volatile解决有序性和可见性问题
线程可见性问题分析
什么是可见性?
如果一个线程对一个共享变量进行了修改 而其他线程不能及时地读取修改后的值 所以在多线程情况下该共享变量就会存在可见性问题
package com.alipay.alibabademo.thread;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.FutureTask;
@Slf4j
public class ThreadDemo {
public static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(()->{
int count = 0;
while (!flag) {
count++;
}
});
thread.start();
System.out.println("start Thread");
Thread.sleep(1000);
flag = true;
}
}
通过flag变量判断是否终止循环 然而在main线程中通过修改flag变量的值破坏循环状态 但是实际情况是线程还一直处于运行状态 那么这是为什么呢?
上述案例问题出现的原因
在HotSpot虚拟机中内置了两个即时编译器 分别是ClientComplier(C1) 编译器和ServerComplier编译器(C2编译器)程序使用哪个编译器取决于JVM虚拟器的运行状态
ServerComplier是专门面向服务器端的 充分优化过的高级编译器他有一些比如代码消除等功能 上述例子中通过ServerComplier中的循环表达式外提进行优化变成了
package com.alipay.alibabademo.thread;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.FutureTask;
@Slf4j
public class ThreadDemo {
public static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(()->{
int count = 0;
if (!flag){
while (true) {
count++;
}
}
});
thread.start();
System.out.println("start Thread");
Thread.sleep(1000);
flag = true;
}
}
被优化的代码对flag变量不具备变化的能力因此会导致当其他线程修改flag的值时该线程无法读取
volatile解决可见性问题
上述问题如果我们在共享变量上加一个volatile就可以充分的解决问题由此可见volatile可以禁止编译器的优化在多处理器环境下保证共享变量的可变性
package com.alipay.alibabademo.thread;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.FutureTask;
@Slf4j
public class ThreadDemo {
public volatile static boolean flag = false;
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(()->{
int count = 0;
while (!flag) {
count++;
}
});
thread.start();
System.out.println("start Thread");
Thread.sleep(1000);
flag = true;
}
}
可见性问题的本质
怎么提升CPU的利用率
CPU是计算机最核心的资源 当程序加载到内存后 操作系统会把当前线程分配给指定的CPU执行在获取CPU 的执行权后CPU从内存中取出指令进行解码并执行然后取出下一个指令继续执行
CPU在做运算的时候,无法避免要从内存中读取数据和指令 CPU的运算速度远远高于内存的I/O速度
CPU在做计算时必须与内存交互 即使是存储在磁盘上的数据也要先加载到内存中 CPU才能访问

基于上述的分析中可以看到 当CPU发起一个读操作时 在等待内存返回之前CPU都处于等待状态 直到返回之后CPU继续运行下一个指令 这个过程很显然会导致CPU资源的浪费为了解决这一问题 开发者在硬件设备 操作系统及编译器层面做了很多优化
1.在CPU层面增加了寄存器 来保存一些关键变量和临时数据还增加了CPU高速缓存以减少CPU和内存IO等待时间
2.在操作系统层面引入进程和线程 也就是在当前进程或线程处于阻塞状态时CPU会把自己的时间片分配给其他线程或进程使用 从而减少CPU空闲时间最大优化提升CPU使用率
3.在编译器层面面增加了指令优化 减少与内存的交互次数
这些优化虽然提升了CPU的利用率 但是也正好是导致可见性问题发生的原因
CPU高速缓存
CPU和内存的I/O操作时无法避免的 为了降低内存的I/O耗时 开发者在CPU中设计了高速缓存,用存储与内存交互的数据,CPU在做读操作时 ,会先从高速缓存中读取目标数据,如果目标数据不存在 就会从内存中加载目标数据并保存到高速缓存中在返回给处理器。
主流的X86处理器中 CPU高速缓存通常分为L1、L2、L3三级 具体的结构如下图

L1和L2是CPU的缓存属于CPU私有的
L1是CPU硬件的缓存 它分为数据缓存和指令缓存(指令缓存用来处理CPU必须要执行的操作信息 数据缓存用来存储CPU要操作的数据)
L2也是CPU硬件的缓存 容量比L1大 但是速度比L1慢
L3是CPU高速缓存中最大的一块同时也是访问速度最慢的缓存 也是共享的缓存
当CPU读取数据时 会先尝试从L1缓存中查找 如果L1缓存未命中 继续从L2和L3缓存中查找 如果在缓存行中没有命中到目标数据然后才会去访问内存。当从内存中加载数据时会优先扭转到L3缓存在到L2 最后到L1缓存 当后续再次访问存在于缓存行中的数据时CPU可以不需要访问内存 从而提升CPU效率
缓存行
CPU的高速缓存是由若干个缓存行组成的,缓存行是CPU高速缓存的最小存储单位 也是CPU和内存交换数据的最小单元在X86架构中 每个缓存行大小为64位 ,CPU每次从内存中加载8字节的数据作为一个缓存行保存到高速缓存中 这就意味着高速缓存中存在的是连续位置的数据
CPU缓存一致性问题
CPU高速缓存的设计大大的提升了CPU运算性能 但是它也存在一个问题,由于CPU中L1和L2缓存是CPU私有的 如果两个线程同时加载同一块数据并保存到高速缓存中 再分别进行修改 那么缓存一致性就得不到保证

如图所示 两个CPU的高速缓存都缓存了 count =0 的值 当CPU1将count+1 此时count=1 但是这个修改只对本地缓存可见 当后续CPU0在对Count进行计算的时候 它获取的值依然是0 此时缓存就不一致了
总线锁和缓存锁
为了解决CPU缓存一致性问题 在CPU层面引入了总线索和缓存锁机制
总线
所谓的总线就是与CPU交互 输入/输出设备传递消息的公共通道 当CPU访问内存进行数据交互时 必须经过总线来传输
总线锁
简单来说就是在总线上声明一个Lock#信号 这个信号能够确保共享内存只有当前CPU可以访问 其他处理器被阻塞 这样可以使得同一时刻访问共享内存 从而解决共享问题 但是代价就是性能的降低让人难以接受 所以后续引入了缓存锁
缓存锁
缓存锁指的是如果当前CPU访问的数据已经缓存在其他CPU的高速缓存中 那么CPU不会再总线上声明Lock#信号而是采用缓存一致性协议来保证多个CPU的缓存一致性
CPU最终采用那种锁解决缓存一致性问题 取决于当前CPU是否支持缓存锁 如果不支持就会采用总线锁 或者当前操作的数据不能被缓存在处理器内存 或者操作的数据跨多个缓存行时 也会使用总线锁
缓存一致性协议
MESI
缓存锁通过缓存一致性协议(MESI)来保证缓存的一致性
M(Modify)
表示共享数据只缓存在当前CPU缓存中 并且是被修改状态 缓存的数据和主内存的数据不一致
E(Exclusive)
表示缓存的独占状态 数据只缓存在当前CPU缓存中 并且没有被修改
S(Shared)
表示数据可能被多个CPU缓存 并且各个缓存中的数据和主内存数据一致
I(Invalid)
表示缓存已经失效
监听任务
MESI的四种状态会基于CPU对缓存行的操作而产生转移 所利益MESI针对不同的状态添加了不同的监听任务
1.如果一个缓存行处于M状态 则必须监听所有试图获取该缓存行对应的主内存地址的操作 如果监听这类操作的发生 则必须在该操作 之前把缓存行中的数据写回主内存
2.如果缓存行处于S状态 那么则必须要监听使该缓存行状态设置为Invalid 或者对缓存行执行Exclusive操作的请求 如果存在则必须要把当前缓存行状态设置为Invalid
3.如果一个缓存行状态为E状态 那么它必须要监听其他试图读取该缓存行对应的主内地址的操作一旦有这种操作该缓存行需要设置成Shared
整个的监听过程是通过CPU中Snoopy的嗅探协议完成的 该协议要求每个CPU缓存都可以监听到总线上的数据事件并作出相应的反应 所以CPU都会监听地址总线上的事件 当某个处理器发出请求时 其他CPU会监听到地址总线的请求根据当前缓存行的状态及监听的请求类型对缓存行状态进行更新
总结可见性问题的本质原因和解决方案
由于CPU高速缓存的设计导致了缓存一致性问题 又为了解决这一问题 设计了总线锁和缓存锁。
指令重排序
什么是指令重排序
指令重排序就是指编译器或CPU为了优化程序的执行性能而对指令进行重排序的一种手段 重排序会带来可见性问题。
从源码到最终运行的指令 会经过两个阶段的重排序
第一阶段:编译器重排序
在编译过程中编译器根据上下文分析对指令进行重排序 目的是减少CPU和内存的交互 重排序之后尽可能保证CPU从寄存器或缓存行中读取数据
第二阶段:处理器重排序 处理器重排序又分为两个部分
1.并行指令集重排序
处理器可以改变指令的执行顺序
2.内存系统重排序
引入Store Buffer缓冲区延时写入产生的指令顺序执行不一致的问题
as-if-serial语义
所有的程序指令都可以因为优化而被重排序 但是必须是在单线程环境下单线程环境下 运行结果和重排序之后的结果一致
指令重排序的本质
CPU通过引入了高速缓存来提升利用率 并且基于缓存一致性来保证缓存的一致性 但是缓存一致性会影响CPU的使用效率
假设存在一个S状态的缓存行(CPU0和CPU1共享同一个缓存行 )如果CPU9对缓存进行修改 那么CPU需要发送一个Invalidate消息到CPU1 在等待CPU1回复的这个时间段 CPU0一直处于空闲状态

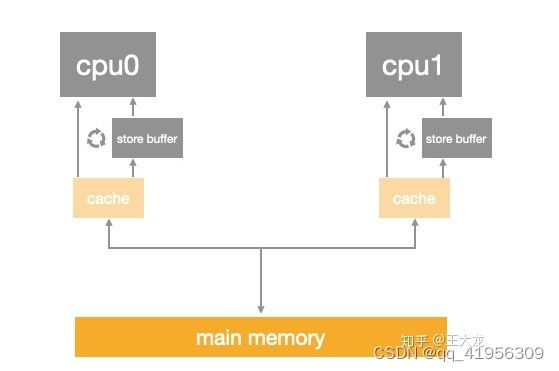
Store Buffer
为了防止这种空闲等待状态 CPU层面又设计了一个Store Buffer

Cpu0引入Store Buffer的设计后 CPU0会先发送一个Invalidate消息给其他包含该缓存行的CPU1 并把当前修改的数据写入StoreBuffers中 然后继续执行后续的指令 等收到CPU1的Ack消息后 Cpu0再把Store Buffer挪到缓存行
Store Buffer引发的问题可见性问题
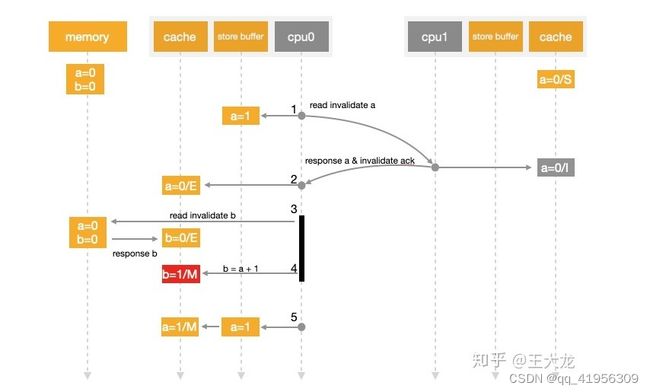
1.假设a 变量的缓存状态是SharedCpu0执行a=1的指令 此时a不存在cpu0的缓存中 但是在其他cpu缓存中他是Shared状态 所以cpu0会发送一个MESI协议消息 read invalidate给CPU1 企图从其他缓存了该变量 cpu中去读取值 并使得其他cpu缓存行失效
2.cpu0把a=1写入cpu0的store buffer中
3.CPU1收到read invalidate消息后 返回 ReadResponse 把 a=0返回 并让cpu1的缓存行失效
4.由于StoreBuffer存在 cpu0在等待cpu1返回之前就继续往下执行b=a+1的指令此时Cache 中还没有加载b 所以b=0
5.cpu0 收到其他cpu返回的结果 更新了缓存行 a=0 接着加载出了a=0
6.接着cpu0把store buffer a=1的数据同步到缓存行中
7.结果判断失败
Store Forwarding
为了解决Store Buffer引起的问题又设计了Store Forwarding 在每个CPU加载数据之前会先引用当前CPU的Store Buffers也就是说支持将CPU存入Store Buffers的数据传递给后续的加载操作而不需要经过Cache
Store Forwarding带来的指令重排序问题

1.CPU0执行a=1的指令 a是独占且a不存在cou0的缓存行中 因此cpu0把a=1写入StoreBuffer中并发送MESI协议消息给 cpu1
2.cpu1执行 b=1的操作 cpu1的缓存行中没有b的缓存 所以cpu1发出一个MESI协议消息 给cpu0
3.cpu0执行 b=1的指令 而B变量 存在于CPU0的缓存行中 也就说缓存行属于M或者E状态 因此直接把b=1写入缓存行
4.此时cpu0收到 cpu1发来的消息 将缓存行中的B=1返回给cpu1 并修改缓存状态为 S
5.CPU1 修改缓存行 b=1并将状态设置为S
6.获取b=1后 cpu1继续执行assert(a=1)的指令 此时cpu1的缓存行中 a=0
7.cpu1收到cpu0的消息把包含a=0的缓存行 返回给cpu0 并设置成I(失效)但此时这个过程比前面的异步步骤执行晚已经导致了问题
8.CPU0收到包含a的缓存行后 把 stre buffer中a=1同步到缓存行
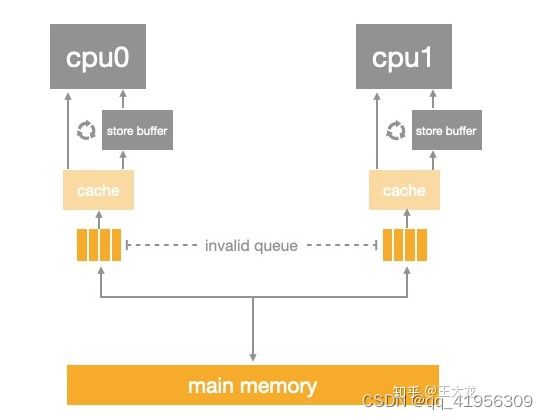
Invalidate Queues(用于让缓存行失效的消息)
Store Buffes 确实进一步提升了CPU的利用率 但是Store Buffes本身的存储容量是有限的 在当前CPU的所有写入操作都存在缓存未命中的情况时 就会导致StoreBuffers 很容易被填满 被填满之后必须等待CPU返回 Invalidate Acknowledge消息 Store Buffers中对应的指令才能被清理 而这个过程CPU必须等待 无论该CPU中后续指令是否存在缓存未命中的情况
当前CPU 之所以要等待 Invalidate Acknowledge的消息才会去清理指令 是因为CPU必须要确保缓存的一致性 但是如果收到 Invalidate 消息的CPU当时处于繁忙状态 那么会导致 Invalidate Acknowledge消息返回延迟 ,我们发现CPU在发送 Invalidate Acknowledge消息之前 并不需要立刻使缓存行失效 反过来 我们也可以按照Store Buffes的设计理念增加一个 Invalidate Queues用来存放让缓存行失效的消息 也就是说 CPU收到Invalidate 消息时 把让该缓存行失效的消息放入 Invalidate Queues然后同步返回一个 Invalidate Acknowledge消息这样就大大的缩短了响应时间
Invalidate Queues导致的问题
增加了Invalidate Queues之后 CPU发出的Invalidate 消息能够很快得到其他CPU发送的 Invalidate Acknowledge消息从而加快了 Store Buffers中指令的处理效率 减少了CPU的阻塞问题 但是 Invalidate Queues存在会导致CPU内存系统wreite操作的重排序问题

- cpu0执行a=1,由于其有包含a的cache line,将a写入store buffer,并发出Invalidate a消息。
- cpu1执行while(b == 0),它没有b的cache,发出Read b消息。
- cpu1收到cpu0的Invalidate a消息,将其放入Invalidate Queue,返回Invalidate ACK。
- cpu0收到Invalidate ACK,将store buffer中的a=1刷新到cache line,标记为Modified。
- cpu0看到smp_wmb()内存屏障,但是由于其store buffer为空,因此它可以直接跳过该语句。
- cpu0执行b=1,由于其cache独占b,因此直接执行写入,cache line标记为Modified。
- cpu0收到cpu1发的Read b消息,将包含b的cache line写回内存并返回该cache line,本地的cache line标记为Shared。
- cpu1收到包含b(当前值1)的cache line,结束while循环。
- cpu1执行assert(a == 1),由于其本地有包含a旧值的cache line,读到a初始值0,断言失败。
- cpu1这时才处理Invalid Queue中的消息,将包含a旧值的cache line置为Invalid
内存屏障解决指令重排序问题
在不同的应用中为了防止CPU的指令重排序 必然会使用CPU提供的内存屏障指令 在Linux的内核中 这三种指令分别封装成smp_mb()、smp_rmb()、smp_wmb
smp_mb:
是全屏障 基于Lock指令来实现 ,声明lock指令后在多处理器环境下 通过总线锁/缓存锁机制来保证执行指令的原子指令
lock指令隐含了一个内存屏障的语义 也就是说 修饰了lock指令的数据能够避免CPU内存重排序文图
smp_wmb:
通过barrier方法实现写屏障
1.读屏障(ifence)
将Invalidate Queues中的指令立即处理 并且强制读取cpu的缓存行 执行 ifence指令之后的读操作不会被重排序到ifence指令之前这意味着其他cpu 暴露出来的缓存行对当前cpu可见
2.写屏障(sfence)
会把 store Buffers中修改刷新到本地缓存中 使得其他cpu可以看到这些修改 而且在执行sfence指令之后的写操作不会重排序到 sfence指令之前 这意味着sfence指令之前的写操作全局可见
3.读写屏障(mfence)
保证了 mfence指令执行前后的读写操作的顺序 同时要求执行 mfence指令之后的写操作全局可见 之前的写操作全局可见
Java Memory Mode
在多线程环境中导致可见性问题的根本原因是CPU的高速缓存及指令重排序 虽然CPU层面提供了内存屏障及锁的机制来保证有序性 然而在不同的CPU类型中 又存在不同的内存屏障指令 Java作为一个跨平台语言 必须要针对不同的底层操作系统和硬件提供统一的线程安全性保证 Java Memory Mode就是这样的一个模型
Java Memory Mode也是一种规范 该规范定义了线程和主内存之间访问规则的抽象关系
总结volatile怎么解决的可见性问题和指令重排序问题
volatile关键字会在JVM层面声明一个C++的volatile 他能防止JIT层面的指令重排序
在对修饰了volatile关键字的字段复制后 JVM会调用 storeload()内存屏障方法该方法声明了lock指令 该指令有两个作用
1.在CPU层面给stip赋值的指令会先存储到StoreBuffers中 所以Lock指令会使得StoreBuffers的数据刷新到缓存行
2.使得其他CPU缓存了该字段的缓存行失效 也就是让存储在Invalidate Queues中的对该字段缓存行失效指令立即生效,当其他线程再去读取该字段的值时会先从内存中或者其他缓存了该字段的缓存行中重新读取从而获得最新的值
Happens-Before模型
Happens-Before用来描述两个操作指令的顺序关系 如果一个操作和另外一个操作存在Happens-Before关系 那么意味着一个操作对第二个操作可见
Happens-Before规则
程序顺序规则(as-if-serial)
一个线程中 存在两个操作 x和y 并且x源代码执行在y之前
传递性规则
如果
A Happens-Before B
B Happens-Before C
那么A 必然 Happens-Before C 不管在单线程还是多线程中传递性规则都能够提供可见性保障
volatile规则
通过内存屏障来保证 volatile变量修饰的写操作一定 Happens-Before读操作
监视器锁规则
一个线程释放锁必须 Happens-Before 后续线程的加锁操作
start 规则
一个线程调用start方法之前的所有操作 Happens-Before 线程B的任意操作
join 规则
main线程执行了一个线程A的join方法并成功返回 那么线程A中的任意操作 Happens-Before 于main线程线程join方法返回之后的操作