计算机网络-TCP协议
面向连接的运输:TCP
TCP连接
TCP被称为面向连接的,因为在应用程序开始互传数据之前,TCP会先建立一个连接,该连接的建立涉及到三次“握手”。
TCP的连接不是一条真实存在的电路,而是一条逻辑链接,其共同状态仅保留在两个通信端系统的TCP程序中。
TCP连接也是点对点的,即TCP连接只能存在于一对一对的主机之间,不允许多于两台主机的共同建立一条TCP连接,最大主机数量为两台。
三次握手的简述
1.客户首先发送一个特殊的TCP报文段。
2.服务器用另一个特殊的TCP报文段来响应。
3.最后,客户用第三个特殊报文段作为响应。
前两个报文段不承载“有效载荷”,即不包含应用层数据。而第三个报文段可以承载有效载荷。
这个过程被称为三次握手。
TCP连接的组成
客户进程通过套接字传递数据流,数据一旦通过该门,它就由客户中的TCP控制,TCP将这些数据引导到该连接的发送缓存里。
发送缓存是三次握手期间设置的缓存之一。
随后TCP将不时地从缓存里取出一块数据,并将数据传递给网络层,并且发送给接收方。
TCP从缓存中取出并放入报文段的数据数量受限于最大报文段长度(MSS)。
MSS通常由本地发送主机发送的最大链路层帧长度(即最大传输单元MTU)来设置。
TCP在接收端接收到一个报文段后,会将该报文段存入接收缓存中,应用程序则从接收缓存中取得数据。
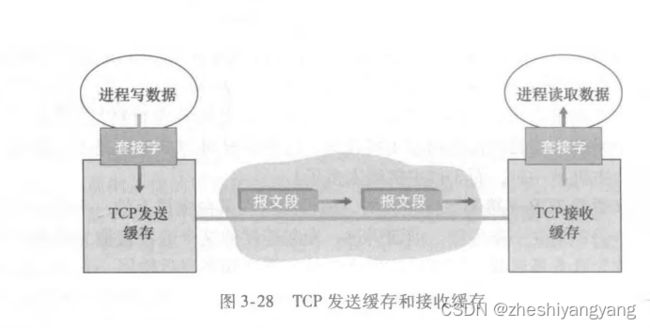 TCP连接的组成包括:一台主机上的发送缓存、套接字、变量,另一台主机上的接收缓存、套接字、变量。
TCP连接的组成包括:一台主机上的发送缓存、套接字、变量,另一台主机上的接收缓存、套接字、变量。
TCP报文段结构

TCP报文段主要包含下列字段:
1.32比特的序号字段、32比特的确认号字段。
2.16比特的接收窗口字段,用来流量控制。
3.4比特的首部长度字段,用来标识TCP首部长度。
4.可选与变长的选项字段,用于发送方与接收方协商最大报文长度(MSS)时。
5.6比特的标志字段。
序号和确认号
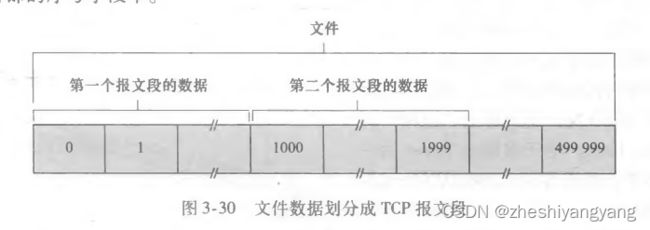
TCP对序号的使用建立在传送的字节流上吗,并不建立在传送的报文段序列之上,一个报文段的序号是该报文段首字母的序号。
例如下面传送一个500 000字节的文件,其MSS为1000字节,数据流的首字节编号是0.
则下图标识了文件数据被换分成不同TCP报文段的方式:
TCP的累积确认
现在假设主机A收到了主机B的字节0~535的报文段,以及另一个包含字节900~1000的报文段。
但没有收到536~899的报文段。所以主机A为了重新构建主机B的数据流,仍在等待字节536(和其
后的字节)。因此,A到B的下一个报文段将在确认号字段中包含536.
因为TCP只确认该流中第一个字节,所以TCP被称为提供累积确认。
下面是Telnet:序号和确认号的一个典型示意图:

往返时间的估计与超时
因为TCP需要实现超时/重传机制,但是超时的时间该怎么设置呢?重传的时间又该设置为多少呢?
为此需要根据往返时间来测定这个超时的时间,但是往返时间的动态测定显然是不现实的,为此我们可以估计往返时间。
估计往返时间
估计往返时间由如下方法来完成:
1.报文段的样本RTT(SampleRTT)就是从某报文段被发出到该报文段被接收之间的时间量。
大多数TCP的实现仅在某个时刻做一次SampleRTT测量。
然后对于SampleRTT的值也许都是非典型的,因此我们引入了一个典型的值,叫做
EstimatedRTT,也就是动态的RTT。
它使用如下公式获得:
![]()
EstimatedRTT是一个SampleRTT的加权平均值。
从统计学观点讲,这种平均被称为指数加权移动平均(EWMA)。
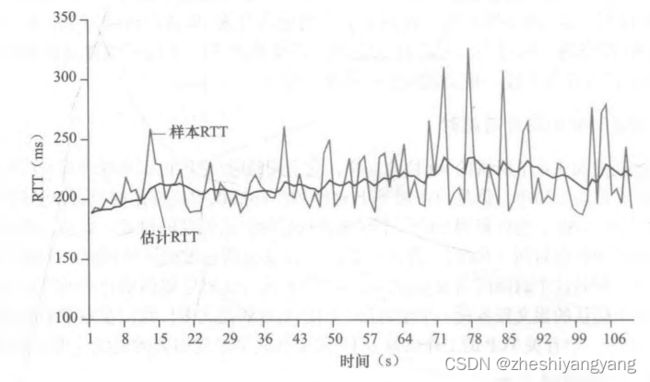
下图是一个SampleRTT和EstimatedRTT的例子:
除了估算RTT以外,我们还可以测量RTT的变化,也就是RTT偏差DevRTT:
![]()
DevRTT是一个SampleRTT与Estimated之间差值的EWMA,如果SampleRTT值波动较小,那么DevRTT的值就会很小,如果波动很大,那么DevRTT的值就会很大。
设置和管理重传超时间隔
TCP超时间隔应该大于等于EstimatedRTT,否则将会造成不必要的重传,但是也不应该比EstimatedRTT大太多。
TimeoutInterval = EstimatedRTT + 4·DevRTT