言叔记面试题
不久前,我的项目组解散了。我又开始继续背面试题了。然后也顺利找到新的工作了。以下是我当时背的面试题。
sql优化:
- 使用索引 :expalin可以查看sql语句是否使用了索引(方便查询,缺点:删除不容易)
- 避免在where子句中对字段进行null判断,(建议:设置默认值0)
- 避免在where子句中使用!=、或<>操作符,否则放弃使用索引而进行全局搜索
存储过程:
是一组为了完成特定功能的 SQL 语句集合。使用存储过程的目的是将常用或复杂的工作预先用 SQL 语句写好并用一个指定名称存储起来,这个过程经编译和优化后存储在数据库服务器中,因此称为存储过程。当以后需要数据库提供与已定义好的存储过程的功能相同的服务时,只需调用“CALL存储过程名字”即可自动完成。
连接池:
数据库连接池是负责分配、管理、释放数据库连接的,它允许程序重复使用一个现有的数据库连接。
静态变量和全局变量的区别:
静态变量被static修饰。调用时用类.变量名。
linux命令:
1、授权:命令:chmod +x aaa.txt
2、压缩:tar -zcvf ab.tar
c:打包文件
v:显示运行过程
f:指定文件名
x:代表解压
tar -zcvf ab.tar aa.txt bb.txt
tar -xvf ab.tar -C /usr------C代表指定解压的位置
3、用户切换
su用于用户之间的切换。sudo是为所有想使用root权限的普通用户设计的。
4、查看进程
ps -ef 查看所有正在运行的进程
5、find命令在目录结构中搜索文件,并对搜索结果执行指定的操作。
find . -name “.log" -ls 在当前目录查找以.log结尾的文件,并显示详细信息。
find /root/ -perm 600 查找/root/目录下权限为600的文件
find . -type f -name ".log” 查找当目录,以.log结尾的普通文件
6、 结束进程:kill
命令:kill pid 或者 kill -9 pid(强制杀死进程) pid:进程号
docker命令
2、下载容器:
docker pull docker.io/nginx
3、查看本地镜像
docker images
4、使用docker run命令启动
docker run -d -p 8080:80 nginx
5、停止容器
docker stop 容器id
6、删除镜像和容器
docker rm 容器id 删除容器
docker rmi 镜像id 删除镜像
SpringBoot开发自定义注解
单点登录
单点登录是指多系统应用群中登录一个系统,便可在其他所有系统中得到授权而无需再次登录,包括单点登录与单点注销部分。
1、登录:
相比于单系统登录,sso需要一个独立的认证中心,只有认证中心能接受用户的密码等安全信息,其它系统不提供登录入口,只提供认证中心的间接授权。简介授权通过令牌实现,sso认证中心判断密码。创建授权令牌,在接下来的跳转过程中,授权令牌作为参数发送给哥哥子系统,子系统拿到令牌,即得到了授权。
设计模式:
类加载机制:
进程是系统资源的最小执行单位,
Springboot:
自定义注解:
类反射:
需求输入,数据库设计
js刷新当前页面的5种方式:
reload() 方法用于重新加载当前文档。
arrayList默认长度是10,hashMap默认长度是16
nacos使用步骤:
1、yaml文件里面添加nacos注册地址以及注册名称
2、项目启动类添加@EnableDiscoveryClient
模块之间互相调用:
1、要调用的配置类上面标注@EnableDiscoveryClient
2、开启远程调用功能 @EnableFeignClients(basePackages="com.atguigu.gulimall.member.feign") *要指定远程调用功能放的基础包*
3、@FeignClient("gulimall-coupon") //告诉spring cloud这个接口是一个远程客户端,要调用coupon服务(nacos中找到),具体是调用coupon服务的/coupon/coupon/member/list对应的方法
public interface CouponFeignService {
// 远程服务的url
@RequestMapping("/coupon/coupon/member/list")//注意写全优惠券类上还有映射//注意我们这个地方不是控制层,所以这个请求映射请求的不是我们服务器上的东西,而是nacos注册中心的
public R membercoupons();//得到一个R对象
}
hashMap存储原理
- 如果 table 数组为空时先创建数组,并且设置相关的加载因子,和扩容阈值;注意:HashMap不是一开始就初始化的,而是在首次put的时候初始化
- 根据键值key计算hash值得到插入的数组索引i,如果table[i]==null,直接新建节点添加。判断table[i]的首个元素是否和key一样,如果相同直接覆盖value,否则转向④,这里的相同指的是hashCode以及equals;
- 遍历table[i],判断链表长度是否大于8,大于8的话把链表转换为红黑树,在红黑树中执行插入操作,否则进行链表的插入操作;遍历过程中若发现key已经存在直接覆盖value即可;
- .插入成功后,判断实际存在的键值对数量size是否超多了最大容量threshold,如果超过,进行扩容。
我们在考虑HashMap的时候,首先要想到的是HashMap只是一个数据结构,既然是数据结构最主要的就是节省时间和空间。负载因子的作用肯定也是节省时间和空间。比如说当前的容器容量是16,负载因子是0.75,16*0.75=12,也就是说,当容量达到了12的时候就会进行扩容操作。
get取值的方法,过程如下:
1、指定key 通过hash函数得到key的hash值
2、比较桶的内部元素是否与key相等,若都不相等,则没有找到。相等,则取出相等记录的value。
3、如果得到 key 所在的桶的头结点恰好是红黑树节点,就调用红黑树节点的 getTreeNode() 方法,否则就遍历链表节点。getTreeNode 方法使通过调用树形节点的 find()方法进行查找。由于之前添加时已经保证这个树是有序的,因此查找时基本就是折半查找,效率很高。
⑤.如果对比节点的哈希值和要查找的哈希值相等,就会判断 key 是否相等,相等就直接返回;不相等就从子树中递归查找。
jvm理解:
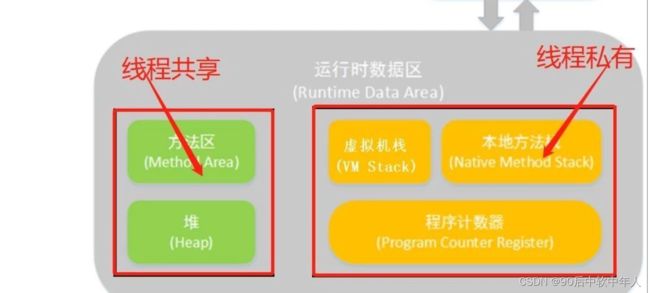
1、栈由系统自动分配,而堆是人为申请开辟;2、栈获得的空间较小,而堆获得的空间较大;3、栈由系统自动分配,速度较快,而堆一般速度比较慢;4、栈是连续的空间,而堆是不连续的空间。
0x01:程序计数器(Program Counter Register)
程序计数器(Program Counter Register)是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。在虚拟机概念模型里(概念模型,各种虚拟机可能会通过一些更高效的方式实现),字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令:分支、跳转、循环、异常处理、线程恢复等基础操作都会依赖这个计数器来完成。
虚拟机栈(VM Stack)
JVM栈是线程私有的内存区域。它描述的是java方法执行的内存模型,每个方法执行的同时都会创建一个栈帧(Stack Frame)用于存储局部变量表、操作数栈、动态链接、方法出口等信息
本地方法栈( Native Method Stack)
本地方法栈和虚拟机栈所发挥的作用是很相似的,它们之间的区别不过是虚拟机栈为虚拟机执行Java方法(字节码)服务,而本地方法栈则为虚拟机使用到的Native方法服务。
0x04:堆(Heap)
Heap是OOM故障最主要的发源地,它存储着几乎所有的实例对象,堆由垃圾收集器自动回收,堆区由各子线程共享使用;通常情况下,它占用的空间是所有内存区域中最大的
方法区(Method Area)
方法区是被所有线程共享的内存区域,用来存储已被虚拟机加载的类信息、常量、静态变量、JIT(just in time,即时编译技术)编译后的代码等数据。
Java的反射机制
反射机制的应用场景:
- 逆向代码 ,例如反编译
- 单纯的反射机制应用框架 例如EventBus 2.x
- 单例模式
线程池如果问到了,直接说在网上找的,jdk或者spring提供的,具体的不是特别了解。jvm其实只要了解堆栈和垃圾回收机制问题就行了。
做自己的强者,不借谁的光。