Basic CNN - Pytorch
笔记来自课程《Pytorch深度学习实践》Lecture 10
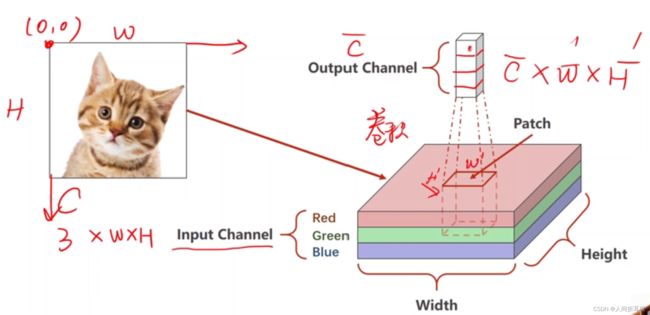
如下图所示,在做全联接的时候,把图片(1*28*28,即C*W*H)全部都拉成了一长串(1*...),所以卷积层是为了保留它的空间特征。
下采样时通道数C不变,下采样是为了减少数据量,从而减轻运算负担。
我们把卷积和下采样这部分称为“特征提取器”,即Feature Extraction。

做了卷积之后,它的C和W和H都有可能会发生改变。
左上角为图片坐标的原点。
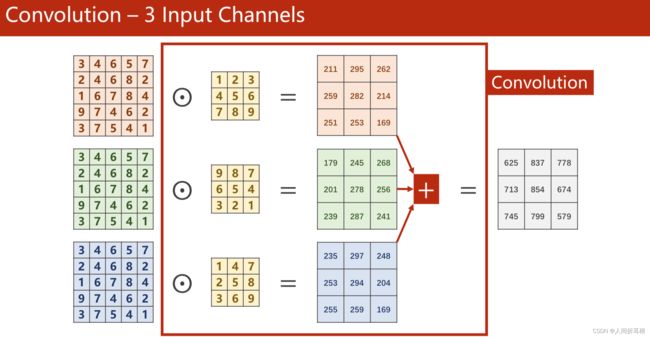
3通道的卷积,如下图所示。每一个通道都要 配一个核。

如果你的输出需要m个通道,那你就需要准备m个卷积核,最后把m个1*W'*H'的矩阵cat起来,得到一个m*W'*H'的矩阵:
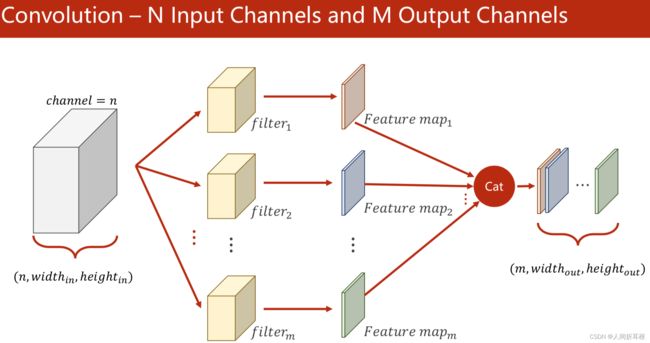 每一个卷积核的通道数要求与输入数量一致,卷积核的个数与输出通道数一致。
每一个卷积核的通道数要求与输入数量一致,卷积核的个数与输出通道数一致。

import torch
in_channels, out_channels= 5, 10
width, height = 100, 100 # 图片的大小
kernel_size = 3
batch_size = 1
input = torch.randn(batch_size,
in_channels,
width,
height)
conv_layer = torch.nn.Conv2d(in_channels, # n
out_channels, # m
kernel_size=kernel_size)
output = conv_layer(input)
print(input.shape)
print(output.shape)
print(conv_layer.weight.shape)kernel_size - 卷积核的大小,3的话就是默认3*3,也可以传入元祖,如(5,5)
最终输出结果为
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])
卷积层 - padding

3*3的就padding一圈,5*5就2圈,3/2 = 1,5/2 = 2
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5) # (Batch, C, W, H)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False)
kernel = torch.Tensor([1,2,3,
4,5,6,
7,8,9]).view(1, 1, 3, 3) # (输入通道数, 输出通道数, W, H)
conv_layer.weight.data = kernel.data # 卷积层权重的初始化
output = conv_layer(input)
print(output)input = torch.Tensor(input).view(1, 1, 5, 5) - input(batch, 通道数, width, height)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3) - (输出通道数,输入通道数,kernel宽度,kernel高度)
conv_layer.weight.data = kernel.data - 为卷积层的权重做一个初始化
卷积层 - 步长stride
import torch
input = [3,4,6,5,7,
2,4,6,8,2,
1,6,7,8,4,
9,7,4,6,2,
3,7,5,4,1]
input = torch.Tensor(input).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False)
kernel = torch.Tensor([1,2,3,4,5,6,7,8,9]).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data
output = conv_layer(input)
print(output)MaxPooling Layer
最大池化层,它是没有权重的,2*2的池化层,默认stride = 2。做MaxPooling通道数不变,但是在下图中,图片缩小为为原来的一半。
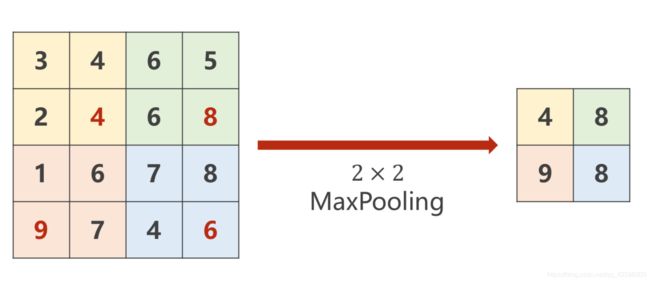
import torch
input = [3,4,6,5,
2,4,6,8,
1,6,7,8,
9,7,4,6]
input = torch.Tensor(input).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2)
output = maxpooling_layer(input)
print(output)一个简单的CNN结构

第一个卷积层,用5*5的卷积,要小2圈,所以28-4 = 24
注意:在最后的分类器那一层,一定要算出来最终的元素个数,本例中是320

在fc之前,要做一个view,把20*4*4变成320. 然后fc把320直接降成10维.
pooling是没有权重的,所以有一个实例就行,like激活函数.
代码如下:
class Net(torch.nn.Module): def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# Flatten data from (n, 1, 28, 28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
x = x.view(batch_size, -1) # flatten
x = self.fc(x)
return x
model = Net()使用GPU运行:
首先,要把模型迁移到GPU,在model = Net()后面增加下面两行代码:
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)第一行 - Define device as the first visible cuda device if we have CUDA available.
第二行 - Convert parameters and buffers of all modules to CUDA Tensor.
接下来,把张量迁移到GPU,在train中增加inputs, target = inputs.to(device), target.to(device),目的是Send the inputs and targets at every step to the GPU.
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target) loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 2000))
running_loss = 0.0在test中也做类似的修改:
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
outputs = model(inputs)
_, predicted = torch.max(outputs.data, dim=1)
total += target.size(0)
correct += (predicted == target).sum().item()
print('Accuracy on test set: %d %% [%d/%d]' % (100 * correct / total, correct, total))