linux服务器搭建kafka并集成springboot
一、在服务器搭建kafka
1、kafka官网地址
http://kafka.apache.org/
2、搭建zookeeper
搭建kafka之前需要先搭建zookeeper,因为kafka依赖zookeeper,它会保存kafka相关节点的数据,所以安装kafka钱需要先安装zookeeper
说明:这里在服务器安装zookeeper和kafka用的安装包直接解压到相关安装目录的,另外也可以使用docker直接拉取相关镜像安装
(1)下载安装包
zookeeper官网下载地址:
https://link.csdn.net/?target=https%3A%2F%2Farchive.apache.org%2Fdist%2Fzookeeper%2F
(2)下载好相关版本后直接上传到服务器相关文件目录
博主下载的版本:apache-zookeeper-3.5.10-bin.tar.gz
(3)在目录下用命令解压
tar -zxvf apache-zookeeper-3.5.10-bin.tar.gz
(4)修改配置文件
使用cd 命令进入apache-zookeeper-3.5.10-bin目录,
然后进入conf文件夹,使用mv命令修改zoo-sample.cfg文件名为zoo.cfg,简化文件名称
vim zoo.cfg进入配置文件,修改Zookeeper数据存储地址,默认地址为Linux临时文件目录,在安装目录下新建文件夹,地址切换为新建文件夹的地址,修改后保存并退出。比如在apache-zookeeper-3.5.10-bin目录下新建data作为存储数据文件
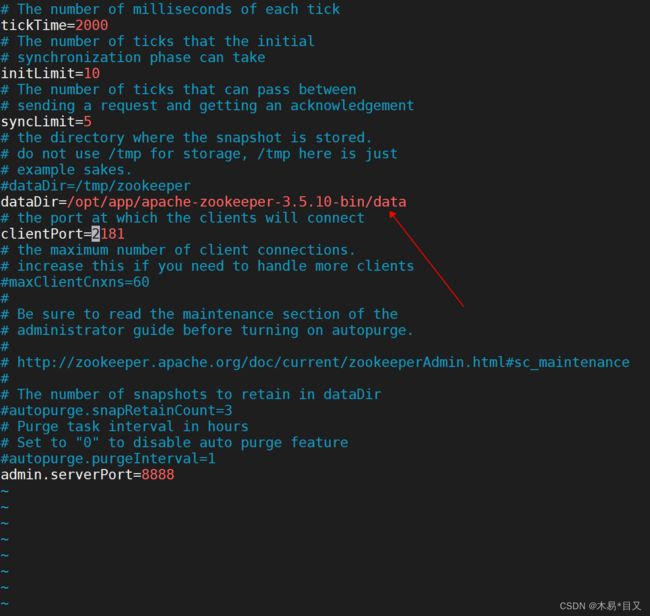
如果需要修改默认端口号也可以直接在这里修改clientPort。
zookeeper conf配置文件zoo.cfg参数详解:
tickTime = 2000 :通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit = 10 :LF初始通信时限
syncLimit = 5 :LF同步通信时限
dataDir:保存Zookeeper中的数据
clientPort = 2181:客户端连接端口
(5)使用cd命令进入bin目录下,使用 ./zkServer.sh start 启动服务 ,启动完成后可以使用命令
ps -ef | grep zookeeper查看zookeeper服务启动进程相关信息。
3、搭建kafka
(1)官网下载地址
https://kafka.apache.org/downloads
(2)下载好相关版本后直接上传到服务器相关文件目录
目前来说Kafka3.0.0版本不再支持Java8,Kafka2.8.0可替换不使用ZooKeeper,所以这边下载的版本需要自己注意下。
博主下载版本:kafka_2.12-2.8.0.tgz
(3)在目录下用命令解压
tar -zxvf kafka_2.12-2.8.0.tgz
(4)修改配置文件
使用cd命令进入kafka_2.12-2.8.0目录下
然后进入config目录
vim server.properties 进入文件后
a、修改配置参数broker.id=0 ,该数值在集群服务中为唯一,不允许重复

b、往下翻,找到配置参数log.dirs=/tmp/kafka-logs,改参数地址为存储Kafka数据地址,默认地址为Linux临时目录,会不定时回收,请修改地址。如果不修改地址也可以,按照/tmp/kafka-logs创建相关目录就可以了。

c、往下翻,找到配置参数zookeeper.connect=localhost:2181,该配置参数为zookeepe集群的地址,可以是多个,多个之间用逗号分割,一般端口都为2181;master:2181,slave0:2181,slave1:2181,这里如果zookeeper的端口号没有更改,又是单机的话,就只需要将ip改为服务器的IP即可。
d、往上翻,找到配置参数listeners和advertised.listeners,其中listeners参数表示允许外部端口连接 对应的IP为服务器的内网IP
查看服务器的内网IP可以直接使用命令: ifconfig eth0
advertised.listeners参数表示外部代理地址,对应的IP为服务器的公网IP,就是你连接服务器的IP
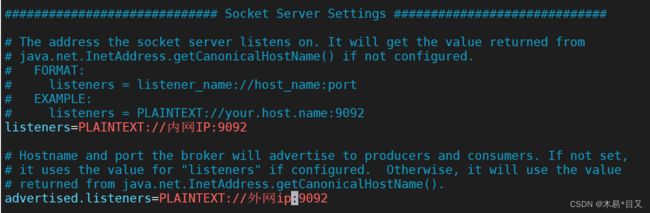
e、配置Kafka环境变量,使用cd命令进入根目录,使用vim ./etc/profile 文件配置Kafkal路径并保存退出 后面的路径为kafka的文件夹地址
export KAFKA_HOME=。。。
export PATH=P A T H : PATH:PATH:KAFKA_HOME/bin
(5)使用cd命令到bin目录下使用./kafka-server-start.sh -daemon …/config/server.properties 启动Kafka服务,但要注意启动kafka前要保证先启动zookeeper服务,然后可以使用
ps -ef | grep kafka来查看kafka启动进程相关信息。
至此,服务器搭建kafka服务完成。
二、springboot集成kafka
1、导入依赖
org.springframework.kafka
spring-kafka
2、在yml配置文件中加入相关配置
spring:
kafka:
bootstrap-servers: 127.0.0.1:9092
# 初始化生产者配置
producer:
# 生产者重试次数
retries: 1
# 应答级别:多少个分区副本备份完成时向生产者发送ack确认
acks: 1
# 批量大小,当有多个消息需要被发送到同一个分区时生产者会把它们放在同一个批次里。该参数指定了一个批次可以使用的内存大小,按照字节数计算16k左右
batch-size: 16384
# 设置生产者内存缓冲区的大小,默认32MB
buffer-memory: 33554432
# 键的序列化方式
key-serializer: org.apache.kafka.common.serialization.StringSerializer
# 值的序列化方式
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 提交延时,当生产端积累的消息达到batch-size或者接收到消息linger.ms后,生产者就会将消息交给Kafka,如果将linger.ms设置为0表示每接收到一条消息就提交给kafka
properties:
linger.ms: 0
# 初始化消费者配置
consumer:
properties:
# 默认的消费组id
group.id: default-group
# 消费会话超时时间,超过这个时间consumer没有发送心跳,就会触发rebalance操作
session.timeout.ms: 120000
# 消费请求超时时间
request.timeout.ms: 180000
# 是否自动提交offset
enable-auto-commit: true
# 接收到消息后多久提交offset
auto-commit-interval: 1S
# 当kafka中没有初始offset或者offset超出范围时将自动重置offset,earliest表示重置为分区中最小的offset,latest表示重置为分区中最新的offset
auto-offset-reset: latest
# 键的反序列化方式
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 值的反序列化方式
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
# 批量消费每次最多消费多少条消息
max-poll-records: 50
listener:
# 消费端监听的topic不存在时,项目启动会报错(关掉)
missing-topics-fatal: false
# 设置批量消费
type: batch
3、创建demo,测试发布和订阅消息
(1)生产者demo
@RestController
@RequestMapping("kafka/demo")
public class KafkaProducerDemo {
@Resource
private KafkaTemplate kafkaTemplate;
@GetMapping("/send")
public String sendMessage(){
kafkaTemplate.send("test", "4.7号发送第二条消息demo");
return "send success";
}
} (2)消费者demo
@Component
@Slf4j
public class KafkaConsumerDemo {
/**
* 单条消费,不指定批量消费
* @param record 消息体
*/
@KafkaListener(topics = {"test"})
public void onMessage(ConsumerRecord record){
log.info("测试kafka消息消息demo, topic为" + record.topic() + "---分区数为" + record.partition() + "---消息内容为" + record.value());
}
/**
* 批量一次行消费多条
* @param record 消费体
*/
@KafkaListener(topics = {"test"}, errorHandler = "myConsumerAwareExceptionHandler")
public void onMessage(List> record){
//throw new BaseException("模拟测试一下异常处理器");
log.info("测试kafka批量消息demo, 一共有" + record.size() + "消息---详情消息内容为" + record.toString());
}
} /**
* 消费异常处理器
*/
@Slf4j
@Configuration
public class ConsumerAwareExceptionHandler {
@Bean
public ConsumerAwareListenerErrorHandler myConsumerAwareExceptionHandler(){
return new ConsumerAwareListenerErrorHandler() {
@Override
public Object handleError(Message message, ListenerExecutionFailedException e, Consumer consumer) {
log.error("===================消息消费发生异常, 异常消息内容为:" + message.toString() + ", 异常详情为:" + e.getMessage());
// 业务处理
return null;
}
};
}
}至此,springboot集成kafka简单demo完成,还有很多消息过滤、事务等在此不做赘述了