MSQL系列(七) Mysql实战-SQL语句Join,exists,in的区别
Mysql实战-SQL语句Join,exists,in的区别
前面我们讲解了索引的存储结构,B+Tree的索引结构,以及索引最左侧匹配原则及讲解一下常用的SQL语句的优化建议,今天我们来详细讲解一下 我们经常使用的 join, exist, in三者的区别
文章目录
-
-
- Mysql实战-SQL语句Join,exists,in的区别
-
- 1.表结构
- 2.使用 in查询 用户及订单表
- 3.使用 exists查询 替换 in语句, 查询用户及订单表
- 4. in exists 用法对比
- 4. 加索引看下执行结果与not in, not exists对比
-
1.表结构
新建表结构 user, user_info
#新建表结构 user
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`id_card` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '身份证ID',
`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',
`age` int NOT NULL COMMENT '年龄',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='用户表'
#新建订单表 order_info
CREATE TABLE `order_info` (
`id` bigint NOT NULL AUTO_INCREMENT COMMENT '主键',
`order_id` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '订单ID',
`user_name` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户名字',
`address` char(32) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci NOT NULL COMMENT '用户地址',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='订单表'
先插入测试数据, 插入 5条user 测试数据 2条订单数据
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (1, '11', 'aa', 10);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (2, '22', 'bb', 20);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (3, '33', 'cc', 30);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (4, '44', 'dd', 40);
INSERT INTO `test`.`user` (`id`, `id_card`, `user_name`, `age`) VALUES (5, '55', 'ee', 50);
#2条订单数据
INSERT INTO `test`.`order_info` (`id`, `order_id`, `user_name`, `address`) VALUES (1, '1', 'aa', '北京');
INSERT INTO `test`.`order_info` (`id`, `order_id`, `user_name`, `address`) VALUES (2, '2', 'bb', '上海');
2.使用 in查询 用户及订单表
我们查看下存在订单的用户有哪些?
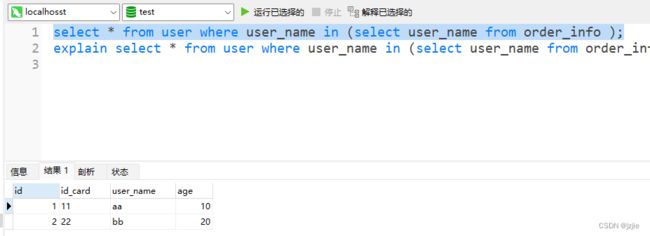
select * from user where user_name in (select user_name from order_info );
explain select * from user where user_name in (select user_name from order_info )
我们看下Explain执行分析
- in查询没有驱动表,先执行子查询,然后再执行外层表
- in 子查询会 使用了临时表 Start Temporary
- in查询其实把外表和内表 作hash 连接,Using join buffer (hash join) 使用hash 连接, 当子查询数量较多时,hash连接后的数据量特别大
- order_info 表 type=ALL没有索引, user表也没有索引, type=ALL

查询结果: 2条数据,正确
3.使用 exists查询 替换 in语句, 查询用户及订单表
前面我们使用了in来进行查询, 现在我们使用 exists来替换 in,实现查询效果
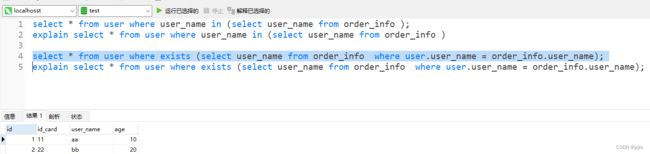
select * from user where exists (select user_name from order_info where user.user_name = order_info.user_name);
explain select * from user where exists (select user_name from order_info where user.user_name = order_info.user_name);
我们看下Explain执行分析
- Exists 同样也会使用临时表
- 二者的连接同样也是 hash join
- Exist是 外层表是驱动表, 先执行外层表,再执行内层表
- 这样看起来似乎是没有区别的,下面我们专门对比下2者

查询结果2条数据,正确
4. in exists 用法对比
前面我们尝试用 in 和 exists 来对比
我们都知道 如果涉及子查询的时候,我们都是小表驱动大表,先查小表,然后查大表,这就导致了in和exists用法的区别
- in 先执行子查询,使用于内小,外大
- exist 先执行外层表驱动表,适用于外小,内大
- in适合 外层大, 内层小, 先执行内层子查询,过滤出来一小部分数据,再用来查外层
- exist适用于外层小,内层大,先执行外层驱动表查询,出来一部分数据,再查内层表
简单通俗来讲就是下面的案例
如果 order表有1w数据,user表有10条数据, order是大表, user是小表, 采用 in 内小外大的用法
- select * from order where user_name in ( select user_name from user )
- in 子查询 user 是小表, 外层order 是大表
如果 user表有1w数据, order表有10条数据,上面的明显是错误的用法,采用 exists的 外小内大的用法
- select * from order where exists (select user_name from user where user.user_name = order_info.user_name )
- order 外小, user 内大
4. 加索引看下执行结果与not in, not exists对比
前面我们尝试用 in 和 exists 来对比,加上索引后,对比下 二者的结果
二者全部都使用了索引
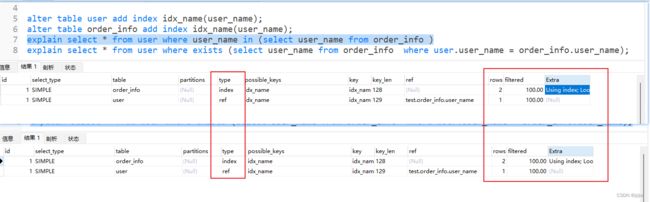
alter table user add index idx_name(user_name);
alter table order_info add index idx_name(user_name);
explain select * from user where user_name in (select user_name from order_info )
explain select * from user where exists (select user_name from order_info where user.user_name = order_info.user_name);
- order_info 表 type=index, user表 type=ref,全都使用了索引
我们再尝试下 not in 和 not exists
explain select * from user where user_name not in (select user_name from order_info )
explain select * from user where not exists (select user_name from order_info where user.user_name = order_info.user_name);
- not in 查询类型 select type 变成了 PRIMARY 和 DEPENDENT SUBQUERY
- not in 索引 type类型变成了ALL 和index_subquery
- not exists 查询类型 select type 依旧是 simple
- not in 索引 type类型变成了ALL 和ref
所以我们还是尽量不要用 not in ,not exists 这种SQL语法

至此,我们彻底的了解了 in, exists的区别,下一篇我们讲解下 join的原理,通过join原理,我们可以更加了解SQL查询的底层逻辑