BPF之事件源
基础
1. BPF和eBPF概念
BPF 原是 Berkeley Packet Filter(伯克利数据包过滤器)的缩写,1992诞生,用于网络包过滤。2014经过修改并入 Linux 内核主线,从此 BPF 变成了一个更通用的执行引擎,主要用于网络、可观测性和安全。将来可能会拓展到更多应用领域,比如控制 scheduler 的行为。
eBPF 是扩展后的 BPF,增加了更多的寄存器,增加 BPF 映射型存储(map)、设计成可即时编译 JIT 方式使用,不过官方缩写通常不带"e",内核中只有一个执行引擎,即 eBPF(扩展后的BPF),同时支持经典 BPF 和扩展后的 BPF,还用 BPF 的缩写。

2. BPF运行机制
简单来说,BPF 提供了一种在各种内核事件和应用程序事件发生时运行一小段自定义的程序的机制,这样就可以控制你的系统。
BPF是一项灵活的技术,主要由指令集、存储对象、辅助函数等组成,采用虚拟指令集规范,也算一种虚拟机实现。这些指令由 Linux 内核的 BPF 模块执行,两种执行机制:(1)解释器 ;(2)JIT编译器(just-in-time)将BPF指令动态转换为本地化指令;指令执行之前需要通过验证器(verifier)的检查,确保不会让系统奔溃。
BPF 程序是由 event-driven (事件驱动),在内核或者用户态程序中插入 hook 点来执行,预置的事件 hook 点有:system calls、function entry/exit、kernel tracepoints、network events 以及其他。

如果预置 hook 点不满足需求,也可以自定义。通过 kernel probe (kprobe) 或 user probe (uprobe) 几乎可以在任何地方来插入 BPF 执行函数。
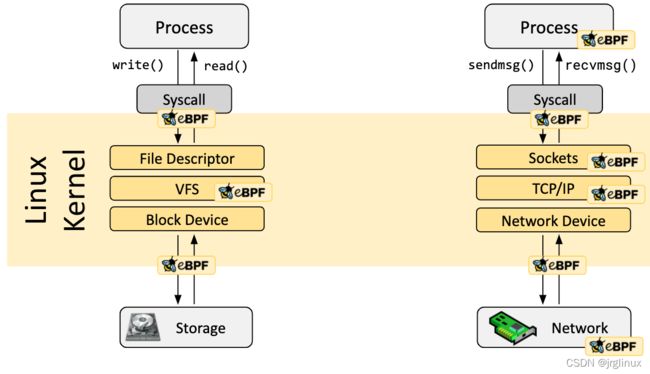
3. 加载 BPF 程序
BPF 程序一般有 bpf system call 进行加载进内核。
进入内核时:BPF 指令需通过验证器(verifier)验证,然后由 BPF 虚拟机执行。虚拟机执行分两种模式,一种是解释器(interpreter),一种是即使编译(JIT); JIT 会将 BPF 指令转换为处理器可以直接执行的机器指令。BPF helpers 辅助函数可以获取内核状态,映射表 Map 用于存储。

| 模块 | 名称 | 作用 |
|---|---|---|
| verifier | 验证器 | 检查确保BPF程序是运行安全的,比如检查: 1. 检查BPF程序的权限,只有有超级权限的才能加载BPF程序进内核 2. 确保BPF程序不会crash或者破坏系统的可能 3. 检查BFP程序能正常运行,不能出现如死循环等阻塞系统的情况 |
| JIT Complier | JIT编译器 | 将BPF指令动态转换为本地化指令 |
| Maps | 映射表Map | BPF机制提供采集信息的共享以及状态的存储,通过Map映射表来实现数据共享,支持多种映射方式,如: 1. 哈希表、数组 2. LRU(least recently used) 3. ring buffer 4. stack trace 5. LPM(longest prefix match) … |
| helpers | 辅助函数 | BPF也可能调用内核中的任意函数,如果能调用任意函数,那么BPF就和内核版本高度定制化了 所以,内核提供辅助函数API,供BPF调用,比如 bpf_get_prandom_u32() 函数等,主要类别有: 1. 随机数生成接口 2. 时间读取接口 3. BPF map 访问接口 4. 获取进程/组的上下文 5. 操控网络报文 … |
BPF支持 Tail & Function Calls,允许在 BPF 中定义和调用函数,Tail Calls 支持调用和执行另一个 BPF 程序来替换当前 BPF 程序,类似于系统调用 execve() 函数族的功能。
4. BPF 技术优势
BPF 相对于其他性能采集工具的与众不同之处在于其高效率和安全性。
以采集磁盘I/O事件到用户态生成直方图为例:

未使用 BPF 之前:
- 【内核空间】打开磁盘I/O事件的插庄观测
- 【内核空间】针对每个event,向perf缓冲区写入记录,如果使用了tracepoint技术,记录中会包含磁盘I/O的几个元数据字段
- 【用户空间】周期性将perf缓冲区内容复制到用户空间
- 【用户空间】遍历每个事件,解析元数据字段,生成直方图,其他不需要的字段忽略
使用 BPF 之后:
- 【内核空间】打开磁盘I/O事件的插庄观测,并挂载 BPF 程序
- 【内核空间】针对每个event,BPF程序获取字节字段,将数据保存到自定义的 BPF Map直方图映射数据结构中
- 【用户空间】一次性读取 BPF 直方图映射表并输出
使用 BPF 优势:避免了将事件数据复制到用户空间再对其处理,避免了对未使用到的元数据字段进行复制,减少了性能的浪费。
BPF 与内核模块对比优势
kprobes 与 tracepoints 技术早已出现,可以通过内核模块加载的方式让用户来采集数据,那么为何还需要 BPF 技术呢?
- BPF 程序会通过 verifier 验证器查验;而内核模块可能引入bug
- BPF 通过 Map 映射表提供丰富的数据结构支持
- BPF 程序可以一次编译,到处运行(BPF instruction set, map, helpers, and infrastructure 是稳定的API,当然有些 BPF 也包含不稳定的因素,比如使用 kprobes 来观测内核数据结构就会影响 BPF 程序自身的稳定性)
- BPF 程序的编译不依赖于内核编译过程的中间结果
- 与内核模块的开发难度相比,BPF 易学
5. 开发 BPF 程序
在跟踪观测方面,前端工具主要有:
-
LLVM
-
BCC
-
bpftrace
-
perf(唯一的代码内置在内核中的前端工具)
LLVM编译器支持将 BPF 作为编译目标体系结构,BPF程序可以使用支持LLVM的更高级语言编写,比如C语言(借助Clang工具编译成BPF目标,如clang -taget bpf)。
BCC允许使用C语言、python等来开发BPF程序。
bpftrace则提供了自己的更高级语言。
eBPF Go Library
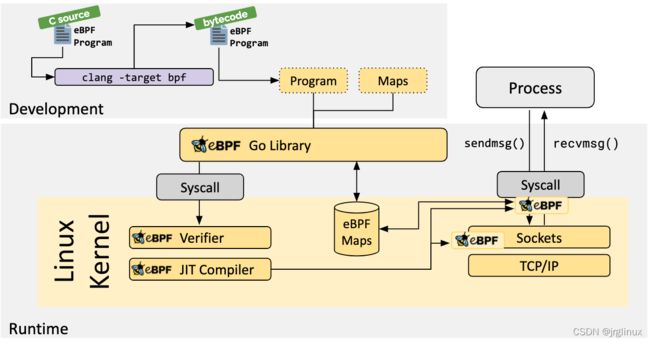
libbpf C/C++ Library

6. BPF之API
可以看看内核代码:include/uapi/lnux/bpf.h,tools/lib/bpf/bpf.c等,内核中提供了不少API接口。
7. BPF与perf关系
简要来说,BPF 使用可以使用 perf, perf 也可以使用 BPF,所以 perf 也是 BPF 的前端工具之一,而且是唯一置于 Linux 中的 BPF 前端工具
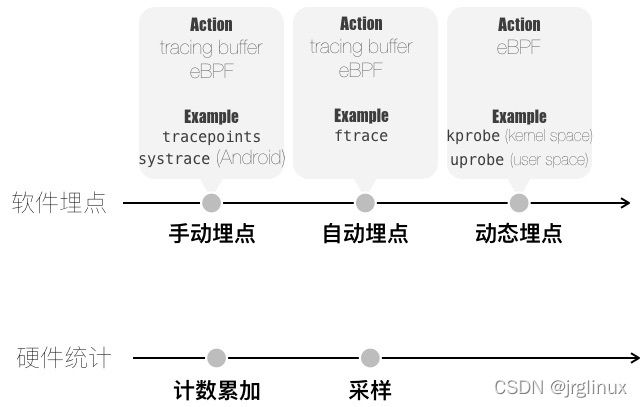
事件源
之前提到过,BPF 是事件驱动的(event-driven),那么事件源有哪些地方?
Brendan Gregg 在《BPF之巅》中有图可参考:

| 插桩方式 | 事件源 |
|---|---|
| 动态插桩 | kprobes、uprobes、Dynamic USDT |
| 静态插桩 | tracepoints、USDT |
1. kprobes
kprobes提供了针对内核的动态插桩支持,可以对任何内核函数进行插桩,也可以对函数内部的指令进行插桩。kprobes还有另一个接口kreprobes,用于对内核函数返回时进行插桩以获取返回值。当kprobes与kretprobes同时对一个函数进行插桩时,可以使用时间戳来记录函数执行的时长。
kprobes工作机制

kretprobes工作机制

kprobes内核模块实例
Linux内核代码中有现成的实例samples/kprobes/kprobe_example.c, samples/kprobes/kretprobe_example.c
编译生成kprobe_example.ko:
-
方法1, config中添加
CONFIG_SAMPLE_KPROBE,CONFIG_SAMPLE_KRETPROBE -
修改
samples/kprobes/Makefile,然后单独编译生成kprobe_exmaple.koobj-m := kprobe_example.o obj-m += kretprobe_example.o KDIR := /lib/modules/$(shell uname -r)/build PWD := $(shell pwd) default: $(MAKE) -C $(KDIR) M=$(PWD) modules clean: @rm -f *.mod *.order *.symvers *.mod.c *.ko *.o .k* .m* .M*
内核中的 kprobe_example.c 与 kretprobe_example.c 代码逻辑很简单,主要流程就是注册需要探测的函数监测点struct kprobe kp,然后register_kprobe(&kp),当加载内核模块时就可以探测。
比如 kprobe_example 用于获取内核在调用"kernel_clone()" 函数时的栈追踪和选择的寄存器地址等信息
[ 2522.789527] Planted kprobe at 00000000a5b977c8
[ 2522.790048] <_do_fork> pre_handler: p->addr = 0x00000000a5b977c8, ip = ffffffff820c8001, flags = 0x206
[ 2522.790049] <_do_fork> post_handler: p->addr = 0x00000000a5b977c8, flags = 0x206
[ 2542.243148] kprobe at 00000000a5b977c8 unregistered
比如 kretprobe_example 用于探测调用"_do_fork()" 函数的返回值和总调用时间
[ 5914.377705] Planted return probe at _do_fork: 00000000a5b977c8
[ 5916.295746] _do_fork returned 3301 and took 134175 ns to execute
[ 5920.006712] _do_fork returned 3302 and took 128528 ns to execute
[ 5926.062090] kretprobe at 00000000a5b977c8 unregistered
[ 5926.062091] Missed probing 0 instances of _do_fork
kprobes接口API
使用kprobes的方法主要有三种:
- kprobe API,比如编写kernel module使用register_kprobe()进行探测
- 基于Ftrace,通过 /sys/kernel/debug/tracing/kprobe_events 文件,通过向改文件写入事件进行使用kprobes
- perf_event_open(),与perf工具使用方法一样,BPF也开始使用这些函数
一般不会使用C语言直接去编写kprobes内核模块进行监测。可以借助于perf、System Tap、BPF跟踪器、BCC与bpftrace等工具使用kprobes。
BPF与kprobes
kprobes给BPF提供了接口:
BCC: attach_kprobe() 和 attach_kretprobe()
bpftrace: kprobe 和 kretprobe 探针类型
BCC 的 kprobes 接口可以支持在函数入口或者某一偏移量位置进行插桩,而 bpftrace 目前只支持在函数入口位置插桩。kretprobes 接口都是在函数返回处插桩。
比如使用 bpftrace 查看 pick_next_task_fifo() 函数被调用的次数【如何统计内核中某个函数被调用的次数】:

2. uprobes
工作机制
uprobes是用户态程序的动态插桩。在用户态程序插桩位置:函数入口、特定偏移处、函数返回处。
uprobes 与 uretprobes 的工作机制与 kprobes 以及 kretprobes 是类似的。
uprobes接口API
- 基于Ftrace,通过/sys/kernel/debug/tracing/uprobe_events,向改文件写入特定字符串进行开启或关闭 uprobes
- perf_event_open(),与 perf 使用方法一样,BPF 也开始使用该接口
BPF与uprobes
BCC: attach_uprobe() 和 attach_uretprobe()
bpftrace: uprobe 和 uretprobe 探针类型
比如使用 bpftrace 对当前运行以及后续运行的bash shell 的 readline() 进行跟踪统计:

3. tracepoints
跟踪点,用于对内核静态插桩
新增tracepoints跟踪点实例
新增一个跟踪 fifo 调度器在选择下一个进程时的跟踪点,用于输出当前进程和选择的下一个进程的有关信息。
/*在 include/trace/event/sched.h 头文件中添加静态tracepoint点*/
TRACE_EVENT(sched_fifo_pick_next,
TP_PROTO(struct task_struct *curr,
struct task_struct *next),
TP_ARGS(curr, next),
TP_STRUCT__entry(
__field( pid_t, curr_pid )
__field( int, curr_prio )
__field( pid_t, next_pid )
__field( int, next_prio )
),
TP_fast_assign(
__entry->curr_pid = curr->pid;
__entry->curr_prio = curr->prio;
__entry->next_pid = next->pid;
__entry->next_prio = next->prio;
),
TP_printk("curr_pid=%d curr_prio=%d ==> next_pid=%d next_prio=%d",
__entry->curr_pid, __entry->curr_prio, __entry->next_pid, __entry->next_prio)
);
/*在 kernel/sched/fifo.c 中调用*/
if(curr && next) {
trace_sched_fifo_pick_next(curr,next);
}
tracepoints工作机制
- 内核编译阶段会在trace_xxx() 跟踪点位置插入一个5字节的nop指令,这是一个不做任何具体操作的指令,只是占位,用于替换为jmp指令
- 在函数尾部插入trampoline蹦床函数(用于遍历存储跟踪点回调函数的数组),这也会导致原函数编译后稍偏大
- 当某个跟踪器比如perf启用跟踪点时(该跟踪点可能已被其他跟踪器启用):
- 在跟踪点回调函数插入一条新的跟踪回调函数,RCU形式同步更新
- 如果之前跟踪点处于禁用状态,则nop指令的地址重写为jmp到trampoline的指令
- 当某个跟踪器比如perf禁用跟踪点时:
- 在跟踪点回调函数数组中删除该跟踪器回调函数,RCU形式同步更新
- 如果最后一个回调函数也被删除,则将jmp指令重写为nop指令
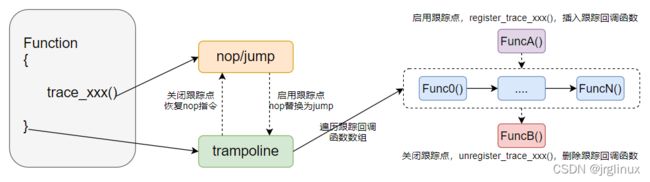
原因:这样可以最小化处于禁用状态的tracepoints的性能开销。
tracepoints接口API
- 基于Ftrace,/sys/kernel/debug/tracing/events下的每个子目录对应跟踪点事件,100多个事件,通过设置这些跟踪点事件实现开关tracepoints
- perf_event_open(),这也是perf 使用的接口,BPF也开始使用(通过perf_tracepoint PMU)
BPF与tracepoints
BCC: TRACEPOINT_PROBE()
bpftrace: 跟踪点探针类型
perf:跟踪点事件
比如用bpftrace对 sched:sched_process_exec进行插桩跟踪:

用 perf 监测 sched:sched_process_exec:

4. USDT
用户态预定义静态跟踪器(user-level statically defined tracing, USDT)。是用户空间的静态跟踪点机制。BCC和bpftrace都支持。
用户态软件跟踪与日志有很多种技术方式,有些程序本身就构建了日志系统,可以根据需要开启关闭。USDT不同之处在于需要依赖外部跟踪器来开启,如果没有外部跟踪器,用户态程序中的 USDT 不会启任何作用。
许多应用软件默认不开启 USDT,可能需要配置参数如 --enable-dtrace-probes 或者 --with-dtrace。
【USDT 了解即可,实际运用不会很多】
添加USDT探针
给用户程序添加 USDT 探针,一般两种方式:
通过 systemtap-sdt-dev 包提供的头文件和工具
自定义头文件,比如facebook 的folly C++库
USDT工作机制
与 uprobes 类似。
BPF与USDT
BCC: USDT().enable_probe()
bpftrace: USDT探针类型
5. Dynamic USDT
USDT 是需要添加到源代码然后编译成二进制文件中,在插桩点留下 nop 指令,在 ELF notes 段中存放元数据。不过有些语言支持在运行的时候解释或编译,如 Java/JVM。动态 USDT 可以用来给 Java 代码增加插桩点。
【Dynamic USDT 了解即可,实际运用不会很多】
工作机制
以 Java 代码举例:
- Pre-compiling a shared library with the desired USDT probes embedded in functions. This shared library can be in C or C++, and it has an ELF notes section for the USDT probes. It can be instrumented like any other USDT probe.
- Loading the shared library when required with dlopen(3).
- Adding shared library calls from the target language. These can be implemented with an API that suits the language, hiding the underlying shared library call.
6. PMCs
性能监控计数器,performance monitoring counter,PMC。属于硬件,是处理器上的硬件可编程计数器。
别名:性能观测计数器(performance instrumention counter,PIC)、CPU性能计数器(CPU performance counter,CPC)、性能监控单元事件(performance monitoring unit event,PMU event)。这些都是指一个东西,即 PMC。
只有通过PMC 才能测量 CPU 指令执行的效率、CPU 缓存的命中率、内存/数据互联和设备总线的利用率,以及阻塞的指令周期等。
cycles
instructions
branch-*
L1-*
LLC-*
不过尽管有上百个 PMC,但任意时刻在CPU中可能只允许读取固定数量的寄存器来进行测量读取。所以在采集代码实现中,通常需要通过这些寄存器来循环采样才可以覆盖到多个PMC(perf自动支持这种循环采样)。
PMC工作模式
- 计数,PMC 跟踪事件发生的频率
- 溢出采样,PMC在所监控的时间发生到一定次数时通知内核,内核可以获取额外的状态。当计数器发生溢出时想内核发信号,如每10000次LLC缓存未命中事件,或者每100万次阻塞的指令时钟周期。
perf_events
perf_events 是 perf 命令所依赖的采样和跟踪机制。BPF 也可以调用 perf_events 来使用了。
BCC 和 bpftrace 使用 perf_events 作为它们的环形缓冲区,然后又增加了对 PMC 的支持,现在又通过 perf_event_open() 来对所有的事件进行观测。
BPF 可以使用 perf, perf 也可以使用 BPF,所以 perf 也是 BPF 的前端工具之一,而且是唯一置于 Linux 中的 BPF 前端工具。
perf 的事件源 events 主要有以下一些,具体有关 perf 的分析另外单独成文。
Hardware [Cache] Events:
CPU相关计数器
CPU周期、指令失效,内存间隔周期、L2CACHE miss等
These instrument low-level processor activity based on CPU performance counters.
For example, CPU cycles, instructions retired, memory stall cycles, level 2 cache misses, etc.
Some will be listed as Hardware Cache Events.
Software Events:
内核相关计数器
These are low level events based on kernel counters.
For example, CPU migrations, minor faults, major faults, etc.
Tracepoint Events:
内核ftrace框架相关,例如系统调用,TCP事件,文件系统IO事件,块设备事件等。
根据LIBRARY归类。如sock表示socket事件。
This are kernel-level events based on the ftrace framework. These tracepoints are placed in interesting and logical locations of the kernel, so that higher-level behavior can be easily traced.
For example, system calls, TCP events, file system I/O, disk I/O, etc.
These are grouped into libraries of tracepoints;
eg, "sock:" for socket events, "sched:" for CPU scheduler events.
Dynamic Tracing:
动态跟踪,可以在代码中的任何位置创建事件跟踪节点。很好很强大。
内核跟踪使用kprobe,user-level跟踪使用uprobe。
Software can be dynamically instrumented, creating events in any location.
For kernel software, this uses the kprobes framework.
For user-level software, uprobes.
Timed Profiling:
采样频度,按指定频率采样,被用于perf record。
Snapshots can be collected at an arbitrary frequency, using perf record -FHz.
This is commonly used for CPU usage profiling, and works by creating custom timed interrupt events.