手把手带你搭建Hadoop分布式集群
文章目录
- 手把手带你搭建Hadoop集群
-
- 虚拟机配置
-
- 修改网络配置文件
- ⚠ ens33找不到
- 三台机子--关闭防火墙
- 三台机子--关闭selinux
- 三台机子--修改主机名
- 三台机子--主机名与ip地址映射
- 三台机子--时钟同步
- 三台机子 -- 添加普通用户
- 三台机子--定义同一目录
- 三台机子hadoop用户免登
- 三台机子--关机重启
- 安装jdk环境
- Hadoop下载安装
-
- 服务部署规划
-
- 修改 core-site.xml
- hdfs-site.xml
- mapred-site.xml
- yarn-site.xml
- workers
- 创建目录
- 拷贝文件
- hadoop环境变量配置
- 格式化集群
- 启动集群
- 关闭集群
- 验证集群
- 补充
-
- rsync
- 创建 xsync脚本
- 启动hadoop集群的脚本
- 所有机器查看进程脚本
- zookeeper 安装
-
- 修改配置文件
- 添加myid配置
- 三台机子配置环境变量
- 启动zookeeper服务
- 关闭zookeeper集群
手把手带你搭建Hadoop集群
视频学习链接 准备工作: Vmware 三台 centos7 虚拟机 NAT 搭建 Hadoop 集群
虚拟机配置
提一句,当在敲linux命令行时,可以利用 tab键进行补全哈~
修改网络配置文件
-ens33网卡
vim /etc/sysconfig/network-scripts/ifcfg-ens33
从 centos7 64位 克隆 三台机子: centos7-001-100、centos7-002-110、centos7-003-120
例: centos7 -001-100
IPADDR="192.168.237.100"
NETMASK="255.255.255.0"
GATEWAY="192.168.237.2"
DNS1="8.8.8.8"
依次修改克隆机子 ipaddr 192.168.237.110 、 192.168.237.120, 同上配置文件
修改后,进行重启
systemctl restart network
查看当前网络情况
ifconfig
⚠ ens33找不到
注意:若遇到 找不到 ens33的情况,可参考依次执行如下命令:
ifconfig ens33 up
systemctl stop NetworkManager
ifup ens33
systemctl restart network.service
接下来,对三台虚拟机进行环境配置。我们可以采用 xshell 远程连接虚拟机的方式,进行命令行配置。当然,也可以直接在虚拟机里进行操作。
由于下面的命令,对三台虚拟机都适用,这边就偷个懒,在xshell,选择发送到所有会话。执行如下命令:
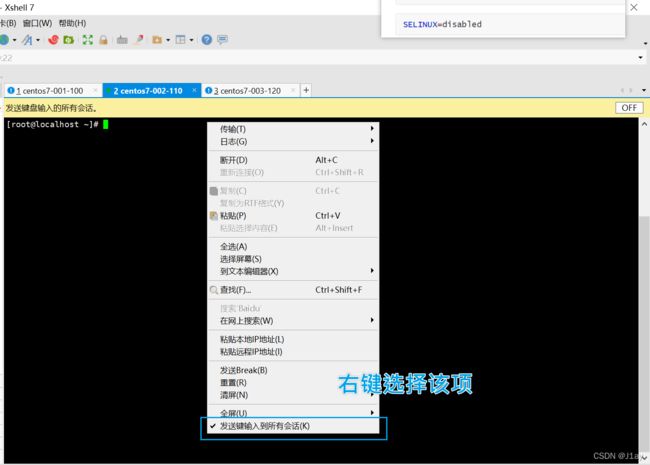
三台机子–关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
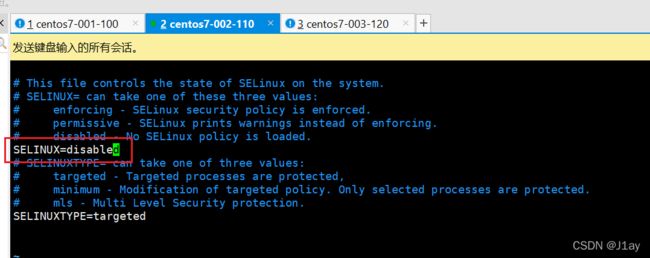
三台机子–关闭selinux
vim /etc/sysconfig/selinux
修改如下:
补充 vim编辑器 快捷键说明:
vim filename# 进入vim编辑器
按下
I进入编辑模式 按下Esc退出该模式, 按下:输入wq保存并退出
:q!# 强制退出不保存
三台机子–修改主机名
vim /etc/hostname
删除文件中内容,依次添加名字如下:
node01.j1ayhey.com # 第一台机子配置
node02.j1ayhey.com # 第二台机子配置
node03.j1ayhey.com # 第三台机子配置

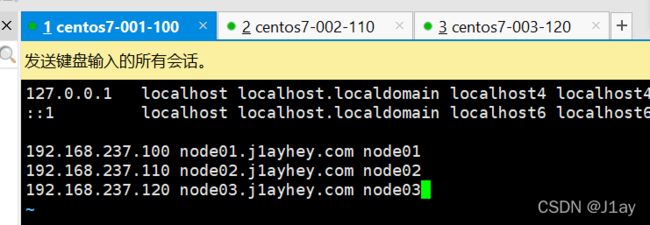
三台机子–主机名与ip地址映射
vim /etc/hosts
三台都执行下面命令
192.168.237.100 node01.j1ayhey.com node01
192.168.237.110 node02.j1ayhey.com node02
192.168.237.120 node03.j1ayhey.com node03
三台机子–时钟同步
通过网络进行时钟同步
三台机子安装 ntpdate
yum -y install ntpdate
阿里云时钟同步服务器
ntpdate ntp4.aliyun.com
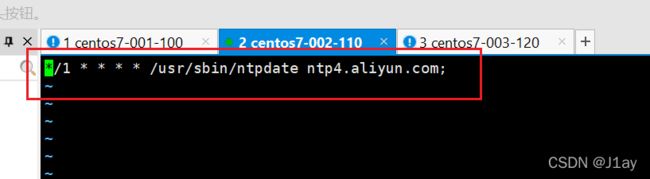
三台机器定时任务
crontab -e
*/1 * * * * /usr/sbin/ntpdate ntp4.aliyun.com;
三台机子 – 添加普通用户
三台机子统一添加普通用户hadoop
useradd hadoop
passwd hadoop
设置普通用户密码 (至少八个字符,且不能同用户名重复)
j1ay7777
给以sudo权限
visudo
按下 /ALL 进行搜索,找到如下,进行添加, 可将光标停留 root这行, 按下 yy,再按一下 p,就会直接复制该行,我们只需将 root 改成 hadoop 即可。
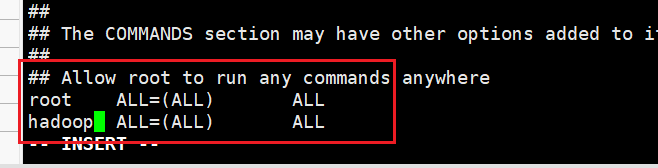
三台机子–定义同一目录
mkdir -p /j1ay/soft # 软件压缩包存放目录
mkdir -p /j1ay/install # 软件解压后存放目录
chown -R hadoop:hadoop /j1ay # 将文件夹权限更改为hadoop用户
三台机子hadoop用户免登
生成公钥与私钥
ssh-keygen -t rsa
按 enter 就完事
拷贝公钥到node01服务器
ssh-copy-id node01
node01服务器将公钥拷贝给 node02与node03服务器
cd /home/hadoop/.ssh/
scp authorized_keys node02:$PWD
scp authorized_keys node03:$PWD
按 yes 即可,输入对应的服务器密码
测试:从node01免登到node02服务器
ssh node02
三台机子–关机重启
sudo reboot -h now
安装jdk环境
jdk8下载教程 将 jdk-8u311-linux-x64.tar.gz 下载, 上传到 node01服务器上

然后在node01服务器下,解压执行以下命令:
cd /j1ay/soft/
tar -xzvf jdk-8u311-linux-x64.tar.gz -C /j1ay/install/
接下来修改环境变量:
sudo vim /etc/profile
在最后,添加配置文件:
# 配置jdk环境变量
export JAVA_HOME=/j1ay/install/jdk1.8.0_311
export PATH=$PATH:$JAVA_HOME/bin
修改生效
source /etc/profile
node01配置完成后,进行配置 node02、node03
直接进行拷贝:
cd /j1ay/install/
scp -r jdk1.8.0_311/ node02:$PWD
scp -r jdk1.8.0_311/ node03:$PWD
配置环境变量同 node1
Hadoop下载安装
下载地址
跟之前一样安装jdk步骤一样,简单介绍如下:
cd /j1ay/soft/
ls
tar -xzvf hadoop-3.3.1.tar.gz -C /j1ay/install/
cd /j1ay/install/hadoop-3.3.1/
bin/hadoop checknative
想要支持openssl,执行如下命令
sudo yum -y install openssl-devel
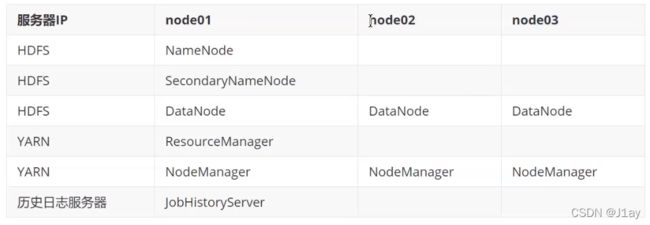
服务部署规划
修改hadoop-env.sh
第一台机子node01:
cd /hadoop-3.3.1/etc/hadoop/
vim hadoop-env.sh
按下 shift + g, 输入 /JAVA_HOME 进行全局搜索,找到 export JAVA_HOME ,将前面 # 去掉,修改如下:
export JAVA_HOME=/j1ay/install/jdk1.8.0_311
修改 core-site.xml
node01 :
vim core-site.xml
添加配置如下:
<configuration>
<property>
<name>fs.defaultFSname>
<value>hdfs://node01:8020value>
property>
<property>
<name>hadoop.tmp.dirname>
<value>/j1ay/install/hadoop-3.3.1/hadoopDatas/tempDatasvalue>
property>
<property>
<name>io.file.buffer.sizename>
<value>4096value>
property>
<property>
<name>fs.trash.intervalname>
<value>10080value>
property>
configuration>
hdfs-site.xml
vim hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-addressname>
<value>node01:9868value>
property>
<property>
<name>dfs.namenode.http-addressname>
<value>node01:9870value>
property>
<property>
<name>dfs.namenode.name.dirname>
<value>file:///j1ay/install/hadoop-3.3.1/hadoopDatas/namenodeDatasvalue>
property>
<property>
<name>dfs.datanode.data.dirname>
<value>file:///j1ay/install/hadoop-3.3.1/hadoopDatas/datanodeDatasvalue>
property>
<property>
<name>dfs.namenode.edits.dirname>
<value>file:///j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/nn/editsvalue>
property>
<property>
<name>dfs.namenode.checkpoint.dirname>
<value>file:///j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/snn/namevalue>
property>
<property>
<name>dfs.namenode.checkpoint.edits.dirname>
<value>file:///j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/nn/snn/editsvalue>
property>
<property>
<name>dfs.replicationname>
<value>3value>
property>
<property>
<name>dfs.permissions.enabledname>
<value>falsevalue>
property>
<property>
<name>dfs.blocksizename>
<value>134217728value>
property>
configuration>
mapred-site.xml
vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.namename>
<value>yarnvalue>
property>
<property>
<name>mapreduce.job.ubertask.enablename>
<value>truevalue>
property>
<property>
<name>mapreduce.jobhistory.addressname>
<value>node01:10020value>
property>
<property>
<name>mapreduce.jobhistory.webapp.addressname>
<value>node01:19888value>
property>
<property>
<name>yarn.app.mapreduce.am.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.map.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
<property>
<name>mapreduce.reduce.envname>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}value>
property>
configuration>
yarn-site.xml
vim yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.hostnamename>
<value>node01value>
property>
<property>
<name>yarn.nodemanager.aux-servicesname>
<value>mapreduce_shufflevalue>
property>
configuration>
workers
vim workers
将原内容替换成
node01
node02
node03
创建目录
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/tempDatas
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/namenodeDatas
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/datanodeDatas
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/nn/edits
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/snn/name
mkdir -p /j1ay/install/hadoop-3.3.1/hadoopDatas/dfs/nn/snn/edits
拷贝文件
将 hadoop-3.3.1 拷贝到node02、node03
cd /j1ay/install/
scp -r hadoop-3.3.1/ node02:$PWD
scp -r hadoop-3.3.1/ node03:$PWD
hadoop环境变量配置
三台机子都得进行hadoop的环境变量配置
sudo vim /etc/profile
export HADOOP_HOME=/j1ay/install/hadoop-3.3.1
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
配置生效
source /etc/profile
格式化集群
- 首次启动HDFS时,必须对其进行格式化操作。只有在首次启动的时候需要,以后不需要
node01执行一遍即可
hdfs namenode -format

说明成功~
启动集群
在node01,执行以下命令
start-dfs.sh
start-yarn.sh
mapred --daemon start historyserver

启动成功~
关闭集群
stop-dfs.sh
stop-yarn.sh
mapred --daemon stop historyserver
# 单个进程逐个启动
# 主节点,即node01
hdfs --daemon start namenode
# node01
hdfs --daemon start secondarynamenode
# 每个节点
hdfs --daemon start datanode
# node01
yarn --daemon start resourcemanager
# 每个结点
yarn --daemon start nodemanager
验证集群
① 访问 web ui界面
-
hdfs集群访问地址
http://192.168.237.100:9870/ -
yarn 集群访问地址
http://192.168.237.100:8088/ -
jobhistory 访问地址
http://192.168.237.100:19888/
② 运行一个mr 例子
hadoop jar /j1ay/install/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 5 5
若能得出结果,即安装成功~
注意,关闭时,先关闭集群,再关闭虚拟机,再关闭电脑。
补充
rsync
sudo yum -y install rsync
命令 选项参数 要拷贝文件路径或名称 目的用户@主机:目的路径/名称 例:
rsync -av /j1ay/soft/jdk-8u311-linux-x64.tar.gz node02:/j1ay/soft/ rsync -av /j1ay/soft hadoop@node02:/j1ay/soft
创建 xsync脚本
cd ~
mkdir bin
cd /home/hadoop/bin
touch xsync
vim xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if ((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo $fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo $pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- node0$host -------------------
rsync -av $pdir/$fname $user@node0$host:$pdir
done
提权,使脚本具有执行权限
cd ~/bin/
chmod 777 xsync
运行 将 bin下的文件分发到node02,node03
xsync /home/hadoop/bin/
启动hadoop集群的脚本
在 /home/hadoop/bin 目录下创建脚本
cd /home/hadoop/bin/
vim hadoop.sh
#!/bin/bash
case $1 in
"start" ) {
source /etc/profile;
/j1ay/install/hadoop-3.3.1/sbin/start-dfs.sh
/j1ay/install/hadoop-3.3.1/sbin/start-yarn.sh
/j1ay/install/hadoop-3.3.1/sbin/mr-jobhistory-daemon.sh start historyserver
};;
"stop"){
/j1ay/install/hadoop-3.3.1/sbin/stop-dfs.sh
/j1ay/install/hadoop-3.3.1/sbin/stop-yarn.sh
/j1ay/install/hadoop-3.3.1/sbin/mr-jobhistory-daemon.sh stop historyserver
};;
esac
修改脚本权限
chmod 777 hadoop.sh
./hadoop.sh start # 启动hadoop集群
./hadoop.sh stop # 停止hadoop集群
所有机器查看进程脚本
依旧在bin目录下
vim xcall
#!/bin/bash
params=$@
for (( i=1; i <= 3; i = $i + 1)); do
echo =========== node0$i $params ============
ssh node0$i "source /etc/profile;$params"
done
- 然后一键查看进程并分发该脚本
chmod 777 xcall
xsync /home/hadoop/bin/
- 所有机器查看进程
xcall jps
zookeeper 安装
下载地址
同之前的步骤,首先解压。
cd /j1ay/soft/
tar -xzvf apache-zookeeper-3.7.0-bin.tar.gz -C /j1ay/install/
修改配置文件
node01:
cd /j1ay/install/apache-zookeeper-3.7.0-bin/conf/
mkdir -p /j1ay/install/apache-zookeeper-3.7.0-bin/zkdatas
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
修改如下:
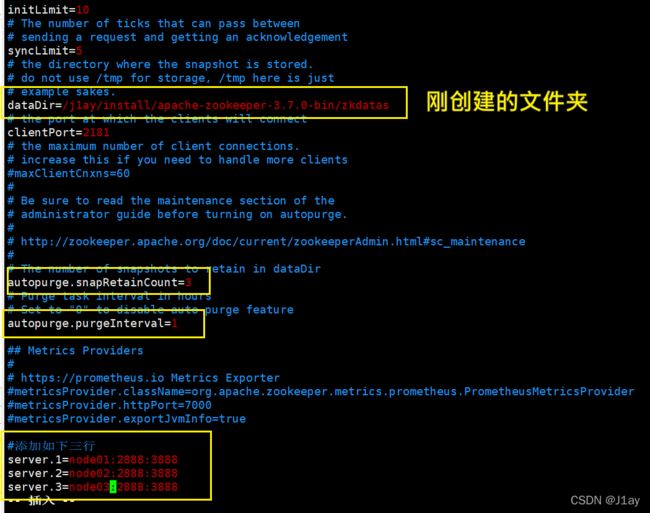
添加myid配置
# 注意路径为 zkdatas [hadoop@node01 zkdatas]$
echo 1 > /j1ay/install/apache-zookeeper-3.7.0-bin/zkdatas/myid
node01, 执行安装包分发
若没编解 xsync脚本,也可使用 scp 命令进行拷贝
xsync /j1ay/install/apache-zookeeper-3.7.0-bin/
在node02修改myid的值为2
echo 2 > /j1ay/install/apache-zookeeper-3.7.0-bin/zkdatas/myid
在node03修改myid的值为3
echo 3 > /j1ay/install/apache-zookeeper-3.7.0-bin/zkdatas/myid
三台机子配置环境变量
sudo vim /etc/profile
添加如下:
export ZK_HOME=/j1ay/install/apache-zookeeper-3.7.0-bin
export PATH=$PATH:$ZK_HOME/bin
source /etc/profile
启动zookeeper服务
# 启动
zkServer.sh start
# 查看启动状态
zkServer.sh status
状态,一个是 leader,其余是 follower
关闭zookeeper集群
zkServer.sh stop