图像处理中底层、高层特征、上下文信息理解
1.图像的语义信息:
图像的语义分为视觉层、对象层和概念层。
视觉层即通常所理解的底层,即颜色、纹理和形状等等,这些特征都被称为底层特征语义;
对象层即中间层,通常包含了属性特征等,就是某一对象在某一时刻的状态;
概念层是高层,是图像表达出的最接近人类理解的东西。
通俗点说,比如一张图上有沙子,蓝天,海水等,视觉层是一块块的区分,对象层是沙子、蓝天和海水这些,概念层就是海滩,这是这张图表现出的语义。
2.图像的底层、高层特征:
2.1图像的低层特征:
图像底层特征指的是:轮廓、边缘、颜色、纹理和形状特征。
边缘和轮廓能反映图像内容;如果能对边缘和关键点进行可靠提取的话,很多视觉问题就基本上得到了解决。图像的低层的特征语义信息比较少,但是目标位置准确;
2.2图像的高层特征:
图像的高层语义特征值得是我们所能看的东西,比如对一张人脸提取低层特征我们可以提取到连的轮廓、鼻子、眼睛之类的,那么高层的特征就显示为一张人脸。高层的特征语义信息比较丰富,但是目标位置比较粗略。
愈深层特征包含的高层语义性愈强、分辨能力也愈强。我们把图像的视觉特征称为视觉空间 (visual space),把种类的语义信息称为语义空间 (semantic space)
3.我们是如何通过神经网络来判别这是一只猫的?

训练好的神经网络会在复杂运算后得到关于一张图片的响应值(可以是实数,也可以是实向量),我们会根据这个响应值按照预先设置的先验规则来得到最终的判别值。比如我们的规则是这个值大于0.5就判别为猫,小于0.5就判别为非猫。我们的网络得到0.8,所以判别为猫。
响应值是如何计算出的?
那么关键就在于最后的神经网络的响应值是如何得到的?请允许锦恢进行一段潦草的说明。
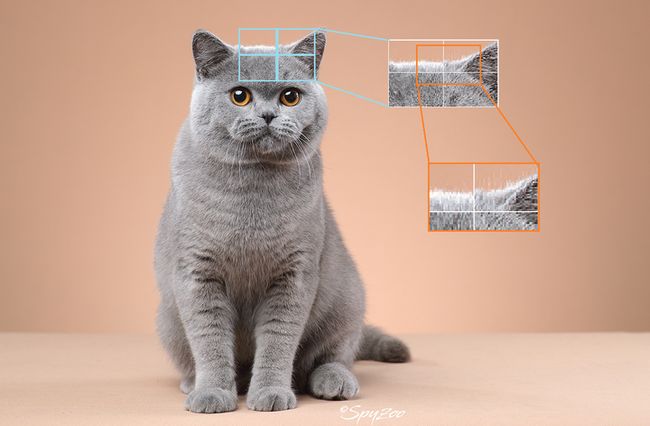
由于卷积神经网络每一个卷积核在单层中只能计算相邻区域的像素点的响应,所以,在第一层中,我们的网络只能计算出每一个小的像素区域的响应值,比如,第一层的某个卷积核就只能计算下图中蓝框框出来的区域中的所有像素的响应值:

这片单个卷积核在原图上能够计算的响应区域被我们称为该卷积的感受野。很明显,第一层的卷积核的感受野很小,这么小的感受野对应的像素点是什么?石灰?沙发?如此小的感受野区域是极难得到关于这个像素是什么这样的信息的,讲得认真点,小感受野对应区域的特征空间太小啦,小到无法与标签空间构成满射。事实上,这就是我们所说的图像的语义信息,因此小的像素区域是难以得到关于图像的高阶语义信息的,因为感受野太小了。
我们继续,进入卷积层的第二层:
第二层基于第一层卷积进行卷积,很明显,它对应的感受野会比第一层卷积核的感受野大,能够计算原图更大区域对应区域的响应值,比如下图中橙色区域对应的区域。
 实际神经网络工作时得到的响应值可不是上图的原图,此处只是为了描述方便才贴的原图
实际神经网络工作时得到的响应值可不是上图的原图,此处只是为了描述方便才贴的原图
事实上,第一层的卷积核在提取区域的同时,还会对所提取区域的色彩,纹理模式等信息进行计算,这种计算可以看成一种临时的隐性编码。因此,到第二层卷积层时,卷积核得到的不仅是一组像素点在更大的原图区域上的响应,还有颜色,纹理等编码信息,用于分类猫猫的特征空间变大了。在这一层中,网络可能得到了原图的轮廓信息,梯度信息等等。
后面的图懒得画了。。。
待神经网络运行到了最后一层时,卷积核的感受野已经能够几乎覆盖原图所有区域,而且每层传递的隐性的编码信息已经将原本的特征空间张得很大了,此时便可以很方便得使用线性分类器:
 来区分了。
来区分了。
因此,非常非常不科学地讲,为什么深层地特征图具备更加丰富的语义信息呢?我认为主要有两点:
- 深层网络的感受野更大,大感受野下才存在一定的高阶语义。
- 深层网络所积累的特征空间更大。
4.上下文信息理解
从语义角度出发,举例说明。

问,中央的两位球员在做什么?
那首先第一步,我得找到球员。
而事实上,计算机看着这玩意就是一堆像素,一个像素是分辨不出球员的,因此需要一个窗口,这个窗口在整张图中滑动,并找到球员的头,身体,手臂等等。
这个窗口就是每个像素点的上下文(context),也即邻域信息,其可以自然表征图像的局部语义。
好的,我们记录下来球员每个部位的姿态了,那么下一个问题来了,他在干啥?
当我们仅仅着眼于上下文时,其实并无法获知他在干嘛,他可能是在投篮,也可能是在跳高,甚至可能是在跳舞。但是如果将全图的元素,包括篮球,球场,观众都综合下来,就可以确定他在投篮了。全图的综合就是全局信息(global)。全局信息可以协助更好地描述局部语义信息,早期的分割方法中的ASPP模块就有这种思想。
那其实这个问题已经解决了,但是这相当于我们用小孔浏览了一圈然后把图中所有元素拼合在一起,但其实这样并不好。图中存在一些东西它们距离很远,但是有很强的语义联系,就像这张图中的球员和篮球,如果能同时涵盖二者,就可以直接理解这幅图。这种关系叫做远距依赖性(long distance dependency),这种依赖不仅存在于图像中,更是存在于视频的不同帧里,非常推荐读一下non local那篇文章,作为前transformer时代一个自注意力模型,讲得很清楚。
ok,图内的信息我们基本提取完了,那我们来回答他到底在做什么?那其实会发现以下回答都是正确的: 1.在运动,2.打篮球,3.投篮。你会发现其实123有隶属关系,你要回答哪个仅仅取决于问问题的人想要哪个层次的回答。这种层次就是语义粒度,粒度这个词常见的一种场合是细粒度分类,比如分出这个动物是猫是狗就属于粗粒度,而分出这只猫属于哪个品种,就属于细粒度了。
参考
c对图像中语义信息、高层和底层特征的理解
深度学习(图像领域)中总是提到的上下文信息,全局信息,长距离依赖,粒度分别是什么意思呢,有什么区别?