K8S集群部署kube-Prometheus监控Ceph(版本octopus)集群、并实现告警。
K8S集群部署kube-Prometheus监控Ceph(版本octopus)集群、并实现告警。
一、背景描述
公司K8S集群后端存储采用的是cephfs,测试环境经常性出现存储故障,虽然最后都解决了但是也比较耗时,于是决定还是把监控做上,测试环境已经有Prometheus了,那就直接采用prometheus实现数据采集。granfa做展示。
除了 Kubernetes 集群中的一些资源对象、节点以及组件需要监控,有的时候我们可能还需要根据实际的业务需求去添加自定义的监控项,添加一个自定义监控的步骤也是非常简单的,主要有以下三个步骤:
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项;
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象;
第三步确保 Service 对象可以正确获取到 Metrics 数据;
Ceph版本为:
[root@k8s01 ceph_exporter]# ceph version
ceph version 15.2.4 (7447c15c6ff58d7fce91843b705a268a1917325c) octopus (stable)
通过度娘得知
在Ceph Luminous之前的版本,可以使用第三方的Prometheus exporterceph_exporter。 Ceph Luminous 12.2.1的mgr中自带了Prometheus插件,内置了 Prometheus ceph exporter,可以使用Ceph mgr内置的exporter作为Prometheus的target。
注:Prometheus、Granfa已经提前部署好,这里就不做演示了!
二、Ceph节点配置
①、启用ceph mgr prometheus插件
[root@k8s01 ceph_exporter]# ceph -s #查看ceph集群状态
cluster:
id: b5f36dec-8faa-4efa-b08d-cbcd8305ae63
health: HEALTH_OK
services:
mon: 3 daemons, quorum k8s01,k8s03,k8s04 (age 2d)
mgr: k8s01(active, since 3d)
mds: cephfs:1 {0=k8s01=up:active}
osd: 3 osds: 3 up (since 2d), 3 in (since 3d)
task status:
scrub status:
mds.k8s01: idle
data:
pools: 3 pools, 81 pgs
objects: 26.35k objects, 6.5 GiB
usage: 24 GiB used, 216 GiB / 240 GiB avail
pgs: 81 active+clean
io:
client: 70 KiB/s wr, 0 op/s rd, 7 op/s wr
[root@k8s01 ceph_exporter]# ceph mgr module enable prometheus #启用prometues exporter
[root@k8s01 ceph_exporter]# netstat -nltp | grep mgr #prometues exporter启动的端口是9283
tcp 0 0 0.0.0.0:9283 0.0.0.0:* LISTEN 1252/ceph-mgr
tcp 0 0 172.16.1.11:6810 0.0.0.0:* LISTEN 1252/ceph-mgr
tcp 0 0 172.16.1.11:8443 0.0.0.0:* LISTEN 1252/ceph-mgr
tcp 0 0 172.16.1.11:6811 0.0.0.0:* LISTEN 1252/ceph-mgr
②、通过浏览器访问:http://172.16.1.11:9283
可以打开接口了!

点击Metrics查看获取到的数据
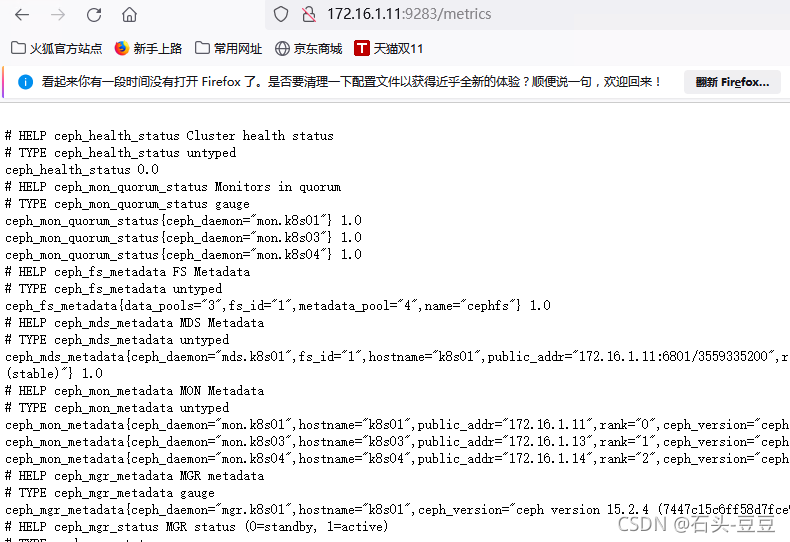
三、Prometheus配置
参考:https://www.cnblogs.com/fengjian2016/p/12666361.html#top 成功部署target
①、添加ceph-cluster的 prometheus-servicemonitor
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: ceph-cluster
namespace: monitoring
labels:
app: ceph-cluster
spec:
jobLabel: ceph-cluster
endpoints:
- port: port
interval: 30s
scheme: http
selector:
matchLabels:
app: ceph-cluster
namespaceSelector:
matchNames:
- kube-system
②、kube-prometheus 添加 rocketmsq service和 endpoint ,把ceph集群服务导入到集群
apiVersion: v1
kind: Endpoints
metadata:
name: ceph-cluster
namespace: kube-system
labels:
app: ceph-cluster
subsets:
- addresses:
- ip: 172.16.1.11
ports:
- name: port
port: 9283
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
name: ceph-cluster
namespace: kube-system
labels:
app: ceph-cluster
spec:
type: ClusterIP
clusterIP: None
ports:
- name: port
port: 9283
protocol: TCP
查看prometheus dashboard
新添加的targets已经出来了

四、granfa展示
①、导入 2842 模板
②、展示

五、告警规则
①、修改prometheus-rules.yaml文件
添加如下这段
[root@k8s01 manifests]# vim kube-prometheus/manifests/prometheus-rules.yaml
- name: Ceph集群-监控告警
rules:
- alert: Ceph 集群状态异常
expr: ceph_health_status > 0
for: 3m
labels:
status: 非常严重
annotations:
summary: "{{$labels.instance}}: Ceph集群状态异常"
description: "{{$labels.instance}}:Ceph集群状态异常,当前状态为{{ $value }}"
- alert: Ceph OSD Down
expr: ceph_osd_down > 0
for: 3m
labels:
status: 非常严重
annotations:
summary: "{{$labels.instance}}: 有{{ $value }}个OSD挂掉了"
description: "{{$labels.instance}}:{{ $labels.osd }}当前状态为{{ $labels.status }}"
- alert: ceph集群空间使用率过高
expr: ceph_cluster_total_used_bytes / ceph_cluster_total_bytes * 100 > 80
for: 3m
labels:
status: 非常严重
annotations:
summary: "{{$labels.instance}}:集群空间不足"
description: "{{$labels.instance}}:当前空间使用率为{{ $value }}"
②、登录prometheus 查看Alerts是否加载出来

测试告警
注:prometheus 钉钉告警因为之前已经搭建好,所以这里略过!
直接看告警。
