Linux下搭建Hadoop分布式教程
1、首先在Linux中安装jdk与Hadoop,解压及安装成功后配置环境变量。
vi /etc/profile
打开文件后,将下面这段代码复制进去
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_231
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
一段是jdk的环境变量,还有一段是Hadoop的环境变量。
配置好后,可以通过javac与java -version命令去检查jdk的环境变量是否配置成功。
Hadoop可以通过 输入start -d 当使用tab补全的时候 出现 start-dfs.sh即配置成功。
检查防火墙是否关闭:systemctl status firewalld
进入到 /opt/module/hadoop-2.7.3/etc/hadoop目录中,里面有很多配置文件,这里需要配置的文件有四个
(1)core-site.xml
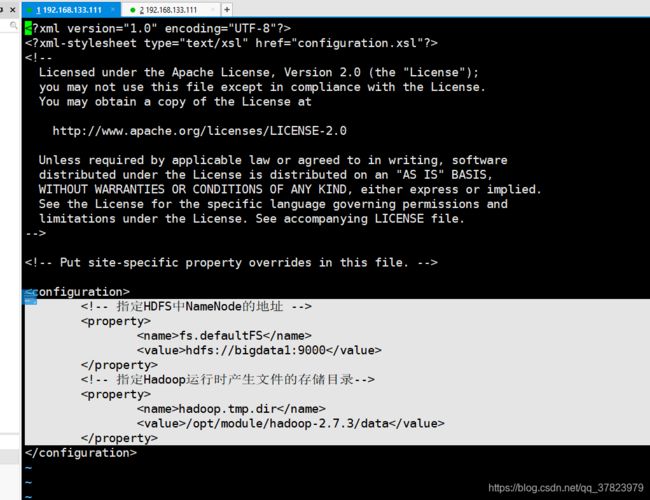
将文件复制进配置文件中的如下位置,bigdata1为主机名称 。
(2)hdfs-site.xml
(3)yarn-site.xml
(4) mapred-site.xml
首先 cp mapred-site.xml.template mapred-site.xml
因为文件夹中只有mapred-site.xml.template 这个文件 所以要把这个文件改名为 mapred-site.xml
上面几步完成后需要将jdk的环境变量(export JAVA_HOME=/opt/module/jdk1.8.0_231)
复制出来加入到下面几个文件中,都是直接放在文件的最后一行
hadoop-env.sh
yarn-env.sh
mapred-env.sh
最后一步,打开 slaves 这个文件,将里面的localhost改为你的主机的名称。
之后对所配置的文件进行格式化 hdfs namenode -format
格式化之后进行启动 start-all.sh
此时当他要你输入密码的时候就将你的密码输入进去,
当启动成功之后,在浏览器里面输入你的 主机IP:50070 查看是否可以访问成功
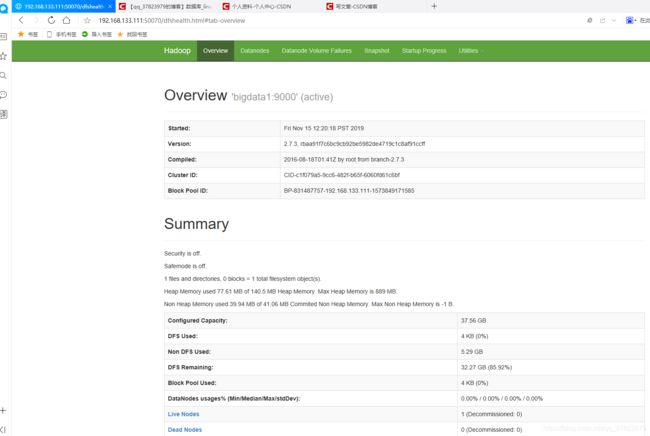
当出现如下页面的时候即已成功,到此伪分布式算是搭建成功。