Redis核心数据结构及底层原理详解
1.redis缓存的数据结构
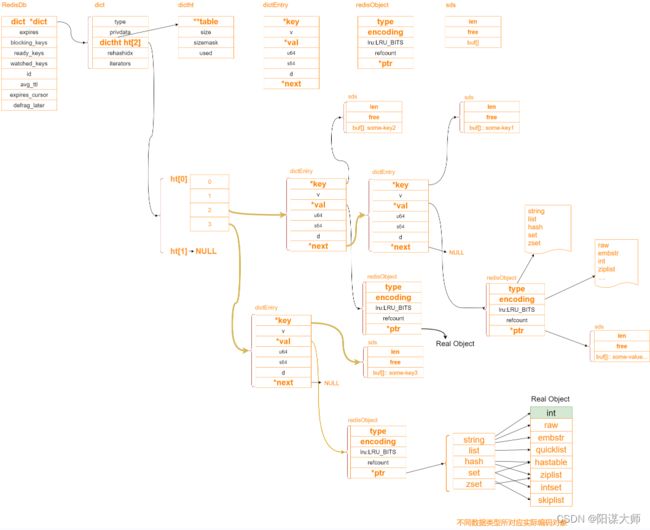
redis底层是一个键值对的结构,我们可以理解为redis是一个大的map(dict:字典),key是string结构,网上很多表示说redis的key可以用string,int,double,float类型作为key,但是,redis客户端在向server端传递数据时,是序列化成一个byte[]数组来传递的,到server端再反序列化,直接构建成了redis的string类型。redis的string类型底层是又SDS数据结构来实现的,SDS在后面五种数据类型会详细解释,这里不做过多赘述。key,vaule底层是通过数组,链表的数据结构实现的。
redis key是string通过hash()加数组的模运算(数组-1的与运算)来定位数组坐标的,然后数组内存放的是一个链表,我们以java角度来解释那就是一个链式结构类型的一个node对象,有key,value,next三个属性,如果有hash冲突的话,next会存放下一个hash值相同的key,value,但是redis发生hash冲突后,链表会采用头插法的方式将冲突数据放在前面。既然redis是通过数组存储key,value值的,那么redis数组是如何扩容的呢?redis数组在数组存满后会重新开辟一个数组,容量是原数组*2,然后进行数据迁移,例:len:4->8。但是如果我们数据量特别大的时候,创建新的数组进行数据迁移会非常浪费时间,这个肯定是不被允许的,所以redis采用的是渐进式扩容(rehash)
什么是渐进式扩容,就是redis在创建好扩容数组后,我们平时访问某一个key的时候,它会选择一部分key进行迁移拷贝,当没有事件发生的时候,它会有一个事件轮询机制,循环的进行数据迁移,直到数据迁移完,然后释放原来的数组,所以redis里层有两个结构,dict,dictht,就是用来做rehash的。
那么,rehash的时候插入数据会怎么样,如果是新插入的数据,会直接添加到扩容后的数组里面。如果是修改以前的数据,那么会将以前的数据拷贝到新的数组中去。
接着来看,扩容未完成之前,如果有数据查询的时候,会先从旧数组中查找,如果找不到则会再从新数组中查找。如果从旧数组中找到,则会将此数据迁移到新数组。
redis 有16个db
redis db主体数据结构
2.redis五种应用级数据结构及其用法
String:mset,mget,setnx,exprie,incr,in 可以用来做参数缓存,分布式锁,对象存储,底层是SDS(simple dynamic string)简单动态字符串
list:HADD,RPUSH......... 用来做数组,队列,
hash:HSET,HGET,HMSET,HMGET,HLEN,HGETALL,用来做对象存储,商城购物车等
set:用来做社交软件人际关系结构,我认识的人,我可能认识的人,我和他共同认识的人等(交际并集)
zset:做新闻事实热点,有一个score权值,可以做延迟队列
HyperLogLog:是一种用来做统计估算的结构,底层是伯努利实验加极大似然估算法,并做了分桶优化,可以用来做日活用户统计的场景
GEO:一种定位位置的算法结构,底层用skiplist来实现的,可以用来做附近的人的场景
4.reidis五种数据结构底层原理
string:底层是SDS实现的,SDS(simple dynamic string 简单动态字符串)
redis底层使用C语言实现的,C语言实现字符串是用字符数组实现,redis使用sds结构实现,他有三个属性:free,len,char[] buf。
char[] buf属性就是存放我们key的字符数组。C语言在存放字符串的时候会在末尾添加\0,读取数据的时候如果读到\0则会返回,这样的话,如果我们字符串中存在\0这种字符的话就会导致字符丢失。redis是通过len这个属性解决的,它会先判断len的值,然后读取数组中对应长度的字符组成字符串,所以它是安全的。其次它每次存放数组的时候都会默认在字符后面添加\0,这样就兼容了C语言。
其次,redis sds扩容机制:举个例子:假设原字符数组长度为6,如果字符串增加三个字符,那么redis就会创建新数组,长度为:原数组长度+增加字符长度然后乘以2(6+3)*2 = 18,这样len = 9,free = 9,就是因为这样的预分配机制,可以让redis避免了频繁的内存分配。
总结一下就是:
1).二进制安全的数据结构;
2).提供了内存的预分配机制,避免了频繁的内存分配;
3).兼容了C语言的函数库
list:底层使用双端链表和zipList组成的,先来看ziplist的结构

此图就是ziplist的原理图
首先ziplist是一个连续内存空间的,顺序的结构,类似于数组,紧凑型
1).zlbytes:存放的是ziplist的大小
2).zltail:尾节点索引的位置
3).zllen:ziplist的元素个数
4).zllend:一个字节,恒等于255,用来表示元素结尾
5).entry:ziplist的元素对象,可以这么理解
6).prerawlen:上一个entry对象data的长度
7).len:当前entry对象data的长度
8).date:实际的数据
这个结构看起来异常的晦涩难懂,我们简单来理解一下。
我们从大的ziplist结构来看,当我们读取内存,我们在读完zllen时就可以顺序拿出一个一个元素了,但是如果我们要倒序读,那么我们可以先从ztail获取末尾元素的索引位置,然后通过zllen属性,直接定位到zlend这个属性的位置,这样我们就可以从末尾把entry一个一个拿出来
那entry是怎么实现双端查找的呢,它主要靠entry的len和prerawlen这两个属性来实现的,顺序的话主要靠len这个属性,当我们读到len的值时,我们就可以按照len的值读取对应的比特位,举个例子(len属性的读取具体看图哈,很容易看懂的),当我们len属性的值前两个比特位是00,那么我们就知道后六位bit表示长度,我们读出来长度是5的话,那么我们就可以继续读取5个bit位的数据来获取到data,这样这个entry就拿到值了,那我们按照这个方式接着往下读就可以顺序获取到每一个entry属性的值了。如果我们倒序获取,就靠prerawlen这个值,原理差不多,假设读到prerawlen值为5,那我们继续往前读取5个bit位就可以获取到前一个entry属性的data了。
大师只是根据自己的理解讲的,有问题希望大家指正哈,不知道大家能不能理解。
如果只用ziplist的话,假设我们数据量别特大,那我们添加元素,删除元素会不会很慢?
会的!所以除了ziplist,list底层还使用到了quicklist(双端链表)。

这个图大家自行理解一下吧,prev next和我们Java中链表的属性意义差不多,将多个ziplist关联起来。
单个ziplist最大存储8K的数据,超过则会分裂成两个ziplist,然后用quicklistNode节点来关联。可以通过设置每个ziplist的最大容量,quicklist的数据压缩范围,提升数据存取效率,一般适用于做日志、时事新闻这种场景
list-max-ziplist-size -2 // 单个ziplist节点最大能存储 8kb ,超过则进行分裂,将数据存储在新的ziplist节点中
list-compress-depth 1 // 0 代表所有节点,都不进行压缩,1, 代表从头节点往后走一个,尾节点往前走一个不用压缩,其他的全部压缩,2,3,4 ... 以此类推
Hash:hash底层结构还是dict,和redis的底层结构是一样的,但是当数据量小的时候,其结构是用ziplist实现的,数据量多的时候用hashtable

hash-max-ziplist-entries 512 // ziplist 元素个数超过 512 ,将改为hashtable编码 hash-max-ziplist-value 64 // 单个元素大小超过 64 byte时,将改为hashtable编码
Set:Set 为无序的,自动去重的集合数据类型,Set 数据结构底层实现为一个value 为 null 的 字典( dict )。当数据可以用整形表示时,Set集合将被编码为intset数据结构。两个条件任意满足时 Set将用hashtable存储数据。
1. 元素个数大于 set-max-intset-entries ,
2. 元素无法用整形表示
set-max-intset-entries 512 // intset 能存储的最大元素个数,超过则用hashtable编码
sorted-set: ZSet 为有序的,自动去重的集合数据类型,ZSet 数据结构底层实现为 字典(dict) + 跳表(skiplist) ,当数据比较少时,用ziplist编码结构存储。

zset-max-ziplist-entries 128 // 元素个数超过128 ,将用skiplist编码
zset-max-ziplist-value 64 // 单个元素大小超过 64 byte, 将用 skiplist编码
skiplist结构是redis里面一个非常重要的结构,它底层是用了多层多向链表来实现了。

上图就是skiplist的结构
如果我们要查询55这个数字,那么它会从最上层索引开始查询
第三层:.23比55小,继续找,65比55大,从23下沉一层继续往前找
第二层: 52比55小,65比55小,从52继续往下找
第一层: 52比55小,59比55小,从52下沉一层继续往前找
数据层:找到55
skiplist底层层数是这样计算的

所以时间复杂度是log(n)
但是redis底层是通过随机算法生成的层高,我们来看看源码

从它的源码中我们可以看到,zset创建时会创建dict和skiplist两个结构,dict用来查询数据到分数的对应关系,skiplist用来根据分数查询数据的,可以用来范围查找
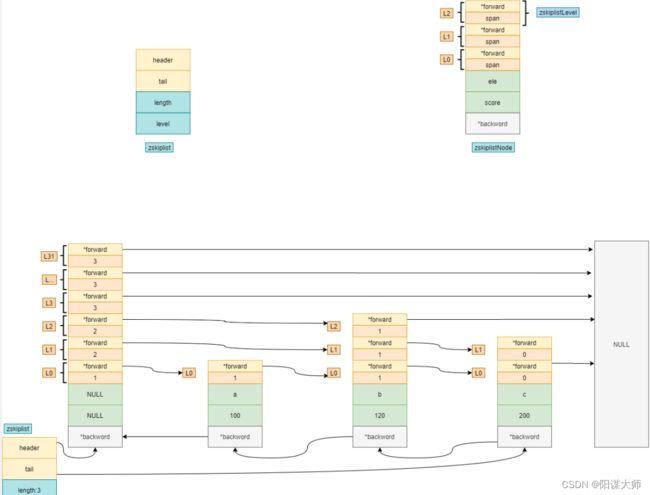
这是skiplist的结构图
总结一下:
跳表是有序集合zset的实现之一
跳表由zskiplist 和 zskiplistNode两个结构组成,zskiplist保存跳表的信息,如表头和表尾节点、跳表的长度等,zskiplistNode 保存节点详细信息
每个跳表节点的层高都是 1~32 之间的随机数
跳表中的对象是唯一的
跳表中的元素是按照分值从小到大排列,当分值相同时,按照成员对象的大小排序
扩展点:
1.为什么redis的槽是16384呢?
因为redis集群为了在节点挂掉后从节点自主选举出master节点后让其他节点知道,redis集群间节点会定时使用gosisp协议进行ping/pong报文通信,然后将自己已知1/10的节点信息带到ping/pong报文中,这样的话,节点越多,报文越大,10个节点占用带宽可能需要1KB,所以redis作者建议集群节点数量不要超过1000,那么16384个槽位完全够用。
2.string 和hash类型在工作中如何选型
1)string 如果有很多大类型相同,小类型不同的数据,例:user:001,user:002,那么就会使redis大结构dict中key数组的值越来越多,会进行更多的rehash,如果是hash的话,大结构的key只有一个
2)我们redis dict结构中的key是可以设置过期时间的,如果我们使用了hash,则只能给hash整体设置一个过期时间,不能给hash里面的 key设置