谈谈函数指针,仿函数(函数对象)和lambda函数
文章目录
- 一、函数指针
-
- 1.函数指针的定义
- 2.函数指针的使用场景
- 二、仿函数(函数对象)
-
- 1.仿函数的定义
- 2.内建函数对象
- 三、lambda函数(表达式)
-
- 1.lambda的定义
- 2.lambda的底层
- 3.为何使用lambda
一、函数指针
1.函数指针的定义
“函数指针”是指向函数的指针变量。通常函数指针的声明如下:
void (*pf)(void)
- 第一个void的位置表示该函数的返回值
- 第二个void的位置表示该函数的参数
- pf 表示这是一个指向函数的函数指针
- (*pf)表示这是一个函数
这里需要注意运算符的优先级,必须在声明中使用括号将 *pf 括起。( )的优先级比 * 运算符高,因此
*pf( ) 意味着pf( ) 是一个返回指针的函数,而(*pf)( ) 意味着pf 是一个指向函数的函数指针。
然后我们可以对函数指针进行赋值:
int add(int a,int b) {return a+b;}
//声明
int (*pf)(int,int);
//赋值
pf = add;
我们可以以如下方式来调用函数指针:
int sum = (*pf)(10,20);
//事实上,c++也允许像使用函数名那样使用pf
int sum = pf(10,20);
2.函数指针的使用场景
使用函数指针可以设计出更优雅的程序,比如设计一个集群的通信框架的底层通信系统:首先将要每个消息的对应处理函数的指针保存映射表中(使用STL的map,键是消息的标志,值是对应的函数指针),然后启动一个线程在结点上的某个端口侦听,收到消息后,根据消息的编号,从映射表中找到对应的函数入口,将消息体数据作为参数传给相应的函数。我曾看过lam-mpi在启动集群中每个结点的进程时的实现,该模块的最上层就是一个结构体,这个结构体中仅是由函数指针构成,每个函数指针都指向一个子模块,这样做的好处就是在运行时期间可以自由的切换子模块。比如某个子模块不适合某个体系结构,只需要改动函数指针,指向另外一个模块就可。
在平时的程序设计中,经常遇到函数指针。如EnumWindows这个函数的参数,C语言库函数qsort的参数,定义新的线程时,这些地方函数指针都是作为回调函数来应用的。
还有就是unix的库函数signal(sys/signal.h)(这个函数我们将多次用到)的声明形式为:
void (*signal)(int signo,void (*func)(int)))(int);
//这个形式是相当复杂的,因为它不仅使用函数指针作为参数
//而且返回类型还是函数指针(虽然这个函数在POSIX中不被推荐使用了)。
二、仿函数(函数对象)
1.仿函数的定义
它在STL历史上有两个不同的名称。仿函数(functors)是早期的命名,c++标准规格定案后所采用的新名称是函数对象(function objects)。
函数指针可以达到“将整组操作当作算法的参数”,那又何必有所谓的仿函数呢?原因在于函数指针毕竟不能满足STL 对抽象性的要求,也不能满足软件积木的要求——函数指针无法和STL其它组件(如配接器adapter)搭配,产生更灵活的变化。
就实现观点而言,仿函数其实是一个“行为类似函数”的对象,为了能够“行为类似函数”,其类别定义中必须自定义function call 运算子operator( )。拥有这样的运算子后,我们就可以在仿函数的对象后面加上一对小括号,以此调用仿函数所定义的operator( )。
template<class T>
class greater
{
public:
void operator(T& a,T& b )() { return a>b ? a : b;}
}
int main()
{
greater<int> ig;
cout<< ig(6,4)<<endl;//产生一个有名对象
cout<< greater<int>()(6,4)<<endl;//产生一个临时的无名对象
}
2.内建函数对象
使用时需要包含头文件
STL 内建了一些函数对象,分为:
- 算术类函数对象
- 关系运算类函数对象
- 逻辑运算类函数对象
算术类函数对象:
template<class T> T plus<T>; // 加法仿函数
template<class T> T minus<T>; // 减法仿函数
template<class T> T multiplies<T>; // 乘法仿函数
template<class T> T divides<T>; // 除法仿函数
template<class T> T modulus<T>; // 取模仿函数
template<class T> T negate<T>; // 取反函数
关系运算类函数对象:
template<class T> bool equal_to<T>; // 等于
template<class T> bool not_equal_to<T>; // 不等于
template<class T> bool greater<T>; // 大于
template<class T> bool greater_equal<T>; // 大于等于
template<class T> bool less<T>; // 小于
template<class T> bool less_equal<T>; // 小于等于
逻辑运算类函数对象:
template<class T> bool logical_and<T>; // 逻辑与
template<class T> bool logical_or<T>; // 逻辑或
template<class T> bool logical_not<T>; // 逻辑非
三、lambda函数(表达式)
1.lambda的定义
C++11引入了lambda表达式,可以方便地定义一个匿名仿函数。与普通的仿函数相比,使用lambda表达式可以减少代码的冗余,从而提高程序的可读性和维护性。
lambda表达式书写格式:
[capture-list] (parameters) mutable -> return-type { statement }
- [capture-list] : 捕捉列表,该列表总是出现在lambda函数的开始位置,编译器根据[]来判断接下来的代码是否为lambda函数,捕捉列表能够捕捉上下文中的变量供lambda函数使用。
- (parameters):参数列表。与普通函数的参数列表一致,如果不需要参数传递,则可以连同()一起省略
- mutable:默认情况下,lambda函数总是一个const函数,mutable可以取消其常量性。使用该修饰符时,参数列表不可省略(即使参数为空)。
- ->returntype:返回值类型。用追踪返回类型形式声明函数的返回值类型,没有返回值时此部分可省略。返回值类型明确情况下,也可省略,由编译器对返回类型进行推导。
- {statement}:函数体。在该函数体内,除了可以使用其参数外,还可以使用所有捕获到的变量。
在lambda函数定义中,参数列表和返回值类型都是可选部分,而捕捉列表和函数体可以为空。因此C++11中最简单的lambda函数为:[]{}; 该lambda函数不能做任何事情。
以下是一些lambda的实例:
int main()
{
// 最简单的lambda表达式, 该lambda表达式没有任何意义
[]{};
// 省略参数列表和返回值类型,返回值类型由编译器推导为int
int a = 3, b = 4;
[=]{return a + 3; };
// 省略了返回值类型,无返回值类型
auto fun1 = [&](int c){b = a + c; };
fun1(10)
cout<<a<<" "<<b<<endl;
// 各部分都很完善的lambda函数
auto fun2 = [=, &b](int c)->int{return b += a+ c; };
cout<<fun2(10)<<endl;
// 复制捕捉x
int x = 10;
auto add_x = [x](int a) mutable { x *= 2; return a + x; };
cout << add_x(10) << endl;
return 0;
}
通过上述例子可以看出,lambda表达式实际上可以理解为无名函数,该函数无法直接调用,如果想要直接调用,可借助auto将其赋值给一个变量。
捕捉列表的说明:
- [var]:表示值传递方式捕捉变量var
- [=]:表示值传递方式捕获所有父作用域中的变量(包括this)
- [&var]:表示引用传递捕捉变量var
- [&]:表示引用传递捕捉所有父作用域中的变量(包括this)
- [this]:表示值传递方式捕捉当前的this指针
注意:
a. 父作用域指包含lambda函数的语句块
b. 语法上捕捉列表可由多个捕捉项组成,并以逗号分割。比如:[=, &a, &b]以引用传递的方式捕捉变量a和b,值传递方式捕捉其他所有变量[&,a, this]:值传递方式捕捉变量a和this,引用方式捕捉其他变量
c. 捕捉列表不允许变量重复传递,否则就会导致编译错误。比如:[=, a]:=已经以值传递方式捕捉了所有变量,捕捉则重复
d. 在块作用域以外的lambda函数捕捉列表必须为空。
e. 在块作用域中的lambda函数仅能捕捉父作用域中局部变量,捕捉任何非此作用域或者非局部变量都 会导致编译报错。
f. lambda表达式之间不能相互赋值,即使看起来类型相同
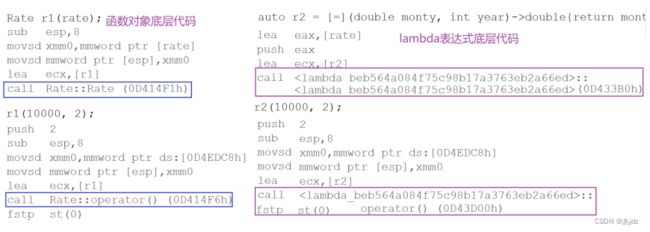
2.lambda的底层
根据下段代码查看汇编:
class Rate
{
public:
Rate(double rate): _rate(rate){}
double operator()(double money, int year){ return money * _rate * year;}
private:
double _rate;
};
int main()
{
// 函数对象
double rate = 0.49;
Rate r1(rate);
r1(10000, 2);
// lamber
auto r2 = [=](double monty, int year)->double{return monty*rate*year; };
r2(10000, 2);
return 0;
}
实际在底层编译器对于lambda表达式的处理方式,完全就是按照函数对象的方式处理的,即:如
果定义了一个lambda表达式,编译器会自动生成一个类,在该类中重载了operator()。
3.为何使用lambda
- 让定义位于使用的地方附近很有用,方便查看、修改、剪切等操作,从这个角度看,lambda是理想的选择,因为其定义和使用是在同一个地方进行的;而函数是最糟糕的选择,因为不能在函数内部定义其它函数,因此函数的定义可能离使用它的地方很远。
- 这三种方法的相对效率取决于编译器内联那些东西。函数指针方法拒绝了内联,因为编译器传统上不会内联其地址被获取的函数,因为函数地址的概念意味着非内联函数。而函数对象和lambda通常不会阻止内联。
- lambda可访问作用域内的任何动态变量。