订单正向链路压测
这次压测会对正向链路中的生订单号、生成订单、预支付、支付回调四个接口做压测,其他接口或逆向接口并发要求不高,所以不做压测。
1、100并发压测4核8G(初步压测,看代码是否有问题)
压测结果: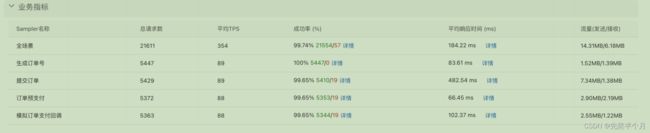 可以看到,生成订单接口的请求成功率为100%,而提交订单、订单预支付、支付回调接口的成功率都是99.65%,且每个接口的TPS(每分钟处理的事务数)为89左右,其中响应时间比较耗时的是提交订单接口(该接口比较复杂所以很正常)
可以看到,生成订单接口的请求成功率为100%,而提交订单、订单预支付、支付回调接口的成功率都是99.65%,且每个接口的TPS(每分钟处理的事务数)为89左右,其中响应时间比较耗时的是提交订单接口(该接口比较复杂所以很正常)
此时除了生成订单号之外的接口都有失败的情况,我们可以看看具体是什么错误。
1)、先看提交订单接口:
![]() 发现是扣减商品库存失败。那这个时候我们去看看数据库的数据是不是真的扣减失败了。
发现是扣减商品库存失败。那这个时候我们去看看数据库的数据是不是真的扣减失败了。
此时就可以知道真的扣减失败了。我们来看下扣减库存时我们的处理是怎么样的。
提交订单接口的逻辑:
1)、入参检查
2)、风控检查
3)、查询数据库,获取商品信息
4)、计算订单价格
5)、验证订单实付金额
6)、生成订单
7)、发送延迟消息用于支付超时自动关单
扣减库存在第6)点,我们看看第6点逻辑:
使用seata AT模式控制下面三个步骤
(1)、锁定优惠券
(2)、扣减库存
(3)、生成订单到数据库
再看看第2步,扣减库存是在AT的模式下,混用TCC模式。看看扣减库存的处理逻辑:
(1)、入参检查
(2)、查询mysql库存数据、查询redis库存数据
(3)、以订单号+sku Id为key做分布式锁防止并发
(4)、查询是否有扣减日志,有则不做重复扣减
(5)、执行库存扣减(TCC模式)
我们可以看到如果扣减失败只能存在第3、5步,先看第三步,第三步的设计是存在问题的,用订单号+sku作为分布式锁的key,此时可以防止同一订单中同一sku的并发问题,可是我们的需求是要做的不同订单的sku的并发问题,所以我们可以初步判断,库存数据错误可能就是分布式锁粒度的问题。此时我们就把key改为sku id再做一次压测。
----------------------------------------------修改完分布式锁key粒度后的压测分析
压测后查看数据:
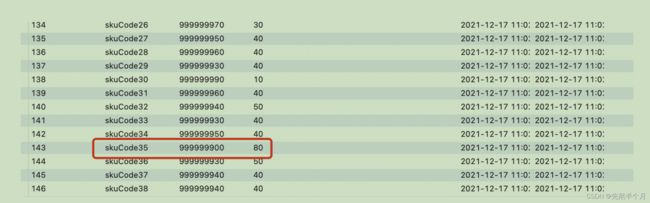 发现仍然有数据错误,此时我们再去看第(5)步执行库存扣减(TCC模式)。看下处理逻辑
发现仍然有数据错误,此时我们再去看第(5)步执行库存扣减(TCC模式)。看下处理逻辑
TCC的分支:1、扣减mysql库存 2、扣减redis库存
扣减mysql库存逻辑:
1)、try阶段:执行扣减库存数量
update inventory_product_stock
set sale_stock_quantity = sale_stock_quantity - #{saleQuantity}
where sku_code = #{skuCode}
and sale_stock_quantity >= #{saleQuantity}
and sale_stock_quantity = #{originSaleStock}
这里只对可售库存做扣减,而没有对已售库存做增加(放在commit阶段,为了模拟数据错乱问题)
2)、commit阶段:增加已售库存,并增加扣减日志
3)、rollback阶段:回滚操作(增加可售库存、删除扣减日志)
此时我们可以看到这里还涉及了另一个表扣减日志表,我们可以顺便看下这个表是否有数据错乱问题:
 可以看到,库存数据依然不正确:已销售库存 + 未销售库存 != 总库存 。
可以看到,库存数据依然不正确:已销售库存 + 未销售库存 != 总库存 。
并且increase_saled_stock_quantity(代表增加后的已销售库存,应改是10->20->30 递增)值就明显不对了,出现了重复的值。
扣减库存的TCC方案: