Kafka入门教程
Kafka入门
- 消息队列的流派
-
-
- 什么是 MQ
- 有 Broker 的 MQ
- 重 Topic
- 轻 Topic
- 无 Broker 的 MQ
-
- 一、Kafka介绍
-
- 1.Kafka的使用场景
- 2.Kafka基本概念
- 二、kafka基本使用
-
- 1.安装前的环境准备
- 2.启动kafka服务器
- 3.创建主题topic
- 4.发送消息
- 5.消费消息
-
- 几个注意点:
- 三、Kafka中的关键细节
-
- 1.消息的顺序存储
- 2. 单播消息的实现
- 3.多播消息的实现
-
- 在一些业务场景中需要让一条消息被多个消费者消费,那么就可以使用多播模式。
- 4.查看消费组及信息
- 四、主题、分区的概念
-
- 1.主题Topic
- 2.partition分区
-
- 为一个主题创建多个分区
- 分区的作用:
- 五、Kafka集群及副本的概念
-
- 1.搭建kafka集群, 3 个broker
-
- 使用如下命令来启动 3 台服务器
- 2.副本的概念
- 3.broker、主题、分区、副本
- 4.kafka集群消息的发送
- 5.kafka集群消息的消费
- 6.关于分区消费组消费者的细节
- 六、Kafka的Java客户端-生产者
-
- 1.引入依赖
- 2.生产者发送消息的基本实现
- 3.发送消息到指定分区上
- 4.未指定分区,则会通过业务key的hash运算,算出消息往哪个分区上发
- 5.同步发送
- 6.异步发消息
-
- 生产者发消息,发送完后不用等待broker给回复,直接执行下面的业务逻辑。可以提供callback,让broker异步的调用callback,告知生产者,消息发送的结果
- 7.关于生产者的ack参数配置
-
- 在同步发消息的场景下:生产者发动broker上后,ack会有 3 种不同的选择:
- code:
- 8.其他一些细节
- 七、消费者
-
- 1.消费者消费消息的基本实现
- 2.自动提交offset
- 3.手动提交offset
-
- 在消费完消息后进行手动提交
- 4.消费者poll消息的过程
- 5.指定分区消费
- 6.消息回溯消费
- 7.指定offset消费
- 8.从指定时间点消费
- 9.新消费组的消费偏移量
- 八 、Springboot中使用Kafka
-
- 1.引入依赖
- 2.配置文件
- 3.消息生产者
- 4.消息消费者
- 九、Kafka集群Controller、Rebalance和HW
-
- 1.Controller
- 2.Rebalance机制
- 3.HW和LEO
- 十、Kafka线上问题优化
-
- 1.如何防止消息丢失
- 2.如何防止消息的重复消费
-
- 幂等性如何保证:
- 3.如何做到顺序消费RocketMQ
- 4.解决消息积压问题
- 5.延迟队列
- 十一、Kafka-eagle监控平台
-
- 安装Kafka-eagle
-
- 官网下载压缩包
消息队列的流派
什么是 MQ
Message Queue(MQ),消息队列中间件。很多人都说:MQ 通过将消息的发送和接收分离来实现应用程序的异步和解偶,这个给人的直觉是——MQ 是异步的,用来解耦的,但是这个只是 MQ 的效果而不是目的。MQ 真正的目的是为了通讯,屏蔽底层复杂的通讯协议,定义了一套应用层的、更加简单的通讯协议。一个分布式系统中两个模块之间通讯要么是HTTP,要么是自己开发的(rpc) TCP,但是这两种协议其实都是原始的协议。HTTP 协议很难实现两端通讯——模块 A 可以调用 B,B 也可以主动调用 A,如果要做到这个两端都要背上WebServer,而且还不支持⻓连接(HTTP 2.0 的库根本找不到)。TCP 就更加原始了,粘包、心跳、私有的协议,想一想头皮就发麻。MQ 所要做的就是在这些协议之上构建一个简单的“协议”——生产者/消费者模型。MQ 带给我的“协议”不是具体的通讯协议,而是更高层次通讯模型。它定义了两个对象——发送数据的叫生产者;接收数据的叫消费者, 提供一个SDK 让我们可以定义自己的生产者和消费者实现消息通讯而无视底层通讯协议
有 Broker 的 MQ
这个流派通常有一台服务器作为 Broker,所有的消息都通过它中转。生产者把消息发送给它就结束自己的任务了,Broker 则把消息主动推送给消费者(或者消费者主动轮询)
重 Topic
kafka、JMS(ActiveMQ)就属于这个流派,生产者会发送 key 和数据到 Broker,由 Broker比较 key 之后决定给哪个消费者。这种模式是我们最常⻅的模式,是我们对 MQ 最多的印象。在这种模式下一个 topic 往往是一个比较大的概念,甚至一个系统中就可能只有一个topic,topic 某种意义上就是 queue,生产者发送 key 相当于说:“hi,把数据放到 key 的队列中”

如上图所示,Broker 定义了三个队列,key1,key2,key3,生产者发送数据的时候会发送key1 和 data,Broker 在推送数据的时候则推送 data(也可能把 key 带上)。
虽然架构一样但是 kafka 的性能要比 jms 的性能不知道高到多少倍,所以基本这种类型的MQ 只有 kafka 一种备选方案。如果你需要一条暴力的数据流(在乎性能而非灵活性)那么kafka 是最好的选择
轻 Topic
这种的代表是 RabbitMQ(或者说是 AMQP)。生产者发送 key 和数据,消费者定义订阅的队列,Broker 收到数据之后会通过一定的逻辑计算出 key 对应的队列,然后把数据交给队列
这种模式下解耦了 key 和 queue,在这种架构中 queue 是非常轻量级的(在 RabbitMQ 中它的上限取决于你的内存),消费者关心的只是自己的 queue;生产者不必关心数据最终给谁只要指定 key 就行了,中间的那层映射在 AMQP 中叫 exchange(交换机)。
AMQP 中有四种 exchange
- Direct exchange:key 就等于 queue
- Fanout exchange:无视 key,给所有的 queue 都来一份
- Topic exchange:key 可以用“宽字符”模糊匹配 queue
- Headers exchange:无视 key,通过查看消息的头部元数据来决定发给那个
- queue(AMQP 头部元数据非常丰富而且可以自定义)
这种结构的架构给通讯带来了很大的灵活性,我们能想到的通讯方式都可以用这四种exchange 表达出来。如果你需要一个企业数据总线(在乎灵活性)那么 RabbitMQ 绝对的值得一用
无 Broker 的 MQ
无 Broker 的 MQ 的代表是 ZeroMQ。该作者非常睿智,他非常敏锐的意识到——MQ 是更高级的 Socket,它是解决通讯问题的。所以 ZeroMQ 被设计成了一个“库”而不是一个中间件,这种实现也可以达到——没有 Broker 的目的
节点之间通讯的消息都是发送到彼此的队列中,每个节点都既是生产者又是消费者。ZeroMQ做的事情就是封装出一套类似于 Socket 的 API 可以完成发送数据,读取数据
ZeroMQ 其实就是一个跨语言的、重量级的 Actor 模型邮箱库。你可以把自己的程序想象成一个 Actor,ZeroMQ 就是提供邮箱功能的库;ZeroMQ 可以实现同一台机器的 RPC 通讯也可以实现不同机器的 TCP、UDP 通讯,如果你需要一个强大的、灵活、野蛮的通讯能力,别犹豫 ZeroMQ
一、Kafka介绍
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的
(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理
大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、
Storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编
写,Linkedin于 2010 年贡献给了Apache基金会并成为顶级开源 项目。
1.Kafka的使用场景
日志收集:一个公司可以用Kafka收集各种服务的log,通过kafka以统一接口服务的方式
开放给各种consumer,例如hadoop、Hbase、Solr等。
消息系统:解耦和生产者和消费者、缓存消息等。
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网⻚、
搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过
订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖
掘。
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产
各种操作的集中反馈,比如报警和报告。
2.Kafka基本概念
kafka是一个分布式的,分区的消息(官方称之为commit log)服务。它提供一个消息系统应该
具备的功能,但是确有着独特的设计。可以这样来说,Kafka借鉴了JMS规范的思想,但是确
并没有完全遵循JMS规范。
首先,让我们来看一下基础的消息(Message)相关术语:
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,⼀个Kafka节点就是⼀个broker,⼀个或者多个Broker可以组成⼀个Kafka集群 |
| Topic | Kafka根据topic对消息进⾏归类,发布到Kafka集群的每条消息都需要指定⼀个topic |
| Producer | 消息⽣产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于⼀个特定的Consumer Group,⼀条消息可以被多个不同的Consumer Group消费,但是⼀个Consumer Group中只能有⼀个Consumer能够消费该消息 |
| Partition | 物理上的概念,⼀个topic可以分为多个partition,每个partition内部消息是有序的 |
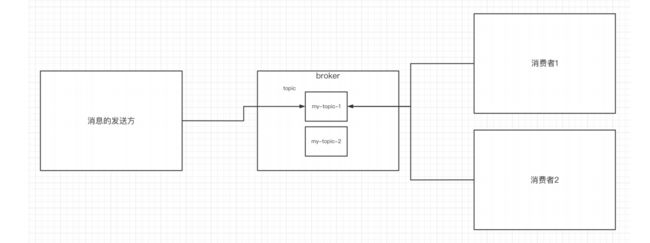
因此,从一个较高的层面上来看,producer通过网络发送消息到Kafka集群,然后consumer
来进行消费,如下图:

服务端(brokers)和客户端(producer、consumer)之间通信通过 TCP协议 来完成。
二、kafka基本使用
1.安装前的环境准备
- 安装jdk
- 安装zk
- 官网下载kafka的压缩包:http://kafka.apache.org/downloads
- 解压缩至如下路径
/usr/local/kafka/
- 修改配置文件:/usr/local/kafka/kafka2.11-2.4/config/server.properties
#broker.id属性在kafka集群中必须要是唯一
broker.id= 0
#kafka部署的机器ip和提供服务的端口号
listeners=PLAINTEXT://192.168.65.60:9092
#kafka的消息存储文件
log.dir=/usr/local/data/kafka-logs
#kafka连接zookeeper的地址
zookeeper.connect= 192.168.65.60:2181
2.启动kafka服务器
进入到bin目录下。使用命令来启动
./kafka-server-start.sh -daemon../config/server.properties
验证是否启动成功:
进入到zk中的节点看id是 0 的broker有没有存在(上线)
ls /brokers/ids/
server.properties核心配置详解:
| Property | Default | Description |
|---|---|---|
| broker.id | 0 | 每个broker都可以⽤⼀个唯⼀的⾮负整数id进⾏标识;这个id可以作为broker的“名字”,你可以选择任意你喜欢的数字作为id,只要id是唯⼀的即可。 |
| log.dirs | /tmp/kafka-logs | kafka存放数据的路径。这个路径并不是唯⼀的,可以是多个,路径之间只需要使⽤逗号分隔即可;每当创建新partition时,都会选择在包含最少partitions的路径下进⾏。 |
| listeners | PLAINTEXT://192.168.65.60:9092 | server接受客户端连接的端⼝,ip配置kafka本机ip即可 |
| zookeeper.connect | localhost:2181 | zooKeeper连接字符串的格式为:hostname:port,此处hostname和port分别是ZooKeeper集群中某个节点的host和port;zookeeper如果是集群,连接⽅式为hostname1:port1, hostname2:port2,hostname3:port3 |
| log.retention.hours | 168 | 每个⽇志⽂件删除之前保存的时间。默认数据保存时间对所有topic都⼀样。 |
| num.partitions | 1 | 创建topic的默认分区数 |
| default.replication.factor | 1 | ⾃动创建topic的默认副本数量,建议设置为⼤于等于2 |
| min.insync.replicas | 1 | 当producer设置acks为-1时,min.insync.replicas指定replicas的最⼩数⽬(必须确认每⼀个repica的写数据都是成功的),如果这个数⽬没有达到,producer发送消息会产⽣异常 |
| delete.topic.enable | false | 是否允许删除主题 |
3.创建主题topic
topic是什么概念?topic可以实现消息的分类,不同消费者订阅不同的topic。
执行以下命令创建名为“test”的topic,这个topic只有一个partition,并且备份因子也设置为1
./kafka-topics.sh --create --zookeeper 172.16.253.35:2181 --replication-factor 1 --partitions 1 --topic test
查看当前kafka内有哪些topic
./kafka-topics.sh --list --zookeeper 172.16.253.35:2181
4.发送消息
kafka自带了一个producer命令客户端,可以从本地文件中读取内容,或者我们也可以以命令行中直接输入内容,并将这些内容以消息的形式发送到kafka集群中。在默认情况下,每一个行会被当做成一个独立的消息。使用kafka的发送消息的客户端,指定发送到的kafka服务器地址和topic
./kafka-console-producer.sh --broker-list 172.16.253.38:9092 --topic test
5.消费消息
对于consumer,kafka同样也携带了一个命令行客户端,会将获取到内容在命令中进行输
出, 默认是消费最新的消息 。使用kafka的消费者消息的客户端,从指定kafka服务器的指定
topic中消费消息
方式一:从最后一条消息的偏移量+1开始消费
./kafka-console-consumer.sh --bootstrap-server 172.16.253.38:9092 --topic test
方式二:从头开始消费
./kafka-console-consumer.sh --bootstrap-server 172.16.253.38:9092 --from-beginning --topic test
几个注意点:
- 消息会被存储
- 消息是顺序存储
- 消息是有偏移量的
- 消费时可以指明偏移量进行消费
三、Kafka中的关键细节
1.消息的顺序存储
消息的发送方会把消息发送到broker中,broker会存储消息,消息是按照发送的顺序进行存储。因此消费者在消费消息时可以指明主题中消息的偏移量。默认情况下,是从最后一个消息的下一个偏移量开始消费。
2. 单播消息的实现
单播消息:一个消费组里 只会有一个消费者能消费到某一个topic中的消息。于是可以创建多个消费者,这些消费者在同一个消费组中。
./kafka-console-consumer.sh --bootstrap-server 10.31.167.10:9092 --consumer-property group.id=testGroup --topic test
3.多播消息的实现
在一些业务场景中需要让一条消息被多个消费者消费,那么就可以使用多播模式。
kafka实现多播,只需要让不同的消费者处于不同的消费组即可。
./kafka-console-consumer.sh --bootstrap-server 10.31.167.10:9092 --consumer-property group.id=testGroup1 --topic test
./kafka-console-consumer.sh --bootstrap-server 10.31.167.10:9092 --consumer-property group.id=testGroup2 --topic test
4.查看消费组及信息
# 查看当前主题下有哪些消费组
./kafka-consumer-groups.sh --bootstrap-server 10.31.167.10:9092 --list
# 查看消费组中的具体信息:比如当前偏移量、最后一条消息的偏移量、堆积的消息数量
./kafka-consumer-groups.sh --bootstrap-server 172.16.253.38:9092 --describe --group testGroup
![]()
- Currennt-offset: 当前消费组的已消费偏移量
- Log-end-offset: 主题对应分区消息的结束偏移量(HW)
- Lag: 当前消费组未消费的消息数
四、主题、分区的概念
1.主题Topic
?主题Topic可以理解成是一个类别的名称。
2.partition分区

一个主题中的消息量是非常大的,因此可以通过分区的设置,来分布式存储这些消息。比如一个topic创建了 3 个分区。那么topic中的消息就会分别存放在这三个分区中。
为一个主题创建多个分区
./kafka-topics.sh --create --zookeeper localhost:2181 --partitions 2 --topic test1
可以通过这样的命令查看topic的分区信息
./kafka-topics.sh --describe --zookeeper localhost:2181 --topic test1
分区的作用:
- 可以分布式存储
- 可以并行写
实际上是存在data/kafka-logs/test-0 和 test-1中的0000000.log文件中
小细节:
定期将自己消费分区的offset提交给kafka内部topic:__consumer_offsets,提交过去的
时候,key是consumerGroupId+topic+分区号,value就是当前offset的值,kafka会定
期清理topic里的消息,最后就保留最新的那条数据
因为__consumer_offsets可能会接收高并发的请求,kafka默认给其分配 50 个分区(可以
通过offsets.topic.num.partitions设置),这样可以通过加机器的方式抗大并发。
通过如下公式可以选出consumer消费的offset要提交到__consumer_offsets的哪个分区
公式:hash(consumerGroupId) % __consumer_offsets主题的分区数
五、Kafka集群及副本的概念
1.搭建kafka集群, 3 个broker
准备 3 个server.properties文件
每个文件中的这些内容要调整
- server.properties
broker.id= 0
listeners=PLAINTEXT://192.168.65.60: