字符串常量池 java_Java字符串常量池
String s1 = "Hello";
String s2= "Hello";
String s3= "Hel" + "lo";
String s4= "Hel" + new String("lo");
String s5= new String("Hello");
String s6=s5.intern();
String s7= "H";
String s8= "ello";
String s9= s7 +s8;
System.out.println(s1== s2); //true
System.out.println(s1 == s3); //true
System.out.println(s1 == s4); //false
System.out.println(s1 == s9); //false
System.out.println(s4 == s5); //false
System.out.println(s1 == s6); //true
刚开始看字符串的时候,经常会看到类似的题,难免会有些不解,查看答案总会提到字符串常量池、运行常量池等概念,很容易让人搞混。
下面就来说说Java中的字符串到底是怎样创建的。
String有两种赋值方式,第一种是通过“字面量”赋值。
String str = "Hello";
第二种是通过new关键字创建新对象。
String str = new String("Hello");
要弄清楚这两种方式的区别,首先要知道他们在内存中的存储位置。

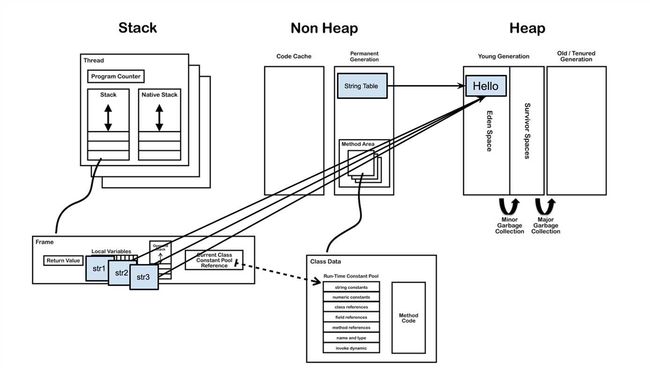
我们平时所说的内存就是图中的运行时数据区(Runtime Data Area),其中与字符串的创建有关的是方法区(Method Area)、堆区(Heap Area)和栈区(Stack Area)。
方法区:存储类信息、常量、静态变量。全局共享。
堆区:存放对象和数组。全局共享。
栈区:基本数据类型、对象的引用都存放在这。线程私有。
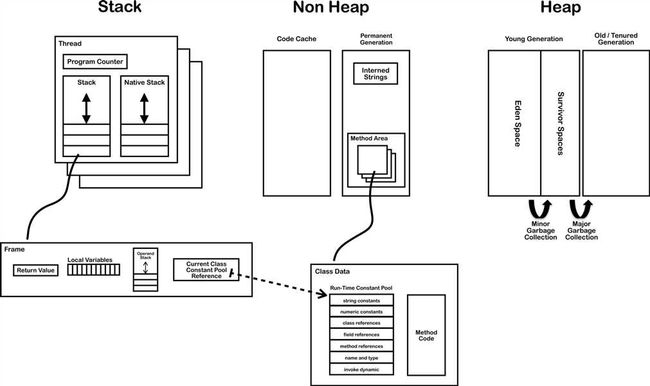
每当一个方法被执行时就会在栈区中创建一个栈帧(Stack Frame),基本数据类型和对象引用就存在栈帧中局部变量表(Local Variables)。
当一个类被加载之后,类信息就存储在非堆的方法区中。在方法区中,有一块叫做运行时常量池(Runtime Constant Pool),它是每个类私有的,每个class文件中的“常量池”被加载器加载之后就映射存放在这,后面会说到这一点。
和String最相关的是字符串池(String Pool),其位置在方法区上面的驻留字符串(Interned Strings)的位置,之前一直把它和运行时常量池搞混,其实是两个完全不同的存储区域,字符串常量池是全局共享的。字符串调用String.intern()方法后,其引用就存放在String Pool中。
了解了这些概念,下面来说说究竟两种字符串创建方式有何区别。
下面的Test类,在main方法里以“字面量”赋值的方式给字符串str赋值为“Hello”。
public classTest {public static voidmain(String[] args) {
String str= "Hello";
}
}
Test.java文件编译后得到.class文件,里面包含了类的信息,其中有一块叫做常量池(Constant Pool)的区域,.class常量池和内存中的常量池并不是一个东西。
.class文件常量池主要存储的就包括字面量,字面量包括类中定义的常量,由于String是不可变的(String为什么是不可变的?),所以字符串“Hello”就存放在这。
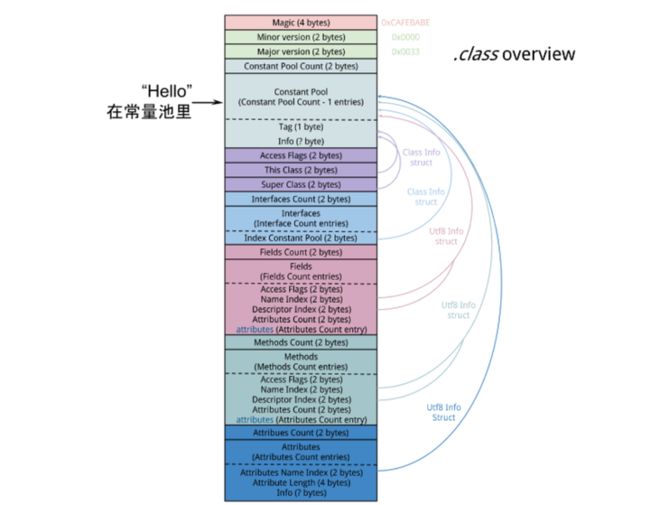
当程序用到Test类时,Test.class被解析到内存中的方法区。.class文件中的常量池信息会被加载到运行时常量池,但String不是。
例子中“Hello”会在堆区中创建一个对象,同时会在字符串池(String Pool)存放一个它的引用,如下图所示。
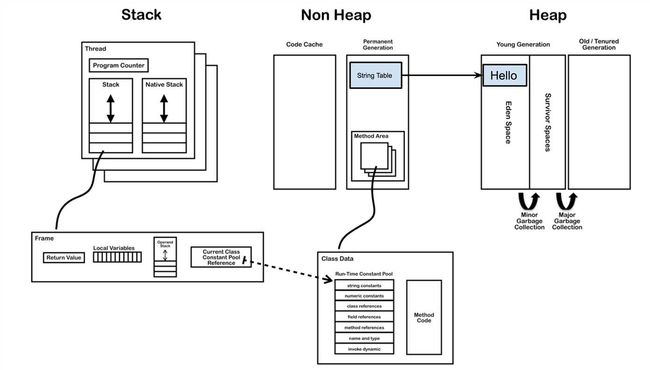
此时只是Test类刚刚被加载,主函数中的str并没有被创建,而“Hello”对象已经创建在于堆中。
当主线程开始创建str变量的,虚拟机会去字符串池中找是否有equals(“Hello”)的String,如果相等就把在字符串池中“Hello”的引用复制给str。如果找不到相等的字符串,就会在堆中新建一个对象,同时把引用驻留在字符串池,再把引用赋给str。
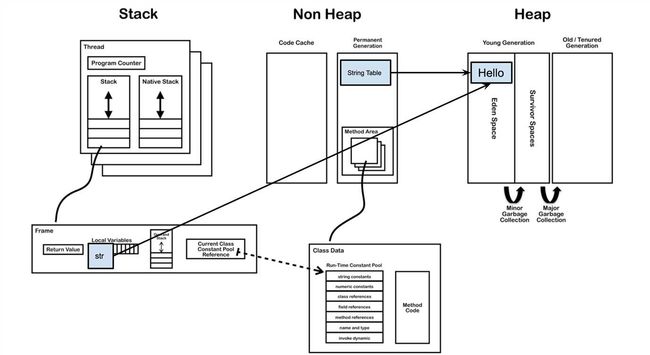
当用字面量赋值的方法创建字符串时,无论创建多少次,只要字符串的值相同,它们所指向的都是堆中的同一个对象。
public classTest {public static voidmain(String[] args) {
String str1= "Hello";
String str2=“Hello”;
String str3=“Hello”;
}
}
当利用new关键字去创建字符串时,前面加载的过程是一样的,只是在运行时无论字符串池中有没有与当前值相等的对象引用,都会在堆中新开辟一块内存,创建一个对象。
public classTest {public static voidmain(String[] args) {
String str1= "Hello";
String str2=“Hello”;
String str3= new String("Hello");
}
}
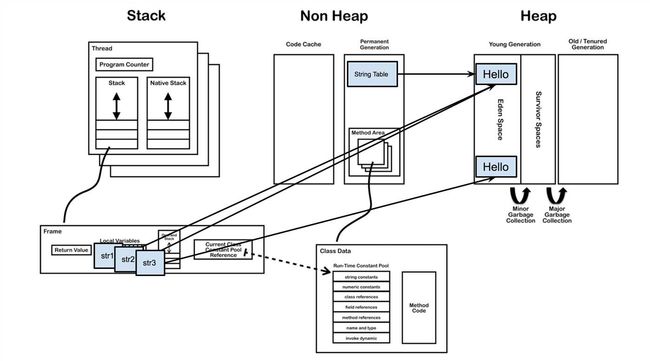
现在我们来回头看之前的例子。
String s1 = "Hello";
String s2= "Hello";
String s3= "Hel" + "lo";
String s4= "Hel" + new String("lo");
String s5= new String("Hello");
String s6=s5.intern();
String s7= "H";
String s8= "ello";
String s9= s7 +s8;
System.out.println(s1== s2); //true
System.out.println(s1 == s3); //true
System.out.println(s1 == s4); //false
System.out.println(s1 == s9); //false
System.out.println(s4 == s5); //false
System.out.println(s1 == s6); //true
有了上面的基础,之前的问题就迎刃而解了。
s1在创建对象的同时,在字符串池中也创建了其对象的引用。
由于s2也是利用字面量创建,所以会先去字符串池中寻找是否有相等的字符串,显然s1已经帮他创建好了,它可以直接使用其引用。那么s1和s2所指向的都是同一个地址,所以s1==s2。
s3是一个字符串拼接操作,参与拼接的部分都是字面量,编译器会进行优化,在编译时s3就变成“Hello”了,所以s1==s3。
s4虽然也是拼接,但“lo”是通过new关键字创建的,在编译期无法知道它的地址,所以不能像s3一样优化。所以必须要等到运行时才能确定,必然新对象的地址和前面的不同。
同理,s9由两个变量拼接,编译期也不知道他们的具体位置,不会做出优化。
s5是new出来的,在堆中的地址肯定和s4不同。
s6利用intern()方法得到了s5在字符串池的引用,并不是s5本身的地址。由于它们在字符串池的引用都指向同一个“Hello”对象,自然s1==s6。
总结一下:
字面量创建字符串会先在字符串池中找,看是否有相等的对象,没有的话就在堆中创建,把地址驻留在字符串池;有的话则直接用池中的引用,避免重复创建对象。
new关键字创建时,前面的操作和字面量创建一样,只不过最后在运行时会创建一个新对象,变量所引用的都是这个新对象的地址。
参考资料:
https://www.zhihu.com/question/29884421/answer/113785601
http://www.cnblogs.com/iyangyuan/p/4631696.html
http://blog.csdn.net/sugar_rainbow/article/details/68150249
原文:http://www.cnblogs.com/justcooooode/p/7603381.html