一文读懂RocketMQ的存储机制
一、存储方式
业界主流的 MQ 产品像 RabbitMQ、RocketMQ、ActiveMQ、Kafka 都是支持持久化存储的,而 ZeroMQ 不需要支持持久化存储。业务系统也确实需要 MQ 支持持久化存储能力,这样可以增大系统的高可用性。但存储方式和效率来看,我们可以分为文件系统、分布式 KV 存储、关系型数据库三种方式:
1、文件系统
目前业界较为常用的几款产品(RabbitMQ、RocketMQ、ActiveMQ、Kafka)均采用的是消息刷盘至所部署虚拟机/物理机的文件系统来做持久化(刷盘一般可以分为异步刷盘和同步刷盘两种模式)。消息刷盘为消 息存储提供了一种高效率、高可靠性和高性能的数据持久化方式。除非部署 MQ 机器本身或是本地磁 挂了,否则一般是不会出现无法持久化的故障问题。
2、分布式KV存储
这类 MQ 一般会采用诸如 LevelDB、RocksDB 、Redis 来作为消息持久化的方式,由于分布式缓存的读写能力要优于DB,所以在对消息的读写能力要求都不是比较高的情况下,这种方案也倒还不错。消息存储于分布式 KV 需要解决的问题在于如何保证 MQ 整体的可靠性?
3、关系型数据库
Apache 下开源的另外一款 MQ——ActiveMQ (默认采用的 KahaDB 做消息存储)可选用 JDBC 的方式来做消息持久化,通过简单的 xml 配置信息即可实现 JDBC 消息存储。由于,普通关系型数据库(如 Mysql )在单表数据量达到千万级别的情况下,其 IO 读写性能往往会出现瓶颈。在可靠性方面,该种方案非常依赖 DB,如果一旦 DB 出现故障,则 MQ 的消息就无法落盘存储会导致线上故障。
三种方式对比:
从存储效率来说:文件系统>分布式KV存储>关系型数据库
从易用性来说:关系型数据库>分布式KV存储>文件系统
二、消息的发送与存储
我们先来看这么一张图,让你对整个 RocketMQ 消息的发送与存储有个大致的脉络。

可以看出消息存储架构图中主要有下面三个跟消息存储相关的文件构成。
1、CommitLog 文件
RocketMQ 的混合型存储结构针对 Producer 和 Consumer 分别采用了数据和索引部分相分离的存储结构,Producer 发送消息至 Broker 端,然后 Broker 端使用同步或者异步的方式对消息刷盘持久化,保存至 CommitLog 中。
CommitLog 存储逻辑视图如下图所示,每条消息的前 4 个字节存储该消息的总长度。

CommitLog 文件的存储目录默认为 ${ROCKET_HOME}/store/commitlog。
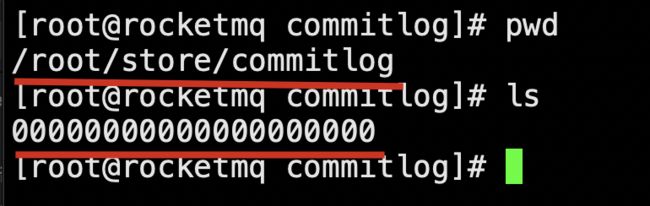
看到上面的 00000000000000000000 文件了吗?这就代表的 commitlog 目录下的第一个文件,该文件主要存储消息主体以及元数据的主体,存储 Producer 端写入的消息主体内容,消息内容不是定长的。单个文件大小默认 1G ,文件名长度为 20 位,左边补零,剩余为起始偏移量。比如 00000000000000000000 代表了第一个文件,起始偏移量为 0,文件大小为 1G=1073741824;当第一个文件写满了,第二个文件为 00000000001073741824,起始偏移量为 1073741824,以此类推。消息主要是顺序写入日志文件,当文件满了,写入下一个文件。
不知道你有没有疑问?commitlog 文件保存着所有的主题消息,那像消费者订阅了某个主题的话,是如何保证高效的检索出你所订阅的主题呢?而且 RocketMQ 基于磁盘存储的,为啥这么高效呢?
盲猜消息基于磁盘的顺序存储的,为啥呢?
目前的高性能磁盘,顺序写速度可以达到 600MB/s, 超过了一般网卡的传输速度。
但是磁盘随机写的速度只有大概 100KB/s,和顺序写的性能相差 6000 倍!
因为有如此巨大的速度差别,好的消息队列系统会比普通的消息队列系统速度快多个数量级。
RocketMQ 的消息用顺序写,保证了消息存储的速度。
除了消息的顺序写能保证如此高效以外,老周带你了解 RocketMQ 引入的 ConsumeQueue 消费队列文件,这个文件就是为了解决上述高效的检索出你所订阅的主题的问题。
2、ConsumeQueue 文件
在说 ConsumeQueue 之前,老周觉得很有必要先说下 MessageQueue。
2.1 MessageQueue
我们知道,在发送消息的时候,要指定一个 Topic。那么,在创建 Topic 的时候,有一个很重要的参数 MessageQueue 。简单来说,就是你这个 Topic 对应了多少个队列,也就是几个 MessageQueue,默认是 4 个。那它的作用是什么呢?
它是一个数据分片的机制。比如我们的 Topic 里面有 100 条数据,该 Topic 默认是 4 个队列,那么每个队列中大约 25 条数据。然后,这些 MessageQueue 是和 Broker 绑定在一起的,就是说每个 MessageQueue 都可能处于不同的 Broker 机器上,这取决于你的队列数量和 Broker 集群。有点像 Kafka 的分片机制哈,因为 RocketMQ 正是参照 Kafka 的设计原理来搞的,说到这里,老周又不得不感叹下老外的创新以及设计能力了。国内虽说开源慢慢在进步了,但创新、颠覆式的产品还是很少呀。
我们来看下面的图,0、1、2、3 就是 MessageQueue,符合上面提到的默认 4 个 MessageQueue。老周这里是单机环境哈,所以它们的 BrokerName 都是指向同一台机器。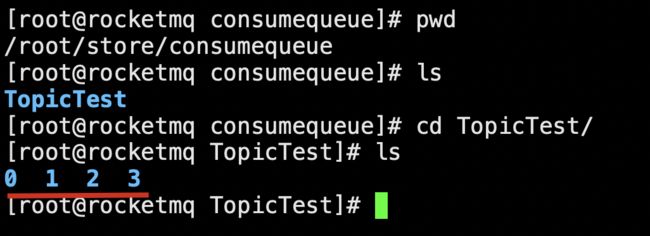
2.2 ConsumeQueue
说完了 MessageQueue ,我们接着来看 ConsumerQueue 。上面我们说,它是为了高效检索主题消息的。
为了加速 ConsumeQueue 消息条目的检索速度与节省磁盘空间,每一个 ConsumeQueue 条目都不会存储消息的全量信息,其存储格式如下图:

单个文件由 30W 个条目组成,可以像数组一样随机访问每一个条目,每个条目共 20 个字节,所以单个 ConsumeQueue 文件大小 30W✖️20 字节约5.72M。
说到这里,为啥能高效检索主题消息,心里应该豁然开朗了吧。
单个 ConsumeQueue 文件可以看出是一个 ConsumeQueue 条目的数组,其下标为 ConsumeQueue 的逻辑偏移量,消息消费进度存储的偏移量即逻辑偏移量。ConsumeQueue 即为 CommitLog 文件的索引文件,其构建机制是当消息到达 CommitLog 文件后,由专门的线程产生消息转发任务,从而构建消息消费队列文件与下文提到的索引文件。
3、Index 文件
上面我们提到的是通过消息偏移量来查找消息的方式,但 RocketMQ 还提供了其它几种方式可以查询消息。
通过 Message Key 查询
通过 Unique Key查询
通过 Message Id查询
在这里, Message Key 和 Unique Key 都是在消息发送之前,由客户端生成的。我们可以自己设置,也可以由客户端自动生成, Message Id 是在 Broker 端存储消息的时候生成。
3.1 通过 Message Id 查询
/**
* 创建消息ID
* @param input
* @param addr Broker服务器地址
* @param offset 正在存储的消息,在Commitlog中的偏移量
* @return
*/
public static String createMessageId(final ByteBuffer input, final ByteBuffer addr, final long offset) {
input.flip();
int msgIDLength = addr.limit() == 8 ? 16 : 28;
input.limit(msgIDLength);
input.put(addr);
input.putLong(offset);
return UtilAll.bytes2string(input.array());
}
当我们根据 Message Id 向 Broker 查询消息时,首先会通过一个 decodeMessageId 方法,将 Broker 地址和消息的偏移量解析出来。
public static MessageId decodeMessageId(final String msgId) throws Exception {
SocketAddress address;
long offset;
int ipLength = msgId.length() == 32 ? 4 * 2 : 16 * 2;
byte[] ip = UtilAll.string2bytes(msgId.substring(0, ipLength));
byte[] port = UtilAll.string2bytes(msgId.substring(ipLength, ipLength + 8));
ByteBuffer bb = ByteBuffer.wrap(port);
int portInt = bb.getInt(0);
// 解析出来Broker地址
address = new InetSocketAddress(InetAddress.getByAddress(ip), portInt);
// 偏移量
byte[] data = UtilAll.string2bytes(msgId.substring(ipLength + 8, ipLength + 8 + 16));
bb = ByteBuffer.wrap(data);
offset = bb.getLong(0);
return new MessageId(address, offset);
}
所以通过 Message Id 查询消息的时候,实际上还是直接从特定 Broker 上的 CommitLog 指定位置进行查询,属于精确查询。
这个也没问题,但是如果通过 Message Key 和 Unique Key 查询的时候, RocketMQ 又是怎么做的呢?
3.2 Index 索引文件
ConsumerQueue 消息消费队列是专门为消息订阅构建的索引文件,提高根据主题与消息队列检索消息的速度。
另外, RocketMQ 引入 Hash 索引机制,为消息建立索引,它的键就是 Message Key 和 Unique Key 。
那我们来看下 RocketMQ 索引文件布局图:

我们发送的消息体中,包含 Message Key 或 Unique Key ,那么就会给它们每一个都构建索引。
根据消息 Key 计算 Hash 槽的位置
根据 Hash 槽的数量和 Index 索引来计算 Index 条目的起始位置
将当前 Index 条目的索引值,写在 Hash 槽 absSlotPos 位置上;将 Index 条目的具体信息 (hashcode/消息偏移量/时间差值/hash槽的值) ,从起始偏移量 absIndexPos 开始,顺序按字节写入。
RocketMQ 将消息索引键与消息偏移量映射关系写入到 IndexFile 的实现方法为:
/**
* 将消息索引键与消息偏移量映射关系写入到 IndexFile
* @param key 消息索引
* @param phyOffset 消息物理偏移量
* @param storeTimestamp 消息存储时间
* @return
*/
public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) {
if (this.indexHeader.getIndexCount() < this.indexNum) {
// 计算key的hash
int keyHash = indexKeyHashMethod(key);
// 计算hash槽的坐标
int slotPos = keyHash % this.hashSlotNum;
int absSlotPos = IndexHeader.INDEX_HEADER_SIZE + slotPos * hashSlotSize;
// 计算时间差值
long timeDiff = storeTimestamp - this.indexHeader.getBeginTimestamp();
timeDiff = timeDiff / 1000;
// 计算INDEX条目的起始偏移量
int absIndexPos =
IndexHeader.INDEX_HEADER_SIZE + this.hashSlotNum * hashSlotSize
+ this.indexHeader.getIndexCount() * indexSize;
// 依次写入hashcode、消息偏移量、时间戳、hash槽的值
this.mappedByteBuffer.putInt(absIndexPos, keyHash);
this.mappedByteBuffer.putLong(absIndexPos + 4, phyOffset);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8, (int) timeDiff);
this.mappedByteBuffer.putInt(absIndexPos + 4 + 8 + 4, slotValue);
// 将当前INDEX中包含的条目数量写入HASH槽
this.mappedByteBuffer.putInt(absSlotPos, this.indexHeader.getIndexCount());
return true;
}
return false;
}
这样构建完Index索引之后,根据 Message Key 或 Unique Key 查询消息就简单了。
比如我们通过 RocketMQ 客户端工具,根据 Unique Key 来查询消息。
adminImpl.queryMessageByUniqKey("order","FD88E3AB24F6980059FDC9C3620464741BCC18B4AAC220FDFE890007");
在 Broker 端,通过 Unique Key 来计算 Hash 槽的位置,从而找到 Index 索引数据。从 Index 索引中拿到消息的物理偏移量,最后根据消息物理偏移量,直接到 CommitLog 文件中去找就可以了。
在 Broker 端,通过 Unique Key 来计算 Hash 槽的位置,从而找到 Index 索引数据。从 Index 索引中拿到消息的物理偏移量,最后根据消息物理偏移量,直接到 CommitLog 文件中去找就可以了。
三、文件存储模型层次结构

RocketMQ 文件存储模型层次结构如上图所示,根据类别和作用从概念模型上大致可以划分为 5 层,下面将从各个层次分别进行分析和阐述:
1、RocketMQ 业务处理器层:Broker 端对消息进行读取和写入的业务逻辑入口,这一层主要包含了业务逻辑相关处理操作(根据解析 RemotingCommand 中的 RequestCode 来区分具体的业务操作类型,进而执行不同的业务处理流程),比如前置的检查和校验步骤、构造 MessageExtBrokerInner 对象、decode 反序列化、构造 Response 返回对象等。
2、RocketMQ 数据存储组件层;该层主要是 RocketMQ 的存储核心类——DefaultMessageStore,其为 RocketMQ 消息数据文件的访问入口,通过该类的 putMessage() 和 getMessage() 方法完成对 CommitLog 消息存储的日志数据文件进行读写操作(具体的读写访问操作还是依赖下一层中 CommitLog对象模型提供的方法);另外,在该组件初始化时候,还会启动很多存储相关的后台服务线程,包括 AllocateMappedFileService(MappedFile预分配服务线程)、ReputMessageService(回放存储消息服务线程)、HAService(Broker 主从同步高可用服务线程)、StoreStatsService(消息存储统计服务线程)、IndexService(索引文件服务线程)等。
3、RocketMQ 存储逻辑对象层:该层主要包含了 RocketMQ 数据文件存储直接相关的三个模型类 IndexFile、ConsumerQueue 和 CommitLog。IndexFile 为索引数据文件提供访问服务, ConsumerQueue 为逻辑消息队列提供访问服务,CommitLog 则为消息存储的日志数据文件提供访问服务。这三个模型类也是构成了 RocketMQ 存储层的整体结构。
4、封装的文件内存映射层:RocketMQ 主要采用 JDK NIO 中的 MappedByteBuffer 和 FileChannel 两种方式完成数据文件的读写。其中,采用 MappedByteBuffer 这种内存映射磁盘文件的方式完成对大文件的读写,在 RocketMQ 中将该类封装成MappedFile 类。这里限制的问题在上面已经讲过;对于每类大文件(IndexFile/ConsumerQueue/CommitLog),在存储时分隔成多个固定大小的文件(单个 IndexFile 文件大小约为 400M、单个 ConsumerQueue 文件大小约 5.72M、单个 CommitLog文件大小为 1G),其中每个分隔文件的文件名为前面所有文件的字节大小数 +1,即为文件的起始偏移量,从而实现了整个大文件的串联。这里,每一种类的单个文件均由 MappedFile 类提供读写操作服务(其中,MappedFile 类提供了顺序写/随机读、内存数据刷盘、内存清理等和文件相关的服务)。
5、磁盘存储层:主要指的是部署 RocketMQ 服务器所用的磁盘。这里,需要考虑不同磁盘类型(如 SSD 或者普通的 HDD)特性以及磁盘的性能参数(如 IOPS、吞吐量和访问时延等指标)对顺序写/随机读操作带来的影响。
四、总结
RocketMQ 的存储机制主要介绍了存储方式,每种方式都有相应优劣吧,需要根据自己的业务场景来选择。然后介绍了消息的发送与存储,消息存储主要由 CommitLog 文件、ConsumeQueue 文件以及 Index 文件构成。最后介绍了文件存储模型层次结构,通过层次结构与上面的消息存储结构图,让你更清晰的了解 RocketMQ 整个消息存储与持久化的机制。
消息存储这一块的源码还是比较复杂的,后续老周有时间再慢慢分析。
特别推荐一个分享架构+算法的优质内容,还没关注的小伙伴,可以长按关注一下:
长按订阅更多精彩▼
如有收获,点个在看,诚挚感谢