yolov8x-p2 实现 tensorrt 推理
简述
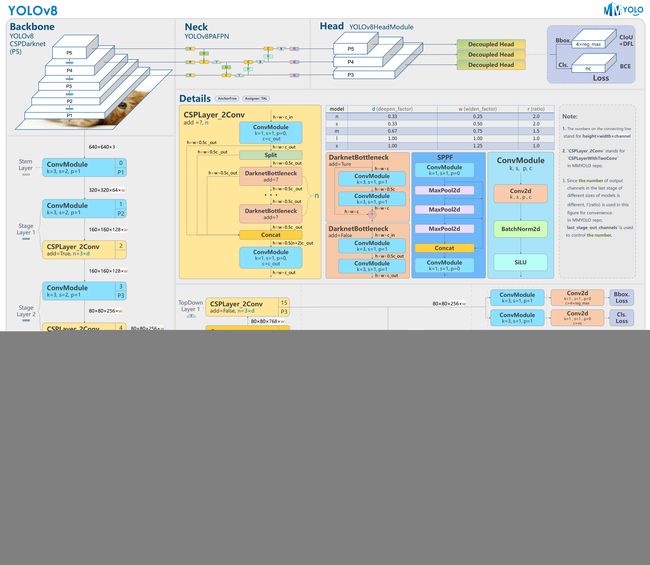
在最开始的yolov8提供的不同size的版本,包括n、s、m、l、x(模型规模依次增大,通过depth, width, max_channels控制大小),这些都是通过P3、P4和P5提取图片特征;
正常的yolov8对象检测模型输出层是P3、P4、P5三个输出层,为了提升对小目标的检测能力,新版本的yolov8 已经包含了P2层(P2层做的卷积次数少,特征图的尺寸(分辨率)较大,更加利于小目标识别),有四个输出层。Backbone部分的结果没有改变,但是Neck跟Head部分模型结构做了调整。
yolov8-p2 yaml
# Ultralytics YOLO , AGPL-3.0 license
# YOLOv8 object detection model with P2-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024]
s: [0.33, 0.50, 1024]
m: [0.67, 0.75, 768]
l: [1.00, 1.00, 512]
x: [1.00, 1.25, 512]
# YOLOv8.0 backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0-p2 head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 2], 1, Concat, [1]] # cat backbone P2
- [-1, 3, C2f, [128]] # 18 (P2/4-xsmall)
- [-1, 1, Conv, [128, 3, 2]]
- [[-1, 15], 1, Concat, [1]] # cat head P3
- [-1, 3, C2f, [256]] # 21 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 24 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 27 (P5/32-large)
- [[18, 21, 24, 27], 1, Detect, [nc]] # Detect(P2, P3, P4, P5)
yolov8-p2 tensort 实现
参考: https://github.com/wang-xinyu/tensorrtx/tree/master/yolov8
-
model.cpp中增加buildEngineYolov8x_p2方法.Backbone
-
backbone 和 yolov8 一样 , 无需改动,照搬下来就行.
/******************************************************************************************************* ***************************************** YOLOV8 BACKBONE ******************************************** *******************************************************************************************************/ nvinfer1::IElementWiseLayer *conv0 = convBnSiLU(network, weightMap, *data, 80, 3, 2, 1, "model.0"); nvinfer1::IElementWiseLayer *conv1 = convBnSiLU(network, weightMap, *conv0->getOutput(0), 160, 3, 2, 1, "model.1"); nvinfer1::IElementWiseLayer *conv2 = C2F(network, weightMap, *conv1->getOutput(0), 160, 160, 3, true, 0.5, "model.2"); nvinfer1::IElementWiseLayer *conv3 = convBnSiLU(network, weightMap, *conv2->getOutput(0), 320, 3, 2, 1, "model.3"); nvinfer1::IElementWiseLayer *conv4 = C2F(network, weightMap, *conv3->getOutput(0), 320, 320, 6, true, 0.5, "model.4"); nvinfer1::IElementWiseLayer *conv5 = convBnSiLU(network, weightMap, *conv4->getOutput(0), 640, 3, 2, 1, "model.5"); nvinfer1::IElementWiseLayer *conv6 = C2F(network, weightMap, *conv5->getOutput(0), 640, 640, 6, true, 0.5, "model.6"); nvinfer1::IElementWiseLayer *conv7 = convBnSiLU(network, weightMap, *conv6->getOutput(0), 640, 3, 2, 1, "model.7"); nvinfer1::IElementWiseLayer *conv8 = C2F(network, weightMap, *conv7->getOutput(0), 640, 640, 3, true, 0.5, "model.8"); nvinfer1::IElementWiseLayer *conv9 = SPPF(network, weightMap, *conv8->getOutput(0), 640, 640, 5, "model.9");
Head
-
由3个输出层 (P3、P4、P5) 变成4个输出层 (P2、P3、P4、P5)
HEAD
/******************************************************************************************************* ****************************************** YOLOV8 HEAD *********************************************** *******************************************************************************************************/ float scale[] = {1.0, 2.0, 2.0}; nvinfer1::IResizeLayer *upsample10 = network->addResize(*conv9->getOutput(0)); upsample10->setResizeMode(nvinfer1::ResizeMode::kNEAREST); upsample10->setScales(scale, 3); nvinfer1::ITensor *inputTensor11[] = {upsample10->getOutput(0), conv6->getOutput(0)}; nvinfer1::IConcatenationLayer *cat11 = network->addConcatenation(inputTensor11, 2); nvinfer1::IElementWiseLayer *conv12 = C2F(network, weightMap, *cat11->getOutput(0), 640, 640, 3, false, 0.5, "model.12"); nvinfer1::IResizeLayer *upsample13 = network->addResize(*conv12->getOutput(0)); upsample13->setResizeMode(nvinfer1::ResizeMode::kNEAREST); upsample13->setScales(scale, 3); nvinfer1::ITensor *inputTensor14[] = {upsample13->getOutput(0), conv4->getOutput(0)}; nvinfer1::IConcatenationLayer *cat14 = network->addConcatenation(inputTensor14, 2); nvinfer1::IElementWiseLayer *conv15 = C2F(network, weightMap, *cat14->getOutput(0), 320, 320, 3, false, 0.5, "model.15"); nvinfer1::IResizeLayer *upsample16 = network->addResize(*conv15->getOutput(0)); upsample16->setResizeMode(nvinfer1::ResizeMode::kNEAREST); upsample16->setScales(scale, 3); nvinfer1::ITensor *inputTensor17[] = {upsample16->getOutput(0), conv2->getOutput(0)}; nvinfer1::IConcatenationLayer *cat17 = network->addConcatenation(inputTensor17, 2); nvinfer1::IElementWiseLayer *conv18 = C2F(network, weightMap, *cat17->getOutput(0), 160, 160, 3, false, 0.5, "model.18"); nvinfer1::IElementWiseLayer *conv19 = convBnSiLU(network, weightMap, *conv18->getOutput(0), 160, 3, 2, 1, "model.19"); nvinfer1::ITensor *inputTensor20[] = {conv19->getOutput(0), conv15->getOutput(0)}; nvinfer1::IConcatenationLayer *cat20 = network->addConcatenation(inputTensor20, 2); nvinfer1::IElementWiseLayer *conv21 = C2F(network, weightMap, *cat20->getOutput(0), 320, 320, 3, false, 0.5, "model.21"); nvinfer1::IElementWiseLayer *conv22 = convBnSiLU(network, weightMap, *conv21->getOutput(0), 320, 3, 2, 1, "model.22"); nvinfer1::ITensor *inputTensor23[] = {conv22->getOutput(0), conv12->getOutput(0)}; nvinfer1::IConcatenationLayer *cat23 = network->addConcatenation(inputTensor23, 2); nvinfer1::IElementWiseLayer *conv24 = C2F(network, weightMap, *cat23->getOutput(0), 640, 640, 3, false, 0.5, "model.24"); nvinfer1::IElementWiseLayer *conv25 = convBnSiLU(network, weightMap, *conv24->getOutput(0), 640, 3, 2, 1, "model.25"); nvinfer1::ITensor *inputTensor26[] = {conv25->getOutput(0), conv9->getOutput(0)}; nvinfer1::IConcatenationLayer *cat26 = network->addConcatenation(inputTensor26, 2); nvinfer1::IElementWiseLayer *conv27 = C2F(network, weightMap, *cat26->getOutput(0), 640, 640, 3, false, 0.5, "model.27");OUTPUT
/******************************************************************************************************* ********************************************* YOLOV8 OUTPUT ****************************************** *******************************************************************************************************/ // output0 nvinfer1::IElementWiseLayer *conv28_cv2_0_0 = convBnSiLU(network, weightMap, *conv18->getOutput(0), 64, 3, 1, 1, "model.28.cv2.0.0"); nvinfer1::IElementWiseLayer *conv28_cv2_0_1 = convBnSiLU(network, weightMap, *conv28_cv2_0_0->getOutput(0), 64, 3, 1, 1, "model.28.cv2.0.1"); nvinfer1::IConvolutionLayer *conv28_cv2_0_2 = network->addConvolutionNd(*conv28_cv2_0_1->getOutput(0), 64, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv2.0.2.weight"], weightMap["model.28.cv2.0.2.bias"]); conv28_cv2_0_2->setStrideNd(nvinfer1::DimsHW{1, 1}); conv28_cv2_0_2->setPaddingNd(nvinfer1::DimsHW{0, 0}); nvinfer1::IElementWiseLayer *conv28_cv3_0_0 = convBnSiLU(network, weightMap, *conv18->getOutput(0), 160, 3, 1, 1, "model.28.cv3.0.0"); nvinfer1::IElementWiseLayer *conv28_cv3_0_1 = convBnSiLU(network, weightMap, *conv28_cv3_0_0->getOutput(0), 160, 3, 1, 1, "model.28.cv3.0.1"); nvinfer1::IConvolutionLayer *conv28_cv3_0_2 = network->addConvolutionNd(*conv28_cv3_0_1->getOutput(0), kNumClass, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv3.0.2.weight"], weightMap["model.28.cv3.0.2.bias"]); conv28_cv3_0_2->setStride(nvinfer1::DimsHW{1, 1}); conv28_cv3_0_2->setPadding(nvinfer1::DimsHW{0, 0}); nvinfer1::ITensor *inputTensor28_0[] = {conv28_cv2_0_2->getOutput(0), conv28_cv3_0_2->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_0 = network->addConcatenation(inputTensor28_0, 2); // P2 // output1 nvinfer1::IElementWiseLayer *conv28_cv2_1_0 = convBnSiLU(network, weightMap, *conv21->getOutput(0), 64, 3, 1, 1, "model.28.cv2.1.0"); nvinfer1::IElementWiseLayer *conv28_cv2_1_1 = convBnSiLU(network, weightMap, *conv28_cv2_1_0->getOutput(0), 64, 3, 1, 1, "model.28.cv2.1.1"); nvinfer1::IConvolutionLayer *conv28_cv2_1_2 = network->addConvolutionNd(*conv28_cv2_1_1->getOutput(0), 64, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv2.1.2.weight"], weightMap["model.28.cv2.1.2.bias"]); conv28_cv2_1_2->setStrideNd(nvinfer1::DimsHW{1, 1}); conv28_cv2_1_2->setPaddingNd(nvinfer1::DimsHW{0, 0}); nvinfer1::IElementWiseLayer *conv28_cv3_1_0 = convBnSiLU(network, weightMap, *conv21->getOutput(0), 160, 3, 1, 1, "model.28.cv3.1.0"); nvinfer1::IElementWiseLayer *conv28_cv3_1_1 = convBnSiLU(network, weightMap, *conv28_cv3_1_0->getOutput(0), 160, 3, 1, 1, "model.28.cv3.1.1"); nvinfer1::IConvolutionLayer *conv28_cv3_1_2 = network->addConvolutionNd(*conv28_cv3_1_1->getOutput(0), kNumClass, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv3.1.2.weight"], weightMap["model.28.cv3.1.2.bias"]); conv28_cv3_1_2->setStrideNd(nvinfer1::DimsHW{1, 1}); conv28_cv3_1_2->setPaddingNd(nvinfer1::DimsHW{0, 0}); nvinfer1::ITensor *inputTensor28_1[] = {conv28_cv2_1_2->getOutput(0), conv28_cv3_1_2->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_1 = network->addConcatenation(inputTensor28_1, 2); // output2 nvinfer1::IElementWiseLayer *conv28_cv2_2_0 = convBnSiLU(network, weightMap, *conv24->getOutput(0), 64, 3, 1, 1, "model.28.cv2.2.0"); nvinfer1::IElementWiseLayer *conv28_cv2_2_1 = convBnSiLU(network, weightMap, *conv28_cv2_2_0->getOutput(0), 64, 3, 1, 1, "model.28.cv2.2.1"); nvinfer1::IConvolutionLayer *conv28_cv2_2_2 = network->addConvolution(*conv28_cv2_2_1->getOutput(0), 64, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv2.2.2.weight"], weightMap["model.28.cv2.2.2.bias"]); nvinfer1::IElementWiseLayer *conv28_cv3_2_0 = convBnSiLU(network, weightMap, *conv24->getOutput(0), 160, 3, 1, 1, "model.28.cv3.2.0"); nvinfer1::IElementWiseLayer *conv28_cv3_2_1 = convBnSiLU(network, weightMap, *conv28_cv3_2_0->getOutput(0), 160, 3, 1, 1, "model.28.cv3.2.1"); nvinfer1::IConvolutionLayer *conv28_cv3_2_2 = network->addConvolution(*conv28_cv3_2_1->getOutput(0), kNumClass, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv3.2.2.weight"], weightMap["model.28.cv3.2.2.bias"]); nvinfer1::ITensor *inputTensor28_2[] = {conv28_cv2_2_2->getOutput(0), conv28_cv3_2_2->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_2 = network->addConcatenation(inputTensor28_2, 2); // output3 nvinfer1::IElementWiseLayer *conv28_cv2_3_0 = convBnSiLU(network, weightMap, *conv27->getOutput(0), 64, 3, 1, 1, "model.28.cv2.3.0"); nvinfer1::IElementWiseLayer *conv28_cv2_3_1 = convBnSiLU(network, weightMap, *conv28_cv2_3_0->getOutput(0), 64, 3, 1, 1, "model.28.cv2.3.1"); nvinfer1::IConvolutionLayer *conv28_cv2_3_2 = network->addConvolution(*conv28_cv2_3_1->getOutput(0), 64, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv2.3.2.weight"], weightMap["model.28.cv2.3.2.bias"]); nvinfer1::IElementWiseLayer *conv28_cv3_3_0 = convBnSiLU(network, weightMap, *conv27->getOutput(0), 160, 3, 1, 1, "model.28.cv3.3.0"); nvinfer1::IElementWiseLayer *conv28_cv3_3_1 = convBnSiLU(network, weightMap, *conv28_cv3_3_0->getOutput(0), 160, 3, 1, 1, "model.28.cv3.3.1"); nvinfer1::IConvolutionLayer *conv28_cv3_3_2 = network->addConvolution(*conv28_cv3_3_1->getOutput(0), kNumClass, nvinfer1::DimsHW{1, 1}, weightMap["model.28.cv3.3.2.weight"], weightMap["model.28.cv3.3.2.bias"]); nvinfer1::ITensor *inputTensor28_3[] = {conv28_cv2_3_2->getOutput(0), conv28_cv3_3_2->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_3 = network->addConcatenation(inputTensor28_3, 2);DETECT
/******************************************************************************************************* ********************************************* YOLOV8 DETECT ****************************************** *******************************************************************************************************/ // P2 nvinfer1::IShuffleLayer *shuffle28_0 = network->addShuffle(*cat28_0->getOutput(0)); shuffle28_0->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 4) * (kInputW / 4)}); nvinfer1::ISliceLayer *split28_0_0 = network->addSlice(*shuffle28_0->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 4) * (kInputW / 4)}, nvinfer1::Dims2{1, 1}); nvinfer1::ISliceLayer *split28_0_1 = network->addSlice(*shuffle28_0->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 4) * (kInputW / 4)}, nvinfer1::Dims2{1, 1}); nvinfer1::IShuffleLayer *dfl28_0 = DFL(network, weightMap, *split28_0_0->getOutput(0), 4, (kInputH / 4) * (kInputW / 4), 1, 1, 0, "model.28.dfl.conv.weight"); nvinfer1::ITensor *inputTensor28_dfl_0[] = {dfl28_0->getOutput(0), split28_0_1->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_dfl_0 = network->addConcatenation(inputTensor28_dfl_0, 2); // P3 nvinfer1::IShuffleLayer *shuffle28_1 = network->addShuffle(*cat28_1->getOutput(0)); shuffle28_1->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 8) * (kInputW / 8)}); nvinfer1::ISliceLayer *split28_1_0 = network->addSlice(*shuffle28_1->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 8) * (kInputW / 8)}, nvinfer1::Dims2{1, 1}); nvinfer1::ISliceLayer *split28_1_1 = network->addSlice(*shuffle28_1->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 8) * (kInputW / 8)}, nvinfer1::Dims2{1, 1}); nvinfer1::IShuffleLayer *dfl28_1 = DFL(network, weightMap, *split28_1_0->getOutput(0), 4, (kInputH / 8) * (kInputW / 8), 1, 1, 0, "model.28.dfl.conv.weight"); nvinfer1::ITensor *inputTensor28_dfl_1[] = {dfl28_1->getOutput(0), split28_1_1->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_dfl_1 = network->addConcatenation(inputTensor28_dfl_1, 2); // P4 nvinfer1::IShuffleLayer *shuffle28_2 = network->addShuffle(*cat28_2->getOutput(0)); shuffle28_2->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 16) * (kInputW / 16)}); nvinfer1::ISliceLayer *split28_2_0 = network->addSlice(*shuffle28_2->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 16) * (kInputW / 16)}, nvinfer1::Dims2{1, 1}); nvinfer1::ISliceLayer *split28_2_1 = network->addSlice(*shuffle28_2->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 16) * (kInputW / 16)}, nvinfer1::Dims2{1, 1}); nvinfer1::IShuffleLayer *dfl28_2 = DFL(network, weightMap, *split28_2_0->getOutput(0), 4, (kInputH / 16) * (kInputW / 16), 1, 1, 0, "model.28.dfl.conv.weight"); nvinfer1::ITensor *inputTensor28_dfl_2[] = {dfl28_2->getOutput(0), split28_2_1->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_dfl_2 = network->addConcatenation(inputTensor28_dfl_2, 2); // P5 nvinfer1::IShuffleLayer *shuffle28_3 = network->addShuffle(*cat28_3->getOutput(0)); shuffle28_3->setReshapeDimensions(nvinfer1::Dims2{64 + kNumClass, (kInputH / 32) * (kInputW / 32)}); nvinfer1::ISliceLayer *split28_3_0 = network->addSlice(*shuffle28_3->getOutput(0), nvinfer1::Dims2{0, 0}, nvinfer1::Dims2{64, (kInputH / 32) * (kInputW / 32)}, nvinfer1::Dims2{1, 1}); nvinfer1::ISliceLayer *split28_3_1 = network->addSlice(*shuffle28_3->getOutput(0), nvinfer1::Dims2{64, 0}, nvinfer1::Dims2{kNumClass, (kInputH / 32) * (kInputW / 32)}, nvinfer1::Dims2{1, 1}); nvinfer1::IShuffleLayer *dfl28_3 = DFL(network, weightMap, *split28_3_0->getOutput(0), 4, (kInputH / 32) * (kInputW / 32), 1, 1, 0, "model.28.dfl.conv.weight"); nvinfer1::ITensor *inputTensor28_dfl_3[] = {dfl28_3->getOutput(0), split28_3_1->getOutput(0)}; nvinfer1::IConcatenationLayer *cat28_dfl_3 = network->addConcatenation(inputTensor28_dfl_3, 2); nvinfer1::IPluginV2Layer *yolo = addYoLoLayer(network, std::vector<nvinfer1::IConcatenationLayer *>{cat28_dfl_0, cat28_dfl_1, cat28_dfl_2, cat28_dfl_3}); yolo->getOutput(0)->setName(kOutputTensorName); network->markOutput(*yolo->getOutput(0));
-
-
修改
yololayer.cu中forwardGpu方法void YoloLayerPlugin::forwardGpu(const float *const *inputs, float *output, cudaStream_t stream, int mYoloV8netHeight, int mYoloV8NetWidth, int batchSize) { int outputElem = 1 + mMaxOutObject * sizeof(Detection) / sizeof(float); cudaMemsetAsync(output, 0, sizeof(float), stream); for (int idx = 0; idx < batchSize; ++idx) { CUDA_CHECK(cudaMemsetAsync(output + idx * outputElem, 0, sizeof(float), stream)); } int numElem = 0; // int grids[3][2] = {{mYoloV8netHeight / 8, mYoloV8NetWidth / 8}, {mYoloV8netHeight / 16, mYoloV8NetWidth / 16}, {mYoloV8netHeight / 32, mYoloV8NetWidth / 32}}; // todo int grids[4][2] = {{mYoloV8netHeight / 4, mYoloV8NetWidth / 4}, {mYoloV8netHeight / 8, mYoloV8NetWidth / 8}, {mYoloV8netHeight / 16, mYoloV8NetWidth / 16}, {mYoloV8netHeight / 32, mYoloV8NetWidth / 32}}; // int strides[] = { 8, 16, 32 }; // todo int strides[] = {4, 8, 16, 32}; // for (unsigned int i = 0; i < 3; i++) // todo for (unsigned int i = 0; i < 4; i++) { int grid_h = grids[i][0]; int grid_w = grids[i][1]; int stride = strides[i]; numElem = grid_h * grid_w * batchSize; if (numElem < mThreadCount) mThreadCount = numElem; CalDetection<<<(numElem + mThreadCount - 1) / mThreadCount, mThreadCount, 0, stream>>>(inputs[i], output, numElem, mMaxOutObject, grid_h, grid_w, stride, mClassCount, outputElem); } } -
修改
main.cpp->serialize_engine,增加一个sub_type... else if (sub_type == "x-p2") { serialized_engine = buildEngineYolov8x_p2(builder, config, DataType::kFLOAT, wts_name); } ... -
参考作者 (https://github.com/wang-xinyu/tensorrtx/tree/master/yolov8) , 获取wts , 然后生成模型.
./yolov8 -s ./weights/xxx.wts ./weights/xxx.engine x-p2 -
推理模型测试
./yolov8 -d xxx.engine ../images g
END
- 官网中没有找到p2的预训练模型,所以需要根据自己数据集训练模型
- 自己训练模型需要更改
config.h中对应的参数. - 以上纯手工输出,若有不对,欢迎大佬指正.
参考:
- https://github.com/ultralytics/ultralytics/tree/main
- https://github.com/wang-xinyu/tensorrtx/tree/master/yolov8