Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时
导读:随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,使得实时数仓在这一过程中起到了不可替代的作用。本文将基于用户遇到的问题与挑战,揭秘 Apache Doris 1.1 特性,对 Flink 实时写入 Apache Doris 的优化实现与未来规划进行详细的介绍。
背景
随着数据实时化需求的日益增多,数据的时效性对企业的精细化运营越来越重要,在海量数据中,如何能实时有效的挖掘出有价值的信息,快速的获取数据反馈,协助公司更快的做出决策,更好的进行产品迭代,实时数仓在这一过程中起到了不可替代的作用。
在这种形势下,Apache Doris 作为一款实时 MPP 分析型数据库脱颖而出,同时具备高性能、简单易用等特性,具有丰富的数据接入方式,结合 Flink 流式计算,可以让用户快速将 Kafka 中的非结构化数据以及 MySQL 等上游业务库中的变更数据,快速同步到 Doris 实时数仓中,同时 Doris 提供亚秒级分析查询的能力,可以有效地满足实时 OLAP、实时数据看板以及实时数据服务等场景的需求。
挑战
通常实时数仓要保证端到端高并发以及低延迟,往往面临诸多挑战,比如:
-
如何保证端到端的秒级别数据同步?
-
如何快速保证数据可见性?
-
在高并发大压力下,如何解决大量小文件写入的问题?
-
如何确保端到端的 Exactly Once 语义?
结合这些挑战,同时对用户使用 Flink+Doris 构建实时数仓的业务场景进行深入调研,在掌握了用户使用的痛点之后,我们在 Doris 1.1 版本中进行了针对性的优化,大幅提升实时数仓构建的用户体验,同时提升系统的稳定性,系统资源消耗也得到了大幅的优化。
优化
流式写入
Flink Doris Connector 最初的做法是在接收到数据后,缓存到内存 Batch 中,通过攒批的方式进行写入,同时使用 batch.size、batch.interval 等参数来控制 Stream Load 写入的时机。这种方式通常在参数合理的情况下可以稳定运行,一旦参数不合理导致频繁的 Stream Load,便会引发 Compaction 不及时,从而导致 version 过多的错误(-235);其次,当数据过多时,为了减少 Stream Load 的写入时机,batch.size 过大的设置还可能会引发 Flink 任务的 OOM。为了解决这个问题,我们引入了流式写入 :
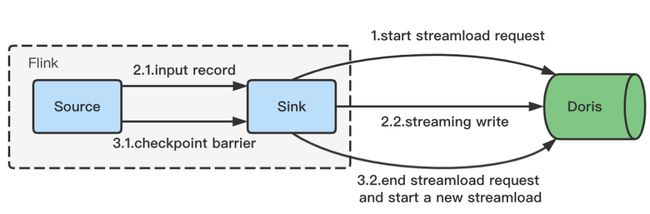
-
Flink 任务启动后,会异步发起一个 Stream Load 的 Http 请求。
-
接收到实时数据后,通过 Http 的分块传输编码(Chunked transfer encoding)机制持续向 Doris 传输数据。
-
在 Checkpoint 时结束 Http 请求,完成本次 Stream Load 写入,同时异步发起下一次 Stream Load 的请求。
-
继续接收实时数据,后续流程同上。
由于采用 Chunked 机制传输数据,就避免了攒批对内存的压力,同时将写入的时机和 Checkpoint 绑定起来,使得 Stream Load 的时机可控,并且为下面的 Exactly-Once 语义提供了基础。
Exactly-Once
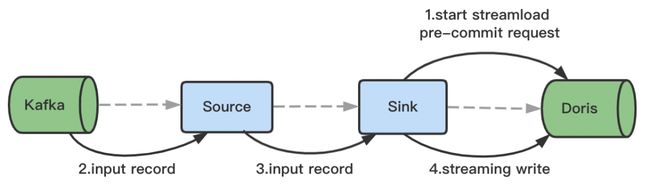
Exactly-Once 语义是指即使在机器或应用出现故障的情况下,也不会重复处理数据或者丢失数据。Flink 很早就支持 End-to-End 的 Exactly-Once 场景,主要是通过两阶段提交协议来实现 Sink 算子的 Exactly-Once 语义。在 Flink 两阶段提交的基础上,同时借助 Doris 1.0 的 Stream Load 两阶段提交,Flink Doris Connector 实现了 Exactly Once 语义,具体原理如下:
-
Flink 任务在启动的时候,会发起一个 Stream Load 的 PreCommit 请求,此时会先开启一个事务,同时会通过 Http 的 Chunked 机制将数据持续发送到 Doris。
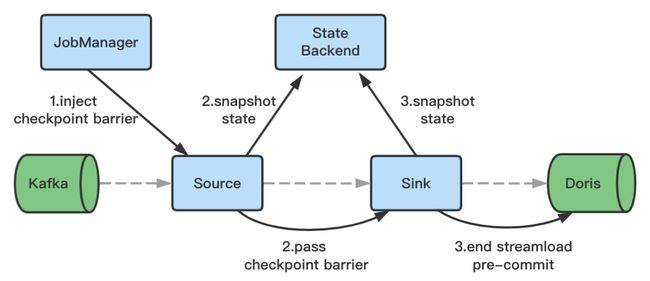
-
在 Checkpoint 时,结束数据写入,同时完成 Http 请求,并且将事务状态设置为预提交(PreCommitted),此时数据已经写入 BE,对用户不可见。
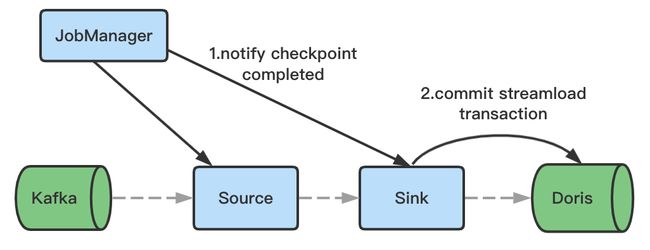
-
Checkpoint 完成后,发起 Commit 请求,并且将事务状态设置为提交(Committed),完成后数据对用户可见。
-
Flink 应用意外挂掉后,从 Checkpoint 重启时,若上次事务为预提交(PreCommitted)状态,则会发起回滚请求,并且将事务状态设置为 Aborted。
基于此,可以借助 Flink Doris Connector 实现数据实时入库时数据不丢不重。
秒级别数据同步
高并发写入场景下的端到端秒级别数据同步以及数据的实时可见能力,需要 Doris 具备如下几方面的能力:
事务处理能力
Flink 实时写入以 Stream Load 2PC 的方式与 Doris 进行交互,需要 Doris 具备对应的事务处理能力,保障事务基本的 ACID 特性,在高并发场景下支撑 Flink 秒级别的数据同步。
数据版本的快速聚合能力
Doris 里面一次导入会产生一个数据版本,在高并发写入场景下必然带来的一个影响是数据版本过多,且单次导入的数据量不会太大。持续的高并发小文件写入场景对 Doris 并不友好,极其考验 Doris 数据合并的实时性以及性能,进而会影响到查询的性能。Doris 在 1.1 中大幅增强了数据 Compaction 能力,对于新增数据能够快速完成聚合,避免分片数据中的版本过多导致的 -235 错误以及带来的查询效率问题。
首先,在 Doris 1.1 版本中,引入了 QuickCompaction,增加了主动触发式的 Compaction 检查,在数据版本增加的时候主动触发 Compaction。同时通过提升分片元信息扫描的能力,快速的发现数据版本多的分片,触发 Compaction。通过主动式触发加被动式扫描的方式,彻底解决数据合并的实时性问题。
同时,针对高频的小文件 Cumulative Compaction,实现了 Compaction 任务的调度隔离,防止重量级的 Base Compaction 对新增数据的合并造成影响。
最后,针对小文件合并,优化了小文件合并的策略,采用梯度合并的方式,每次参与合并的文件都属于同一个数据量级,防止大小差别很大的版本进行合并,逐渐有层次的合并,减少单个文件参与合并的次数,能够大幅的节省系统的 CPU 消耗。
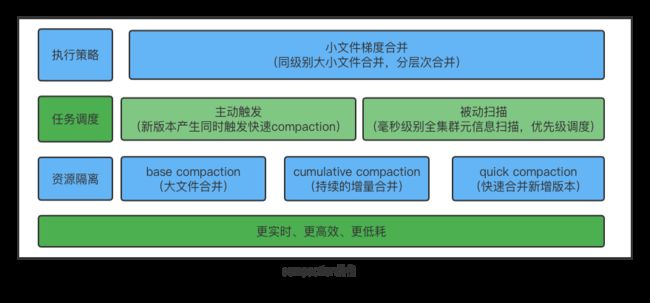
Doris 1.1 对高并发导入、秒级别数据同步、数据实时可见等场景都做了针对性优化,大大增加了 Flink + Doris 系统的易用性以及稳定性,节省了集群整体资源。
效果
通用 Flink 高并发场景
在调研的通用场景中,使用 Flink 同步上游 Kafka 中的非结构化数据,经过 ETL 后使用 Flink Doris Connector 将数据实时写入 Doris 中。这里客户场景极其严苛,上游维持以每秒 10w 的超高频率写入,需要数据能够在 5s 内完成上下游同步,实现秒级别的数据可见。这里 Flink 配置为 20 并发,Checkpoint 间隔 5s,Doris 1.1 的表现相当优异。具体体现在如下几个方面:
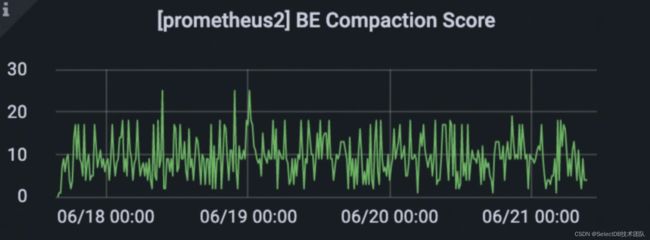
Compaction 实时性
数据能快速合并,Tablet 数据版本个数维持在 50 以下, Compaction Score 稳定。相比于之前高并发导入频出的 -235 问题,Compaction 合并效率有 10+ 倍提升。
CPU 资源消耗
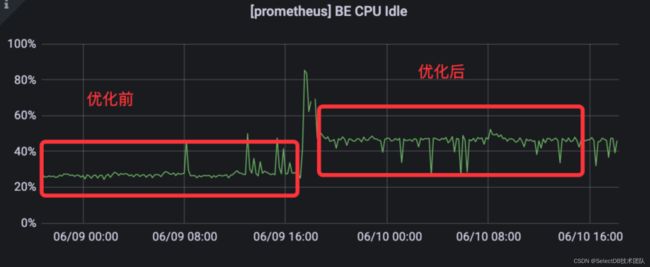
Doris 1.1 针对小文件的 Compaction 进行了策略优化,在上述高并发导入场景,CPU 资源消耗下降 25%。
QPS 查询延迟稳定
通过降低 CPU 使用率,减少数据版本的个数,提升了数据整体有序性,从而减少了 SQL 查询的延迟。
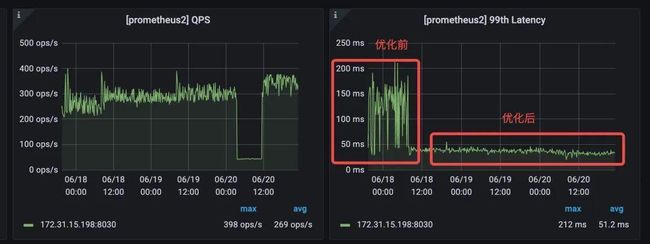
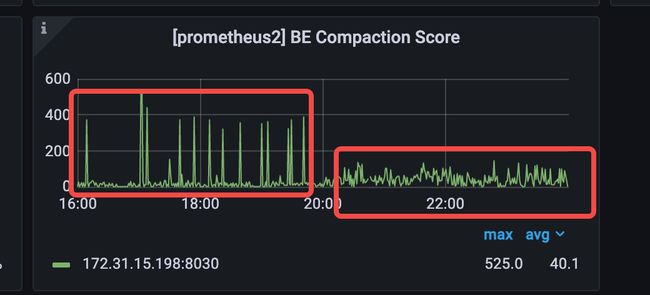
秒级别数据同步场景(极限大压力)
单 BE 单 Tablet,客户端 30 并发极限 Stream Load 压测,数据在实时性<1s,Compaction Score 优化前后对比
使用建议
数据实时可见场景
对延迟要求特别严格的场景,比如秒级别数据同步,通常意味着单次导入文件较小,此时建议调小 cumulative_size_based_promotion_min_size_mbytes,单位是 MB,默认 64,可以设置成 8,能够很大程度提升 Compaction 的实时性。
高并发场景
对于高并发的写入场景,可以通过增加 Checkpoint 的间隔来减少 Stream Load 的频率,比如 Checkpoint 可以设置为 5-10s,不仅可以增加 Flink 任务的吞吐,也可以减少小文件的产生,避免给 Compaction 造成更多压力。
此外,对数据实时性要求不高的场景,比如分钟级别的数据同步,可以增加 Checkpoint 的间隔,比如 5-10 分钟,此时 Flink Doris Connector 依然能够通过两阶段提交 +checkpoint 机制来保证数据的完整性。
未来规划
实时 Schema Change
目前通过 Flink CDC 实时接入数据时,当上游业务表进行 Schema Change 操作时,必须先手动修改 Doris 中的 Schema 和 Flink 任务中的 Schema,最后再重启任务,新的 Schema 的数据才可以同步过来。这样使用方式需要人为的介入,会给用户带来极大的运维负担。后续会针对 CDC 场景做到支持 Schema 实时变更,上游的 Schema Change 实时同步到下游,全面提升 Schema Change 的效率。
Doris 多表写入
目前 Doris Sink 算子仅支持同步单张表,所以对于整库同步的操作,需要手动在 Flink 层面进行分流,写到多个 Doris Sink 中,这无疑增加了开发者的难度,在后续版本中我们也将支持单个 Doris Sink 同步多张表,这样就大大的简化了用户的操作。
自适应的 Compaction 参数调优
目前 Compaction 策略参数较多,在大部分通用场景能发挥较好的效果,但是在一些特殊场景下并不能高效的发挥作用。我们将在后续版本中持续优化,针对不同的场景,进行自适应的 Compaction 调优,在各类场景下提高数据合并效率,提升实时性。
单副本 Compaction
目前的 Compaction 策略是各 BE 单独进行,在后续版本中我们将实现单副本 Compaction,通过克隆快照的方式实现 Compaction 任务,减少集群 2/3 的 Compaction 任务,降低系统的负载,把更多的系统资源留给用户侧。
相关链接:
SelectDB 官方网站:
SelectDB - 基于 Apache Doris 的云原生实时数据仓库
Apache Doris 官方网站:
Home - Apache Doris
Apache Doris Github:
GitHub - apache/doris: Apache Doris is an MPP-based interactive SQL data warehousing for reporting and analysis.
Apache Doris 开发者邮件组:
dev@doris.apache.org