Linux部署 kafka集群
目录
问题现象:
解决方法:
0、环境
环境:
1、下载
地址:
拓展:Scala是什么?
2、部署
2.1 linux服务器上新建目录
2.2 上传kafka压缩包到服务器
2.3 解压
2.4 重命名解压后的文件夹
2.5 创建logs日志目录和data数据目录
2.6 修改配置
2.7 部署集群中的其他服务实例
3、启动
3.1 执行启动脚本
拓展:服务启动报错"Cannot allocate memory"
3.2 查看 kafka 进程信息
3.3 查看服务日志
拓展:-daemon 参数
拓展:server.properties 的 listeners 配置规范
4、应用
4.1 开放防火墙端口
4.2 创建话题topic
拓展:创建topic的脚本命令变动
拓展:脚本命令参数
4.3 查看topic列表
4.4 查看topic的详细信息
4.5 测试生产消息&消费消息
4.6 删除话题topic
问题现象:
Linux 系统如何部署 kafka集群?
解决方法:
0、环境
环境:
linux 系统、JDK8、zookeeper集群、kafka 压缩包(tar.gz)。
由于 kafka 是基于 zookeeper 的,因此安装 kafka 必须先安装好zookeeper 。
注意:对于 linux 系统上安装 zookeeper集群 感兴趣的小伙伴,可以参考一下文章:
https://blog.csdn.net/weixin_42585386/article/details/122359581
1、下载
地址:
Apache Kafka
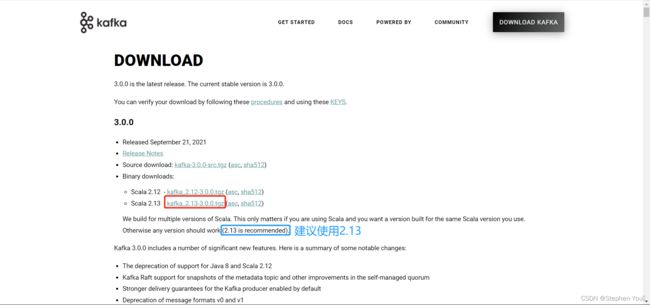
可以看见有 2.12 和 2.13 版本,根据提示可知:如果用到了 Scala 则根据 Scala 的版本来选择,否则建议使用 2.13 版本。
拓展:Scala是什么?
Scala是一门多范式的编程语言,一种类似java的编程语言,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性,有人说 Scala可能是下一代Java!!!
详情可以参考百度百科文章:
Scala(编程语言)_百度百科
回到正题,点击 2.13 版本后,跳转到新的页面,点击红框内的下载链接进行下载: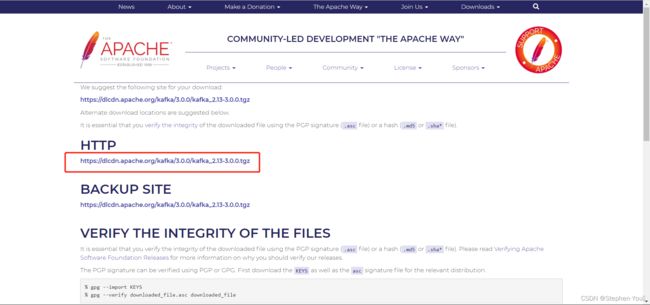
下载后得到 kafka_2.13-3.0.0.tgz 压缩包文件:
2、部署
2.1 linux服务器上新建目录
先新建一个目录,如 kafka-cluster:
# 进入自定义目录路径,用于存放kafka服务,如/home/thp/public
cd /home/thp/public
# 创建文件夹(目录),如kafka-cluster
mkdir kafka-cluster2.2 上传kafka压缩包到服务器
上传kafka压缩包到kafka-cluster文件夹下:
# 进入kafka-cluster目录路径
cd /home/thp/public/kafka-cluster
2.3 解压
# 解压 zookeeper压缩包
tar -zxvf kafka_2.13-3.0.0.tgz
2.4 重命名解压后的文件夹
由于要搭建kafka集群,所以为了区分,我们对解压后的文件夹进行重命名:
# 重命名为 kafka_2.13-3.0.0-1
mv kafka_2.13-3.0.0 kafka_2.13-3.0.0-1
2.5 创建logs日志目录和data数据目录
新建 logs目录 用来存放 kafka服务日志 :
# 进入 kafka_2.13-3.0.0-1目录
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1
#创建 logs 目录
mkdir logs 
2.6 修改配置
首先修改系统域名配置文件:
# 编辑 hosts系统文件
vi /etc/hosts加入以下内容:
192.168.16.230 kafkahost 修改后的hosts文件内容如下:
注意ip不要使用127.0.0.1,因为kafka的配置中是无法识别的。
接下来就是修改kafka配置文件 server.properties:
# 进入解压后的文件夹下的 config 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/config
# 编辑 server.properties配置文件
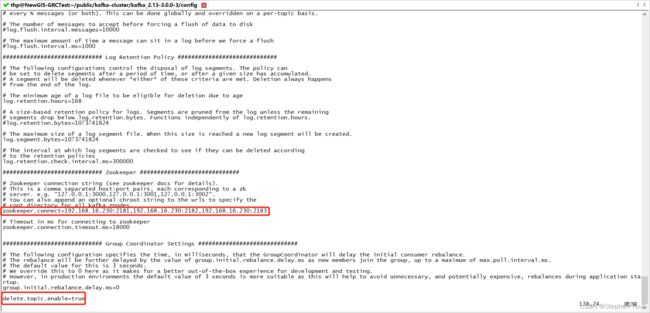
vi server.properties需要修改的内容如下:
# broker.id 是当前实例的id标识(集群中各实例的id标识不可相同)
broker.id=1
# kafka服务的ip(linux服务器ip)和port(默认9092),由于服务器9091端口已被占用,所以我用了0091
listeners=PLAINTEXT://kafkahost:0091
# kafka的服务日志存放目录
log.dirs=/home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/logs
# zookeeper集群各实例的ip和端口,用英文逗号分隔
zookeeper.connect=192.168.16.230:2181,192.168.16.230:2182,192.168.16.230:2183
# 在配置文件末尾添加如下配置,表示允许删除topic
delete.topic.enable=true修改后内容如下:
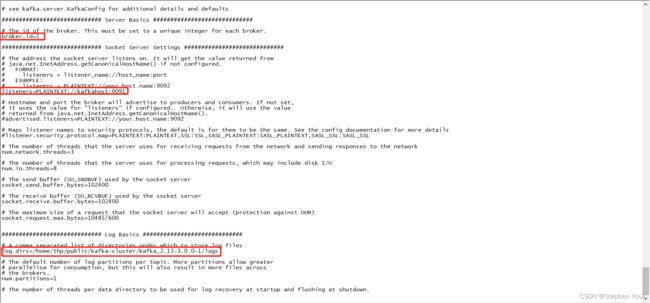
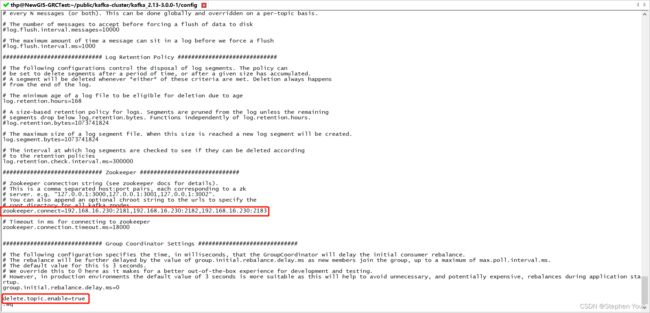 至此 kafka实例1就配置完成了!!!
至此 kafka实例1就配置完成了!!!
2.7 部署集群中的其他服务实例
有了上面已经配置好的服务实例1,接下来部署其他服务实例就容易多了:
1、复制 kafka_2.13-3.0.0-1 文件夹到 /home/thp/public/kafka-cluster 目录下,命名为 kafka_2.13-3.0.0-2:
# 进入 kafka-cluster目录路径
cd /home/thp/public/kafka-cluster
# 复制 kafka_2.13-3.0.0-1 并命名为 kafka_2.13-3.0.0-2
cp -r kafka_2.13-3.0.0-1 kafka_2.13-3.0.0-2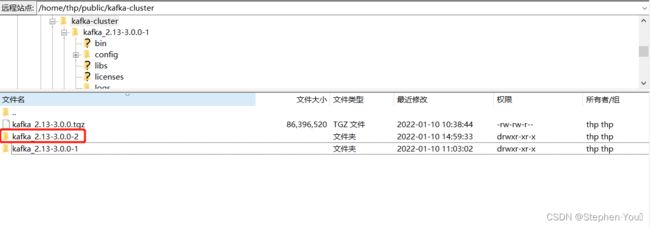
2、仿照 2.6 ,修改 /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-2/config 目录下的 server.properties 文件:
# 进入 config 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-2/config
# 编辑 server.properties 配置文件
vi server.properties需要修改的内容如下:
# broker.id 是当前实例的id标识(集群中各实例的id标识不可相同)
broker.id=2
# 由于服务器9092端口已被占用,所以我用了0092
listeners=PLAINTEXT://kafkahost:0092
# kafka的服务日志存放目录
log.dirs=/home/thp/public/kafka-cluster/kafka_2.13-3.0.0-2/logs修改后内容如下:
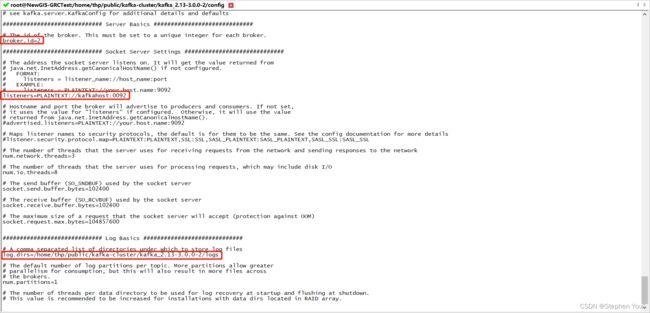

3、同样的再配置一个服务实例,复制 kafka_2.13-3.0.0-1 文件夹到 /home/thp/public/kafka-cluster 目录下,命名为 kafka_2.13-3.0.0-3:
# 进入 kafka-cluster目录路径
cd /home/thp/public/kafka-cluster
# 复制 kafka_2.13-3.0.0-1 并命名为 kafka_2.13-3.0.0-3
cp -r kafka_2.13-3.0.0-1 kafka_2.13-3.0.0-3修改 /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-3/config 目录下的 server.properties 文件:
# 进入 config 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-3/config
# 编辑 server.properties 配置文件
vi server.properties需要修改的内容如下:
# broker.id 是当前实例的id标识(集群中各实例的id标识不可相同)
broker.id=3
# 由于服务器9093端口已被占用,所以我用了0093
listeners=PLAINTEXT://kafkahost:0093
# kafka的服务日志存放目录
log.dirs=/home/thp/public/kafka-cluster/kafka_2.13-3.0.0-3/logs修改后内容如下:

至此所有的服务实例已经配置完成!!!
3、启动
3.1 执行启动脚本
依次执行3个服务实例的启动脚本:
# 进入 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/bin
# 执行 kafka-server-start.sh 启动脚本文件
./kafka-server-start.sh -daemon ../config/server.properties &
# 进入 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-2/bin
# 执行 kafka-server-start.sh 启动脚本文件
./kafka-server-start.sh -daemon ../config/server.properties &
# 进入 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-3/bin
# 执行 kafka-server-start.sh 启动脚本文件
./kafka-server-start.sh -daemon ../config/server.properties & 依次执行3个服务实例的启动脚本文件:
拓展:服务启动报错"Cannot allocate memory"
假如在执行启动脚本之后,出现"Cannot allocate memory"(无法分配内存)报错,说明是当前服务器内存满了,这个不是kafka服务有问题,而是服务占用的内存大于当前服务器剩余可运行的内存大小。
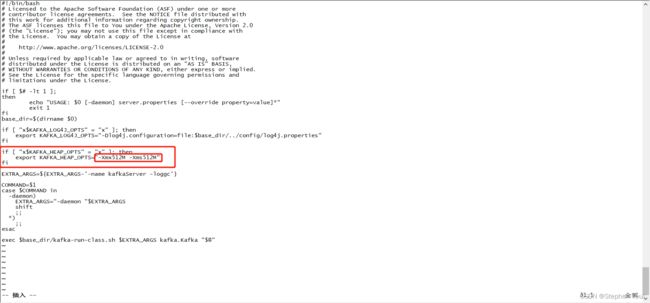
这个情况下可以修改kafka服务的启动脚本文件:
# 进入 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/bin
# 编辑启动脚本文件
kafka-server-start.sh服务所占内存大小初始值是1G:

修改为512M,或者更小的256M、128M等,减少服务所占用内存大小:
3.2 查看 kafka 进程信息
# 查看带有 ‘kafka’ 关键字的进程
ps -ef |grep kafka
由于篇幅问题,就不截图剩余部分了。执行命令后是可以看见有3个进程在运行,对应了3个kafka服务实例。
3.3 查看服务日志
进一步确认服务运行情况
# 进入 服务实例的logs目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/logs
# 查看日志
tail -n 300 -f server.log
日志中出现类似 [KafkaServer id=服务实例id] started (kafka.server.KafkaServer) 的信息,则表示服务启动成功!!!
拓展:-daemon 参数
通过查看 kafka-server-start.sh 启动脚本文件,可知启动命令中可以添加 -daemon 参数:
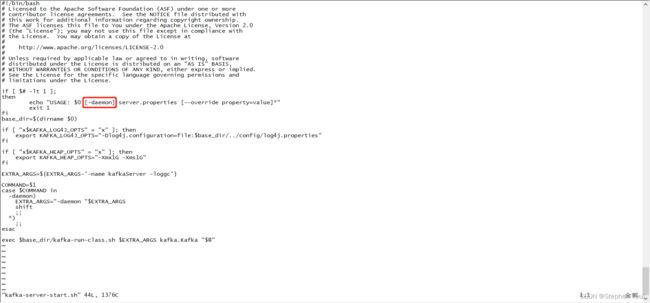
分析:
-daemon 参数的作用就是让kafka服务实例以后台进程(守护进程)的模式来启动,简单的说就是不会占用当前命令行窗口,而不添加该参数的话,就会占用/阻塞当前命令行窗口进程,导致无法在当前窗口进行其他操作(除非ctrl + z / ctrl + c 停止当前服务实例,才会释放进程),必须打开一个新的命令窗口才能进行其他操作,这样显然是不方便的。
总结:
1、在执行服务启动脚本时,强烈建议带上-daemon 参数!!!
2、要依次启动服务集群中的3个服务实例,不要漏掉!!!
拓展:server.properties 的 listeners 配置规范
关于 server.properties 配置文件,有个很关键的点是需要注意的,就是 listeners 这个配置,如下:
# kafka服务的ip(linux服务器ip)和port(默认9092),由于服务器9091端口已被占用,所以我用了0091
listeners=PLAINTEXT://192.168.16.230:0091这里我使用了域名配置,而没有使用linux服务器ip地址,假如我在服务实例1中不用域名,而是使用linux服务器ip地址,如下:
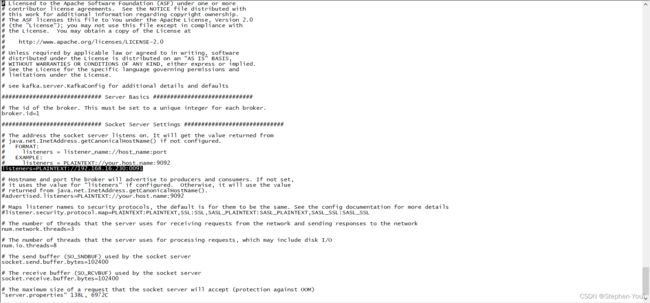
可能会出现如下情况:
一、执行服务实例1的启动脚本后,服务是起不来的,而且没有任何报错日志,如下:
# 服务启动后,查看 服务实例1 的端口(注意我配置的端口是0091,linux会识别为91,而不是0091)
netstat -tunlp | grep 91

 可以看到没有占用 91端口的相关进程!!! 但是服务实例2和服务实例3是起来了的!!!
可以看到没有占用 91端口的相关进程!!! 但是服务实例2和服务实例3是起来了的!!!
二、服务实例1能启动,但通过查看服务日志会看见以下报错:
# 进入 服务实例的logs目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/logs
# 查看日志
tail -n 300 -f server.log
可以看见,日志显示无法连接到zookeeper服务集群!!!
分析:
通过查看配置可以发现有如下提示:

也就是说该配置的格式必须是服务器域名:端口号,而不能是ip:port。
此外经过测试发现,当使用localhost域名时,也会报同样的错误:

总结:
server.properties 的 listeners 配置规范:
1、格式必须是服务器域名:端口号,而不能是ip:port。
2、服务器域名不能使用localhost,无法识别。
4、应用
4.1 开放防火墙端口
开放3个kafka服务实例所用的端口:
# 开放端口
sudo firewall-cmd --zone=public --add-port=0091/tcp --permanent
sudo firewall-cmd --zone=public --add-port=0092/tcp --permanent
sudo firewall-cmd --zone=public --add-port=0093/tcp --permanent
# 重启防火墙
sudo firewall-cmd --reload
# 查看开放端口列表
sudo firewall-cmd --zone=public --list-ports端口开放成功:

4.2 创建话题topic
创建一个分区数为 2(分区数不可大于集群中服务实例总数),脚本数为 2(脚本数不可大于分区数),话题名为 first 的 topic:
# 进入 服务实例去的 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/bin
# 创建topic话题
./kafka-topics.sh --bootstrap-server 192.168.16.230:0091 --create --replication-factor 2 --partitions 2 --topic first出现如下信息则为创建成功:
![]()
拓展:创建topic的脚本命令变动
有些小伙伴可能是用以下命令执行的脚本:
./kafka-topics.sh --create --zookeeper 192.168.16.230:2181 --replication-factor 2 --partitions 2 --topic first这个我测试过是不行的,查阅了以下网上资料,原因应该是因为kafka版本不同,据说是从kafka 2.12 版本开始,改成了新的创建topic的脚本命令,如:
# 创建topic话题
./kafka-topics.sh --bootstrap-server 192.168.16.230:0091 --create --replication-factor 2 --partitions 2 --topic first可以看见新旧命令的区别在于 集群服务实例的指定参数上:
旧版本用的是:--zookeeper 192.168.16.230:2181,
新版本用的是: --bootstrap-server 192.168.16.230:0091,
原因:
旧版本的topic的offset信息存储在zookeeper集群上(数据存储在kafka集群中),所以消费者在消费消息/获取数据时,必须先和zookeeper服务实例通信获取到offset,再和kafka服务实例通信来消费消息/获取数据。
新版本中offset信息和数据都存储在kafka集群上了,kafka会自动创建一个 topic(__consumer_offsets)来保存offset的信息,消费者在消费消息/获取数据时,只需要和kafka服务实例进行一次通信即可,有利于提高效率。
拓展:脚本命令参数
有些小伙伴可能是用以下命令执行的脚本:
./kafka-topics.sh --create --zookeeper 192.168.16.230:2181 --replication-factor 2 --partitions 2 --topic first这个我测试过是不行的,查阅了以下网上资料,原因应该是因为kafka版本不同,据说是从kafka 2.12 版本开始(确切的说是从kafka 2.11大版本的0.9.0.0小版本开始,为了方便记忆,我们记住大版本就好),改成了新的创建topic的脚本命令,如:
# 创建topic话题
./kafka-topics.sh --bootstrap-server 192.168.16.230:0091 --create --replication-factor 2 --partitions 2 --topic first--create : topic 创建标识
--bootstrap-server ip:0091,ip:0092,ip:0092.... : 指定kafka集群(kafka版本2.2以上)
--zookeeper ip:0091,ip:0092,ip:0092.... : 指定zookeeper集群
--partitions 分区数 : 指定分区总数
--replication-factor 副本数 : 指定每个分区的副本数
--topic 话题名称 : 指定新建话题的名称
创建topic成功后,可以从3个服务实例各自的logs目录下,看到对应的分区目录,如:
服务实例1 有两个分区,分别是 first-0 和 first-1 :

服务实例2 有一个分区,是 first-1 (为什么不是 first-0?随机分配的,别在意这些 ):
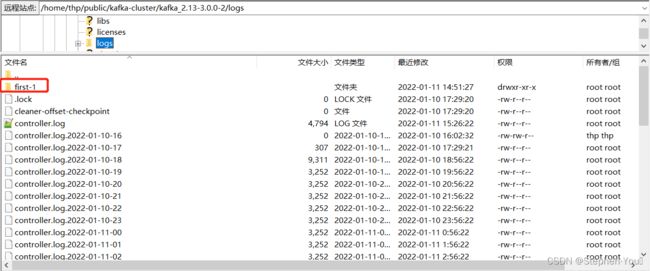
因此服务实例3 上就是另一个分区 first-1 :
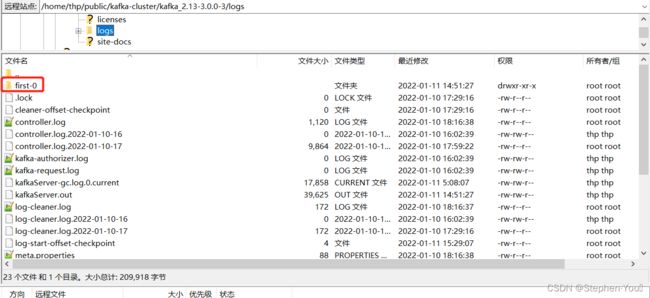
4.3 查看topic列表
# kafka旧版本(2.2以下)
./kafka-topics.sh --list --zookeeper 172.17.80.219:2181
# kafka新版本(2.2及以上)
./kafka-topics.sh --list --bootstrap-server 192.168.16.230:0091

可以看见91、92、93服务所在的kafka集群中目前只有同一个topic,名为 first。
4.4 查看topic的详细信息
# kafka旧版本(2.2以下)
./kafka-topics.sh -zookeeper 192.168.16.230:2181 -describe -topic first
# kafka新版本(2.2及以上)
./kafka-topics.sh --describe --bootstrap-server 192.168.16.230:0091 --topic first
属性描述:
第一行(topic话题主要信息):
Topic:话题名称
TopicId:话题id
PartitionCount:分区数
ReplicationFactor:每个分区的副本数
第二行、第三行。。。(各分区信息记录):
Topic:话题名称
Partition:分区记录id
Leader:领导者id,取值来源于kafka服务实例id(broker.id)
Replicas:副本所在的kafka服务实例id(broker.id),逗号分隔
Isr: 副本所在的kafka服务实例id(broker.id),逗号分隔,该值在投票选举的时候用的,哪个分区副本的数据和leader数据越接近,这个分区所在的kafka服务实例id(broker.id)就越靠前,当leader挂掉时,就取Isr中最靠前的一个kafka服务实例来充当leader。
4.5 测试生产消息&消费消息
执行脚本命令让服务实例3作为生产者;
由于执行后会占用当前命令窗口,而消息通信具有实时性,所以需要开启一个新的命令窗口,再执行脚本命令让服务实例1作为消费者,从头部开始消费消息;
再开启一个新的命令窗口,再执行脚本命令让服务实例2作为消费者,从尾部开始消费消息;
执行如下命令:
# 进入 服务实例3 的 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-3/bin
# 服务实例3(192.168.16.230:0093)生产消息
./kafka-console-producer.sh --broker-list 192.168.16.230:0093 --topic first
# 进入 服务实例1 的 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-1/bin
# 开启新的命令窗口后,让服务实例2(192.168.16.230:0092)从头部消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.16.230:0091 --topic first --from-beginning
# 进入 服务实例2 的 bin 目录路径
cd /home/thp/public/kafka-cluster/kafka_2.13-3.0.0-2/bin
# 开启新的命令窗口后,让服务实例2(192.168.16.230:0092)从尾部消费消息
./kafka-console-consumer.sh --bootstrap-server 192.168.16.230:0092 --topic first --offset latest --partition 0
![]()
![]()
![]()
服务实例3生产消息:
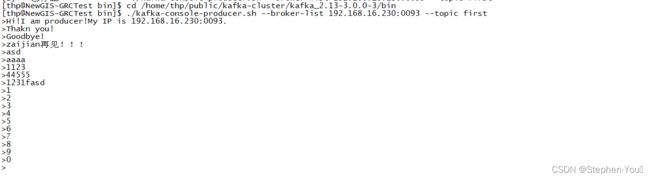
服务实例1从头部消费消息:
 服务实例2从尾部消费消息:
服务实例2从尾部消费消息:

可以看出服务实例1完全按顺序获取到了服务实例3实时生产的消息,而服务实例2会出现丢失,推测是因为服务实例3中生产的消费是随机存储在分区0和1中的,而从尾部消费消息时,是需要指定分区的,因此只能获取到该分区上存储的消费消息。
参数说明:
--from-beginning :从头开始消费消息。
--offset latest :从尾部开始消费消息;--offset 位移量,如: --offset 2 表示从第2个消息开始消费。
4.6 删除话题topic
# kafka旧版本
./kafka-topics.sh --zookeeper 192.168.16.230:0091 --delete --topic first
# kafka新版本
./kafka-topics.sh --bootstrap-server 192.168.16.230:0091 --topic first --delete

可以看见之前创建的话题topic名为first的已经不存在了! 但是多了两个topic,推测是之前kafka集群在处理first话题的时候,自动生成的。
同理也可以将这两个topic也删除掉:
