rknn的后处理代码分析
最近有个活儿, 终于有机会细研究了一下rknn的后处理部分.
如你所知, yolo模型有3个维度的输出:
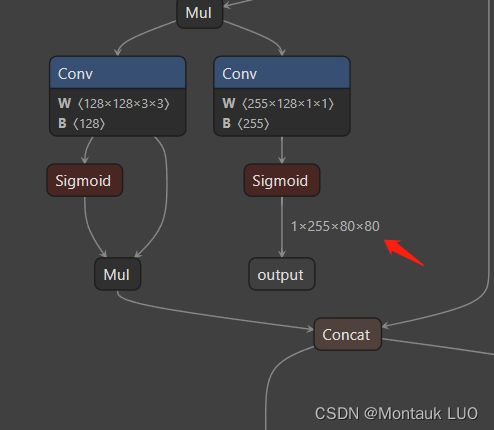
其中一个如上图, 1x255x80x80, 80x80表示把640x640的图像输入分成了80x80个格子:

例如, 上面这个图, 首先会加灰边, 因为原图不到640x640, 宽度不够, 所以两边加上灰边, 然后每8个像素, 组成一个格子, 一共是80x80个格子, 后面称之为grid_cell, 当然还有其他2个维度, 40x40跟20x20, 先说这个维度:

当rknn的模型正向推理完成之后, 即调用
ret = rknn_run(ctx, NULL);
就会形成三个output, 经过一个色彩通道顺序调整后, output_mems_nchw[0], output_mems_nchw[1], output_mems_nchw[3], 即三个维度的输出数据, 其中output_mems_nchw[0]就是基于80x80个预测框的, 学名叫bounding boxes, 或者prediction boxes,
同时传入的还有图像的宽高, 预测框的置信度阈值(是个预设的固定值), nms的阈值(也是固定值), 以及图像跟预测框的缩放比例, 方便将来形成结果的时候, 计算xy,wh值到图像尺度.最后两个值用于做量化.
post_process(output_mems_nchw[0], output_mems_nchw[1], output_mems_nchw[2], IMAGE_INPUT_WIDTH, IMAGE_INPUT_HEIGHT, box_conf_threshold, nms_threshold, scale_w, scale_h, out_zps, out_scales);
重点就是研究这个后处理函数post_process
// stride 8
int stride0 = 8;
int grid_h0 = model_in_h / stride0;
int grid_w0 = model_in_w / stride0;
int validCount0 = 0;
validCount0 = process(input0, (int *)anchor0, grid_h0, grid_w0, model_in_h, model_in_w,
stride0, filterBoxes, objProbs, classId, conf_threshold, qnt_zps[0], qnt_scales[0]);
stride即跨度, 也就是每个预测框的宽度/高度.
先验anchor的长宽是个固定值, 例如当stride为8的时候, 使用:
const int anchor0[6] = {10, 13, 16, 30, 33, 23}; 当跨度为8的时候, 这3个锚框(两个值分别代表宽高)分别去框定相对方形, 瘦高型, 矮胖型(比如我)的物体,
grid_h0, grid_w0, 即80, 80, 预测框的宽高,
validCount非常重要, 就是在80x80这个维度, 所有预测框中超过置信度阈值的总个数.
接下来看看process函数:
static int process(int8_t *input, int *anchor, int grid_h, int grid_w, int height, int width, int stride,
std::vector<float> &boxes, std::vector<float> &objProbs, std::vector<int> &classId,
float threshold, int32_t zp, float scale)
{
int validCount = 0;
int grid_len = grid_h * grid_w;
float thres = unsigmoid(threshold);
int8_t thres_i8 = qnt_f32_to_affine(thres, zp, scale);
for (int a = 0; a < 3; a++)
{
for (int i = 0; i < grid_h; i++)
{
for (int j = 0; j < grid_w; j++)
{
int8_t box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j];
if (box_confidence >= thres_i8)
{
int offset = (PROP_BOX_SIZE * a) * grid_len + i * grid_w + j;
int8_t *in_ptr = input + offset;
float box_x = sigmoid(deqnt_affine_to_f32(*in_ptr, zp, scale)) * 2.0 - 0.5;
float box_y = sigmoid(deqnt_affine_to_f32(in_ptr[grid_len], zp, scale)) * 2.0 - 0.5;
float box_w = sigmoid(deqnt_affine_to_f32(in_ptr[2 * grid_len], zp, scale)) * 2.0;
float box_h = sigmoid(deqnt_affine_to_f32(in_ptr[3 * grid_len], zp, scale)) * 2.0;
box_x = (box_x + j) * (float)stride;
box_y = (box_y + i) * (float)stride;
box_w = box_w * box_w * (float)anchor[a * 2];
box_h = box_h * box_h * (float)anchor[a * 2 + 1];
box_x -= (box_w / 2.0);
box_y -= (box_h / 2.0);
int8_t maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k)
{
int8_t prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs)
{
maxClassId = k;
maxClassProbs = prob;
}
}
if (maxClassProbs > thres_i8)
{
boxes.push_back(box_x);
boxes.push_back(box_y);
boxes.push_back(box_w);
boxes.push_back(box_h);
objProbs.push_back(sigmoid(deqnt_affine_to_f32(maxClassProbs, zp, scale)) * sigmoid(deqnt_affine_to_f32(box_confidence, zp, scale)));
classId.push_back(maxClassId);
validCount++;
}
}
}
}
}
return validCount;
}
输出结果的数据排列, 类似下面这样:
0: 640个floatx3anchor
1: 640个floatx3anchor
2: 640个floatx3anchor
3: 640个floatx3anchor
…
84: 640个floatx3anchor
前面4个640x3 float单位数据, 分别是640x3个预测框的x,y, w, h, 3个的原因是每个预测框有3个anchor.
接着个第五个640x3, 就是目标物的置信度, box_confidence, 这个置信度是objectness的置信度, 表示属于这80个可识别的类别的置信度.
接着是80个类别分别的置信度, 比如它觉得这个框里面有猫的信心为0.7, 是狗的信心是0.4, 是个车的概率是0.1 那么大概率里面是个猫, 但是也有可能是狗, 不太可能是个车.
后处理就是处理这些数据
int8_t box_confidence = input[(PROP_BOX_SIZE * a + 4) * grid_len + i * grid_w + j];
if (box_confidence >= thres_i8)
{
这段是表示, 根据物体置信度的一个固定阈值, 把低于这个阈值的预测框都扔掉, 以上面的例子来说, 如果置信度阈值为0.35, 那么, 预测为猫/狗的框都被保留, 但是预测为车的框就会被扔掉.
接着:
int8_t maxClassProbs = in_ptr[5 * grid_len];
int maxClassId = 0;
for (int k = 1; k < OBJ_CLASS_NUM; ++k)
{
int8_t prob = in_ptr[(5 + k) * grid_len];
if (prob > maxClassProbs)
{
maxClassId = k;
maxClassProbs = prob;
}
}
这就对80个类别的预测结果做个排序, 拿到这个预测框所有80类别中, 它的置信度最高的那个结果, 比如还是上面的例子, 猫是0.7, 狗是0.4, 那么就认为这个预测框的置信度为0.7, 且类别为猫.其他类别都抛弃.
保留的动作就是用vector的push方法, 把这个框的宽高跟anchor做一个运算, 拿结果作为预测框的宽高, 当作输出box, 即输出box其实是某
这里面注意以下几点
- 输出box其实跟anchor是密切相关的, 本质上可以理解成anchor的框经过缩放比例计算, 就是最终呈现的大家看到的yolo画的结果框.
- 由于anchor有3个, 所以不排除同一个grid cell里面, 3个anchor的置信度都超过阈值, 属于或者不属于同一个物体, 比如下面这个图中红色框对应的grid_cell, 有3个anchor, 置信度都超过阈值, 那么最终会有3个box被push到结果列表中, 后面会使用nms方法去掉其中的两个, 保留一个.

- 结果置信度, 其实是一个物体置信度跟类别置信度的一个乘积, 就是个贝叶斯概率, 即它是个物体的情况下, 是猫的概率, 比如你觉得它8成(0.8)是个80分类中的某个东西, 同时又觉得它是猫的概率是0.7, 那么最终的结果置信度, 就是objProbs的结果就是0.8*0.7=0.56.
// stride 8
int stride0 = 8;
int grid_h0 = model_in_h / stride0;
int grid_w0 = model_in_w / stride0;
int validCount0 = 0;
validCount0 = process(input0, (int *)anchor0, grid_h0, grid_w0, model_in_h, model_in_w,
stride0, filterBoxes, objProbs, classId, conf_threshold, qnt_zps[0], qnt_scales[0]);
// stride 16
int stride1 = 16;
int grid_h1 = model_in_h / stride1;
int grid_w1 = model_in_w / stride1;
int validCount1 = 0;
validCount1 = process(input1, (int *)anchor1, grid_h1, grid_w1, model_in_h, model_in_w,
stride1, filterBoxes, objProbs, classId, conf_threshold, qnt_zps[1], qnt_scales[1]);
// stride 32
int stride2 = 32;
int grid_h2 = model_in_h / stride2;
int grid_w2 = model_in_w / stride2;
int validCount2 = 0;
validCount2 = process(input2, (int *)anchor2, grid_h2, grid_w2, model_in_h, model_in_w,
stride2, filterBoxes, objProbs, classId, conf_threshold, qnt_zps[2], qnt_scales[2]);
3个维度, 分别做了process, 并代入了三个尺度的各anchor, 看一眼anchor的数据:
const int anchor0[6] = {10, 13, 16, 30, 33, 23};
const int anchor1[6] = {30, 61, 62, 45, 59, 119};
const int anchor2[6] = {116, 90, 156, 198, 373, 326};
你会发现, stride越大, anchor的尺寸就越大(好像是废话, 但是证明是吻合的). 再说一遍anchor的数据是{10, 13, 16, 30, 33, 23}, 代表, 10, 13 是中间一个几乎正方形的框, 16, 30是个瘦高的框, 33, 23是个矮胖的框, 跟8x8的图像的关系你想象一下就知道了.
int validCount = validCount0 + validCount1 + validCount2;
// no object detect
if (validCount <= 0)
{
return 0;
}
接着把3个维度的结果加起来, 这个时候你要有个概念, 目前的结果其实有非常的多, 包含了, 可能一个grid_cell里面就有3个anchor框分别觉得自己框里面有个猫, 然后在差不多同一个区域的其他grid_cell也发现了猫, 同时, 在更大的维度, 也可以发现猫, 借下面这个图, 你理解一下:

当然在3个尺度上, 都能识别出是狗的概率是比较小的, 但是越小的物体, 的确是可能被两个维度或以上的预测框都预测到, 但是这不是不问题, 因为接下来就要用非极大值抑制来选出最合适的预测框.
首先这个nms为啥要翻译成非极大值抑制, 其实就是直译, non-maximum suppression, 就是有话不好好说, 装杯的一种叫法, 翻译成中文, 那就是取最大值, 接下来我就直接用取最大值或者直接用nms缩写来代替.
在做nms之前,先要把前面3个维度的处理结果box做点准备工作:
std::vector<int> indexArray;
for (int i = 0; i < validCount; ++i)
{
indexArray.push_back(i);
}
这里很简单, 就是根据validCount数量, 做一个排序的用索引列表, 内容就是从0到validCount-1, 如果你三个维度一共查出来预测框是56个, 那么这里indexArray就是0-55的一个int数组(列表)
quick_sort_indice_inverse(objProbs, 0, validCount - 1, indexArray);
这一步的意思就是, 根据置信度objProbs, 对indexArray做一个排序.
那么原本indexArray的内容0, 1, 2,3, 4,…(validCount-1)
排完序之后, indexArray的内容就变成了可能6, 9, 11, 3, 43…而排第一个的6, 就是那个目前所有结果box中, 置信度最高的那个box对应的index. 因为box是个vector, 并不是map数据类, 我不是太清楚cpp有没有map数据类型, 如果你熟悉一些高级语言就会发现, 这就是一个对map list的根据value的一个排序而已.
或者简单点, 理解成, 对所有目前的box, 无论什么维度, 属于哪个grid_cell, 预测的class属于哪个, 都进行了从高到低的排序, 由于box本身是个vector, 可能类似链表吧, 不方便排序, 所以使用indexArray保存的这个排序的结果, indexArray中, 排第一个的值, 就是box中objectProbs最高的那个的数组下标.
如果还是没讲明白, 那就重复看两次吧, 我觉得没法更清楚了, 要想更清楚, 你把indexArray的内容, 在排序前后分别打印一下结果出来就明白了.

上图中, validCount是24, 代表又24个预测框通过了置信度阈值, 你可能要问, 我设置的置信度阈值明明是0.35啊, 为啥后面几个都低于0.35都被push到vector里面了? 因为如我上面所说, 这个objProbs, 是贝叶斯概率, 是两个物体置信度跟分类置信度的乘积.
可以看到, objProbs是从大到小排列好的.
接下来, 就是把目前这24个box的class, 做一个set出来, cpp里面已经有set的概念了,set其实就是不重复的一个列表, 就是去重了, 所以你看到, 原本每个box都包含一个class分类, 但是总共的分类数量只有4种, 0, 39, 56, 65, 也就是说, 打个比方, 我第2, 4,9,22,个预测box, 都觉得自己是猫,而3, 5,7, 预测框, 都觉得自己里面有狗, 综合起来, 整个图像里面, 一共出线的可识别的分类就是2个, 猫/狗, 把这两个分类, 做成一个class_set:
std::set<int> class_set(std::begin(classId), std::end(classId));
接着就是, 分别拿出这几个分类, 来做nms, 也就是说, 每次只对一个分类, 做nms, 即, 所有认为自己有猫在里面的box, 大家来比比, 跟置信度最高的那个框, 比比IOU
比如下面这个柠檬, 可能被同一个gird_cell的几个不同的anchor的置信度都过了阈值, 那么就看看他们跟置信度最高的那个box之间的IOU关系如何.

for (auto c : class_set)
{
// 对每一个类比如person做非极大值抑制
printf("class %d\n", c);
nms(validCount, filterBoxes, classId, indexArray, c, nms_threshold);
}
nms的具体过程, 其实核心就下面这句:
float iou = CalculateOverlap(xmin0, ymin0, xmax0, ymax0, xmin1, ymin1, xmax1, ymax1);
即, 将所有的认为自己是这个类别的框, 都相互比较IOU, 就是交并比, 交并比的意思就是两个区域到底有多重合, 这个值越高说明, 这两个区域差不多是同一个区域.
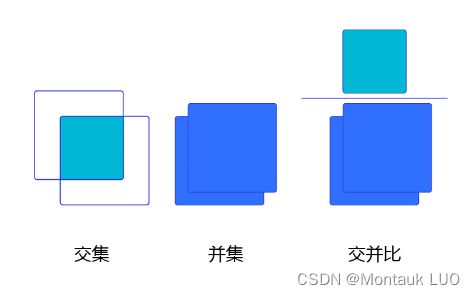
当你交并比足够低的时候, 就可以认为画面中的物体时同一类, 但是不是同一个, 跟上面的一个柠檬不同, 下面有三个斑马, 但是他们不是同一个斑马.:

if (iou > threshold)
{
order[j] = -1;
}
对于交并比超过某个阈值(这个叫做nms_阈值), 我们就可以视为两个区域是同一个区域. 不加入最终结果框列表之中.
比较过程如下图:

如果有4个box, 就比较5轮就可以了.
将昨晚nms之后的预测框, 还原到图像尺度, 限制边界, 之后就是预测框了.
总结一下, 整个过程, 第一步, 将rknn的三个尺度的结果, 分别提取出来, 例如这个图中的所有grid_cell的3个anchor的正向传播计算结果, 先拿物体置信度阈值过滤一遍, 再拿出每个gride_cell的的80类别的置信度, 排序之后, 保留最大的那个, 再过一遍分类置信度, 在这里, 跟物体置信度是同一个阈值, 低于这个阈值的丢掉, 然后两个置信度相乘, 作为这个grid_cell的objetcProb, 而最大的置信度的类比, 作为这个grid_cell的分类标签.

第二步, 前面原来的640x640+320x320+160x160个grid_cell, 经过置信度阈值之后, 可能就剩下几十个置信度足够高的grid_cell了, 他们可能是同一个物体在不同的grid_cell, 所以要做一个nms, 取最大值, 就是找到这个物体最应该属于哪个预测框. 而丢掉其他的周围的同标签的置信度更低的框, 之所以你在实际实践的过程中, 看到预测框在画面中轻微的跳动, 就是因为同一个物体被两个差不多置信度的grid_cell来回的抢夺结果造成的.
制造强则中国强, 诸君努力!