本效果才明显,easy的场景用处就没那么大了。比如说在实际工程中,甚至可以这样去做,如果识别结果的置信度比较低,就反复多轮迭代,置信度比较高,就没必要迭代了。
文中还提出了一种基于自训练的半监督学习方法,有兴趣的同学可以参考下原文,算是尝试一些新的思路吧,毕竟感知识别的深度学习方法还是数据为王。
模型其他部分的细节请阅读原文…
算法效果
首先给出部分定性的分析结果,一个是迭代方式下的中间结果、一个是在Uber-Text上半监督训练的学习的结果。
 依次:GT,第一轮迭代、第二轮迭代、第三轮迭代
依次:GT,第一轮迭代、第二轮迭代、第三轮迭代  半监督训练下识别结果
半监督训练下识别结果
2. 训练的过程便是分别预训练视觉及语言模型,作为ABINet的初始化参数进一步学习,其他细节参考原文。多种配置下跟其他方法的对比:
 Ours:小视觉模型/大视觉模型/半监督学习
Ours:小视觉模型/大视觉模型/半监督学习
3. 这里也很感谢SRN作者Deli小哥在我们复现SRN代码时的鼎力相助。
参考文献
[1] Jeonghun Baek, Geewook Kim, Junyeop Lee, Sungrae Park, Dongyoon Han, Sangdoo Yun, Seong Joon Oh, and Hwalsuk Lee. What is wrong with scene text recognition model comparisons? dataset and model analysis. ICCV 2019.
[2] Shancheng Fang, Hongtao Xie, Zheng-Jun Zha, Nannan Sun, Jianlong Tan, and Yongdong Zhang. Attention and language ensemble for scene text recognition with convolutional sequence modeling. ACM Multimedia 2018.
[3] Baoguang Shi, Mingkun Yang, Xinggang Wang, Pengyuan Lyu, Cong Yao, and Xiang Bai. Aster: An attentional scene text recognizer with flexible rectification. IEEE TPAMI 2018.
[4] Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, Canjie Luo, Xiaoxue Chen, Yaqiang Wu, Qianying Wang, and Mingxiang Cai. Decoupled attention network for text recognition. AAAI 2020
[5] Deli Yu, Xuan Li, Chengquan Zhang, Tao Liu, Junyu Han, Jingtuo Liu, and Errui Ding. Towards accurate scene text recognition with semantic reasoning networks. CVPR 2020.
下载
后台回复:CVPR2021,即可下载代码开源的论文合集
重磅!CVer-OCR交流群成立
扫码添加CVer助手,可申请加入CVer-OCR 微信交流群
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如OCR+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加小助手微信,进交流群
▲点击上方卡片,关注CVer公众号
整理不易,请给CVer点赞和在看