Vision Transformer 入门到继续入门2022
推荐文章:
搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了
推荐视频:
B站:李宏毅 transfromer
推荐关注问题:
如何看待Transformer在CV上的应用前景,未来有可能替代CNN吗? - 知乎
关于Transformer的那些个为什么 - 知乎
最近两年借助self-attention的Transformer一下火了,不看不行。
问题1: TransForms是什么?
相对于传统RNN网络结构一种加强,作为一种网络结构取代了传统seq2seq中的RNN模型,解决了并行计算的问题,为模型训练提供了加速能力,他是一种基于注意力机制的深度学习网络。
问题1: TransForms为什么可以对序列模型建模?因为里面的核心采用了注意力机制(Attention Is All You Need 2017)
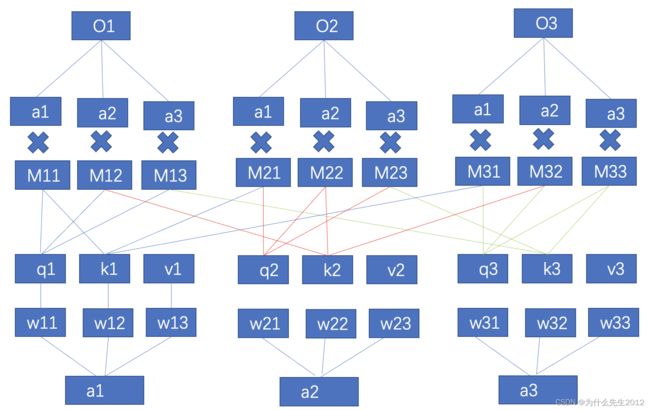
例如当输入为一个序列的时候,其中每一个输入都会经过一个可学习的矩阵W产生Q,K,V,然后每一个的V会和所有的K进行相乘,然后经过归一化处理得到对应的系数值,再将这个系数值与每一个V相乘并求和得到对应的输出O,可以发现每个输入都会与其他输入产生交集,从而很快的获取了全局信息,其中M就是我们称之为的注意力。同时q和k的相乘可以理解为计算两个向量之间的相似度。另外这里的使用Q/K/V的W不相同可以保证在不同空间进行投影,增强了表达能力,提高了泛化能力。
问题2:为什么单个图像也可以使用Transfomer?
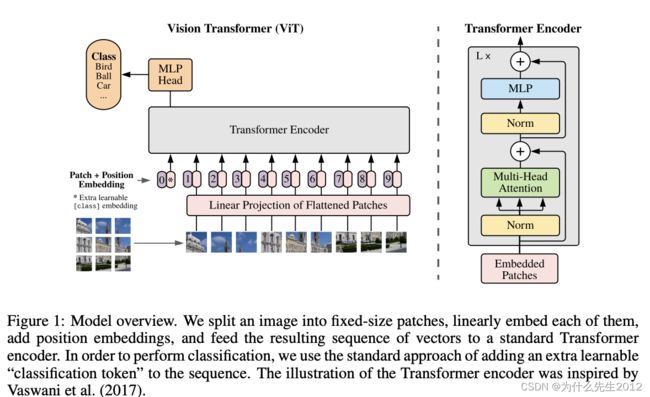
Vision Transformer, 将Transformer应用于图像,来自《AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》 ICLR2021,里面涉及到一个图像序列化的过程,称之为Patch Embedding:
Patch Embedding:图像-> 分块(reshape并形成序列)-〉特征(称为image tokens),image tokens作为transformer的输入。
问题3: 为什么 transfromer 火了?
Transformer 模型使用了 Self-Attention 机制,不采用RNN顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。从NLP到CV一路过五关斩六将,但是基于图像的transformer:VIT为啥没有NLP那么厉害呢,这里Swin Transfomer谈到的是因为图像和NLP本质还是有区别,NLP的尺度固定,图像不是,另外图像的计算量大。 因此 相比于ViT,Swin Transfomer计算复杂度大幅度降低,具有输入图像大小线性计算复杂度。Swin Transformer随着深度加深,逐渐合并图像块来构建层次化Transformer,可以作为通用的视觉骨干网络,应用于图像分类、目标检测和语义分割等任务。
问题4: 深度学习的归纳偏置是什么?
西瓜书中对归纳偏好是这样的定义的,机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好,简称偏好(1.4节,6)。归纳偏好可以看作学习算法自身在一个庞大的假设空间中对假设进行选择的启发式或者“价值观”。CNN对图像问题有天然的inductive bias,如平移不变性等等,以及CNN的仿生学特性,这让CNN在图像问题上更容易;相比之下,transformer没有这个优势,那么学习的难度很大,往往需要更大的数据集(ViT)或者更强的数据增强(DeiT)来达到较好的训练效果。
问题5: transfromer与CNN的对比?(下面引用知乎等回答)
4.1 全局和局部的差异 CNN侧重局部,transfromer侧重全局,CNN通过层数的累积可以达到全局的效果,但是这种全局感受野是以某个中心为原点向外高斯衰减的。为了解决这个问题,CNN可以设计attention module来得到更大更均衡的attention map,很多工作也证明了attention module的有效性。(attention 说白了就是不同特征给予不同权重系数,一般通过softmax得到一个系数)。而Transformer天然自带的long range特性使得从浅层到深层,都比较能利用全局的有效信息,并且multi-head机制保证了网络可以关注到多个discriminative parts,
4.2 (底层局部特征 VS 高层全局抽象特征)CNN网络在提取底层特征和视觉结构方面有比较大的优势。这些底层特征构成了在patch level 上的关键点、线和一些基本的图像结构。这些底层特征具有明显的几何特性,往往关注诸如平移、旋转等变换下的一致性或者说是共变性。例如各种滤波算子。但当我们检测得到这些基本视觉要素后,高层的视觉语义信息往往更关注这些要素之间如何关联在一起进而构成一个物体,以及物体与物体之间的空间位置关系如何构成一个场景,这些是我们更加关心的。目前来看,transformer在处理这些要素之间的关系上更自然也更有效。
4.3 参数动态角度谈论CNN和transformer有什么差异?
CNN 适合监督性学习,但是当数据达到一定量级的时候,CNN吃不消了,推理的时候,模型权重也都是固定的,但是transfrom适配能力不一样,因为transform的参数很多是动态的,每一次的推理,结合不同的上下文,同一个词的词向量可能是不同的。
Transformer的未来?
1 计算效率:毫无疑问,目前Transformer还无法替代CNN的一个重要原因就是计算效率;
2 针对性的设计:目前CV领域还是直接套用NLP中的Transformer结构,并未对CV数据做专门的设计,但是图像的信息量是远大于text,所以目前计算开销依然很大。
2 CNN与Transformer如何优缺点互补?