阅读文献1:Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training(文章翻译及自身的理解和总结)
目录
前言
一、文章标题
二、摘要
我在这里直接翻译过来:
三、Introduction
这里也没有什么好解释哒,我也直接翻译过来:
四、Related Work
(1)Vision Transformers
(2)Knowledge Distillation
五、Method
1.Preliminaries
1.1 Convolution
1.2 MHSA
2.Agent CNN
2.1 Generalized Convolution
2.2 Constructing Agent CNN
Weight Sharing
3.Bootstrapping Optimization
3.1 Adaptive Intermediate Supervision
3.2 Optimization Objective
3.3 Bootstrapping Training Algorithm
六、Experiments
1.Implementation
2.Experimental Results
3.Ablation Study
4.The Choice of Agent CNNs
5.Sensitivity Analysis of Hyperparameters
七、Conclusion and Future Work
总结
前言
萌新第一次写文章,有什么不对还请各位大佬多多指正。我写这个文章的目的是把我自己平时看文献学到的知识学习记录下来,方便我之后去查阅,顺带发布在CSDN上,因为很多东西我也是第一次基础,报着从0开始的态度去学习! (文章已获得作者的授权~)
若无说明,文中图片均来自论文。若要转载,请表明出处,谢谢~ 希望这篇文章可以帮助到大家呢
一、文章标题
Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training
文献下载:[2112.03552v2] Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training (arxiv.org) https://arxiv.org/abs/2112.03552v2
https://arxiv.org/abs/2112.03552v2
二、摘要
我在这里直接翻译过来:
近年来,视觉变形器(ViTs)发展迅速,并开始挑战卷积神经网络(CNNs)在计算机视觉领域的统治地位。随着通用Transformer架构取代了卷积的硬编码归纳偏置,ViTs已经超过了CNN,特别是在数据充足的情况下。然而,ViTs容易在小数据集上过度拟合,因此依赖于大规模的预训练,花费大量的时间。在本文中,我们努力通过将CNN的归纳偏置引入到ViTs中,将ViTs从预训练中解放出来,同时保留其网络架构的更高上界,并设置更合适的优化目标。首先,基于给定的ViT设计了一个具有归纳偏置的代理CNN。在此基础上,提出了一种自举训练算法,通过权值共享实现智能体和ViT的联合优化,在此过程中ViT学习智能体中间特征的归纳偏置。利用有限的训练数据在CIFAR-10/100和ImageNet-1k上进行的广泛实验显示了令人振奋的结果,归纳偏置帮助ViTs显著更快地收敛,并在参数更少的情况下优于传统CNN。
代码可以在https://github.com/zhfeing/Bootstrapping-ViTs-pytorch上公开。
归纳偏置(Inductive Bias):这个博客大家可以借鉴一下【机器学习】浅谈 归纳偏置 (Inductive Bias)_花与人间事同的博客-CSDN博客_归纳偏置https://blog.csdn.net/qq_39478403/article/details/121107057
三、Introduction
这里也没有什么好解释哒,我也直接翻译过来:
卷积神经网络(cnn)的巨大成功将研究人员从手工制作视觉特征中解放出来。通过归纳偏置,即关注局部特征和权重共享,cnn是处理视觉识别任务的有效工具。然而,这些偏见限制了他们建立更深层次、更大模型的能力,因为他们忽略了长期依赖性。
近年来,在自然语言处理(NLP)中,Transformers 被提出用通用网络架构代替归纳偏差。Transformers 完全依赖多头注意力机制(MHA),天生具备捕捉语言标记内全局依赖关系的能力,已成为 NLP 中事实上首选的数据驱动模型。受此启发,越来越多的研究人员将 Transformer 架构引入计算机视觉 (CV) 领域。一个令人鼓舞的发现是,视觉转换器 (ViTs) 在参数数量相似的情况下大大优于最先进的CNN(SOTA)。CNN (SOTA) : 这个大家可以当参考资料https://harvard-iacs.github.io/2021-CS109B/lectures/lecture18/presentation/cnn5.pdf
尽管取得了吸引人的成就,但ViTs的性能较差,尤其是没有足够的注释或强大的数据增强策略。造成这种情况的原因有两个:一方面,ViTs 中广泛采用的多头自注意力机制(MHSA)对卷积有密集的连接,如果没有先验知识很难优化; 另一方面,Chen等人表明,ViTs在尖锐区域趋于收敛到最小值,这通常与有限的泛化能力和过拟合问题有关。因此,NLP中Transforms的典型训练方案依赖于对下游任务进行大规模的预训练后再微调,这将消耗大量的GPU (TPU)时间和能量。例如,Dosovitskiy等人花了数千TPU天来预训练带有303M图像的ViT。自然地,它提出了以下问题:我们如何在没有预先培训的情况下有效地优化ViTs。
据我们所知,现有的针对这个问题的方法主要可以分为两部分:第一种方法试图将归纳偏置带回Transfomers,如稀疏注意和标记聚合。这种对 ViT 的启发式修改将不可避免地导致大量超参数的复杂调整。第二种方法的目的是构造合适的Transfomers训练方案,使其收敛,具有更好的泛化能力。特别是,Chen等人利用锐度感知最小化器(SAM)来寻找平滑的最小值,而[24,45](文章中引用的文献)则通过提取预先训练的教师知识来优化Transformer。尽管如此,这些方法仍然需要对中等规模的数据集(如ImageNet-1k[29])进行预先训练,而如何用相对较小的数据集从头开始有效地训练ViTs仍然是一个悬而未决的问题。
受到蒸馏方法的启发,利用教师模型来引导学生的优化方向,在本文中,我们努力利用代理CNN来进一步优化ViTs, CNN也与ViT一起从零开始学习。我们的目标是在不修改其架构的情况下,将来自代理CNN的归纳偏置注入到ViT中,并设计一个更友好的优化过程,使ViT可以在不需要预先训练的小规模数据集上定制。
为此,我们提出了一种新的优化策略,以自引导的形式训练Transformers,这样即使没有对中型数据集进行预训练或数据增强,ViTs仍然可以在缺乏训练数据的情况下具有竞争力。具体来说,如图1所示,我们首先提出一个针对给定ViT设计的agent CNN,在归纳偏置的作用下,agent的收敛速度会比ViT快。然后我们在相互学习框架中,联合优化ViT和agent,其中agent的中间特征通过归纳偏差监督ViT,使其快速收敛。为了减少训练负担,我们进一步将ViT的参数共享给agent,并提出一种自举学习算法来更新共享参数。我们在缺乏数据的设置下,对CIFAR-10/100数据集和ImageNet-1k进行了广泛的实验,实验结果表明:(1)我们的方法已经成功地将归纳偏置注入到ViTs中,因为它们的收敛速度明显快于从零开始训练,并最终超过了agent和SOTA CNN;(2)自举学习方法可以有效地优化共享权值,无需额外的参数集。
我们的贡献可概括成三个方面:
- 我们提出了基于标准ViTs构建的代理CNN,利用共享权重和归纳偏置有效地训练ViTs。
- 我们提出了一种新的自举优化算法来优化共享参数。
- 我们的实验表明,即使没有预训练,通过采用归纳偏置和合适的优化目标,ViTs可以优于SOTA CNN。
 图1
图1
图1:我的理解是,把图片送入,分别要经过代理CNN层和ViT层,两层之间互相作用,代理CNN通过归纳偏差去监督ViT层,同时ViT层把权重分享给代理CNN层,最后输出结果。这是一个基本的框架。
四、Related Work
作者从两个大方面叙述,我浅浅总结一下
(1)Vision Transformers
Transformer已经成为NLP中的SOTA和首选模型,研究人员开始将transforms用于处理CV任务。ViT利用纯Transformer架构进行图像分类,取得巨大成功。ViT的变体进一步用于更复杂CV任务。然而,ViTs依赖于大规模的预训练,在有限的训练数据下表现不佳。为了解决这个问题,一些方法试图通过启发式修改向ViTs引入归纳偏差,如稀疏注意。其他人则提出为transforms定制的新型培训方案。尽管如此,这些方法仍然需要对中等规模的数据集进行预训练。如何在没有预先训练的情况下有效地优化ViTs,特别是在小型数据集上,仍然是一个未解决的问题。我们努力在不修改网络结构的情况下,将cnn的归纳偏置注入到ViTs中。
(2)Knowledge Distillation
关于知识蒸馏大家可以参考这个https://zhuanlan.zhihu.com/p/81467832
知识蒸馏(KD)是一种模型压缩技术,它通过软标签监督将教师隐藏的知识传递给学生。为了充分转移知识,FitNets额外使用中间特征进行监督,接下来的作品提取了不同方面的更深层次信息。最近,KD的变体(mutual learning)相互学习吸引了很多人的兴趣,因为所有的模型(学生)都在同时相互学习。这种实用的学习策略已经应用于行人再识别、目标检测和人脸识别。除了相互学习的应用之外,一些研究者引入更多的监督来提高相互学习,如中间特征或特征融合。受此启发,提出利用与ViT联合优化的代理CNN。在具有自适应中间特征监督的相互学习框架下,硬编码的归纳偏差被转移到 ViT。
五、Method
本节介绍了CNN和ViTs的初步情况。然后,基于卷积层和MHSA层的关系,提出agent CNN来帮助训练ViTs。最后描述了bootstrapping优化算法,其中agent和ViT在没有预先训练的情况下进行了联合优化。该方法的工作流程如图2所示:
 图2
图2
1.Preliminaries
1.1 Convolution
一系列视觉标记 作为输入, 为维度的嵌入式向量,所以具有内核大小()的卷积输出序列,是X的线性投影之和:
 公式1
公式1
其中是一个常数稀疏矩阵,表示局部依赖的硬编码归纳偏差,接收域的大小 ,并且投影矩阵 是可训练的。
1.2 MHSA
ViTs中的多头自我注意机制(MHSA)以一系列视觉标记作为输入,也可以像公式1一样进行公式化:
 公式2
公式2
H是头的数量;和是两个投影矩阵的组合(),
是基于线性投影标记的两两相似度计算的密集注意矩阵。
2.Agent CNN
由于公式1和公式2相似,卷积层可以被视为具有稀疏关系矩阵 Ψ 的 MHSA 层的特例,我们建议基于给定的ViT构造一个代理CNN,从零开始训练时收敛更快。
2.1 Generalized Convolution
首先,我们提出一种广义卷积层,其接受域的大小N等于MHSA层的头数H,命名为CONV,带有硬编码的归纳偏差 :
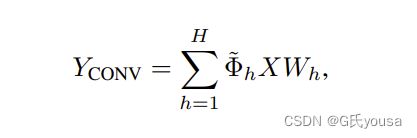 公式3
公式3
2.2 Constructing Agent CNN
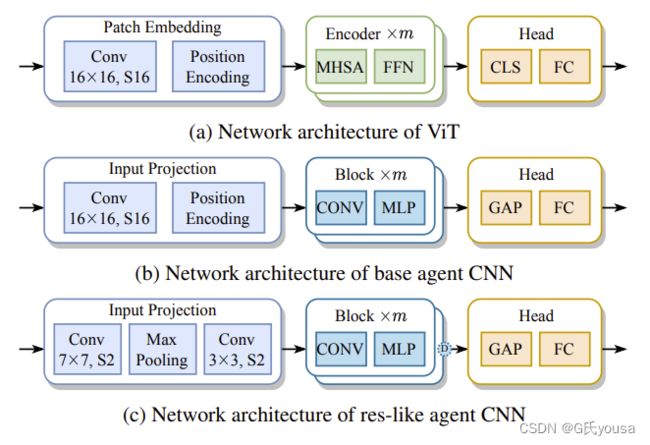 图3
图3
3a:标准的ViT模型;3b:基础代理CNN;3c:类res代理CNN
1.代理中的MLP由两个卷积层组成,相当于Transformers FFNs中的全连接层。
2.图3b将ViT的MHSA层替换为CONV层,得到了base agent CNN,res-like agent CNN也同理。
3.我们通过以下方法构建最终的res-like agent CNN(图3c):(1)引入ResNet风格的输入投影块,该投影块包含两个卷积层和一个最大池化层,(2)在每个编码器层后采用可配置的下样本。
4.通过硬编码的归纳偏差,agent比从头训练对应的ViT收敛更快,性能更高,如图5第三张所示。
Weight Sharing
利用相应的网络结构,我们提出的agent接受来自ViT模型的共享权值,以减少训练负担。由于卷积和FC层等价,ViT每个编码器块中的FFNs可以直接由代理共享。
深度学习基础-多层前馈神经网络(FFN)的构建和反向传播训练 - LittileStar - 博客园 (cnblogs.com)https://www.cnblogs.com/justLittleStar/p/16226591.html
此外,当与公式(2)中MHSA的输出投影共享时,CONV的形式为:
 公式4
公式4
设和为MHSA输出的第c-th个标记,并相应地共享CONV。假设输入序列相同,用X表示,差 可以写成:
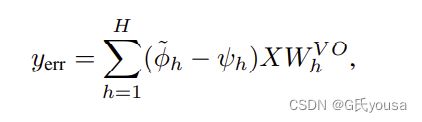 公式5
公式5
由于精力有限,该公式有一些证明在附录中,有需要可以自行去查阅。
3.Bootstrapping Optimization
3.1 Adaptive Intermediate Supervision
为了在不改变ViT结构的情况下将agent的归纳偏置注入到ViT中,我们提出了一种自适应的中间监督方法,即agent的自适应特征映射监督ViT对应的视觉序列。让和 (我没找到ℓ)分别
表示扁平的特征图和可视化序列的ℓ-th编码器层的代理和ViT,ViT 和代理的第 ℓ 层的自适应中间损
失定义为:
 公式6
公式6
式中= Adapt(F)为自适应特征,通过序列插值或二维平均池化得到。最后,自适应中间监督是所有分配层Λ的总和:
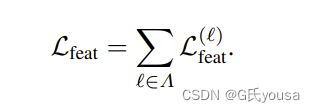 公式7
公式7
3.2 Optimization Objective
除了中间监督之外,我们引入了相互学习的框架,即ViT(记为)和agent(记为)相互学习的预测概率为:
 公式8
公式8
其中表示变量被视为常数向量,即:对于前向传播路径中的变量,没有计算梯度。是在温度T下定义的知识蒸馏损失,y表示输入图像的ground truth标签。所以,优化目标为:
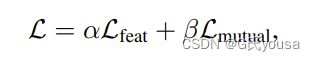
α和β是平衡两项的加权超参数。
3.3 Bootstrapping Training Algorithm
算法1给出了自举训练算法,其中每个网络计算的梯度是对齐的,并联合更新共享权值。
 算法1
算法1
六、Experiments
1.Implementation
(1)Datasets:
CIFAR-10 (CIFAR-10数据集包含60000幅32x32彩色图像,分为10个类,每个类6000幅图像。有50000张训练图像和10000张测试图像)
CIFAR-10 and CIFAR-100 datasets (toronto.edu)数据集下载
CIFAR-100(由60000张32x32彩色图像组成。CIFAR-100中的100个类被分组为20个超类。每个类有600张图片。每个图像都有一个“精细”标签(它所属的类)和一个“粗糙”标签(它所属的超类)。每个类有500个训练图像和100个测试图像)
CIFAR-100 Dataset | Papers With Code数据集下载
ImageNet-1k
图像网 (image-net.org)数据集下载
为了模拟缺乏数据的情况,从ImageNet数据集的训练分区中随机提取1%、5%和10%的标记样本。在以前的方法中,ViTs需要强大的数据增强,但在我们的实验,CNN和ViTs只通过几种简单的增强方法进行了优化,包括随机调整大小的裁剪和随机水平翻转 。
(2)Vision Transformers
下表为agent CNN和ViTs的详细配置,其中layers为层数,Heads为头的数量,Hidden size为隐藏层大小。
 表2
表2
(3)Agent CNNs
代理是根据给定的ViTs构建的,因此与ViTs共享相同的网络设置。详细配置如下:
 表6
表6
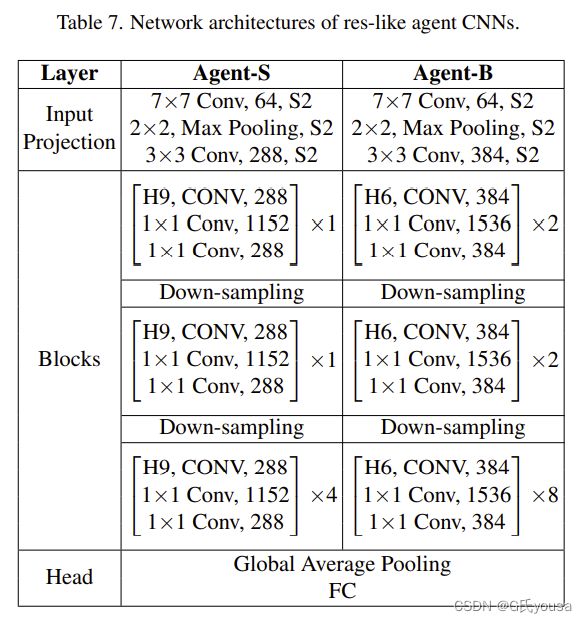 表7
表7
表6和表7:分别代表基础的代理CNN和类res的代理CNN,H9’和‘H6’分别为接受野为9和6的广义卷积。代理CNN和ViTs的输入图像被调整为224×224像素。在每个块中,CONV层取代了ViTs中的MHSA层。MLP层由两个1×1卷积层组成。最后,将来自全局平均池化层的特征输入到全连接(FC)层进行分类。Down-sampling指下采样(缩小图像)
(4)Training Details and Selection of Hyperparameters.
优化器设计理论篇(AdamW、AdaDeltaW、FTRL)https://zhuanlan.zhihu.com/p/329877052
使用Pytorch框架来实现,使用AdamW(可以参考上面的论文)对独立和联合训练方案中的ViTs和代理CNN进行优化,学习率为,权重衰减为。而传统的CNN,如ResNet和EfficientNet,则采用SGD进行优化,学习率为,权值衰减为。我们在两个 Nvidia Tesla A100 GPU 上训练了 240 个 epochs 的所有设置,批次大小为 32,采用余弦退火算法作为学习速率衰减算法
设置中间特征监督线性衰减,以保持ViTs的容量,并在之后比较了不同的衰减策略。
2.Experimental Results
我们使用以下比较设置评估我们提出的方法:
- CNN:独立的agent和传统的CNN
- ViTs:原始的ViTs及其变体,用于高效率的训练
- 预训练ViTs:在ImageNet-1k上进行预训练,然后对评估数据集进行微调的视觉Transformers
- 联合实验:视觉Transformers与代理联合优化,权重不共享
- 共享实验:视觉Transformers与代理联合优化,权重共享
(1)Performance on CIFAR Datasets.
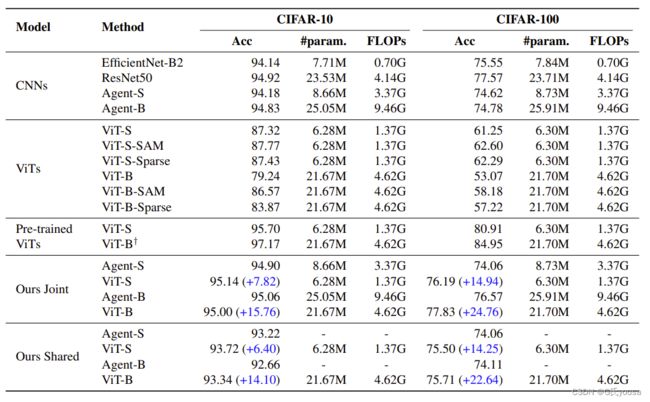 表1
表1
通过上述表1的结果可以得出:
(1)当代理CNN(Agent_S,Agent_B)单独训练时,其表现很难超越传统的CNN(ResNet,Eff- icientNet)
(2)在没有预先训练或强数据增强的情况下,由于MHSA层之间的紧密连接,ViTs的表现很差(ViTs与Pre-trained ViTs对比可得)
(3)作者提出的方法明显优于基线设置,包括原始ViTs和变体。在CIFAR-10和CIFAR-100上,ViTs(joint→ViT-s)分别比原始基线(ViTs→ViT-s) 高出7.82%和14.94%(文献这里应该写错了),在参数较少的情况下优于agent和EfficientNet-B2
(4)在共享设置中,自举学习策略证明,共享的权值可以在有限的准确性下降的情况下进行稳定的优化。ViTs的权重可以直接转移到硬编码的归纳偏差框架,这样ViTs就可以利用归纳偏差,而无需额外的一组参数或复杂的修改
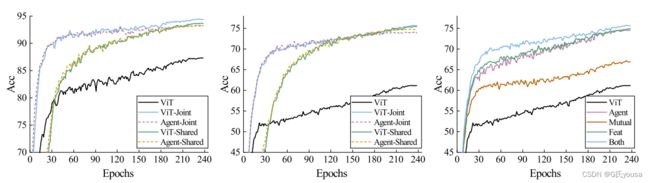 图5
图5
通过图5可以得出:
(1)ViTs可以像CNN一样快速收敛,并最终达到比CNN更高的上界(观察前两个图的蓝线和绿线,在epochs偏高时,要高于对应的紫色和橙色虚线)
(2)第三个图为消融实验的比较结果,其中Mutual仅表示具有相互知识蒸馏项 的训练,Feat仅表示具有自适应中间监督项 的训练。另外,将单独训练agent模型的曲线绘制为agent。其中Both的效果最好。
(2)Performance on ImageNet
 表3
表3
ImageNet-1k上不同数量标记图像的对比结果如表3所示:Mehod是Method(可能是打错了把,孩子也布吉岛),表示用的方法,作者随机抽取5%、10%和50%的训练图像。在数据极度匮乏的情况下,作者方法的改进是突出的,而其他的方法则显示出不明显的改善甚至是损害
3.Ablation Study
(1)Ablation of Loss Terms
最终优化目标有两个项:自适应中间监督项 和相互学习项 。在表4中,我们分别这两个项来评估有监督时的联合学习设置,可以看出两个损失项都对最终结果有贡献。为了更好地说明,图5的第三张图绘制了学习曲线:"Feat "项的收敛速度明显快于"Mutual "项。因此,通过中间特征的监督已经成功地将归纳偏差注入到ViT中。
 表4
表4
在Feat列中,√表示使用默认设置;No Decay表示 在整个训练过程中保持恒定的重量β;AP-2D表示采用2D平均池化作为公式6中的自适应函数。
(2)Ablation of Decay Strategy
特征监督衰减策略的影响如表4所示。如果没有衰减策略,性能下降了1.35%。这可以解释为,具有归纳偏差的持续监督限制了 ViTs 学习远程依赖关系,因此损害了 ViT 的上限
(3)Ablation of Adaptive Functions
作者用两个中间的特征适应性函数来评估他们的方法:1D序列插值(默认)和2D平均池化。对比结果如表4所示,序列插值优于平均池化。
4.The Choice of Agent CNNs
本文介绍了具有两种不同网络架构(base和res-like)的代理CNN。从表5可以看出,类res结构的性能均优于base结构。
 图5
图5
5.Sensitivity Analysis of Hyperparameters
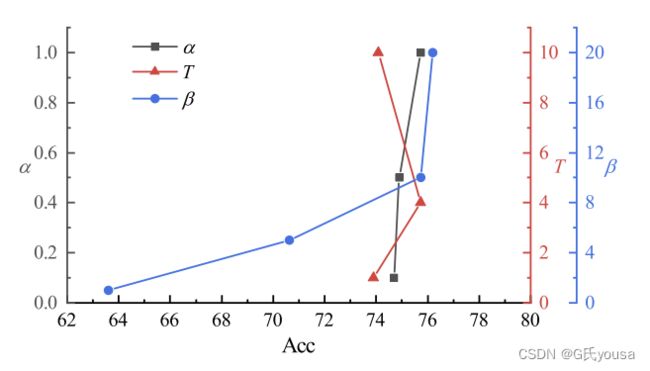 图6
图6
其中α和β在公式8中,在公式9中。图6表明:该方法对α和的变化是稳定的,然而,β有更显著的影响,当更多的归纳偏差被用于监督ViTs.时,ViTs的表现更好。
七、Conclusion and Future Work
在本文中,我们建议在不需要预先训练或强数据增强的情况下,有效地分解优化视觉变形器(ViTs)。我们的目标是将卷积神经网络(CNN)的归纳偏置引入到ViTs中,同时在更高的上界保留ViTs的网络结构,并进一步设置更合适的优化目标。为此,我们提出与针对ViT的网络架构构造的代理CNN一起对ViT进行优化。ViT通过自适应的中间监督和预测概率来学习归纳偏差。
在此基础上,提出了一种自举训练算法,对ViT和具有权值共享的智能体进行优化。大量的实验已经显示了令人鼓舞的结果,归纳偏置帮助ViTs显著更快地收敛,并且以更少的参数胜过传统CNN。在未来的工作中,我们将扩展我们的方法,超越CNN风格的归纳偏置,并为ViTs引入更多可解释的特征。
总结
本篇文章,我掌握到了很多之前没有接触过的知识,很多内容我也要去第一次去学,加深了我对该方向的一些理解。希望这篇文章可以帮助到你们呢,有什么问题还请多多指正。
