python实验12_中文文本分析
实验12:中文文本分析
1.实验目标及要求
(1)掌握jieba库的常用方法。
(2)掌握使用WordCloud库绘制词云的方法。
(3)掌握使用networkx库绘制关系图的方法。
2. 实验主要内容
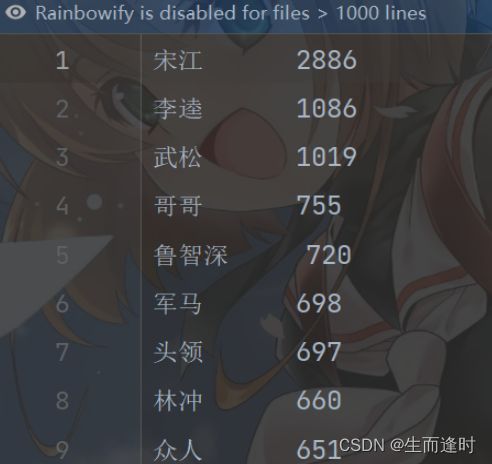
(1)分析文本“水浒.txt”,分词并统计有实质意义的词频(跟内容息息相关)。
(2)将《水浒》中的高频词制作词云。
(3)分析每一章节的“喜怒哀乐”走向。
(4)使用networkx库绘制《水浒传》中的人物关系图。对小说中关键人物的称呼进行必要的统一,计算人物之间的共现关系(假设出现在同一个段落中的人物之间具有共现关系),根据人物的共现关系绘制人物关系图。
代码部分:(1)
import jieba
s=open('水浒传.txt','r',encoding='utf-8',errors='ignore').read() #读取文件·
jieba.load_userdict('水浒传.txt')
words=jieba.lcut(s) # 进行分词操作
stopwords_list=[] # 创建中文停用词列表
with open('stopword.txt','r',encoding='utf-8') as f:
for line in f:
line = line[:-1]
stopwords_list.append(line)
words_dict={}
for word in words:
if len(word)==1:
continue
if word=='宋江道':
word='宋江'
if word =='智深' or word =='和尚':
word='鲁智深'
if word =='太尉':
word='高太尉'
# 长度大于1和不在停用词中的词 保存到字典并记录词频
if word not in stopwords_list:
words_dict[word]=words_dict.get(word,0)+1
words_list=list(words_dict.items())
words_list.sort(key=lambda x:x[1],reverse=True) #按词频大小排序
# 将词和词频保存在文件中
f=open('input水浒传.txt','w',encoding='utf-8')
for i in range(len(words_list)):
k,v=words_list[i]
f.write('{:<8}{:>2}\n'.format(k,v))
f.close()
print('输出成功')
输出结果


代码部分:(2)
# 生成词云图
from imageio.v2 import imread
import wordcloud
text=open('input水浒传.txt','r',encoding='utf-8').read()
wordmap=wordcloud.WordCloud(background_color='white',width=1000,height=800,font_path=r'C:\Windows\Fonts\simkai.ttf',mask=imread('1.jpg'))
wordmap.generate(text)
wordmap.to_file('词云图.jpg')

代码部分:(3)
import re
import matplotlib.pyplot as plt
f=open('水浒传.txt','r',encoding='utf8').read()
lst_chapter=[]
chapter=re.findall("第[\u4E00-\u9FA5]+回",f)
for x in chapter:
if x=='第三卷上有回' or x=='第方回' or x=='第一百零五回宋公明避暑疗军兵乔道清回':
continue
if x not in lst_chapter:
lst_chapter.append(x)
lst_start_chapter=[]
for x in lst_chapter:
lst_start_chapter.append(f.index(x))
lst_end_chapter=lst_start_chapter[1:]+[len(f)]
lst_chapter=list(zip(lst_start_chapter,lst_end_chapter))
cnt_enjoy=[]
cnt_cry=[]
cnt_pity=[]
cnt_laugh=[]
for i in range(120):
start=lst_chapter[i][0]
end=lst_chapter[i][1]
cnt_enjoy.append(f[start:end].count('喜'))
cnt_laugh.append(f[start:end].count('乐'))
cnt_cry.append(f[start:end].count('怒'))
cnt_pity.append(f[start:end].count('哀'))
plt.subplot(2,2,1)
plt.plot(range(120),cnt_enjoy,label='喜')
plt.legend()
plt.subplot(2,2,2)
plt.plot(range(120),cnt_cry,label='怒')
plt.legend()
plt.subplot(2,2,3)
plt.plot(range(120),cnt_pity,label='哀')
plt.legend()
plt.subplot(2,2,4)
plt.plot(range(120),cnt_laugh,label='乐')
plt.legend()
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.show()

代码部分:(4)
from matplotlib import pyplot as plt
import networkx as nx
Names=['宋江','林冲','武松','吴用','卢俊义','鲁智深','柴进','公孙胜','戴宗','晁盖','朱仝','燕青','高太尉','杨志','史进','西门庆','阮小七']
relations={}
lst_para=open('水浒传.txt','r',encoding='utf-8').read().split('\n')#lst_para是每一段
for text in lst_para:
for name_0 in Names:
if name_0 in text:
for name_1 in Names:
if name_1 in text and name_0!=name_1 and (name_1,name_0) not in relations:
relations[(name_0,name_1)]=relations.get((name_0,name_1),0)+1
maxRela=max([v for k,v in relations.items()])
relations={k:v / maxRela for k,v in relations.items()}
plt.figure(figsize=(15,15))
G=nx.Graph()
for k,v in relations.items():
G.add_edge(k[0],k[1],weight=v)
#筛选权重大于0.6的边
elarge=[(u,v) for (u,v,d) in G.edges(data=True) if d['weight']>0.6]
#筛选权重大于0.3小于0.6的边
emidle=[(u,v) for (u,v,d) in G.edges(data=True) if (d['weight']>0.3) & (d['weight']<=0.6)]
#筛选权重小于0.3的边
esmall=[(u,v) for (u,v,d) in G.edges(data=True) if d['weight']<=0.3]
#设置图形布局
pos=nx.spring_layout(G)
#设置节点样式
nx.draw_networkx_nodes(G,pos,alpha=0.8, node_size=1200)
#设置大于0.6的边的样式
nx.draw_networkx_edges(G,pos,edgelist=elarge, width=2.5,alpha=0.9,edge_color='g')
#0.3~0.6
nx.draw_networkx_edges(G,pos,edgelist=emidle, width=1.5,alpha=0.6,edge_color='y')
#<0.3
nx.draw_networkx_edges(G,pos,edgelist=esmall, width=1,alpha=0.4,edge_color='b',style='dashed')
nx.draw_networkx_labels(G,pos,font_size=12)
plt.rcParams['font.sans-serif'] =['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.axis('off')
plt.title("水浒传人物关系图")
plt.show()

3. 心得体会
经过本次实验,感觉到了难度的升高,也是到目前为止感觉难度最高的一次实验里。因为对这三个模块不是很熟悉,所以需要从基础开始入手来进行学习这三个模块的知识点。对于jieba库的学习还算是轻松,因为实验内容就是知识点的基础内容,也是使用最多的,所以根据视频讲解也是很快的就完成了对文章的分词操作,关键是引入停用词文件,将不需要的高频词去掉,就能得到跟文章相关性比较大的词频了。对于WordCloud库绘制词云的学习也是轻松,因为所用到的代码也就是几行而已,感叹到这个模块的功能强大,只要简单的一行代码,调用模块内部函数,将传入的参数生成一张词云图,可见python的模块确实给使用者提供了相当大的帮助。唯一遇到头疼的就是networkx库了,看完PPT也算是茅塞顿开,将这一块的知识点成功的填补完成,将剩下的人际关系图结合matplotlib库做出来了。