学习并了解MQ消息队列
消息队列
消息队列是什么
服务端⾸先需要考虑的是它的稳定性这⼀层,但是在⾼并发的情况下,对服务端的稳定性造成很⼤的破坏性,那么就需要⼀个缓冲的机制,⽽消息队列在异步通信的模式下,使⽤异步处理请求来缓解系统的压⼒。
消息队列概述
从通信的思路来说,主要可以分为同步通信和异步通信,⽽异步通信主要是通过MQ的消息中间件来实现应⽤程序之间的通信。消息队列这⾥⾯的⼀部分,主要体现在如下的⼏个维度。
发布与订阅系统
发布与订阅系统的特点是:数据发送者不会直接把数据发送给接收者。
它的形式是发布者会以某种形式对消息进⾏分类,接收者订阅他们,以便接收特定类型的消息。
发布与订阅系统⼀般会有⼀个broker,这个broker可以理解为发布消息的中⼼点。
异步处理
如果⼀个系统注册账户,同时需要对邮件和⼿机号码发送验证码,但是如果同时进⾏发送的话,对服务端的压⼒还是很⼤的,那么这个时候进⾏优化,体交互流程如下:
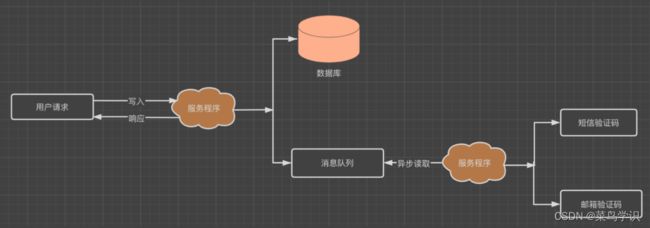
消息通信
消息队列具备的另外⼀个特性是⾼效的通信机制。⽐如如下的交互模式:

数据限流
在⼤促销的时候,⽐如秒杀的业务场景下,客户端⾼并发的请求到服务端,⼀瞬间服务端需要承受巨⼤的压⼒,这样导致应⽤程序的服务端⽆法处理请求⽽导致崩溃。那么如果有了消息队列,我们可以先把客户端⾼并发的请求放到消息队列,然后服务端这层根据服务端的处理能⼒从消息队列⾥⾯读取数据,具体如下:
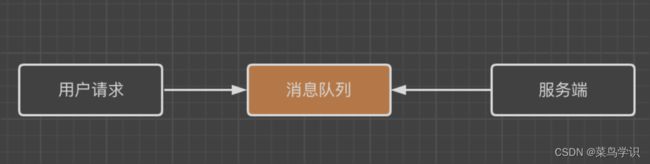
MQ
ActiveMQ
开源的,以及⽬前最流⾏的开源消息总线,并且完全⽀持JMS规范的消息中间件。它具有⾮常丰富的API,多集群构建模式。⼀般⽽⾔,我们对MQ的衡量标准主要依据是是:服务性能,数据存储,集群架构
集群模式
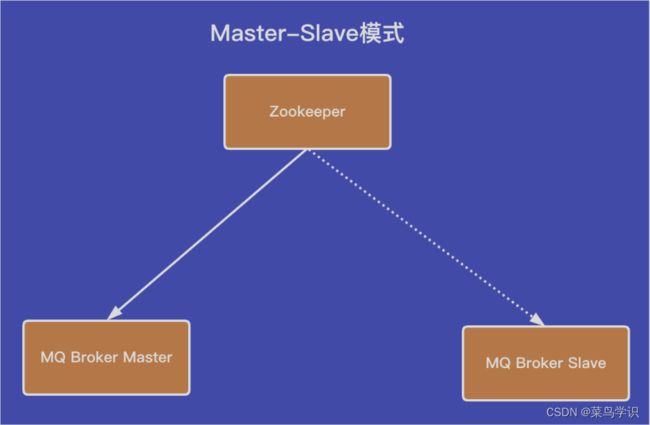
如上架构的图形中,master节点是⼯作模式,slave是⾮⼯作模式,除⾮是master节点出现问题的时候,使⽤zookeeper的⾼可⽤来切换到slave的节点模式。
网络模式
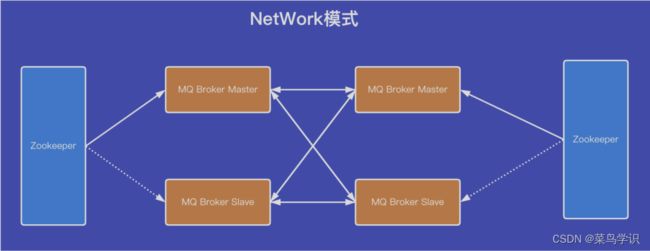
network模式可以理解为:两组主备模式的集成,中间使⽤⽹关配置的模式,就可以形成分布式的集群了。
Kafka
基于pull的模式来处理消息消费,追求⾼吞吐量,最初主要是应⽤于⽇志收集和传输。不⽀持事务,对消息的重复,丢失,错误没有严格要求,适合⼤数据服务的数据收集业务,主要也是应⽤于⼤数据的核⼼组件中。
Kafka集群模式
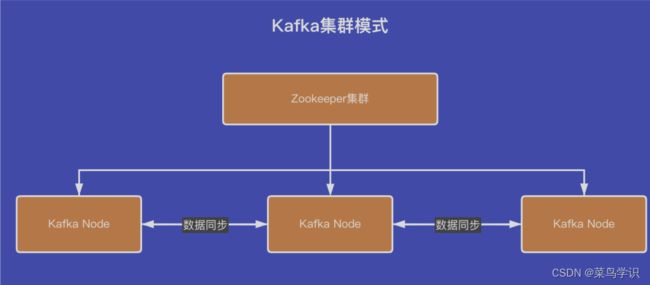
节点与节点之间进⾏副本的同步,也可以把这个过程理解为数据的同步过程。
RabbitMQ
基于AMQP协议来实现,AMQP协议可以理解为:⾯向消息,队列,路由(发布/订阅模式),可靠性,安全。AMQP的协议主要更多的应⽤于企业的内部,对数据⼀致性,稳定性和可靠性要求很⾼的场景,对性能和吞吐量要求还在其次。
Kafka实战
Kafka的由来
kafka⽬前成为处理流式数据的利器,它最初是LinkedIn内部的⼀个基础设施系统,基于实时流它的数据形式是持续变化和不断增⻓的流,Kafka后续逐步的应⽤于社交⽹络的实时应⽤和数据流,⽬前Kafka是下⼀代数据架构的基础。所以对Kafka,可以把它理解为⼀个流平台,在这个流平台上可以发布和订阅数据流,并且把它保存起来,进⾏数据的处理。
Kafka安装&配置
zookeeper安装
zooKeeper是维护配置信息、命名、提供分布式同步和提供群组服务的集中服务,搭建kafka之前首先需要搭建zooKeeper的组件
linux下载:wget https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper-3.7.0-bin.tar.gz
下载成功后解压并添加到环境变量
export ZK_HOME=/Applications/devOps/bigData/zookeeper
export PATH=$PATH:$ZK_HOME/bin
在zookeeper的conf的目录下,把zoo_sample.cfg复制一份并命名为zoo.cfg,修改zoo.cfg内容
添加内容如下:
dataDir=/Applications/devOps/bigData/zookeeper/data
dataLogDir=/Applications/devOps/bigData/zookeeper/log
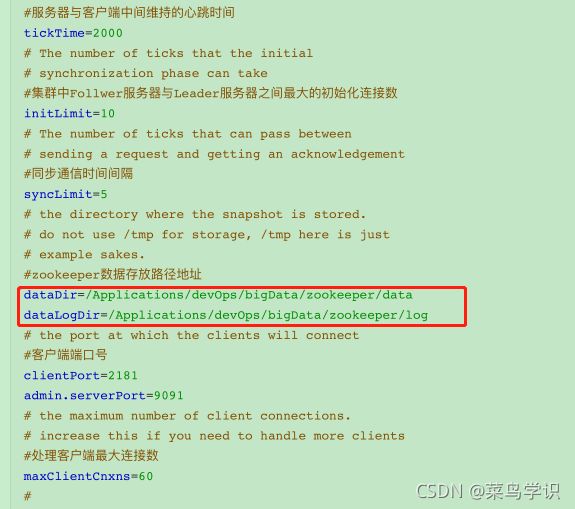
并在安装目录下面新建一个空的data文件夹和log文件夹
启动zookeeper的服务,命令为:zkServer.sh start
下⾯查看监听的端⼝,具体如下: lsof -i:2181
查看zookeeper的集群状态信息: zkServer.sh status
使用zk客户端连接测试zookeeper,命令为:zkCli.shkafka安装
在Apache Kafka下载kafka中间件,解压后在kafka解压目录下下有一个config的文件夹我的目录是/Applications/devOps/bigData/kafka/config/server.properties
cd进入kafka解压目录启动命令:bin/kafka-server-start.sh config/server.properties
编辑⽂件server.properties,填写⽬录以及zookeeper的信息,具体如下:
#设置消息⽇志存储路径
# log.dirs=/tmp/kafka-logs
log.dirs=/Applications/devOps/bigData/kafka/data
#指定Zookeeper的连接地址
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
启动具体命令为:
kafka-server-start.sh /Applications/devOps/bigData/kafka/config/server.properties
执⾏后就会启动kafka,它监听的端⼝具体是9092,具体如下:
lsof -i:9092
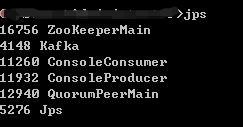
输入jps也可以看到kafka的进程信息
Kafka术语
代理(Broker)
在Kafka的集群中,⼀个Kafka的进程就被称为⼀个broker,也就是代理节点。代理节点是消息队列中的基本概念,⼀般⽽⾔,在⼀台服务器上⼀般部署⼀个Kafka的实例。
⽣产者(Producer)
kafka是⼀个消息队列的中间件,在Kafka的系统中,⽣产者⼀般被称为Producer。所谓Producer就是把消息记录发送到Kafka集群指定的主题中进⾏存储,同时了Producer也能通过⾃定义的算法决定消息记录发送到那个分区(Partition)。
消费者(Consumer)
消费者英⽂是Consumer,指的是从Kafka集群指定的主题中读取消息记录,在读取主题数据时,需要设置消费者组,如果没有设置,Kafka的集群⼀般会默认⽣成⼀个⼩消费组名称。
消费者组
Consumer在读取Kafka主题数据的时候,⼀般会使⽤多线程来进⾏执⾏读取数据,那么⼀个消费者组可以包含⼀个或者多个消费者程序,使⽤多分区以及多线程的模式可以极⼤的提⾼读取数据的效率。
主题(Topic)
Kafka系统是通过主题来区分不同业务类型的消息记录和数据,如招聘数据是A主题,被招聘数据是B主题,那么订阅了A,只能获取招聘数据A。
分区(Partition)
在每⼀个主题中可以有⼀个或者是多个分区,分区它是基于物理层⾯的设计来思考的,不同的分区对应着不同的数据⽂件。Kafka通过分区来⽀持物理层⾯上的并发读写(IO操作),来提⾼Kafka集群的吞吐量。在Kafka的系统中,每个分区内部的消息记录是有序的,每个消息都有⼀个连续的便移量序号Offset。⼀个分区只对应⼀个代理节点,当然⼀个代理节点可以管理多个分区。
副本(Replication)
在Kafka的系统中,每个主题在创建时需要指定它的副本,默认是1,通过副本的机制来保障Kafka分布式集群数据的⾼可⽤性。
记录(Record)
被实际写⼊到Kafka集群并且可以被消费者程序读取的数据,被称为记录,也就是Record,每个记录包含⼀个键(key),值(value),和时间戳(Timestamp)。
kafka的基本操作
主题操作
在kafka中,主题是⾮常重要的部分,通过⼀个具体的主题来获取具体的数据。主题的操作主要会涉及到主题的创建,主题的查看,以及主题的删除操作。下⾯具体来看这部分的操作,操作topic的主题使⽤到的命令是kafka-topics.sh。
创建主题
#创建主题
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic dev
#创建主题成功后输出的信息
Created topic dev.
备注:replication-factor代表是副本的意思,这里副本是1,partitions代表的是分区,这里分区是6
查看所有主题
kafka-topics.sh --list --zookeeper localhost:2181
查看具体主题
kafka-topics.sh --describe --zookeeper localhost:2181 --topic dev
删除主题
kafka-topics.sh --delete --zookeeper localhost:2181 --topic dev
生产者消费者模式
生产者
创建一个消息生产者:kafka-console-producer.sh --broker-list localhost:9092 -topic login
消费者
创建一个消息消费者:
kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic login --from-beginning
生产者消费者通信
在生产者端模拟发送消息,看消费者是否收到
kafka-console-producer.sh --broker-list localhost:9092 -topic login
#生产者端模拟消息
>this is a product message在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息
kafka的生产者模式
生产者模块概述
Kafka系统作为MQ的中间件,都是基于生产者和消费者的模式,思维生产者可以简单的理解就是把应用程序的log信息写入到Kafka的集群,因为有了生产者写入的数据,也就有了消费者对数据的消费。Kafka系统的核心组件主要是生产者,消费者,数据流,连接器。其实这也符合逻辑,也就是说信息的输入,中间是处理过程,最后是信息输出的过程
对于Kafka的生产者写入数据的过程,简单的描述主要为:Kafka系统实时读取原始数据(可能是log数据,也可能是应用程序其他的数据),然后把实时读取到的原始数据写入到Kafka的集群中。
生产者写入数据代码实现
一般的方式是通过Kafka系统的bin目录下kafka-console-producer.sh来写入数据,然后使用消费端的工具就能够看到往生产者写入数据的过程。下面主要演示下使用代码的方式,也就是单线程的方式往Kafka的生产者里面写入数据,实现代码具体如下:
package MQ;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.producer.Callback;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Date;
import java.util.Properties;
/*
* 模拟Kafka生产者客户端
* */
public class KafkaMqProducer extends Thread
{
//创建日志对象
private final Logger logger=LoggerFactory.getLogger(KafkaMqProducer.class);
public Properties configure()
{
Properties properties=new Properties();
//指定kafka的集群地址
properties.put("bootstrap.servers","localhost:9092");
//设置应答机制
properties.put("acks","1");
//批量提交大小
properties.put("batch.size",16384);
//延时提交
properties.put("linger.ms",1);
//缓充大小
properties.put("buffer.memory",33554432);
//序列化主键
properties.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
//序列化值
properties.put("value.serializer","org.apache.kafka.common.serialization.StringSerializer");
return properties;
}
public void run()
{
Producer objProducer=new org.apache.kafka.clients.producer.KafkaProducer(this.configure());
//模拟发送数据
JSONObject jsonObject=new JSONObject();
jsonObject.put("username","wuya");
jsonObject.put("city","西安");
jsonObject.put("age",18);
jsonObject.put("date",new Date().toString());
//异步发送,调用回调函数,给主题login写入数据
objProducer.send(new ProducerRecord("login", jsonObject.toJSONString()), new Callback() {
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e)
{
if(e!=null)
{
logger.error("发送错误,信息具体为:"+e.getMessage());
}
else
{
logger.info("写入的数据为:"+recordMetadata.offset());
}
}
});
try{
Thread.sleep(3000);
}catch(Exception e){
e.printStackTrace();
}
//关闭生产者的对象
objProducer.close();
}
public static void main(String[] args)
{
KafkaMqProducer kafkaMqProducer=new KafkaMqProducer();
kafkaMqProducer.start();
}
} 执行代码后,查看主题“login”消费者,就可以看到数据被写入到了生产者,消费者在执行代码后输出的信息如下:
kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic login
{"date":"Sat Apr 10 19:42:42 CST 2021","city":"西安","age":18,"username":"wuya"}在Maven的pom.xml文件里面得引入kafka的信息,具体为:
org.apache.kafka
kafka_2.13
2.7.0
Kafka消费者模式
消费者概述
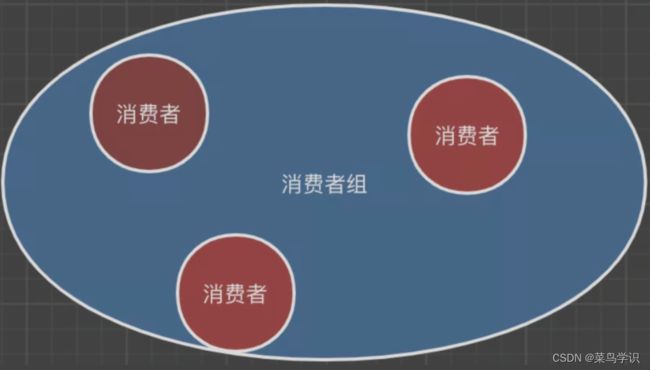
在Kafka的系统⾥⾯,⼀个消费者组是可以包含多个消费者的,消费者组的名字具有唯⼀性的特点,消费者组与消费者的关系具体如下所示:
在Kafka的系统中,主要提供了kafka-console-consumer.sh的脚本来查看⽣产者的的消费信息,命令的⽅式具体为:
kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic login --from-beginning
消费者代码
使⽤Java的语⾔编写消费者的程序来接收⽣产者⽣产的数据,消费者的程序代码具体如下:
package MQ;
import kafkaMq.KafkaMqManyProducer;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class KafkaMqConsumer extends Thread
{
public Properties configure()
{
Properties properties=new Properties();
//指定kafka的集群地址
properties.put("bootstrap.servers","localhost:9092");
//指定消费者组
properties.put("group.id","console-consumer-32947");
//开启⾃动提交
properties.put("enable.auto.commit","true");
//⾃动提交的时间间隔
properties.put("auto.commit.interval.ms","1000");
//反序列化消息主键
properties.put("key.deserializer","org.apache.kafka.common.serialization.StringDeseria
lizer");
//序列化消息记录
properties.put("value.deserializer","org.apache.kafka.common.serialization.StringDeser
ializer");
return properties;
}
@Override
public void run()
{
KafkaConsumer consumer=new KafkaConsumer
(configure());
//订阅消费主题集合
consumer.subscribe(Arrays.asList("login"));
boolean flag=true;
while (flag)
{
//获取主题消息数据
ConsumerRecords resords=consumer.poll(100);
for(ConsumerRecord record:resords)
{
//循环打印消息数据
System.out.printf("offerset=%d,key=%s,value=%s
%n",record.offset(),record.key(),record.value());
}
}
consumer.close();
}
public static void main(String[] args)
{
KafkaMqConsumer kafkaMqConsumer=new KafkaMqConsumer();
kafkaMqConsumer.start();
}
} Kafka连接器
连接器概述
Kafka除了⽣产者和消费者的核⼼组件外,它的另外⼀个核⼼组件就是连接器,简单的可以把连接器理解为是Kafka系统与其他系统之间实现数据传输的通道。通过Kafka的连接器,可以把⼤量的数据移⼊到Kafka的系统,也可以把数据从Kafka的系统移出。具体如下显示:

依据如上,这样Kafka的连接器就完成了输⼊和输出的数据传输的管道。也就很好的理解了我们从第三⽅获取到海量的实时流的数据,通过⽣产者和消费者的模式写⼊到Kafka的系统,再经过连接器把数据最终存储到⽬标的可存储的数据库,⽐如Hbase等。基于如上,Kafka的连接器使⽤场景具体可以总结为:
- Kafka作为⼀个连接的管道,把⽬标的数据写⼊到Kafka的系统,再通过Kafka的连接器把数据移出到⽬标的数据库
- Kafka作为数据传输的中间介质,仅仅是数据传输的⼀个管道或者说是数据传输的中间介质⽽已。如⽇志⽂件的信息传输到Kafka的系统后,然后再从Kafka的系统把这些数据移出到ElasticSearch中进⾏存储并展示。通过Kafka的连接器,可以有效的把Kafka系统的⽣产者模式和消费者模式进⾏的整合,完成它的解耦。
连接器实战
本地⽂件写到Kafka
启动Kafka系统的连接器可以通过两种⽅式来进⾏启动,⼀种⽅式是单机模式,另外⼀种的⽅式是分布式模式,这⾥主要是以单机模式来启动Kafka的连接器。在kafka/config的⽬录下配置连接器的信息,它的配置⽂件名称为:connect-file-source.properties,配置的内容为:
# limitations under the License.
#设置连接器名称
name=local-file-source
#指定连接器类
connector.class=FileStreamSource
#设置最⼤任务数
tasks.max=1
#指定读取的⽂件
file=/tmp/data.txt
#指定主题名
topic=conn下来在tmp的⽬录下创建data.txt的⽂件,⽂件的内容为:
cat data.txt
Kafka
Hadoop
Spark
Hive
Hbase
查看主题data的消费者的程序,启动命令:
kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic conn --from-beginning
配置成功后,通过如下的命令为启动连接器,具体命令为:
./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-
file-source.properties
连接器启动成功后,可以看到data的主题接收到了数据信息,具体如下:
#查看主题data的消费者程序
kafka-console-consumer.sh --bootstrap-server localhost:9092 -topic data --from-
beginning
#启动连接器后,接收到的数据信息(也就是/tmp/data.txt的数据⽂件)
{"schema":{"type":"string","optional":false},"payload":"Kafka"}
{"schema":{"type":"string","optional":false},"payload":"Hadoop"}
{"schema":{"type":"string","optional":false},"payload":"Spark"}
{"schema":{"type":"string","optional":false},"payload":"Hive"}
{"schema":{"type":"string","optional":false},"payload":"Hbase"}
{"schema":{"type":"string","optional":false},"payload":"Flink"}Kafka数据写到本地
下⾯实现在单机的模式下,把Kafka主题中的数据导出到本地的具体⽂件中,在config的配置⽂件connect-file-sink.properties中指定被导出的数据写⼊到本地的具体⽂件中,具体⽂件内容如下:
# limitations under the License.
name=local-file-sink
connector.class=FileStreamSink
tasks.max=1
file=/tmp/target.txt
topics=login实现kafka的数据步骤为:
- ./connect-standalone.sh ../config/connect-standalone.properties ../config/connect-file-
source.properties - 然后在/tmp下创建⽂件target.txt。下来执⾏如下命令把Kafka的数据导出到本地
- ./connect- standalone.sh ../config/connect-standalone.properties ../config/connect-file-sink.properties