分库分表-ShardingSphere 4.x(1)
❤️作者简介:2022新星计划第三季云原生与云计算赛道Top5、华为云享专家、云原生领域潜力新星
博客首页:C站个人主页
作者目的:如有错误请指正,将来会不断的完善笔记,帮助更多的Java爱好者入门,共同进步!
文章目录
- 分库分表-ShardingSphere 4.x(1)
-
- ShardingSphere概述
- Sharding-JDBC实战教程(上)
-
- Sharding-JDBC分库分表(⭐)
-
- 必备环境(数据库和SpringBoot项目⭐)
-
- 数据库(orderdb1和orderdb2),内容都为如下
- Pom.xml
- OrderMapper.class(mapper接口)
- Order.class(实体类)
- ShardingSphereApplication(SpringBoot启动类)
- 实战1:使用shardingsphere代理JDBC数据源操作数据库(不分库、不分表)
-
- application.properties
- junit测试类
-
- 测试1:插入10条记录
- 测试2:查询所有数据
- 实战2:使用shardingsphere操作数据库(inline策略分表、但是不分库)⭐
-
- application.properties
- junit测试类
-
- 测试1:插入10条记录
- 测试2:查询所有数据
- 测试3:查询指定order_id的数据
- 实战3:使用shardingsphere操作数据库(inline策略分表、inline策略分库)⭐
-
- application.properties
- junit测试类
-
- 测试1:插入10条记录
- 测试2:查询所有数据
- 测试3:查询指定order_id的数据
- inline策略的缺点(不能使用between,否则会报错⭐)
- 实战4:使用shardingsphere操作数据库(standard策略分表、standard策略分库)⭐
-
- 自定义分片策略类(standard策略)
-
- MyStandardRangeTableAlgorithm类(自定义分表的standard策略的范围分片类)
- MyStandardPreciseTableAlgorithm类(自定义分表的standard策略的精准分片类)
- MyStandardRangeDataBaseAlgorithm类(自定义分数据库的standard策略的范围分片类)
- MyStandardPreciseDataBaseAlgorithm类(自定义分数据库的standard策略的精准分片类)
- application.properties
- junit测试类
-
- 测试1:插入10条记录
- 测试2:查询指定order_id的数据
- 测试3:使用between范围查询,测试inline和standard的区别(inline策略会报错,但是standard策略不会)⭐
- 实战5:使用shardingsphere操作数据库(complex策略分表、complex策略分库)⭐
-
- 自定义分片策略类(complex策略)
-
- MyComplexTableAlgorithm类(自定义分表的complex策略的分片类)
- MyComplexDataBaseAlgorithm类(自定义分数据库的complex策略的分片类)
- application.properties
- junit测试类
-
- 测试1:查询指定order_id和user_id的数据(并且order_id和user_id同时都是分片键)⭐
- 实战6:使用shardingsphere操作数据库(hint策略分表、hint策略分库)⭐
-
- 自定义分片策略类(Hint策略)
-
- MyHintTableAlgorithm(自定义分表的Hint策略的分片类)
- MyHintDataBaseAlgorithm(自定义分数据库的Hint策略的分片类)
- application.properties
- junit测试类
-
- 测试1:根据hint策略进行强制分库分表插入数据到ds1的order_2表⭐
- 测试2:利用Hint策略查询ds1的order_2表⭐
分库分表-ShardingSphere 4.x(1)
项目所在仓库
ShardingSphere概述
Apache ShardingSphere 是一款开源的分布式数据库生态项目,由 JDBC 和 Proxy 两款产品组成。 其核心采用可插拔架构,通过组件扩展功能。 对上以数据库协议及 SQL 方式提供诸多增强功能,包括数据分片、访问路由、数据安全等;对下原生支持 MySQL、PostgreSQL、SQL Server、Oracle 等多种数据存储引擎。 Apache ShardingSphere 项目理念,是提供数据库增强计算服务平台,进而围绕其上构建生态。 充分利用现有数据库的计算与存储能力,通过插件化方式增强其核心能力,为企业解决在数字化转型中面临的诸多使用难点,为加速数字化应用赋能。
Sharding-JDBC实战教程(上)
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache ShardingSphere 的前身。 它定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
ShardingSphere-JDBC 的优势在于极致性能和对 Java 应用的友好度。
Sharding-JDBC分库分表(⭐)
必备环境(数据库和SpringBoot项目⭐)
数据库(orderdb1和orderdb2),内容都为如下
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
DROP TABLE IF EXISTS `order`;
CREATE TABLE `order` (
`order_id` bigint(20) NOT NULL,
`order_info` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
DROP TABLE IF EXISTS `order_1`;
CREATE TABLE `order_1` (
`order_id` bigint(20) NOT NULL,
`order_info` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
DROP TABLE IF EXISTS `order_2`;
CREATE TABLE `order_2` (
`order_id` bigint(20) NOT NULL,
`order_info` varchar(255) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`user_id` bigint(20) NOT NULL,
PRIMARY KEY (`order_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = DYNAMIC;
DROP TABLE IF EXISTS `t_config`;
CREATE TABLE `t_config` (
`config_id` bigint(20) NOT NULL,
`config_info` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
PRIMARY KEY (`config_id`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
SET FOREIGN_KEY_CHECKS = 1;
Pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>ShardingSphere-DemoartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<spring-boot.version>2.5.9spring-boot.version>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-dependenciesartifactId>
<version>${spring-boot.version}version>
<type>pomtype>
<scope>importscope>
dependency>
dependencies>
dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-webartifactId>
dependency>
<dependency>
<groupId>mysqlgroupId>
<artifactId>mysql-connector-javaartifactId>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-jdbcartifactId>
dependency>
<dependency>
<groupId>com.baomidougroupId>
<artifactId>mybatis-plus-boot-starterartifactId>
<version>3.5.1version>
dependency>
<dependency>
<groupId>com.alibabagroupId>
<artifactId>druidartifactId>
<version>1.2.6version>
dependency>
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>sharding-jdbc-spring-boot-starterartifactId>
<version>4.1.1version>
dependency>
<dependency>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-starter-testartifactId>
<scope>testscope>
dependency>
<dependency>
<groupId>org.projectlombokgroupId>
<artifactId>lombokartifactId>
<version>1.18.12version>
dependency>
dependencies>
<build>
<finalName>ShardingSpherefinalName>
<plugins>
<plugin>
<groupId>org.springframework.bootgroupId>
<artifactId>spring-boot-maven-pluginartifactId>
<executions>
<execution>
<phase>packagephase>
<goals>
<goal>repackagegoal>
goals>
execution>
executions>
<version>${spring-boot.version}version>
<configuration>
<includeSystemScope>trueincludeSystemScope>
<mainClass>com.boot.ShardingSphereApplicationmainClass>
configuration>
plugin>
plugins>
build>
project>
OrderMapper.class(mapper接口)
package com.boot.dao;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.boot.entity.Order;
import org.apache.ibatis.annotations.Mapper;
import org.springframework.stereotype.Repository;
@Mapper
@Repository
public interface OrderMapper extends BaseMapper<Order> {
}
Order.class(实体类)
package com.boot.entity;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import java.io.Serializable;
/**
* TODO: 2022/8/2
* @author youzhengjie
*/
//lombok注解简化开发
@Data
@AllArgsConstructor
@NoArgsConstructor
@Accessors(chain = true) //开启链式编程
//由于mybatis-plus是在mybatis的基础上建立的,所以也有下面的通病(就是order本身就是关键字,无法被解析,所以需要加上``符号)。
//如果不加上@TableName指定表名,默认的表名就是该类的名称。
@TableName("`order`")
public class Order implements Serializable {
@TableField("order_id")
private Long orderId; //订单id
@TableField("order_info")
private String orderInfo; //订单信息
@TableField("user_id")
private Long userId; //用户id
}
ShardingSphereApplication(SpringBoot启动类)
package com.boot;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ShardingSphereApplication {
public static void main(String[] args) {
SpringApplication.run(ShardingSphereApplication.class,args);
}
}
实战1:使用shardingsphere代理JDBC数据源操作数据库(不分库、不分表)
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1
#配置ds1的数据源(可以配置多个)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
junit测试类
测试1:插入10条记录
@Test
void addOrder(){
for (int i = 0; i < 10; i++) {
Order order = new Order();
order.setOrderId(Long.parseLong(""+(i+1)))
.setOrderInfo("订单信息"+(i+1))
.setUserId(Long.parseLong(""+(1001+i)));
System.out.println(order);
orderMapper.insert(order);
}
}
- 查看数据库:

测试2:查询所有数据
@Test
void selectOrderList(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
实战2:使用shardingsphere操作数据库(inline策略分表、但是不分库)⭐
效果是:插入的数据如果order_id是奇数则会分到order_2表,偶数会分到order_1表(数据所在的数据库都为orderdb1,因为我们暂时没有分库)
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1
#配置ds1的数据源(可以配置多个)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
# 真实数据节点配置,采用Groovy表达式(这里就代表我们可以操作的节点有ds1.order_1和ds1.order_2两个表)
spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds1.order_$->{1..2}
# 主键id生成策略。
# 指定主键列,shardingsphere会为这个主键列自动生成id
spring.shardingsphere.sharding.tables.order.key-generator.column=order_id
# 生成主键的算法(推荐使用雪花算法)
spring.shardingsphere.sharding.tables.order.key-generator.type=snowflake
# 开始正式的使用inline策略进行分表(缺点是这个策略会对mysql的BETWEEN AND、>、 <、 >=、 <= 操作失效!)-----分表。
# 指定一个分片键(这里指定指定一个)
spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column=order_id
# 分片算法(表达式)
spring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression=order_$->{order_id % 2 + 1}
#开启ShardingSphere的SQL输出日志
spring.shardingsphere.props.sql.show=true
# 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 order_id ---> orderId
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 这个配置一定要加(注意)
spring.main.allow-bean-definition-overriding= true
junit测试类
测试1:插入10条记录
//根据inline策略进行分表,但是不分库
@Test
void addOrderByinlineShardingTable(){
for (int i = 0; i < 10; i++) {
Order order = new Order();
//orderid不需要自己手动插入了!
order.setOrderInfo("订单信息"+(i+1))
.setUserId(Long.parseLong(""+(1001+i)));
orderMapper.insert(order);
}
}
- 查看输出日志:

- 查看数据库:

测试2:查询所有数据
//查询全部数据
@Test
void selectAllByinlineShardingTable(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
- 查看输出日志:

测试3:查询指定order_id的数据
//查询指定order_id的数据
@Test
void selectOrderByinlineShardingTable_orderid(){
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.eq("order_id",762459329767931905L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
- 输出日志:

实战3:使用shardingsphere操作数据库(inline策略分表、inline策略分库)⭐
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1,ds2
#配置ds1的数据源(对应orderdb1数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
#配置ds2的数据源(对应orderdb2数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/orderdb2?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=18420163207
# 真实数据节点配置,采用Groovy表达式(这里就代表我们可以操作的节点有ds1.order_1和ds1.order_2和ds2.order_1和ds2.order_2四张表)
spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds$->{1..2}.order_$->{1..2}
# 主键id生成策略。
# 指定主键列,shardingsphere会为这个主键列自动生成id
spring.shardingsphere.sharding.tables.order.key-generator.column=order_id
# 生成主键的算法(推荐使用雪花算法)
spring.shardingsphere.sharding.tables.order.key-generator.type=snowflake
# 开始正式的使用inline策略进行分表(缺点是这个策略会对mysql的BETWEEN AND、>、 <、 >=、 <= 操作失效!)-----分表。
# 指定一个分片键(这里指定指定一个)
spring.shardingsphere.sharding.tables.order.table-strategy.inline.sharding-column=order_id
# 表的分片算法(表达式),下面这种算法会操作表的浪费,只有ds1.order_1和ds2.order_2才被使用,其他都被浪费
spring.shardingsphere.sharding.tables.order.table-strategy.inline.algorithm-expression=order_$->{order_id % 2 + 1}
# 开始正式的使用inline策略进行分库(缺点是这个策略会对mysql的BETWEEN AND、>、 <、 >=、 <= 操作失效!)------分库。
# 指定一个分片键(这里指定指定一个)
spring.shardingsphere.sharding.tables.order.database-strategy.inline.sharding-column=order_id
# 数据库的分片算法(表达式)
spring.shardingsphere.sharding.tables.order.database-strategy.inline.algorithm-expression=ds$->{order_id % 2 + 1}
#开启ShardingSphere的SQL输出日志
spring.shardingsphere.props.sql.show=true
# 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 order_id ---> orderId
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 这个配置一定要加(注意)
spring.main.allow-bean-definition-overriding= true
junit测试类
测试1:插入10条记录
//根据inline策略进行分库和分表
@Test
void addOrderByinlineShardingTableAndDatabase(){
for (int i = 0; i < 10; i++) {
Order order = new Order();
order.setOrderInfo("订单信息"+(i+1))
.setUserId(Long.parseLong(""+(1001+i)));
orderMapper.insert(order);
}
}
- 输出日志:

- 查看数据库:

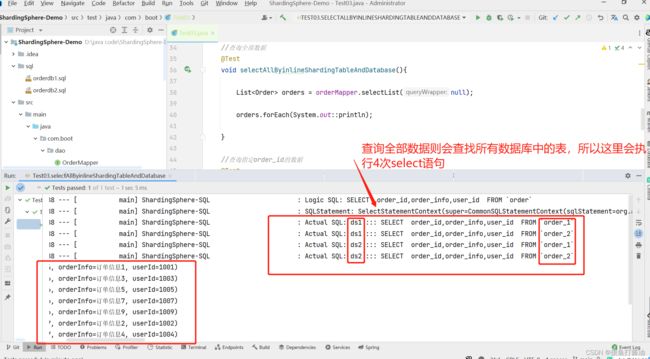
测试2:查询所有数据
//查询全部数据
@Test
void selectAllByinlineShardingTableAndDatabase(){
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
}
- 输出日志:
测试3:查询指定order_id的数据
//查询指定order_id的数据
@Test
void selectOrderByinlineShardingTableAndDatabase_orderid(){
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.eq("order_id",762681526788816896L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
- 输出日志:

inline策略的缺点(不能使用between,否则会报错⭐)
//查询order_id在一个范围的数据
@Test
void selectOrderByinlineShardingTableAndDatabase_between(){
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.between("order_id",762681526704930816L,862681526830759936L);
//lt是小于、gt是大于,这些inline策略都是不支持的
// objectQueryWrapper.lt("order_id",762681526704930816L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
- 这里我们使用了between,由于between是范围查询,而inline策略是不支持这种查询的,所以会报错。
- 解决方法:就是使用其他分片策略,比如下面的standard/complex/Hint这些。(这些策略提供了精确分片和范围分片)

实战4:使用shardingsphere操作数据库(standard策略分表、standard策略分库)⭐
自定义分片策略类(standard策略)
MyStandardRangeTableAlgorithm类(自定义分表的standard策略的范围分片类)
package com.boot.algorithm.standard.range;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* 该类适用于BETWEEN AND、>、 <、 >=、 <= 操作
*/
//1:MyStandardRangeTableAlgorithm:自定义分表的standard策略的范围分片类
//2:RangeShardingAlgorithm接口的泛型是分片键的类型(我们的分片键是order_id它是Long类型的所以就是Long)
public class MyStandardRangeTableAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 由于是范围分片,所以返回的是一个集合(集合里面的值是表名)
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
//例如sql:select * from order where order_id between 200 and 300
String logicTableName = rangeShardingValue.getLogicTableName(); //逻辑表名:也就是order
String columnName = rangeShardingValue.getColumnName(); //分片键:也就是order_id
Long lowerEndpoint = rangeShardingValue.getValueRange().lowerEndpoint(); //between的最小值:在上面的sql就是200
Long upperEndpoint = rangeShardingValue.getValueRange().upperEndpoint(); //between的最大是:在上面的sql就是300
List<String> tables = new ArrayList<>(); //需要sharding-jdbc查询的表
//由于这里是range范围查询,所以要查询全部表,所以要把所有表名添加到集合中
tables.add(logicTableName+"_1"); //表名:order_1
tables.add(logicTableName+"_2"); //表名:order_2
return tables;
}
}
MyStandardPreciseTableAlgorithm类(自定义分表的standard策略的精准分片类)
package com.boot.algorithm.standard.precise;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
/**
* 该类适用于=、in操作
*/
//1:MyStandardPreciseTableAlgorithm:自定义分表的standard策略的精准分片类
//2:PreciseShardingAlgorithm接口的泛型是分片键的类型(我们的分片键是order_id它是Long类型的所以就是Long)
public class MyStandardPreciseTableAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* 由于是精准分片,所以返回的是一个字符串(字符串就是指定的表名)
* @param collection 真实表名集合。order_1和order_2
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//例如sql:select * from order where order_id=201
String logicTableName = preciseShardingValue.getLogicTableName(); //逻辑表名。也就是order
String columnName = preciseShardingValue.getColumnName(); //分片键名。也就是order_id
Long columnvalue = preciseShardingValue.getValue(); //分片键的值。比如上面的sql,那么这个value就是201
//实现order_$->{order_id % 2 + 1} 分片算法
BigInteger bigInteger = BigInteger.valueOf(columnvalue);
BigInteger tableNumber = bigInteger.mod(new BigInteger("2")).add(new BigInteger("1"));
//最终需要查询的表名
String tableName=logicTableName+"_"+tableNumber; //如果tableNumber是1,那么tableName就是order_1
//判断我们计算出来的表名是否存在
if(collection.contains(tableName)){
return tableName; //返回指定的表名
}
throw new UnsupportedOperationException("MyStandardPreciseTableAlgorithm没有找到指定的表名");
}
}
MyStandardRangeDataBaseAlgorithm类(自定义分数据库的standard策略的范围分片类)
package com.boot.algorithm.standard.range;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.RangeShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
/**
* 该类适用于BETWEEN AND、>、 <、 >=、 <= 操作
*/
// MyStandardRangeDataBaseAlgorithm:自定义分数据库的standard策略的范围分片类
public class MyStandardRangeDataBaseAlgorithm implements RangeShardingAlgorithm<Long> {
/**
* 由于是范围分片,所以返回的是一个集合(集合里面的值是数据源名)
*/
@Override
public Collection<String> doSharding(Collection<String> collection, RangeShardingValue<Long> rangeShardingValue) {
List<String> dataSources = new ArrayList<>(); //数据源名称集合
//由于这里是范围查询,所以全部数据源都要查询,故把所有数据源名称添加进去
dataSources.add("ds1");
dataSources.add("ds2");
return dataSources;
}
}
MyStandardPreciseDataBaseAlgorithm类(自定义分数据库的standard策略的精准分片类)
package com.boot.algorithm.standard.precise;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import java.math.BigInteger;
import java.util.Collection;
/**
* 该类适用于=、in操作
*/
// MyStandardPreciseDataBaseAlgorithm:自定义分数据库的standard策略的精准分片类
public class MyStandardPreciseDataBaseAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
*
* collection存储了所有表名。ds1和ds2
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//实现ds$->{order_id % 2 + 1}算法
Long value = preciseShardingValue.getValue();//拿到分片键的值。也就是order_id的值
BigInteger bigInteger = BigInteger.valueOf(value);
BigInteger dataSourceNumber = bigInteger.mod(new BigInteger("2")).add(new BigInteger("1"));
//最终查询的数据源名称
String dataSourceName="ds"+dataSourceNumber; //ds1或者ds2
if (collection.contains(dataSourceName)) { //判断dataSourceName是否真实存在
return dataSourceName;
}
throw new UnsupportedOperationException("MyStandardPreciseDataBaseAlgorithm没有找到指定数据源名称");
}
}
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1,ds2
#配置ds1的数据源(对应orderdb1数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
#配置ds2的数据源(对应orderdb2数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/orderdb2?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=18420163207
# 真实数据节点配置,采用Groovy表达式(这里就代表我们可以操作的节点有ds1.order_1和ds1.order_2和ds2.order_1和ds2.order_2四张表)
spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds$->{1..2}.order_$->{1..2}
# 主键id生成策略。
# 指定主键列,shardingsphere会为这个主键列自动生成id
spring.shardingsphere.sharding.tables.order.key-generator.column=order_id
# 生成主键的算法(推荐使用雪花算法)
spring.shardingsphere.sharding.tables.order.key-generator.type=snowflake
# 开始正式的使用standard策略进行分表-----分表。
# 指定一个分片键(这里指定指定一个)
spring.shardingsphere.sharding.tables.order.table-strategy.standard.sharding-column=order_id
# 指定范围分片的自定义类的全类名 (比如BETWEEN AND、>、 <、 >=、 <= 操作就是范围分片)
spring.shardingsphere.sharding.tables.order.table-strategy.standard.range-algorithm-class-name=com.boot.algorithm.standard.range.MyStandardRangeTableAlgorithm
# 指定精准分片的自定义类的全类名 (比如=、in就是精准分片)
spring.shardingsphere.sharding.tables.order.table-strategy.standard.precise-algorithm-class-name=com.boot.algorithm.standard.precise.MyStandardPreciseTableAlgorithm
# 开始正式的使用standard策略进行分库------分库。
# 指定一个分片键(这里指定指定一个)
spring.shardingsphere.sharding.tables.order.database-strategy.standard.sharding-column=order_id
# 指定范围分片的自定义类的全类名 (比如BETWEEN AND、>、 <、 >=、 <= 操作就是范围分片)
spring.shardingsphere.sharding.tables.order.database-strategy.standard.range-algorithm-class-name=com.boot.algorithm.standard.range.MyStandardRangeDataBaseAlgorithm
# 指定精准分片的自定义类的全类名 (比如=、in就是精准分片)
spring.shardingsphere.sharding.tables.order.database-strategy.standard.precise-algorithm-class-name=com.boot.algorithm.standard.precise.MyStandardPreciseDataBaseAlgorithm
#开启ShardingSphere的SQL输出日志
spring.shardingsphere.props.sql.show=true
# 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 order_id ---> orderId
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 这个配置一定要加(注意)
spring.main.allow-bean-definition-overriding= true
junit测试类
测试1:插入10条记录
//根据standard策略进行分库和分表
@Test
void addOrderBystandardShardingTableAndDatabase(){
for (int i = 0; i < 10; i++) {
Order order = new Order();
order.setOrderInfo("订单信息"+(i+1))
.setUserId(Long.parseLong(""+(1001+i)));
orderMapper.insert(order);
}
}
测试2:查询指定order_id的数据
//查询指定order_id的数据
@Test
void selectOrderBystandardShardingTableAndDatabase_orderid(){
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.eq("order_id",763033347873046528L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
测试3:使用between范围查询,测试inline和standard的区别(inline策略会报错,但是standard策略不会)⭐
//查询order_id在一个范围的数据(inline策略会报错)
@Test
void selectOrderByStandardShardingTableAndDatabase_between(){
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.between("order_id",762681526704930816L,862681526830759936L);
//lt是小于、gt是大于,这些inline策略都是不支持的
// objectQueryWrapper.lt("order_id",762681526704930816L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
- 测试结果:(standard策略不会报错。)

实战5:使用shardingsphere操作数据库(complex策略分表、complex策略分库)⭐
自定义分片策略类(complex策略)
MyComplexTableAlgorithm类(自定义分表的complex策略的分片类)
package com.boot.algorithm.complex;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.math.BigInteger;
import java.util.*;
public class MyComplexTableAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
//collection存储了所有表名
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
//select * from order where order_id between 663033347873046528L and 763033347873046528L and user_id=1003
String logicTableName = complexKeysShardingValue.getLogicTableName(); //逻辑表名
//getColumnNameAndRangeValuesMap方法:获取范围(between、>、<)的分片键。(相当于standard策略的范围分片类)
Range<Long> orderIdRange = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("order_id");
//如果我们的sql没有写between and或者其他范围相关的操作符,则orderIdRange就会空,调用下面的Endpoint方法就会NullPointerException。
//所以一定要进行如下判断
if(orderIdRange!=null&&orderIdRange.isEmpty()){
Long lowerEndpoint = orderIdRange.lowerEndpoint(); //663033347873046528L
Long upperEndpoint = orderIdRange.upperEndpoint(); //763033347873046528L
}
//getColumnNameAndShardingValuesMap方法:获取精准(=、in)的分片键。(相当于standard策略的精准分片类)
Collection<Long> userIdCol = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_id");
//如果我们的sql没有写=或者in,则userIdCol就会空,那么下面遍历这个集合就会NullPointerException
//所以一定要进行如下判断.
//如果userIdCol不为null,则遍历这个集合,实现order_$->{order_id % 2 + 1}算法
if (userIdCol!=null&&!userIdCol.isEmpty()) {
//最终查询的表名集合,因为=和in可能有多个值。
List<String> tables = new ArrayList<>();
//这里虽然是集合,但是我们很多情况下可以把它想成只有一个元素。
for (Long value : userIdCol) {
BigInteger bigInteger = BigInteger.valueOf(value);
BigInteger tableNumber = bigInteger.mod(new BigInteger("2")).add(new BigInteger("1"));
String tableName=logicTableName+"_"+tableNumber;
if(collection.contains(tableName)){
tables.add(tableName); //添加到集合中
}else {
throw new UnsupportedOperationException("MyComplexTableAlgorithm没有该表名");
}
}
System.out.println(tables);
return tables;
}else { //如果userIdCol集合为null,那么就相当于范围查询,则查询全部表
return collection; //collection里面有全部表名
}
}
}
MyComplexDataBaseAlgorithm类(自定义分数据库的complex策略的分片类)
package com.boot.algorithm.complex;
import com.google.common.collect.Range;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.complex.ComplexKeysShardingValue;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
public class MyComplexDataBaseAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
//collection存储了全部数据源名称
@Override
public Collection<String> doSharding(Collection<String> collection, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
//getColumnNameAndRangeValuesMap方法:获取范围(between、>、<)的分片键。(相当于standard策略的范围分片类)
Range<Long> orderIdRange = complexKeysShardingValue.getColumnNameAndRangeValuesMap().get("order_id");
//如果我们的sql没有写between and或者其他范围相关的操作符,则orderIdRange就会空,调用下面的Endpoint方法就会NullPointerException。
//所以一定要进行如下判断
if(orderIdRange!=null&&orderIdRange.isEmpty()){
Long lowerEndpoint = orderIdRange.lowerEndpoint(); //663033347873046528L
Long upperEndpoint = orderIdRange.upperEndpoint(); //763033347873046528L
}
//getColumnNameAndShardingValuesMap方法:获取精准(=、in)的分片键。(相当于standard策略的精准分片类)
Collection<Long> userIdCol = complexKeysShardingValue.getColumnNameAndShardingValuesMap().get("user_id");
//如果我们的sql没有写=或者in,则userIdCol就会空,那么下面遍历这个集合就会NullPointerException
//所以一定要进行如下判断。
//如果userIdCol不为null,则遍历这个集合,实现ds$->{order_id % 2 + 1}算法。
if (userIdCol!=null&&!userIdCol.isEmpty()) {
//最终查询的表名集合,因为=和in可能有多个值。
List<String> datasouces = new ArrayList<>();
//这里虽然是集合,但是我们很多情况下可以把它想成只有一个元素。
for (Long value : userIdCol) {
BigInteger bigInteger = BigInteger.valueOf(value);
BigInteger dataSourceNumber = bigInteger.mod(new BigInteger("2")).add(new BigInteger("1"));
String dataSourceName="ds"+dataSourceNumber;
if(collection.contains(dataSourceName)){
datasouces.add(dataSourceName); //添加到集合中
}else {
throw new UnsupportedOperationException("MyComplexDataBaseAlgorithm没有该数据源名");
}
}
return datasouces;
}else { //如果userIdCol集合为null,那么就相当于范围查询,则查询全部数据源
return collection; //collection里面有全部数据源名称
}
}
}
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1,ds2
#配置ds1的数据源(对应orderdb1数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
#配置ds2的数据源(对应orderdb2数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/orderdb2?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=18420163207
# 真实数据节点配置,采用Groovy表达式(这里就代表我们可以操作的节点有ds1.order_1和ds1.order_2和ds2.order_1和ds2.order_2四张表)
spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds$->{1..2}.order_$->{1..2}
# 主键id生成策略。
# 指定主键列,shardingsphere会为这个主键列自动生成id
spring.shardingsphere.sharding.tables.order.key-generator.column=order_id
# 生成主键的算法(推荐使用雪花算法)
spring.shardingsphere.sharding.tables.order.key-generator.type=snowflake
# 开始正式的使用complex策略进行分表-----分表。
# 指定一个或多个分片键(这里的分片键指定为order_id和user_id)
spring.shardingsphere.sharding.tables.order.table-strategy.complex.sharding-columns=order_id,user_id
# 指定complex分片的自定义类的全类名
spring.shardingsphere.sharding.tables.order.table-strategy.complex.algorithm-class-name=com.boot.algorithm.complex.MyComplexTableAlgorithm
# 开始正式的使用complex策略进行分库------分库。
# 指定一个或多个分片键(这里的分片键指定为order_id和user_id)
spring.shardingsphere.sharding.tables.order.database-strategy.complex.sharding-columns=order_id,user_id
# 指定complex分片的自定义类的全类名
spring.shardingsphere.sharding.tables.order.database-strategy.complex.algorithm-class-name=com.boot.algorithm.complex.MyComplexDataBaseAlgorithm
#开启ShardingSphere的SQL输出日志
spring.shardingsphere.props.sql.show=true
# 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 order_id ---> orderId
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 这个配置一定要加(注意)
spring.main.allow-bean-definition-overriding= true
junit测试类
测试1:查询指定order_id和user_id的数据(并且order_id和user_id同时都是分片键)⭐
//查询指定order_id和user_id的数据(并且order_id和user_id同时都是分片键)
@Test
void selectOrderBystandardShardingTableAndDatabase_orderidAndUserid(){
//select * from order where order_id between 663033347873046528L and 763033347873046528L and user_id=1003
QueryWrapper<Order> objectQueryWrapper = new QueryWrapper<>();
objectQueryWrapper.between("order_id",663033347873046528L,763033347873046528L);
objectQueryWrapper.eq("user_id",1003L);
List<Order> orders = orderMapper.selectList(objectQueryWrapper);
orders.forEach(System.out::println);
}
实战6:使用shardingsphere操作数据库(hint策略分表、hint策略分库)⭐
自定义分片策略类(Hint策略)
MyHintTableAlgorithm(自定义分表的Hint策略的分片类)
package com.boot.algorithm.hint;
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
//HintShardingAlgorithm的泛型就是addTableShardingValue方法的value的类型(我们通常使用Integer)
public class MyHintTableAlgorithm implements HintShardingAlgorithm<Integer> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Integer> hintShardingValue) {
List<String> tables = new ArrayList<>();
String tableName="order_"+hintShardingValue.getValues().toArray()[0];
if(collection.contains(tableName)){
tables.add(tableName);
return tables;
}
throw new UnsupportedOperationException("MyHintTableAlgorithm没有找到表名");
}
}
MyHintDataBaseAlgorithm(自定义分数据库的Hint策略的分片类)
package com.boot.algorithm.hint;
import org.apache.shardingsphere.api.sharding.hint.HintShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.hint.HintShardingValue;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
//HintShardingAlgorithm的泛型就是addDatabaseShardingValue方法的value的类型(我们通常使用Integer)
public class MyHintDataBaseAlgorithm implements HintShardingAlgorithm<Long> {
@Override
public Collection<String> doSharding(Collection<String> collection, HintShardingValue<Long> hintShardingValue) {
List<String> datasources = new ArrayList<>();
String dataSourceName="ds"+hintShardingValue.getValues().toArray()[0];
if(collection.contains(dataSourceName)){
datasources.add(dataSourceName);
return datasources;
}
throw new UnsupportedOperationException("MyHintDataBaseAlgorithm没有找到数据源名");
}
}
application.properties
#配置ShardingSphere数据源,定义一个或多个数据源名称
spring.shardingsphere.datasource.names=ds1,ds2
#配置ds1的数据源(对应orderdb1数据库)
spring.shardingsphere.datasource.ds1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds1.url=jdbc:mysql://localhost:3306/orderdb1?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds1.username=root
spring.shardingsphere.datasource.ds1.password=18420163207
#配置ds2的数据源(对应orderdb2数据库)
spring.shardingsphere.datasource.ds2.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds2.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.ds2.url=jdbc:mysql://localhost:3306/orderdb2?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
spring.shardingsphere.datasource.ds2.username=root
spring.shardingsphere.datasource.ds2.password=18420163207
# 真实数据节点配置,采用Groovy表达式(这里就代表我们可以操作的节点有ds1.order_1和ds1.order_2和ds2.order_1和ds2.order_2四张表)
spring.shardingsphere.sharding.tables.order.actual-data-nodes=ds$->{1..2}.order_$->{1..2}
# 主键id生成策略。
# 指定主键列,shardingsphere会为这个主键列自动生成id
spring.shardingsphere.sharding.tables.order.key-generator.column=order_id
# 生成主键的算法(推荐使用雪花算法)
spring.shardingsphere.sharding.tables.order.key-generator.type=snowflake
# 开始正式的使用hint策略进行分表-----分表。
# 指定hint分片的自定义类的全类名
spring.shardingsphere.sharding.tables.order.table-strategy.hint.algorithm-class-name=com.boot.algorithm.hint.MyHintTableAlgorithm
# 开始正式的使用hint策略进行分库------分库。
# 指定hint分片的自定义类的全类名
spring.shardingsphere.sharding.tables.order.database-strategy.hint.algorithm-class-name=com.boot.algorithm.hint.MyHintDataBaseAlgorithm
#开启ShardingSphere的SQL输出日志
spring.shardingsphere.props.sql.show=true
# 在映射实体或者属性时,将数据库中表名和字段名中的下划线去掉,按照驼峰命名法映射 order_id ---> orderId
mybatis-plus.configuration.map-underscore-to-camel-case=true
# 这个配置一定要加(注意)
spring.main.allow-bean-definition-overriding= true
junit测试类
测试1:根据hint策略进行强制分库分表插入数据到ds1的order_2表⭐
@Test
void addOrderByHintShardingTableAndDataBase(){
HintManager hintManager = HintManager.getInstance();
//实现指定操作ds1的order_2表
hintManager.addDatabaseShardingValue("order",1);//添加分库的值为1
hintManager.addTableShardingValue("order",2); //添加分表的值为2
for (int i = 0; i < 10; i++) {
Order order = new Order();
//orderid不需要自己手动插入了!
order.setOrderInfo("订单信息"+(i+1))
.setUserId(Long.parseLong(""+(1001+i)));
orderMapper.insert(order);
}
hintManager.close(); //用完之后要调用close方法。
}
- 查询数据库

测试2:利用Hint策略查询ds1的order_2表⭐
@Test
void selectAllByHintShardingTableAndDataBase(){
HintManager hintManager = HintManager.getInstance();
//实现指定操作ds1的order_2表
hintManager.addDatabaseShardingValue("order",1);//添加分库的值为1
hintManager.addTableShardingValue("order",2); //添加分表的值为2
List<Order> orders = orderMapper.selectList(null);
orders.forEach(System.out::println);
hintManager.close(); //用完之后要调用close方法。
}
- 输出日志:
