HashMap实现原理及扩容机制详解
文章目录
- 一、HashMap基础
- 二、红黑树基础
- 三、HashMap实现原理
-
- 1、Node和Node链
- 2、拉链法
- 3、关于Node数组 table
- 4、散列算法
- 5、HashMap和红黑树
- 6、关于TreeNode
转自,这篇更详细: https://blog.csdn.net/lkforce/article/details/89521318
一、HashMap基础
HashMap继承了AbstractMap类,实现了Map,Cloneable,Serializable接口
HashMap的容量,默认是16
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
HashMap的加载因子,默认是0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
当HashMap中元素数超过容量*负载因子时,HashMap会进行扩容。
二、红黑树基础
红黑树是一种近似平衡的二叉查找树,他并非绝对平衡,但是可以保证任何一个节点的左右子树的高度差不会超过二者中较低的那个的一倍。
红黑树有这样的特点:
- 1、每个节点要么是红色,要么是黑色。
- 2、根节点必须是黑色。叶子节点必须是黑色NULL节点。
- 3、红色节点不能连续。
- 4、对于每个节点,从该点至叶子节点的任何路径,都含有相同个数的黑色节点。
- 5、能够以O(log2(N))的时间复杂度进行搜索、插入、删除操作。此外,任何不平衡都会在3次旋转之内解决。
三、HashMap实现原理
1、Node和Node链
首先来了解一下HashMap中的元素类型:HashMap类中的元素是Node类,翻译过来就是节点,是定义在HashMap中的一个内部类,实现了Map.Entry接口。
Node类的定义如下:
/**
* Basic hash bin node, used for most entries. (See below for
* TreeNode subclass, and in LinkedHashMap for its Entry subclass.)
*/
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
可以看到,Node类的基本属性有:
hash:key的哈希值
key:节点的key,类型和定义HashMap时的key相同
value:节点的value,类型和定义HashMap时的value相同
next:该节点的下一节点
值得注意的是其中的next属性,记录的是下一个节点本身,也是一个Node节点,这个Node节点也有next属性,记录了下一个节点,于是,只要不断的调用Node.next.next.next……,就可以得到:
Node–>下个Node–>下下个Node……–>null
这样的一个链表结构,而对于一个HashMap来说,只要明确记录每个链表的第一个节点,就能顺序遍历链表上的所有节点。
2、拉链法
HashMap使用拉链法管理其中的每个节点。
由Node节点组成链表之后,HashMap定义了一个Node数组:
transient Node<K,V>[] table;
这个数组记录了每个链表的第一个节点,于是最终形成了HashMap下面这样的数据结构:
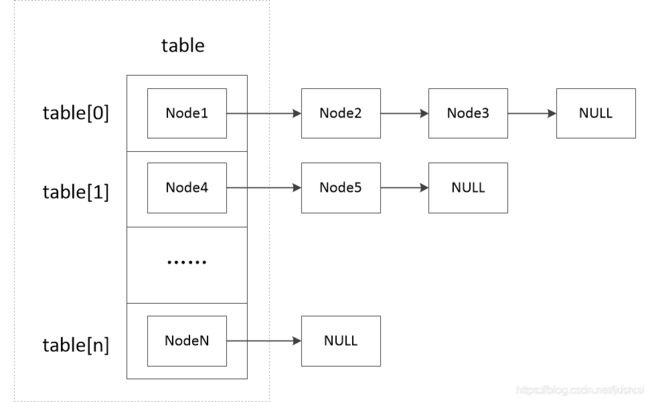
这种数组+链表的数据结构,使得HashMap可以较为高效的管理每一个节点。
3、关于Node数组 table
对于table的理解,对后面关于扩容的理解很有帮助。
table在第一次往HashMap中put元素的时候初始化。
如果HashMap初始化的时候没有指定容量,那么初始化table的时候会使用默认的DEFAULT_INITIAL_CAPACITY参数,也就是16,作为table初始化时的长度。
如果HashMap初始化的时候指定了容量,HashMap会把这个容量修改为2的倍数,然后创建对应长度的table。因为table在HashMap扩容的时候,长度会翻倍。所以table的长度肯定是2的倍数。
修改容量的方法是这样的:
/**
* Returns a power of two size for the given target capacity.
*/
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
所以要注意,如果要往HashMap中放1000个元素,又不想让HashMap不停的扩容,最好一开始就把容量设为2048,设为1024不行,因为元素添加到七百多的时候还是会扩容。
4、散列算法
当调用HashMap.put()方法时,经历了以下步骤:
-
对key进行hash值计算
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); } -
hash值和table.length取模
取模的方法是
(table.length - 1) & hash,算法直接舍弃了二进制hash值在table.length以上的位,因为那些位都代表table.length的2的n次方倍数。取模的结果就是Node将要放入table的下标。比如,一个Node的hash值是5,table长度是4,那么取余的结果是1,也就是说,这个Node将被放入table[1]所代表的链表(table[1]本身指向的是链表的第一个节点)。
-
添加元素
如果此时table的对应位置没有任何元素,也就是table[i]=null,那么就直接把Node放入table[i]的位置,并且这个Node的next==null。如果此时table对应位置是一个Node,说明对应的位置已经保存了一个Node链表,则需要遍历链表,如果发现相同hash值则替换Node节点,如果没有相同hash值,则把新的Node插入链表的末端,作为之前末端Node的next,同时新Node的next==null。
如果此时table对应位置是一个TreeNode,说明链表被转换成了红黑树,则根据hash值向红黑树中添加或替换TreeNode。(JDK1.8)
-
如果添加元素之后,Node链表的节点数超过了8个,则该链表会考虑转为红黑树。
-
如果添加元素之后,HashMap总节点数超过了阈值,则HashMap会进行扩容。
相关代码是这样的:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) //注释1
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k)))) //注释2
e = p;
else if (p instanceof TreeNode) //注释3
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash); //注释4
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) //注释5
resize();
afterNodeInsertion(evict);
return null;
}
代码解析:
- 注释1,table对应位置无节点,则创建新的Node节点放入对应位置。
- 注释2,table对应位置有节点,如果hash值匹配,则替换。
- 注释3,table对应位置有节点,如果table对应位置已经是一个TreeNode,不再是Node,也就说,table对应位置是TreeNode,表示已经从链表转换成了红黑树,则执行插入红黑树节点的逻辑。
- 注释4,table对应位置有节点,且节点是Node(链表状态,不是红黑树),链表中节点数量大于TREEIFY_THRESHOLD,则考虑变为红黑树。实际上不一定真的立刻就变,table短的时候扩容一下也能解决问题,后面的代码会提到。
- 注释5,HashMap中节点个数大于threshold,会进行扩容。
5、HashMap和红黑树
从JDK1.8开始,在HashMap里面定义了一个常量TREEIFY_THRESHOLD链表转红黑树阀值,默认为8。当链表中的节点数量大于TREEIFY_THRESHOLD时,链表将会考虑改为红黑树,代码是在上面putVal()方法的这一部分:
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
其中的treeifyBin()方法就是链表转红黑树的方法,这个方法的代码是这样的:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
可以看到,如果table长度小于常量MIN_TREEIFY_CAPACITY最小树形化阈值时,不会变为红黑树,而是调用resize()方法进行扩容。MIN_TREEIFY_CAPACITY的默认值是64。显然HashMap认为,虽然链表长度超过了8,但是table长度太短,只需要扩容然后重新散列一下就可以。
后面的代码中可以看到,如果table长度已经达到了64,就会开始变为红黑树,else if中的代码把原来的Node节点变成了TreeNode节点,并且进行了红黑树的转换。
6、关于TreeNode
当HashMap把链表转为红黑树的时候,原来的Node节点就会被转为TreeNode节点,TreeNode也是HashMap中定义的内部类,定义大概是这样的:
/**
* Entry for Tree bins. Extends LinkedHashMap.Entry (which in turn
* extends Node) so can be used as extension of either regular or
* linked node.
*/
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
/**
* Ensures that the given root is the first node of its bin.
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
tab[index] = root;
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
/**
* Finds the node starting at root p with the given hash and key.
* The kc argument caches comparableClassFor(key) upon first use
* comparing keys.
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
可以看到,TreeNode继承了LinkedHashMap的Entry,TreeNode节点在构造时,也指定了hash值,key,value,下一节点next,这些都是和Node相同的结构。
同时,TreeNode还保存了父节点parent, 左孩子left,右孩子right,上一节点prev,另外还有红黑树用到的red属性。