Spark RDD&算子 基本操作
1.RDD
Spark提供了两种创建RDD的方式:
(1)由一个已经存在的Scala集合进行创建。
(2)由外部存储系统的数据集创建,包括本地的文件系统,还有所有Hadoop支持的数据集,比如HDFS、Cassandra、HBase等。
1.1读取文件
textFile()
val rdd = sc.textFile("/home/student.txt")//文件路径
1.2集合创建RDD
Spark会将集合中的数据拷贝到集群上去,形成一个分布式的数据集合,也就是一个RDD。相当于是,集合中的部分数据会到一个节点上,而另一部分数据会到其他节点上。然后就可以用并行的方式来操作这个分布式数据集合,即RDD。
parallelize()
val list=List(1,2,3,4,5)
val stu=sc.parallelize(list,3)//参数1:Seq集合,必须。参数2:分区数,默认为该Application分配到的资源的CPU核数
//val stu=sc.makeRDD(list,3) //和parallelize用法一样。(该用法可以指定每一个分区的preferredLocations)。
val sum=stu.reduce(_+_)
println(sum)
2.转换算子
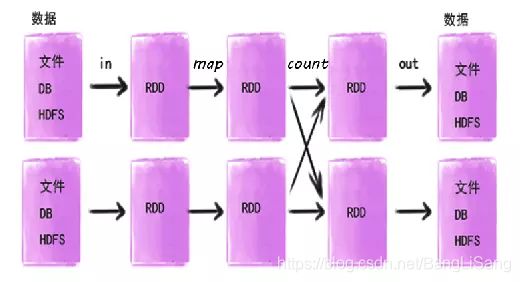
算子的作用
如下图描述了Spark的输入、运行转换、输出。在运行转换中通过算子对RDD进行转换。算子是RDD中定义的函数,可以对RDD中的数据进行转换和操作。
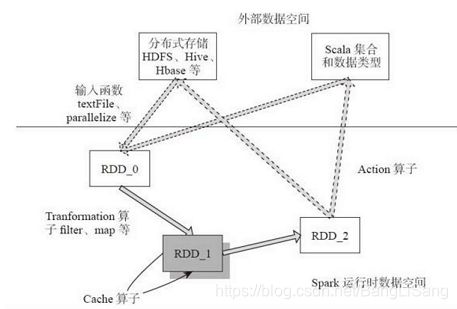
输入:在Spark程序运行中,数据从外部数据空间(如分布式存储:textFile读取HDFS等,parallelize方法输入Scala集合或数据)输入Spark,数据进入Spark运行时数据空间,转化为Spark中的数据块,通过BlockManager进行管理。
运行:在Spark数据输入形成 RDD后便可以通过变换算子,如fliter等,对数据进行操作并将RDD转化为新的RDD,通过Action算子,触发Spark提交作业。如果数据需要复用,可以通过Cache算子,将数据缓存到内存。
输出:程序运行结束数据会输出Spark运行时空间,存储到分布式存储中(如saveAsTextFile输出到HDFS),或Scala数据或集合中( collect输出到Scala集合,count返回Scala int型数据)。
算子的分类
从大方向来说,算子可以分为Transformation转换算子和Action行动算子。
#####Transformation 转换算子:
如map,flatMap,reduceByKey,mapValues等。
Transformation操作是延迟计算的,也就是说从一个RDD转换生成另一个 RDD的转换操作不是马上执行,需要等到有Action操作的时候才会真正触发运算。
Action 行动算子:
如count,take,collect,reduce,saveAsTextFile等。
每遇到一个这种算子就会触发SparkContext提交Job作业。
2.1map
==map(func)==将函数应用于RDD中的每个元素,将返回值构成新的RDD,示例如下:
val list=List(1,2,3)
val rdd=sc.parallelize(list)
val rdd1=rdd.map(x=>x+1)
rdd1.foreach(println)
2
3
4
说明:rdd.map(x=>x+1)表示将rdd中的每个元素x加1得到新的rdd1(2,3,4)
2.2distinct
==distinct()==去重
val list=List(1,2,3,2,3)
val rdd=sc.parallelize(list)
val rdd1=rdd.distinct()
rdd1.foreach(println)
1
3
2
说明:表示将rdd(1,2,3,2,3)通过rdd.distinct()对元素去重,生成新的rdd1(1,2,3)
2.3flatMap
==flatMap(func)==将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD.
val list=List(1,2,3)
val rdd=sc.parallelize(list)
val rdd1=rdd.flatMap(x=>x.to(3))
rdd1.foreach(println)
1
2
3
2
3
3
说明:flatMap与Map的区别,map函数会对每一条输入进行指定操作,然后为每一条输入返回一个对象;而flatmap函数则是两个操作的集合,最后将所有对象合并为一个对象
2.4filter
==filter(func)==筛选出满足函数的元素,并返回一个新的RDD.
val list=List(1,2,3)
val rdd=sc.parallelize(list)
val rdd1=rdd.map(x=>x+1)
val rdd2=rdd1.filter(x=>x>2)
rdd2.foreach(println)
3
4
2.5reduceByKey
==reduceByKey(func)==应用于(k,v)键值对RDD,对相同key的value进行运算.
val list=List((3,2),(1,4),(2,5),(2,8))
val rdd=sc.parallelize(list)
val rdd2= rdd.reduceByKey(_+_)
rdd2.foreach(print)
(1,4)
(3,2)
(2,13)
.reduceByKey((x,y)=>(x._1+y._1,x._2+y._2))
说明:rdd.reduceByKey(+)表示将相同key的value进行累加,传入两个参数(例:5和8)返回一个值(13)。
2.6mapValues
==mapValues(func)==应用于(k,v)键值对RDD,对RDD中的value进行map操作,而不对key进行处理。
val list=List((3,2),(1,4),(2,5),(2,8))
val rdd=sc.parallelize(list)
val rdd2= rdd.reduceByKey(_+_)
val rdd3=rdd2.mapValues(x=>x*2)
rdd3.foreach(print)
(1,8)
(3,4)
(2,26)
.mapValues(x=>(x._1,x._1*x._2))
2.7groupByKey
groupByKey应用于(k, v)键值对RDD,对具有相同key的value值进行分组。
val list=List((3,2),(2,5),(2,8))
val rdd=sc.parallelize(list)
val rdd1=rdd.groupByKey()
rdd1.foreach(println)
(3,CompactBuffer(2))
(2,CompactBuffer(5, 8))
说明:如果您分组是为了对每个键执行聚合(如求和或求平均值),使用reduceByKey或aggregateByKey会产生更好的性能。
2.8sortByKey
==sortByKey()==应用于(k, v)键值对 RDD,返回一个新的根据key排序的 RDD.
val list=List((3,2),(2,5),(2,8))
val rdd=sc.parallelize(list)
val rdd1=rdd.groupByKey()
val rdd2= rdd1.sortByKey()
rdd2.foreach(println)
(2,CompactBuffer(5, 8))
(3,CompactBuffer(2))
3.行动算子
3.1count
==count()==返回RDD中元素的个数。
val list=List(3,4,5,8)
val rdd=sc.parallelize(list)
val r1=rdd.count();
println(r1)
4
3.2take
==take(n)==以数组的形式返回RDD中的前n个元素。
val list=List(3,4,5,8)
val rdd=sc.parallelize(list)
val rdd1= rdd.take(3)
rdd1.foreach(println)
3
4
5
3.3reduce
==reduce(func)==通过函数func(输入两个参数并返回一个值)聚合 RDD 中的元素。
val list=List(3,4,5,8)
val rdd=sc.parallelize(list)
val rdd1=rdd.reduce(_*_)
println(rdd1)
480
3.4collect
==collect()==以数组的形式返回 RDD 中的所有元素,收集分布在各个worker的数据到driver节点。
val list=List(3,4,5,8)
val rdd=sc.parallelize(list)
val rdd1= rdd.collect()
rdd1.foreach(println)
3
4
5
8
3.5saveAsTextFile
saveAsTextFile将数据输出,存储到指定目录。
val list=List(3,4,5,8)
val rdd=sc.parallelize(list)
rdd.saveAsTextFile("C:\\Users\\admin\\Desktop\\test")
结果将会被保存到以上目录下,该目录下有以下文件:

3.6foreach
==foreach(func)==将RDD中的每个元素传递到函数func中运行,与map的区别是无返回值。
rdd.take(3).foreach(println)