Java-基于URL与IO流的网络资源访问和下载
URL与基于IO流的网络文件下载
- 1 File类文件注释浅析
- 2 网络资源与文件的关系
- 3 网络资源与java.net.URL类
-
- 3.1 网络资源的路径表示
- 3.2 java.net.URL类
- 4 java.net.URLConnection与网络资源的简单读写
-
- 4.1 URLConnection简介
- 4.2 URLConnection实现网络资源的简单下载
- 4.3 HttpURLConnection
- 4.4 使用HttpURLConnection模拟浏览器搜索电影资源
IO流作为JavaSE体系中用于执行文件IO操作的基本单元,可在本地机上实现诸如:文件删除、创建、复制、重命名...等基本操作。但是,通过jdk源码就会发现,File类自身实现了Serializable接口,这意味着,一个File对象是可序列化的,那么文件IO操作自然也支持文件的远程网络传输(上传/下载)操作。
例如:结合java.net包下的URL类与URLConnection接口,就可以实现网络资源的简单下载功能。
以下首先介绍File-文件在Java程序中的定义与访问路径表示;其次简述网络资源与文件之间的关系、URL-资源定位符与文件路径之间的关系;再次,介绍如何通过URLConnection完成网络资源的本地下载操作;最后,介绍HttpURLConnection实现模拟浏览器搜索电影资源的案例。
1 File类文件注释浅析
JDK源码中的文档注释部分,将File类描述为:(物理)文件和路径的(逻辑)抽象表示。
用户接口和操作系统使用依赖于系统路径名称的字符串来表示“文件和路径”(user interfaces and
operating systems use system-dependent pathname-strings to name files and
directories),File类表示一个抽象的(abstract)、系统无关的(system-independent )
层次路径视图,一个抽象的路径名称包含两部分内容:
[1]一个可选的独立于系统的前缀字符串。——路径分隔符号:/或者\\
[2]0个或者多个文件名
以:
F:\Java-dependencies\apache-tomcat-9.0.43\apache-tomcat-9.0.43\conf\server.xml
或者
https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json为例,
--》抽象路径的首个名称可能是一个文件夹名称(F:\Java-dependencies\apache-tomcat-9.0.43\
apache-tomcat-9.0.43\conf\),也可能是一个主机名称(geo.datav.aliyun.com),每一级字符
序列都可以定位到一个文件夹(或者某一级域名),最后的名称则为文件名(server.xml、
100000_full.json)或者目录名。
结合实际代码,不难发现,即时磁盘上不存在某个路径或者文件,依旧可以通过new关键字创建File类的对象,这正是因为文件在逻辑概念层次上的——抽象性(abstract)和系统无关性(system-independent )。
但是,文件在物理概念层次,在实际移动、复制、删除、重命名一个File类对象时,又必须要求它对应的字符串路径在磁盘上真实存在,这正是因为——在JVM之下的操作系统底层,它使用依赖于系统路径名称的字符串来表示“文件和路径”(user interfaces and operating systems use system-dependent pathname-strings to name files and directories)
当前,文件路径又有相对路径和绝对路径之分,在此不做深究。只需明确一点:Java中用于表示文件的字符串路径,既可以是这样,又可以是那样:
这样:F:\Java-dependencies\apache-tomcat-9.0.43\apache-tomcat-9.0.43\conf\server.xml
那样:https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json
2 网络资源与文件的关系
由1 File类文件注释浅析可知,既然文件路径可以抽象表示为:https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json,那么,网络资源实质上应当就是:存储于服务器上的一个普通文件,例如:pdf、xml、png、mp4…
文件有不同的类型,那么网络资源也自然是如此。文件的类型可以根据编码格式(GBK、UTF-8…)、后缀名(*.pdf、*.jpg、*.xml、*.png、*.mp3…)等进行区分,网络资源的类型如何进行区分呢?
网络资源,在HTTP超文本传输协议中,也使用content-type响应头标签来进行标识,用于告诉客户端——服务器端当前正在返回的网络资源的内容类型。这个Content-type可以通过ServletResponse的setContentType(String)方法进行设置,它将决定浏览器客户端以什么形式、什么编码去读取这个网络资源(文件)。例如:如下所示的context-type为text/html,表示当前正在访问的网络资源是一个HTML文件。
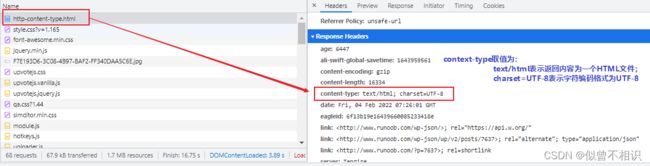
context-type属性的取值被称为MIME类型(即:媒体类型),常见的媒体格式如下所示,也可访问https://www.runoob.com/http/http-content-type.html 查看更多MIME类型取值。

3 网络资源与java.net.URL类
通过上述解读,可知:网络资源本质上是存在于服务器上的一个普通文件资源,这个资源文件的类型也叫作MIME媒体类型,HTTP将其作为标准的一部分进行实现。那么,如何访问到这个网络资源呢?
3.1 网络资源的路径表示
网络资源的路径通过URL表示。
而URL(Uniform Resource Locator),叫做资源定位符。百度将其诠释为:
在WWW(World Wide Web)万维网上,每一网络资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是万维网的统一资源定位标志,就是指网络地址。
将URL具象化,也就是我们通常看到的浏览器窗口地址栏里面的字符串。

URL-资源定位符由4部分组成:协议(protocol)、主机(host)、端口(port)、路径(path),一般其语法规则如下:
protocol :// hostname[:port] / path / [:parameters][?query]#fragment
例如:
https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json
则:
protocol:https
域名(hostname+port):geo.datav.aliyun.com(可借助域名服务器通过域名获取主机名和端口号)
path:areas_v3/bound/100000_full.json
也可使用:在线域名解析工具。
3.2 java.net.URL类
在Java编程语言中,将其URL抽象为java.net包下的URL类。有关其文档注释的部分解析如下:
URL类表示资源定位符(Uniform Resource Locator),指向万维网(the World
Wide Web)上的一个资源(Resource)。
一个资源可以是简单的文件或者目录(文件与目录在Java中被抽象为File类),或者也
可以是一个更加复杂的对象(其它类型:对于数据库或搜索引擎的一次查询操作)。
一个URL的端口号是可选的,若未明确指定,那么默认为80.
URL类可以实现类似于3.1中提到“域名解析”功能(但是这个URL类本身并不具有这个功能,而是由内部维护的URLStreamHandler抽象类来实现)
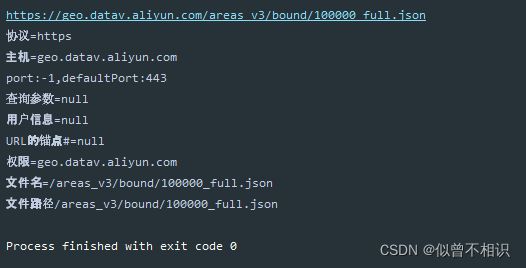
获取URL-https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json的基本信息。
package com.xwd.demo;
import java.io.File;
import java.io.IOException;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
public class URLDemo{
//methods
public static void main(String[] args) {
try {
URL url=new URL("https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json");
URLConnection connection=url.openConnection();
System.out.println(url.toString());
//获取通信协议
String protocol = url.getProtocol();
System.out.println("协议="+protocol);
//获取主机名
String host = url.getHost();
System.out.println("主机="+host);
//获取端口号
int port = url.getPort();
int defaultPort = url.getDefaultPort();
System.out.println("port:"+port+",defaultPort:"+defaultPort);
//获取请求参数
String query = url.getQuery();
System.out.println("查询参数="+query);
//
String userInfo = url.getUserInfo();
System.out.println("用户信息="+userInfo);
String ref = url.getRef();
System.out.println("URL的锚点#="+ref);
String authority = url.getAuthority();
System.out.println("权限="+authority);
//获取文件名称
String file = url.getFile();
System.out.println("文件名="+file);
//获取路径名称
String path = url.getPath();
System.out.println("文件路径"+path);
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
}
4 java.net.URLConnection与网络资源的简单读写
4.1 URLConnection简介
基于上述解读,已经可以通过一个包含指向网络资源的URL拿到它对应的文件名和路径。那么,如何实现网络资源的读写操作呢?例如:将一个网络资源通过URL来下载到本地。
就像文件IO操作,网络资源的IO操作,需要先获取一个客户端到这个网络资源所在服务器之间的URL连接对象,然后通过这个连接对象来完成各种IO操作。基本原理如下图所示。

Java编程语言中提供了java.net.URLConnection来表示客户端与网络资源之间的连接通道。对其文档注释做如下简要解读,
URLConnection抽象类是表示所有代表客户端程序与URL之间的连接(link)的类的父类。
该类的对象可以通过调用URL的openConnection()方法创建,其用于读取、写入URL指向
的资源。
4.2 URLConnection实现网络资源的简单下载
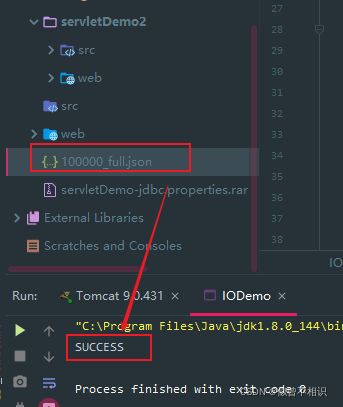
网络资源的下载操作,其示例代码如下:
package com.xwd.demo;
import java.io.*;
import java.net.URL;
import java.net.URLConnection;
/**
* @ClassName IODemo
* @Description: com.xwd.demo
* @Auther: xiwd
* @Date: 2022/2/4 - 02 - 04 - 16:27
* @version: 1.0
*/
public class IODemo {
//methods
public static void main(String[] args) {
URL url=null;
URLConnection connection=null;
InputStream inputStream=null;
OutputStream outputStream=null;
byte[] buffer=new byte[1024];
int len=-1;
try {
//提供URL-网络资源定位符
url = new URL("https://geo.datav.aliyun.com/areas_v3/bound/100000_full.json");
//获取网络资源的名称
String file = url.getFile();
String filename= file.lastIndexOf("/")==-1?file: file.substring(file.lastIndexOf("/")+1,file.length());
//获取客户端与URL的连接对象
connection = url.openConnection();
//获取输入流对象
inputStream = connection.getInputStream();
//获取输出流对象——并指定网络资源的本地保存位置
outputStream = new FileOutputStream(filename);
//执行网络资源下载操作
while ((len = inputStream.read(buffer)) != -1) {
outputStream.write(buffer,0,len);
}
System.out.println("SUCCESS");
} catch (IOException e) {
e.printStackTrace();
System.out.println("FAILED");
} finally {
//释放流资源
if (outputStream!=null) {
try {
outputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (inputStream!=null) {
try {
inputStream.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
4.3 HttpURLConnection
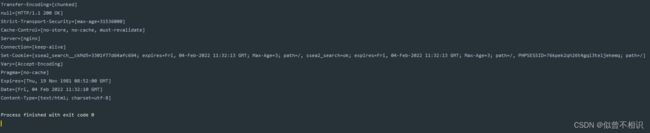
HttpURLConnection抽象类是URLConnection抽象类的子类。该类的一个对象可用于向指定网站发送GET请求、POST请求(但http服务器的底层网络连接可能会被多个对象所共享(一种HTTP服务器的多线程处理机制),在请求结束之后,调用close()方法可以使访问所占有的网络资源,但是不会对其它持久性连接(persistent connection)有任何影响。)。
它在URLConnection的基础上提供了如下便捷的方法:
int getResponseCode(); // 获取服务器的响应代码。
String getResponseMessage(); // 获取服务器的响应消息。
String getResponseMethod(); // 获取发送请求的方法。
void setRequestMethod(String method); // 设置发送请求的方法。
4.4 使用HttpURLConnection模拟浏览器搜索电影资源
示例代码如下:
其中:GET请求获取的响应结果为一个HTML页面的源码,过于冗长,就没有打印;后续还可根据结合这个HTML页面的源码,引起dom4j.jar包,实现页面信息爬取操作。
package com.xwd.demo;
import com.sun.jmx.snmp.SnmpNull;
import java.io.*;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import java.util.Set;
/**
* @ClassName IODemo
* @Description: com.xwd.demo
* @Auther: xiwd
* @Date: 2022/2/4 - 02 - 04 - 16:27
* @version: 1.0
*/
public class IODemo {
//methods
public static void main(String[] args) {
HttpURLConnectionTest();
}
//http://www.sdpxgd.com/search.php?searchword=画江湖
private static void HttpURLConnectionTest(Object... args) {
URL url= null;
HttpURLConnection connection =null;
InputStream inputStream=null;
BufferedReader reader=null;
try{
//获取URL对象
url = new URL("http://www.sdpxgd.com/search.php?searchword=%E7%94%BB%E6%B1%9F%E6%B9%96");
//获取HttpURLConnection对象
connection = (HttpURLConnection) url.openConnection();
//设置请求参数
connection.setDoOutput(false);//是否向HttpURLConnection输出
connection.setDoInput(true);//是否从HttpURLConnection读入
connection.setRequestMethod("GET");//设置请求方式
connection.setUseCaches(true);//设置是否使用缓存
connection.setInstanceFollowRedirects(true);//设置是否应当自动执行HTTP重定向
connection.setConnectTimeout(3000);//设置超时响应时间
//执行连接
connection.connect();
//获取状态码
int responseCode = connection.getResponseCode();
//获取数据
String msg="";
if (responseCode==200){
//获取输入流对象
inputStream = connection.getInputStream();
reader=new BufferedReader(new InputStreamReader(inputStream));
//读取信息
String line=null;
while ((line=reader.readLine())!=null)
msg+=line+"\n";
}
//查询结果打印
//System.out.println(msg);//这里打印的是搜索结果页面的HTML代码,内容太多,就不打印了
//打印响应体信息
Map<String, List<String>> headerFields = connection.getHeaderFields();
Set<Map.Entry<String, List<String>>> entries = headerFields.entrySet();
Iterator<Map.Entry<String, List<String>>> iterator = entries.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next().toString());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} finally {
if (reader!=null) {
try {
reader.close();
} catch (IOException e) {
e.printStackTrace();
}
}
//断开连接
if (connection!=null) {
connection.disconnect();
}
}
}
}